每日论文速递 | NLP大佬们联合发文,倡导使用检索增强模型RA-LMs
每日论文速递 | NLP大佬们联合发文,倡导使用检索增强模型RA-LMs

深度学习自然语言处理 分享 整理:pp

摘要:参数化语言模型(LMs)通过在大量网络数据上进行训练,展现出了显著的灵活性和能力。然而,它们仍然面临着诸如幻觉、难以适应新数据分布以及缺乏可验证性等实际挑战。在这篇立场论文中,我们主张将检索增强型LMs作为下一代LMs取代参数化LMs。通过在推理过程中结合大规模数据存储,检索增强型LMs可以更加可靠、适应性强,并且具有可归因性。尽管具有潜力,但检索增强型LMs由于几个障碍尚未被广泛采用:具体来说,当前的检索增强型LMs在超出知识密集型任务(如问答)的文本利用方面遇到困难,检索和LM组件之间的互动有限,缺乏用于扩展的基础设施。为了解决这些问题,我们提出了开发通用检索增强型LMs的路线图。这涉及重新考虑数据存储和检索器,探索具有改进的检索器-LM交互的流水线,并且在高效训练和推理的基础设施上进行重大投资。
https://arxiv.org/abs/2403.03187

Q1: 这篇论文试图解决什么问题?
A:这篇论文试图解决的问题是现有参数化语言模型(Parametric Language Models, LMs)在实际应用中面临的一系列挑战,包括幻觉(hallucinations)、难以适应新数据分布、缺乏可验证性、难以退出特定序列以及模型大小过大等问题。为了应对这些挑战,论文提倡使用检索增强型语言模型(Retrieval-Augmented Language Models, RA-LMs)作为下一代语言模型。通过在推理过程中结合大规模数据存储库,RA-LMs可以更可靠、适应性强和可归因。论文提出了一个发展通用检索增强型LMs的路线图,涉及对数据存储库和检索器的重新考虑、探索改进检索器与LM之间互动的管道,以及在高效训练和推理基础设施方面的重大投资。
Q2: 有哪些相关研究?
A:论文中提到了多项与检索增强型语言模型(Retrieval-Augmented Language Models, RA-LMs)相关的研究,这些研究涵盖了RA-LMs的不同方面,包括架构、训练方法、应用和数据存储库。以下是一些关键的相关研究:
DrQA (Chen et al., 2017): 将基于术语的信息检索(IR)系统与神经问答(QA)模型结合起来,用于回答知识密集型问题。
REALM (Guu et al., 2020): 通过联合预训练检索器和语言模型,探索了检索增强型LM的有机结合。
RAG (Lewis et al., 2020a): 提出了一种方法,通过在现有强大的参数化LMs(如GPT-3)之上补充集成检索,而无需额外训练。
RETRO (Borgeaud et al., 2022): 引入了一种新的注意力机制,用于在中间空间同时整合多个预编码的文本块。
kNN LM (Khandelwal et al., 2020): 通过输出插值直接检索连续的标记或短语,而不需要额外的训练。
NPM (Min et al., 2023b): 使用大型预训练语料库(如The Pile)作为数据存储库,展示了在更广泛的语言理解任务上的有效性。
SPALM (Yogatama et al., 2021) 和 Adaptive kNN (Drozdov et al., 2022): 这些工作探索了在不同的粒度级别上进行检索,例如在标记级别或短语级别。
GPT-3 (Black et al., 2022) 和 GPT-4 (OpenAI, 2023): 这些是大型参数化LMs的例子,它们在各种任务上展示了强大的性能。
Llama (Touvron et al., 2023a) 和 Llama 2 (Touvron et al., 2023b): 这些是公开发布的模型,它们在数万亿个标记上训练较少的参数,展示了在各种任务上的强大性能。
这些研究为RA-LMs的发展提供了基础,并展示了在不同领域和任务中应用RA-LMs的潜力。论文还强调了需要进一步的研究来克服RA-LMs的固有局限性,以便它们能够更广泛地被采用。
Q3: 论文如何解决这个问题?

