CVPR 2024 | 百度提出视觉新骨干ViT-CoMer,刷新密集预测任务SOTA
CVPR 2024 | 百度提出视觉新骨干ViT-CoMer,刷新密集预测任务SOTA

本文分享 CVPR 2024 论文ViT-CoMer: Vision Transformer with Convolutional Multi-scale Feature Interaction for Dense Predictions,由百度提出视觉新骨干 ViT-CoMer,刷新密集预测任务 SOTA。

- 论文链接:https://arxiv.org/pdf/2403.07392.pdf
- 开源地址:https://github.com/Traffic-X/ViT-CoMer,(欢迎大家试用和star)
1.算法效果
1.1.炸裂结果
检测效果SOTA
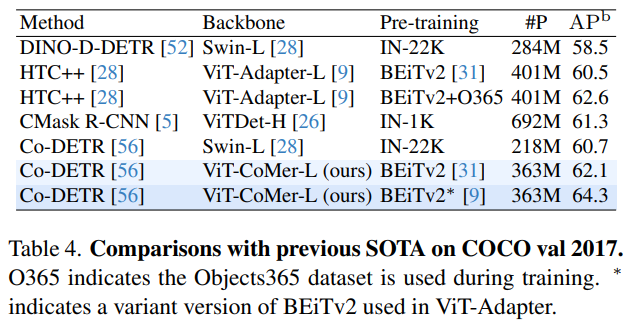
在未增加额外训练数据的情况下,ViT-CoMer-L在目标检测benchmark COCO val2017上达到了64.3% AP。此前检测的SOTA算法为Co-DETR,在未增加额外数据时Co-DETR的效果为60.7% AP,使用ViT-CoMer替换原backbone(Swin-L)的同时采用了ViT-Adapter提供的BEiTv2*作为预训练,其检测效果可达64.3% AP,相比较其他同体量算法ViT-CoMer效果更优。
分割效果SOTA
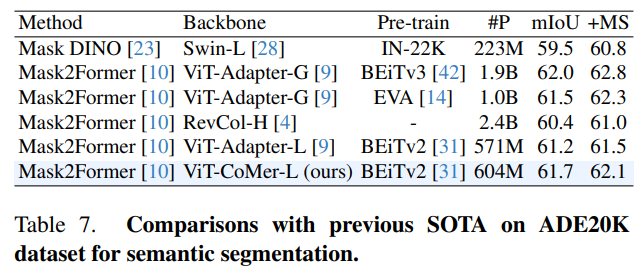
