每日论文速递 | TeaMs-RL: 通过强化学习让LLM自己学会更好的指令
每日论文速递 | TeaMs-RL: 通过强化学习让LLM自己学会更好的指令

深度学习自然语言处理 分享 整理:pp

摘要:大语言模型(LLM)的开发经常面临挑战,这些挑战源于强化学习与人类反馈(RLHF)框架中对人类注释者的严重依赖,或与自我指导范式相关的频繁而昂贵的外部查询。在这项工作中,我们转向了强化学习(RL)--但有一个转折。与典型的 RLHF(在指令数据训练后完善 LLM)不同,我们使用 RL 直接生成基础指令数据集,仅此数据集就足以进行微调。我们的方法 TeaMs-RL 使用一套文本操作和规则,优先考虑训练数据集的多样化。它有助于生成高质量数据,而无需过度依赖外部高级模型,从而为单一微调步骤铺平了道路,并消除了对后续 RLHF 阶段的需求。我们的研究结果凸显了我们的方法的主要优势:减少了对人工参与的需求,减少了模型查询次数(仅为WizardLM总查询次数的5.73美元/%$),同时,与强大的基线相比,LLM在制作和理解复杂指令方面的能力得到了增强,模型隐私保护也得到了大幅改善。
https://arxiv.org/abs/2403.08694
Q1: 这篇论文试图解决什么问题?
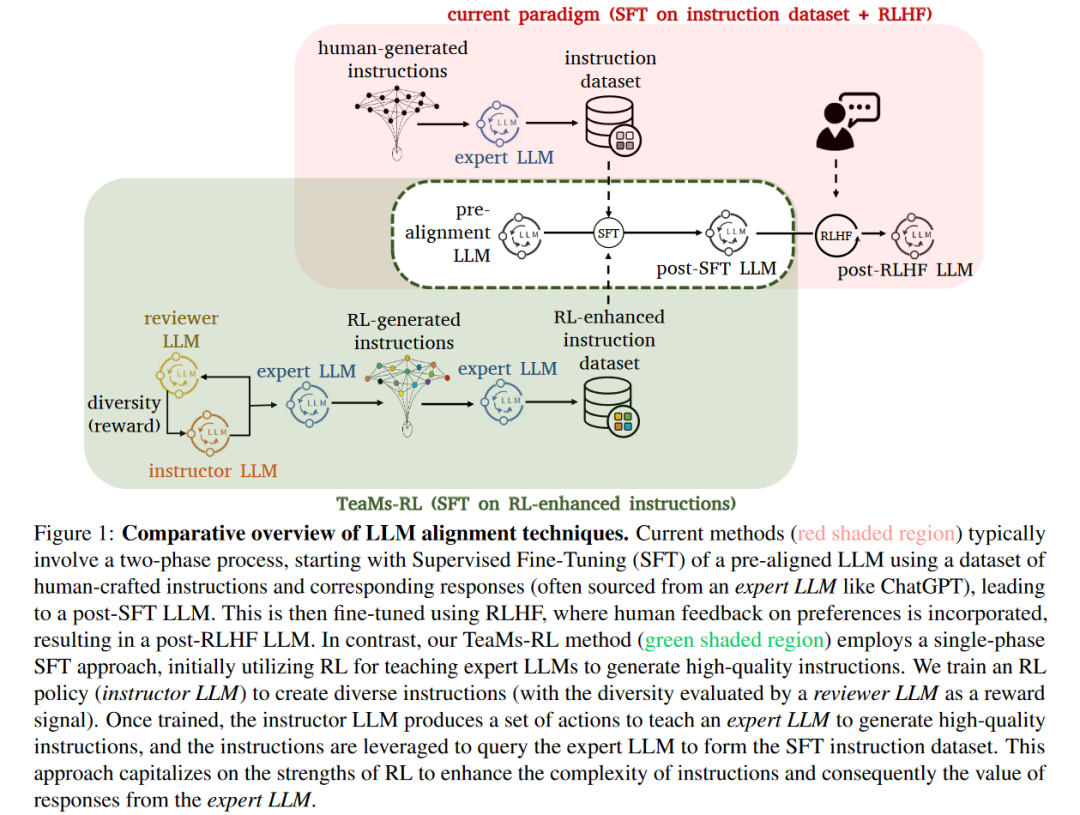
A:这篇论文试图解决的问题是如何提高大型语言模型(LLMs)在执行复杂指令时的性能,同时减少对人类注释者的依赖和减少外部高级模型的查询次数。具体来说,它提出了一种名为TeaMs-RL的方法,该方法使用强化学习(RL)直接生成用于微调的基础指令数据集,而不是依赖于传统的依赖人类反馈的强化学习(RLHF)框架或自我指导范式中的频繁外部查询。
TeaMs-RL方法的核心在于训练一个指导性的大型语言模型(作为RL策略),以生成多样化和高质量的指令,这些指令随后用于从专家级LLM中获取响应,形成增强多样性的指令数据集。这个数据集最后用于对预对齐的LLM进行监督式微调(SFT),从而提高其处理复杂任务的能力。
论文的主要贡献包括:
- 减少了对人类指导者(例如注释者和评估者)的需求,提供了一种成本效益更高的对齐范式,支持有能力且负担得起的LLM的持续发展。
- 减少了对外部模型频繁查询的需求,带来了经济利益,并减轻了能源密集型数据中心的环境影响。
- 通过减少对外部数据(用于SFT或RLHF)的依赖,可能扩大了数据可用性有限或数据收集成本高昂的其他工程和科学领域的应用范围。
- 这种方法还显著提高了模型的隐私保护能力。
Q2: 有哪些相关研究?
A:这篇论文中提到的相关研究主要集中在以下几个方面:
大型语言模型(LLMs)的训练:研究了使用指令和相应响应对进行训练的方法,例如GPT-3(Brown et al., 2020)、ChatGPT-4(OpenAI, 2023)、Flan系列(Longpre et al., 2023)、Flan模型(Wei et al., 2021)和Alpaca(Taori et al., 2023)。
