7B 最强多模态文档理解大模型 mPLUG-DocOwl 1.5
7B 最强多模态文档理解大模型 mPLUG-DocOwl 1.5

多模态大模型 Multimodal LLM (MLLM) 相关研究致力于实现通用的图片理解,其中类别多样、文字丰富且排版复杂的文档图片一直是阻碍多模态大模型实现通用的痛点。当前爆火的多模态大模型QwenVL-Max, Gemini, Claude3, GPT4V都具备很强的文档图片理解能力,然而开源模型在这个方向上的进展缓慢,距离这些闭源大模型具有很大差距 (例如DocVQA上开源7B SOTA 66.5,而Gemini Pro 1.5为86.5)。
mPLUG-DocOwl 1.5 是阿里巴巴mPLUG团队在多模态文档图片理解领域的最新开源工作,在10个文档理解benchmark上达到最优效果,5个数据集上提升超过10个点,部分数据集上超过智谱17.3B的CogAgent,在DocVQA上达到82.2的效果。
- github: https://github.com/X-PLUG/mPLUG-DocOwl
- arxiv: http://arxiv.org/abs/2403.12895
模型结构
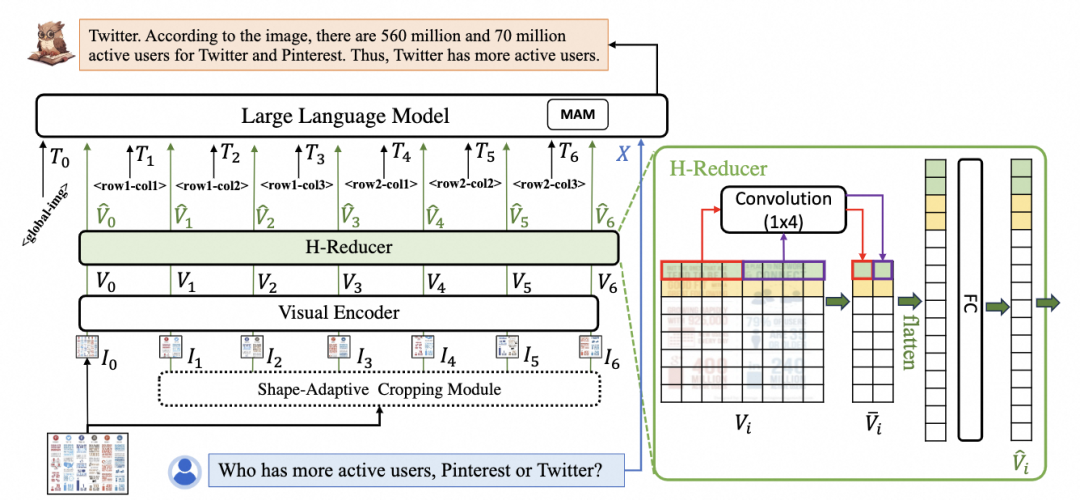
DocOwl 1.5强调文档图片理解中对于“文档结构”理解的重要性,提出对于所有文字信息丰富的图片进行统一的结构学习。DocOwl 1.5延续该团队前序工作DocOwl以及UReader处理高分辨率文档图片的方式,采用一个形状适应的切图模块将高分辨率图片切为多个大小一致的子图。为了更好的将图片的文字布局信息传递给LLM,同时避免在处理高分辨率文档图片时视觉特征过长,DocOwl 1.5提出来一个基于卷积的连接结构H-Reducer,其在水平方向上混合4个视觉特征,模型结构如下图所示。
模型训练
DocOwl 1.5采用两阶段的训练策略,如下图所示:
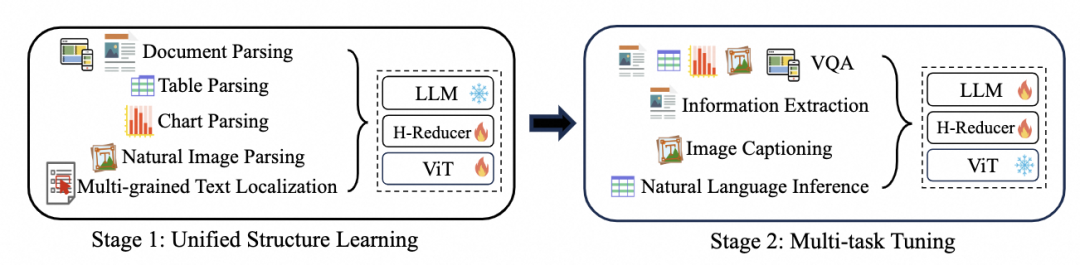
第一阶段进行所有类别图片的结构学习,即Unified Structure Learning。该学习过程既包含考虑结构的全局文字解析,即文档解析(Document Parsing),表格解析 (Table Parsing),图表解析 (Chart Parsing),自然图解析(Natural Image Parsing),又包括多粒度的文字识别或定位,包括词语级别(word),词组级别 (phrase),行级别 (line) 以及块级别 (block),如下图所示。考虑到LLM本身对于结构化文本具有很强的理解能力,这个阶段主要训练Visual Encoder和H-Reducer来增强文字和结构的视觉表示能力。
第二阶段进行下游文档理解数据集多任务微调。该阶段主要是为了让模型充分利用基础的视觉文字和结构理解能力,遵循用户不同的指令(例如问答,信息抽取,描述)来进行回复。因此Visual Encoder被冻住,其它结构进行训练。
训练数据
为了进行统一的文档结构学习,该工作基于开源数据集构建了一个全面的结构化解析数据集DocStruct4M。对于文档图片或者网页截图,主要采用空格和换行表示文字布局;对于表格,其改进的Markdown语法既能表示跨行跨列,又相比html缩减了大量标签;对于图表,同样采用markdown来表示其数学特征,并且限定数值的有效位以保证其在图片中视觉可见;对于自然图,采用描述加上ocr文本的形式。DocStruct4M具体的分布如下图所示:

第二阶段的多任务微调数据延续mPLUG-DocOwl/UReader,并移除了原始的忽略结构的文字阅读数据,涵盖文档图片信息抽取,视觉问答,图片描述,自然语言推理等任务,共计60w左右。
此外,本文为了将LLM的解释能力应用到多模态文档理解,基于GPT3.5以及GPT4V构建了一个包含详细解释的高质量指令微调数据集DocReason25K。通过混合Benchmark数据和DocReason25K进行联合训练,进一步得到DocOwl 1.5-Chat。
实验结果
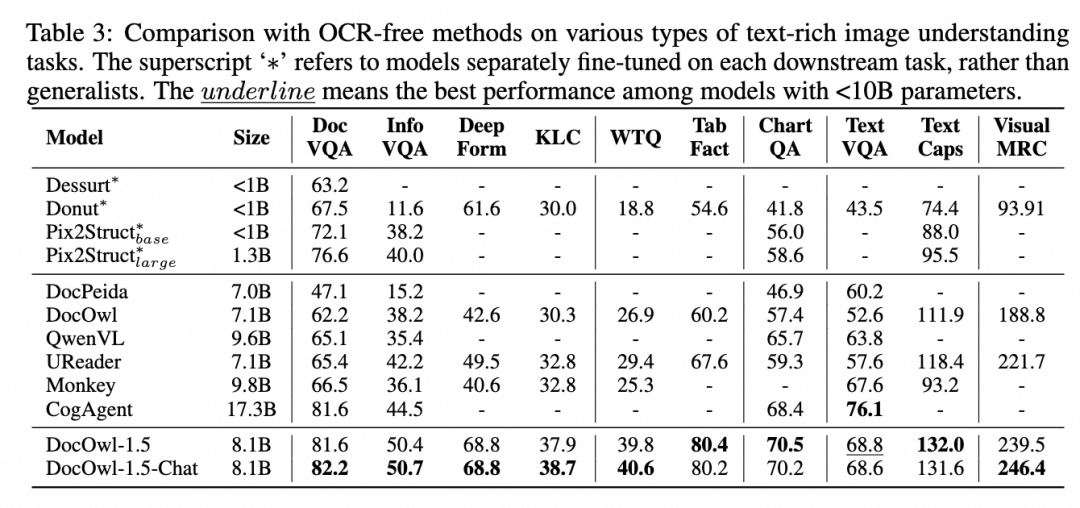
DocOwl 1.5 (8.1B) 和DocOwl 1.5-Chat (8.1B) 在10个benchmark上达到SOTA效果,部分数据集上超过训练了>107M文档数据的CogAgent(17.3B),如下图所示。
从样例可以看出,DocOwl 1.5在经过统一结构学习后,对于文档,表格,图表,自然图都能进行准确的解析。