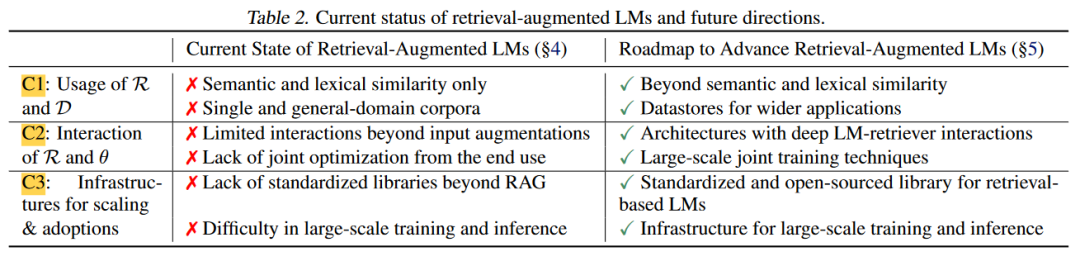
A:论文提出了一个发展检索增强型语言模型(Retrieval-Augmented Language Models, RA-LMs)的路线图,以解决参数化语言模型(Parametric LMs)面临的挑战。这个路线图包括以下几个关键步骤:
- 重新考虑数据存储库和检索器(C1):
- 超越语义和词汇相似性:重新定义输入查询和数据存储库中的文档之间的“相关性”,以在非知识密集型任务中取得成功。
- 改进数据存储库:研究如何构建和确保高质量、有效的数据存储库,以及如何平衡多个领域。
- 增强检索器和语言模型之间的互动(C2):
- 新的架构设计:开发超越输入增强的更专业的、集成的架构,如输出插值或中间融合。
- 在预训练中整合检索:探索在预训练阶段就整合检索的方法,以提高模型对检索上下文的利用。
- 预训练后的进一步适应:研究如何在预训练后对RA-LMs进行适应性调整,以提高其在各种下游任务中的有效性。
- 高效的端到端训练:研究如何在不牺牲检索组件的情况下,联合优化检索器和语言模型。
- 构建更好的系统和基础设施以实现扩展和适应(C3):
- 为大规模数据存储库开发可扩展的搜索:探索压缩和量化算法,以及更快的最近邻搜索算法。
- 标准化和开源发展:建立标准化的RA-LMs实现和评估基准,以支持各种架构和训练配置。
通过这些步骤,论文旨在推动RA-LMs的发展,使其能够更广泛地应用于各种任务和领域,同时克服现有参数化LMs的局限性。这需要跨学科的合作努力,包括硬件、系统、算法和语言模型应用的专家。
Q4: 论文做了哪些实验?
A:论文本身是一个立场性文件(position paper),它提出了一个关于检索增强型语言模型(RA-LMs)的发展路线图,而不是一个实验性研究。因此,它并没有报告具体的实验结果。相反,论文讨论了RA-LMs的潜在优势,并指出了当前RA-LMs在实际应用中面临的挑战。它还回顾了一些现有的相关工作,并基于这些工作提出了未来研究的方向。
论文的主要贡献在于提出了一个框架,用于指导未来的研究工作,以便开发出更可靠、适应性强和可归因的RA-LMs。这包括对数据存储库和检索器的重新考虑、改进检索器与语言模型之间的互动,以及为RA-LMs的高效训练和推理建立基础设施。这些建议旨在推动社区进一步探索RA-LMs,并解决它们在广泛采用方面所面临的障碍。
Q5: 有什么可以进一步探索的点?
A:论文提出了多个可以进一步探索的点,以推动检索增强型语言模型(RA-LMs)的发展和应用。以下是一些关键的研究方向:
重新定义相关性:探索如何超越传统的语义和词汇相似性,以更好地理解在各种任务中哪些文档是有帮助的。
改进数据存储库:研究如何构建和维护高质量、有效的数据存储库,以及如何在多个领域之间平衡。
新的架构设计:开发新的RA-LM架构,以实现更深层次的检索器与语言模型之间的互动,例如通过输出插值或中间融合。
检索器与语言模型的联合预训练:探索在预训练阶段整合检索的方法,以提高模型对检索上下文的利用。
预训练后的适应性调整:研究如何在预训练后对RA-LMs进行有效的适应性调整,以提高其在特定任务上的表现。
端到端训练的优化:研究如何更有效地联合优化检索器和语言模型,以减少检索错误并提高整体性能。
基础设施和系统开发:开发支持大规模数据存储库的搜索算法,以及提高RA-LMs训练和推理效率的硬件和软件工具。
标准化和开源:建立标准化的RA-LMs实现和评估基准,以促进社区的协作和共享。
跨学科合作:鼓励硬件、系统、算法和语言模型应用领域的专家合作,共同解决RA-LMs面临的挑战。
应用探索:在更广泛的任务和领域中测试RA-LMs的有效性,包括非知识密集型任务和多模态任务。
这些研究方向旨在解决RA-LMs在实际应用中的限制,并推动其在自然语言处理(NLP)领域的广泛应用。
Q6: 总结一下论文的主要内容?
A:这篇论文提出了检索增强型语言模型(Retrieval-Augmented Language Models, RA-LMs)作为下一代语言模型的解决方案,以克服现有参数化语言模型(Parametric LMs)的局限性。主要内容包括:
- 问题阐述:论文指出参数化LMs在实际应用中面临的挑战,如幻觉、适应性差、缺乏可验证性、退出特定序列的困难、计算成本高和模型规模大。
- RA-LMs的优势:提出RA-LMs通过在推理时结合大规模数据存储库,可以减少事实错误、提供更好的归因、灵活地选择序列、适应新分布,并提高参数效率。
- 现有RA-LMs的局限性:尽管RA-LMs有潜力,但它们在知识密集型任务之外的应用受限,主要因为它们难以利用超出知识密集型任务的有用文本,检索和LM组件之间的交互有限,且缺乏扩展基础设施。
- 发展路线图:论文提出了一个发展RA-LMs的路线图,包括重新考虑数据存储库和检索器、探索改进检索器与LM互动的管道、以及投资于高效训练和推理的基础设施。
- 挑战与解决方案:论文识别了RA-LMs面临的挑战,并提出了相应的解决方案,如改进检索的相关性定义、开发新的架构设计、优化端到端训练技术、以及建立标准化和开源的RA-LMs实现。
- 未来研究方向:论文鼓励研究社区在RA-LMs的架构、训练方法和基础设施方面进行深入研究,以实现其在更广泛任务和领域的应用。
总的来说,这篇论文为RA-LMs的发展提供了一个全面的框架,并强调了跨学科合作在推动这一领域进步中的重要性。
以上内容均由KimiChat生成,深入了解论文内容仍需精读论文