Parrot:用于文本到图像生成的帕累托最优多奖励强化学习框架
Parrot:用于文本到图像生成的帕累托最优多奖励强化学习框架

论文题目:Parrot: Pareto-optimal Multi-Reward Reinforcement Learning Framework for Text-to-Image Generation 论文链接:http://arxiv.org/abs/2401.05675 论文作者:Seung Hyun Lee, Yinxiao Li, Junjie Ke, Innfarn Yoo, Han Zhang, Jiahui Yu, Qifei Wang, Fei Deng, Glenn Entis, Junfeng He, Gang Li, Sangpil Kim, Irfan Essa, Feng Yang 内容整理:黄海涛 本文介绍了 Parrot,一种用于 T2I (text to image)生成的新型多奖励 RL 框架。通过使用批量 Pareto 最优选择,Parrot 在 T2I 的 RL 优化过程中自动识别不同奖励之间的最佳权衡。此外,Parrot对T2I模型和提示扩展网络采用联合优化方法,有助于生成质量感知的文本提示,从而进一步提高最终图像质量。为了抵消由于提示扩展而导致的对原始用户提示的潜在灾难性遗忘,本文在推理时引入了以原始提示为中心的指导,确保生成的图像保持忠实于用户输入。大量实验和用户研究表明,Parrot 在各种质量标准(包括美学、人类偏好、图像情感和文本图像对齐)方面均优于多种基线方法。
介绍
最近的工作表明,使用具有质量奖励的强化学习(RL)可以提高文本到图像(T2I)生成中生成图像的质量。然而,多个奖励的简单聚合可能会导致某些指标的过度优化和其他指标的退化,并且手动找到最佳权重具有挑战性。所以非常需要一种有效的策略来联合优化 RL 中的多种奖励以生成 T2I。
为了实现这一目标,本文提出了一种用于文本到图像生成的新型帕累托最优多奖励强化学习框架,表示为 Parrot。在 T2I 模型产生的样本中,每个样本都体现了各种奖励函数之间的独特权衡。通过识别和利用在这样的训练批次中实现最佳权衡的集合(即帕累托最优集合),Parrot 有效地同时优化了多个奖励。这会生成具有良好美感、正确的图文对齐、符合人类偏好以及整体令人愉悦的情感的图像。
生成图像的质量很大程度上受到提供给 T2I 模型的文本提示输入的影响。语义丰富的提示已被证明可以生成更高质量的图像。认识到手动制作有效提示的难度,Promptist 被引入以通过大型语言模型(LLM)自主学习提示扩展。这涉及 LLM 的 RLtuning,同时保持 T2I 模型冻结为黑匣子。然而,由于 T2I 模型没有与提示扩展网络协作进行调整,因此它可能很难适应生成的文本输入。在 Parrot 中,使用多种质量奖励来联合优化提示扩展网络和 T2I 模型。这使得提示扩展网络和T2I模型能够协同生成更高质量的图像。
方法
Parrot概述
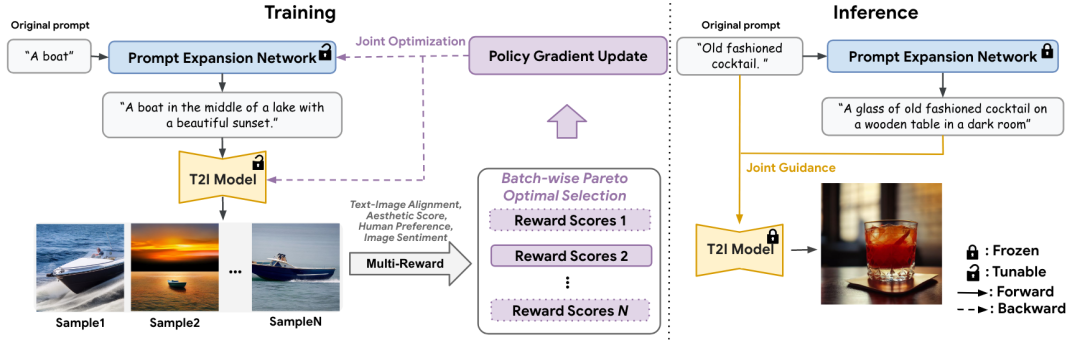
图 1
上图显示了Parrot的流程图,它由提示扩展网络(PEN)
和T2I扩散模型
组成。PEN 首先从提示扩展的有监督微调模型初始化,T2I 模型从预训练的扩散模型初始化。给定原始提示
,PEN 生成扩展提示
,T2I 模型根据该扩展提示生成图像。在多重奖励强化学习微调过程中,会对一批
个图像进行采样,并为每个图像计算多个质量奖励,涵盖文本图像对齐、美观、人类偏好和图像情感等方面。基于这些奖励分数,Parrot 使用非支配排序算法识别批量帕累托最优集。然后,通过 RL 策略梯度更新,将这组最佳图像用于 PEN 和 T2I 模型参数的联合优化。在推理过程中,Parrot 同时利用原始提示及其扩展,在保持对原始提示的忠实度和融入额外细节以提高质量之间取得平衡。
批量帕累托最优选择