case1

case2

case3

case4
除了全图解析,对于各种粒度的文字也能进行准确的定位或者识别。
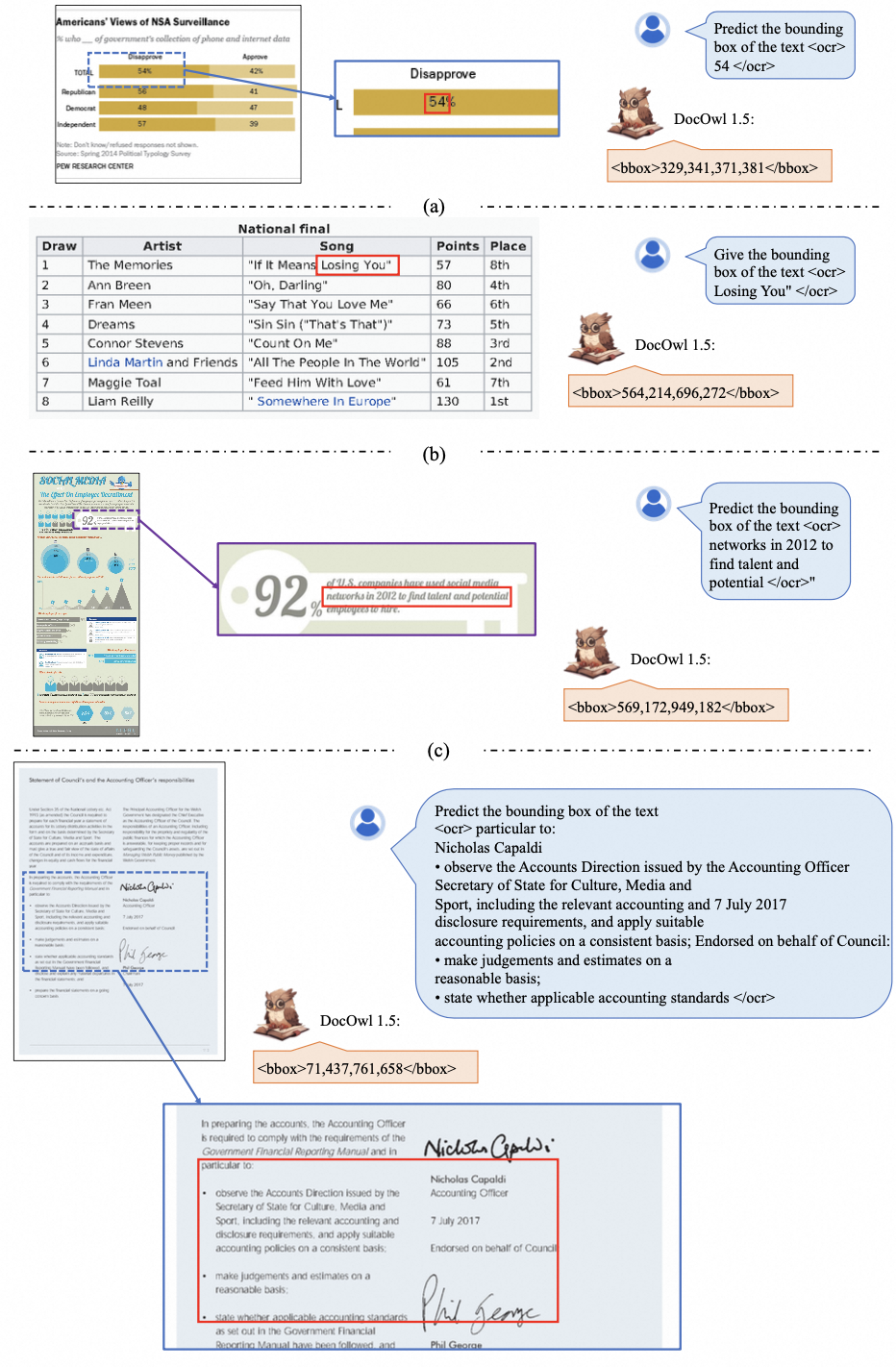
case6

case5
另外,DocOwl 1.5-Chat可以对于各种类别图片的问答给出详细的解释。

case7

case8
总结
mPLUG-DocOwl 1.5是目前在多模态文档领域最强的7B左右多模态大模型,具备多种类型文档图片的结构化解析能力,文字识别和定位能力以及指令遵循和详细解释能力,大幅度提升了开源大模型的通用文档理解性能。不过其距离闭源大模型仍然有较大差距,在自然场景中文字识别、数学计算等方面仍然有进步空间。mPLUG团队会进一步优化DocOwl的性能并进行开源,欢迎大家持续关注和友好讨论!