自我指导方法:Wang et al. (2022) 提出了自我指导方法,使用外部LLM生成对人类生成的种子指令的响应,用于指令数据集的策划。
进化策略:Xu et al. (2024) 介绍了WizardLM,一种进化指令方法,通过合并命令指令和专家LLM(如ChatGPT)来适应初始指令。
模型对齐:研究了如何通过指令和响应的配对来训练语言模型,通常需要人类注释者来制定指令和整理相应的响应,从而构建详细的指令-响应数据集。
模型隐私保护:研究了如何通过合成数据集来增强模型的隐私保护,特别是在AI安全领域,以及如何通过数据合成器来减少数据泄露的风险。
环境影响:探讨了大型数据中心的环境影响,以及如何通过减少对外部模型的查询来减轻这些影响。
强化学习(RL):在语言模型的上下文中,探索了使用RL来提高指令质量的方法,以及如何通过RL来增强LLMs理解和执行复杂指令的能力。
这些相关研究为TeaMs-RL方法提供了背景和对比,展示了当前在LLMs训练、指令生成、模型对齐和隐私保护等方面的研究进展。
Q3: 论文如何解决这个问题?

A:论文通过提出一种名为TeaMs-RL的新方法来解决上述问题,该方法主要包括以下几个步骤:
- 训练指导性LLM(RL策略):首先,论文训练一个指导性的LLM(作为RL策略),这个模型被称为“指导者LLM”。它使用一系列文本操作和规则来生成多样化的指令,这些指令旨在提高训练数据集的多样性。这个过程使用了一个连续的动作空间编码,并且以指令多样性作为奖励信号。
- 生成高质量的指令响应对:接着,使用训练好的指导者LLM来教导一个专家级LLM(如ChatGPT)生成高质量的指令。这些指令随后被用来从专家LLM那里获取响应,形成了一个增强了多样性的指令响应对数据集。
- 微调预对齐的LLM:使用生成的指令响应对数据集对一个预对齐的LLM(例如Llama-1)进行监督式微调(SFT)。这个过程旨在提高LLM处理复杂任务的能力。
- 减少对人类反馈的依赖:通过上述步骤,TeaMs-RL方法减少了对人类反馈的依赖,因为它不依赖于人类注释者来创建指令数据集。此外,它还减少了对外部高级模型的查询次数,从而降低了成本并提高了隐私保护。
- 实验验证:论文通过一系列实验来验证TeaMs-RL方法的有效性。这些实验包括在ARC和HellaSwag基准测试中的性能比较、模型隐私攻击测试,以及在解决一般任务和数学问题方面的能力比较。
总的来说,TeaMs-RL方法通过使用RL直接生成用于微调的高质量指令数据集,提供了一种新的途径来提高LLMs的性能,同时减少了对人类注释和外部模型的依赖。这种方法不仅提高了效率,还有助于降低成本和环境影响,同时增强了模型的隐私保护。
Q4: 论文做了哪些实验?