ViT-CoMer-L在语义分割 benchmark ADE20K val上获得了62.1% mIoU,10亿参数量以下效果SOTA。基于Mask2Former分割算法,对比了ViT-CoMer和其他先进的骨干网络(如RevCol-H,ViT-Adapter-L等),从表7可以看出,在相似体量下,ViT-CoMer算法达到了SOTA的效果,甚至可媲美其他更大体量的模型(ViT-Adapter-G,1B参数)
小体积大能量
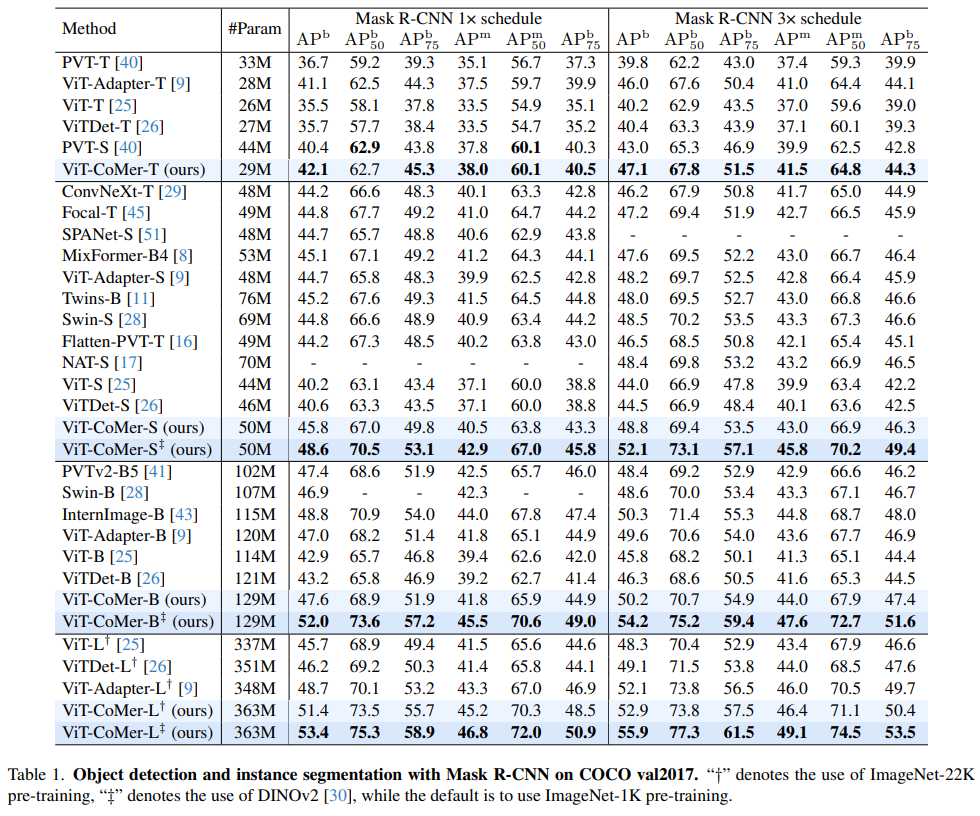
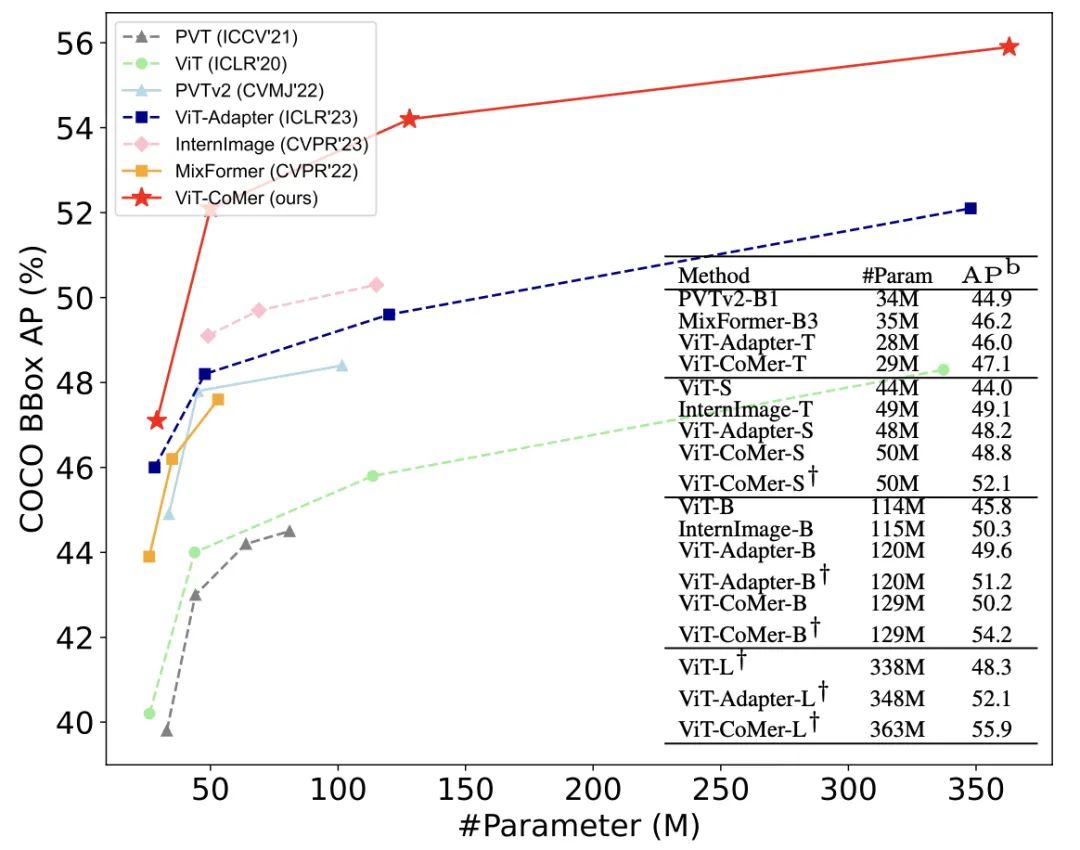
Small也可以当Large用,ViT-CoMer-S (1/6 ViT-L参数量 )取得与ViT-L相当的检测效果。基于经典的Mask R-CNN检测框架,我们跨体量跨骨干网络对比了在COCO数据集上的效果,惊喜的发现ViT-CoMer-Small(仅ViT-Large参数量的1/6)可以达ViT-Large相同效果,而当采用更先进的预训练时效果又出现了代差级的提升。
不同规模效果样样强
ViT-CoMer 在不同的参数规模下都可以获得SOTA效果。同样基于Mask-RCNN检测框架,我们对比了不同骨干网络在COCO数据集上的效果,不难发现,ViT-CoMer在不同参数规模、不同训练配置下效果均领先于其他先进的骨干网络。
1.2.性能
训推性能均强悍(Rebuttle内容,后续补充至github)
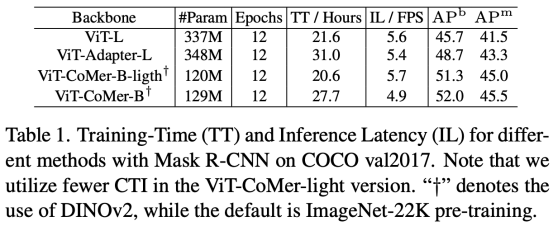
相同的效果下,ViT-CoMer在训练、推理性能(耗时更短)上都更优。基于Mask-RCNN检测框架,对比分析了ViT-Large、ViT-Adapter-Large和ViT-CoMer-Base-light三种方案的性能,可以看出ViT-CoMer-Base-light(使用少量的CTI模块)用更短的训练和推理时间,即可取得更好的效果。
1.3.可拓展性
零成本使用先进预训练