A:论文中进行了一系列实验来验证TeaMs-RL方法的有效性和效率。以下是主要的实验内容:
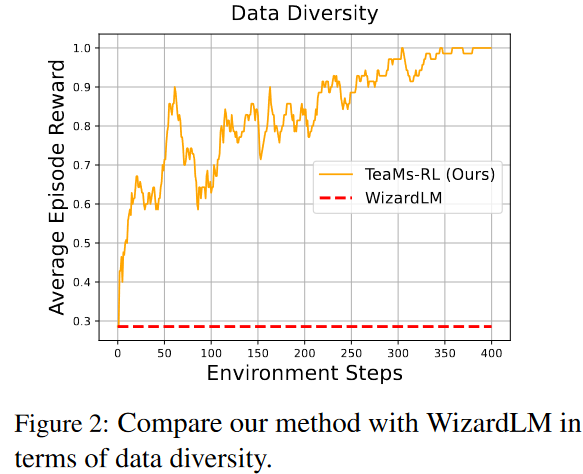
- 指令多样性提升:通过设计一个策略,该策略能够根据六个不同的指令动作生成指令,来比较TeaMs-RL方法与WizardLM方法在数据多样性方面的表现。实验结果表明,TeaMs-RL方法能够可靠地提高指令集的多样性得分。
- 教授LLM生成指令:使用训练好的RL策略,教授专家级LLM(如ChatGPT-4和ChatGPT-3.5)生成高质量的指令。通过比较初始指令和生成的指令,展示了TeaMs-RL方法在生成复杂和创造性指令方面的能力。
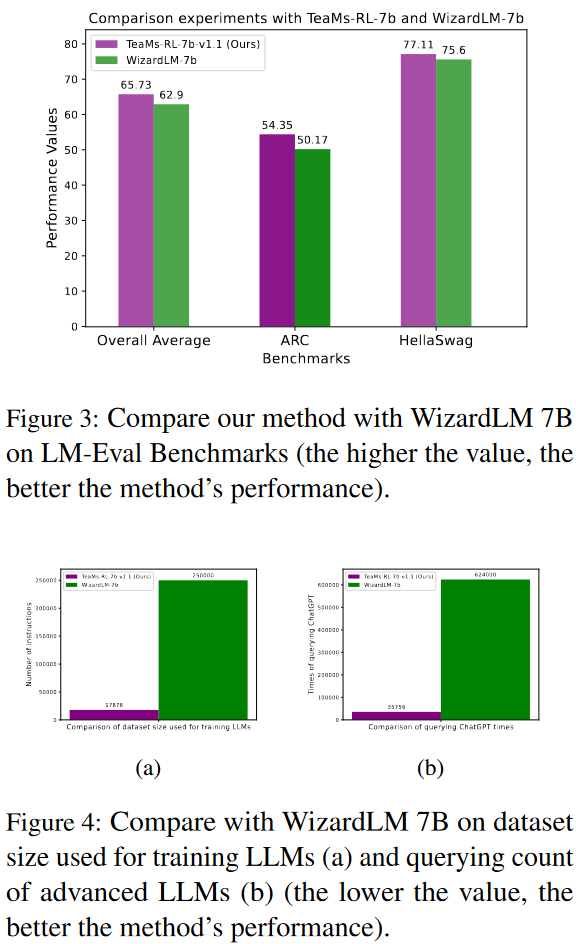
- 在ARC和HellaSwag基准测试上的比较:在AI2 Reasoning Challenge (ARC) 和 HellaSwag 基准测试上,将TeaMs-RL方法训练的模型与WizardLM-7b模型进行比较。结果显示,TeaMs-RL方法在这些基准测试上表现出色,且使用的指令-响应对数据集远小于WizardLM。
- 模型隐私攻击实验:通过会员推断攻击(membership inference attack)来评估模型的隐私保护性能。TeaMs-RL模型在隐私保护方面表现出色,其ROC曲线更接近于随机猜测,AUC值更低,表明更好的隐私保护性能。
- 在Apaca Eval基准测试上的比较:使用apalca eval基准测试来评估模型在多种任务上的表现。TeaMs-RL模型在这个基准测试上的胜率高于WizardLM-7b模型。
- 解决一般任务的比较实验:提供了随机任务的场景,比较了TeaMs-RL模型与基线模型在生成响应方面的表现。TeaMs-RL模型在提供结构良好和准确的响应方面表现更好。
- 解决数学问题的比较实验:在数学任务上,比较了TeaMs-RL模型与其他强大基线模型的表现。TeaMs-RL模型在解决数学问题方面表现出色,即使与参数数量更多的模型相比也是如此。
- 与Llama-2-7b-chat模型的比较:在ARC和HellaSwag基准测试上,与使用RLHF训练的llama-2-chat-7b模型进行比较,TeaMs-RL模型在这两个基准测试上的表现都优于llama-2-chat-7b模型。
- 数据量消融实验:通过扩大数据集大小,评估了TeaMs-RL模型在ARC挑战和HellaSwag基准测试上的表现。结果显示,数据集的扩大带来了性能的提升。
- 在更大模型上的方法有效性评估:将TeaMs-RL方法应用于更大的模型(llama-1-13b),并与WizardLM-13b进行比较。在HellaSwag基准测试中,TeaMs-RL-13b模型表现优于WizardLM-13b模型。
这些实验全面地展示了TeaMs-RL方法在提高LLM性能、减少对人类反馈的依赖、降低成本、减少查询次数以及增强模型隐私保护方面的有效性。
Q5: 有什么可以进一步探索的点?
A:尽管TeaMs-RL方法在多个方面取得了显著的成果,但仍有一些方面可以进行进一步的探索和研究:
人类反馈的潜在价值:论文中提到,尽管TeaMs-RL方法减少了对人类反馈的依赖,但并未完全消除。探索在特定阶段引入人类反馈可能进一步提升模型对指令的理解和执行能力。
政策泛化能力:研究中使用的政策是基于特定指令训练的,可能不适用于所有初始指令。探索如何训练一个更通用的政策,以适应不同初始指令的生成。
成本与性能的平衡:虽然TeaMs-RL减少了对外部模型的查询次数,但训练过程本身可能需要大量的计算资源。研究如何在成本和性能之间找到最佳平衡点。
模型价值观对齐:探索TeaMs-RL方法在对齐LLMs与人类价值观方面的潜力,确保生成的指令不仅高质量,而且符合伦理和社会标准。
长期影响和可持续性:评估TeaMs-RL方法在长期使用中的可持续性,包括其对环境的影响和对数据隐私的长期保护。
跨领域应用:将TeaMs-RL方法应用于除自然语言处理之外的其他领域,如计算机视觉、机器人技术等,以评估其跨领域的适用性和有效性。
模型鲁棒性和健壮性:研究TeaMs-RL方法在面对不同类型的攻击(如对抗性攻击)时的鲁棒性,并探索提高模型健壮性的策略。
更大规模的数据集和模型:在更大规模的数据集上训练和测试TeaMs-RL方法,以验证其在大数据环境下的扩展性和性能。
多模态和跨模态学习:探索TeaMs-RL方法在处理多模态数据(如文本、图像、声音)时的表现,以及如何将其应用于跨模态学习任务。
实时和动态环境适应性:研究TeaMs-RL方法在动态和实时环境中的表现,例如在对话系统或实时决策支持系统中的应用。
这些探索点可以帮助研究者更深入地理解TeaMs-RL方法的潜力和局限性,从而推动大型语言模型的发展和应用。
以上内容均由KimiChat生成,深入了解论文内容仍需精读论文