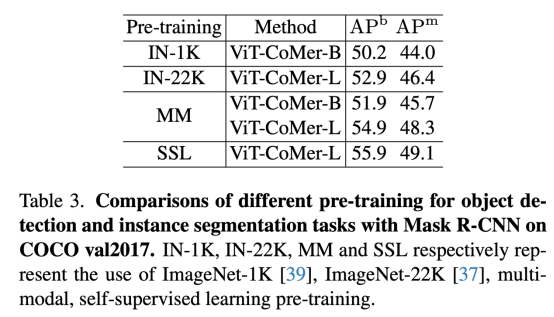
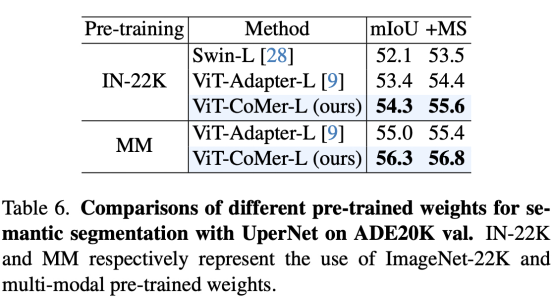
ViT-CoMer可以直接加载不同的预训练(如ImagNet-1K,ImageNet-22K,MM等)。基于Mask-RCNN检测和UperNet分割框架,依次使用Imagenet-1K,Imagenet-22K和多模态等预训练初始化ViT分支。从表3和表6中我们可以看出预训练越强,算法效果越好。
高效兼容不同算法框架
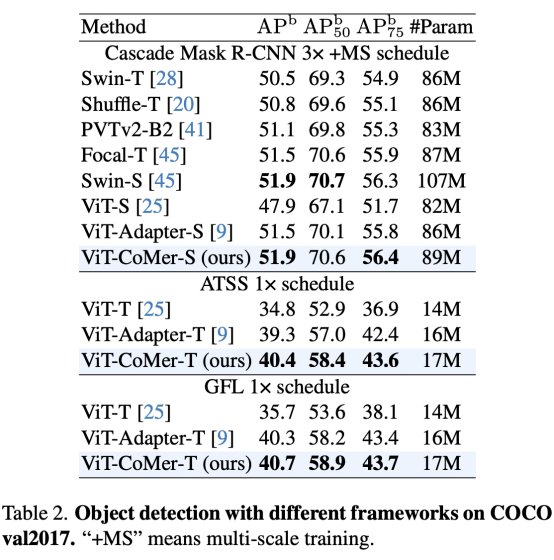
ViT-CoMer可以直接嵌入到不同的检测框架中。将ViT-CoMer迁移到Cascade Mask-RCNN,ATSS和GFL等检测框架中,从表2可以看出,ViT-CoMer效果较其他骨干网络更优。
轻松适配不同Transformer
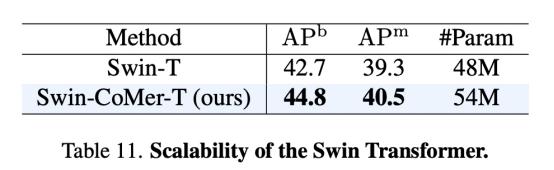
CoMer不仅仅可以适配ViT框架,其他基准骨干网络(如Swin)也可以轻松适配。我们尝试将CoMer迁移到ViT之外的其他Transformer框架中,我们惊喜的发现,CoMer同样可以在其中发挥作用,从表11中可以看到,适配后X-CoMer效果相比较基准模型更优。
有效的PEFT策略(Rebuttle内容,后续补充至github)
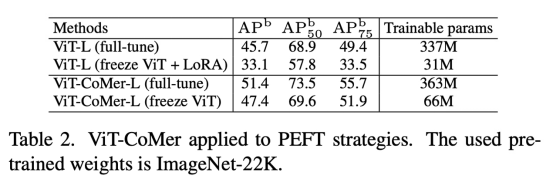
CoMer也可以作为一种有效的PEFT策略使用。当我们freeze住ViT部分,只训练CoMer部分参数,可以看出CoMer效果要优于LoRA(ViT-CoMer-L(freeze ViT) > ViT-L(full-tune) > ViT-L(freeze ViT + LoRA))。
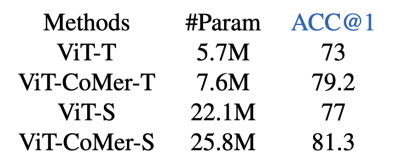
密集预测任务不是极限
除了密集预测任务之外,我们也尝试了ViT-CoMer在分类任务上的效果。我们在Imagenet数据集上对比了ViT和ViT-CoMer的结果,实验显示我们的算法依旧有很强的竞争力。
2.动机
当前Tranformer骨干网络处理密集预测任务存在以下问题:
- ViT骨干网络处理密集预测任务(检测、分割等)效果不佳;
- 特制骨干网络需要重新预训练,增加训练成本;
- 适配骨干网络仅对ViT和卷积特征进行信息交互,缺少不同尺度特征之间的信息交互。
针对以上三个问题,Vit-CoMer做了如下优化:
- 针对问题1和2, 设计了一种新颖的密集预测骨干网络,它集成了ViT和CNN特征。由于网络保留了完整的ViT结构,所以可以有效地利用各种ViT开源预训练权重,同时网络融入多感受野空间多尺度卷积特征,解决了ViT特征之间缺乏交互以及表征尺度单一的问题。
- 针对问题3, 设计了一种CNN-Transformer双向交互模块,不仅能够丰富与增强彼此之间的特征,还能同时进行层级之间多尺度特征的融合,从而得到更加丰富的语义信息,有利于处理密集预测任务。
3.方案
3.1.整体框架
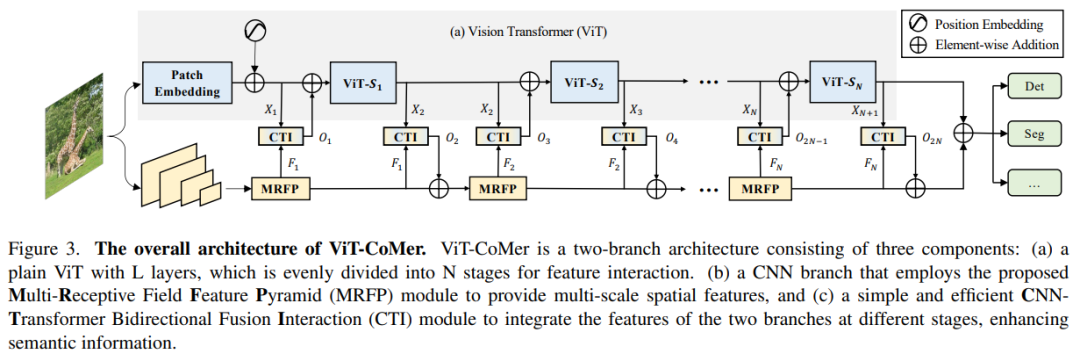
ViT-CoMer网络架构十分简洁(如图3所示),其中ViT占主体(如红色框内1所示),适配一个轻量的CNN结构(如绿色框内所示)。整个结构包含2个关键模块:MRFP(如绿2)和CTI(如绿3)。其中MRFP主要作用是补充多尺度和局部特征信息。CTI的作用则是对不同架构特征信息进行增强。
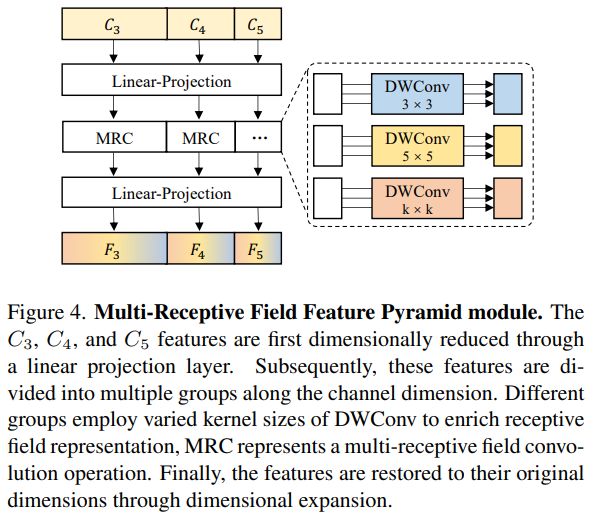
3.2.多感受野特征金字塔模块(MRFP)
MRFP是由特征金字塔和多感受野卷积层组成。特征金字塔能提供丰富的多尺度信息,而后者通过不同的卷积核扩展感受野,增强了CNN特征的长距离建模能力。该模块如图4所示。
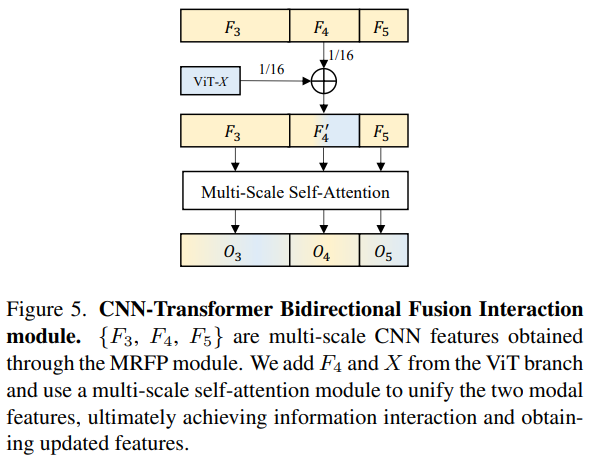
3.3.CNN-Transformer双向交互融合模块(CTI)
CTI是一种跨架构的特征融合方法,如图5所示。在不改变ViT的结构的情况下,引入了CNN的多尺度特征,由于ViT是单尺度特征,CNN为多尺度特征,在实现的时候直接将CNN中与ViT同尺度的特征进行相加(优势,简单高效)。同时对相加后的特征进行了多尺度自注意力操作,这样不同尺度的特征之间也进行了借鉴和增强。通过双向交互模块,CTI缓解了ViT中缺乏局部信息交互和非层次特征的问题,同时进一步增强了CNN的长距离建模和语义表征能力。
4.可视化效果
目标检测和实例分割可视化对比分析

与ViT相比:从图6可以看出,ViT-CoMer产生了更具层次感的多尺度特征,具备丰富的局部边缘和纹理,提升了目标检测和实例分割的效果。

与ViT-Adapter相比(Rebuttle内容,后续补充至github):从图1可以看出,ViT-Adapter和ViT-CoMer同时具备丰富的多尺度纹理信息,但是相比ViT-Adapter, ViT-CoMer的信息颗粒度更胜一筹。更细节的内容请阅读原文和代码。
Reference Xia, C., Wang, X., Lv, F., Hao, X., & Shi, Y. (2024). ViT-CoMer: Vision Transformer with Convolutional Multi-scale Feature Interaction for Dense Predictions.