图 2
上图的算法概述了 Parrot 的过程。Parrot 没有使用所有图像来更新梯度,而是专注于高质量样本,考虑每个小批量中的多个质量奖励。在多奖励强化学习中,T2I 模型生成的每个样本都为每个奖励提供了不同的权衡。在这些样本中,存在一个具有不同目标的最佳权衡的子集,称为帕累托集。对于帕累托最优样本,其目标值中的任何一个都无法在不损害其他目标值的情况下进一步提高。换句话说,帕累托最优集不被任何数据点支配,也称为非支配集。为了通过 T2I 扩散模型实现帕累托最优解,Parrot 使用非支配排序算法选择性地使用非支配集中的数据点。这自然会鼓励 T2I 模型针对多奖励目标生成帕累托最优样本。
奖励特定偏好:受到多目标优化中偏好信息的使用的启发,Parrot 通过奖励特定标识合并偏好信息。这使得 Parrot 能够自动确定每个奖励目标的重要性。具体来说,通过为第 k 个奖励添加奖励特定标识符“”来丰富扩展提示
。基于该奖励特定提示,生成
张图像,并用于在梯度更新期间最大化相应的第
个奖励模型。在推理时,所有奖励标识符“<reward 1>,...,”的串联用于图像生成。
非支配排序:Parrot 基于多种奖励之间的权衡,用非支配点构造 Pareto 集。这些非支配点优于其余解并且互不支配。形式上,支配关系定义如下:图像
支配图像
,表示为
, 当且仅当
对于所有
,并且存在
使得
。例如,给定小批量中第
个生成的图像
,当小批量中没有点支配
时,它被称为非支配点。
梯度更新策略:我们为不包含在非支配集中的数据点分配奖励值为零,并且仅更新这些非支配数据点的梯度,如下所示:
其中
表示小批量中图像的索引,
表示批量的一组非支配点。
和
分别是奖励模型的总数和总扩散时间步长。每批次更新扩散模型时都会使用相同的文本提示。
原始提示集中指导
虽然及时扩展可以增强细节并通常提高生成质量,但人们担心添加的上下文可能会淡化原始输入的主要内容。为了在推理过程中缓解这种情况,本文引入了原始的以提示为中心的指导。当以原始提示为条件进行采样时,扩散模型
通常通过结合无条件分数估计和提示条件估计来预测噪声。本文建议使用两个指导的线性组合来生成 T2I,而不是仅仅依赖于 PEN 的扩展提示:一个来自用户输入,另一个来自扩展提示。原始提示的强度由引导尺度
和
控制。噪声
是根据下式估算得出的,其中 null 表示空文本。
实验
定性分析
与基线比较:下图显示了Parrot和多个基线的视觉比较。Parrot通常会得到更好的图像,特别是在图像的颜色组合、裁剪、透视和细节等方面。这一改进可归因于 Parrot 的 T2I 模型与在训练过程中融入美学关键词的即时扩展模型一起进行了微调。Parrot 生成的结果与输入提示更加一致,并且视觉上更令人愉悦。

图 3
下图对比了使用Parrot和使用奖励分数线性组合的训练曲线。每个子图代表一个奖励。WS1和WS2表示具有多个奖励分数的两个不同权重。WS1 更注重审美得分,而 WS2 在审美、人类偏好、文本图像对齐和图像情感之间采用平衡权重。尽管美学和人类偏好显着增强,但采用多种奖励的加权和会导致图像情感得分下降。相比之下,Parrot 在所有指标上始终表现出改进。
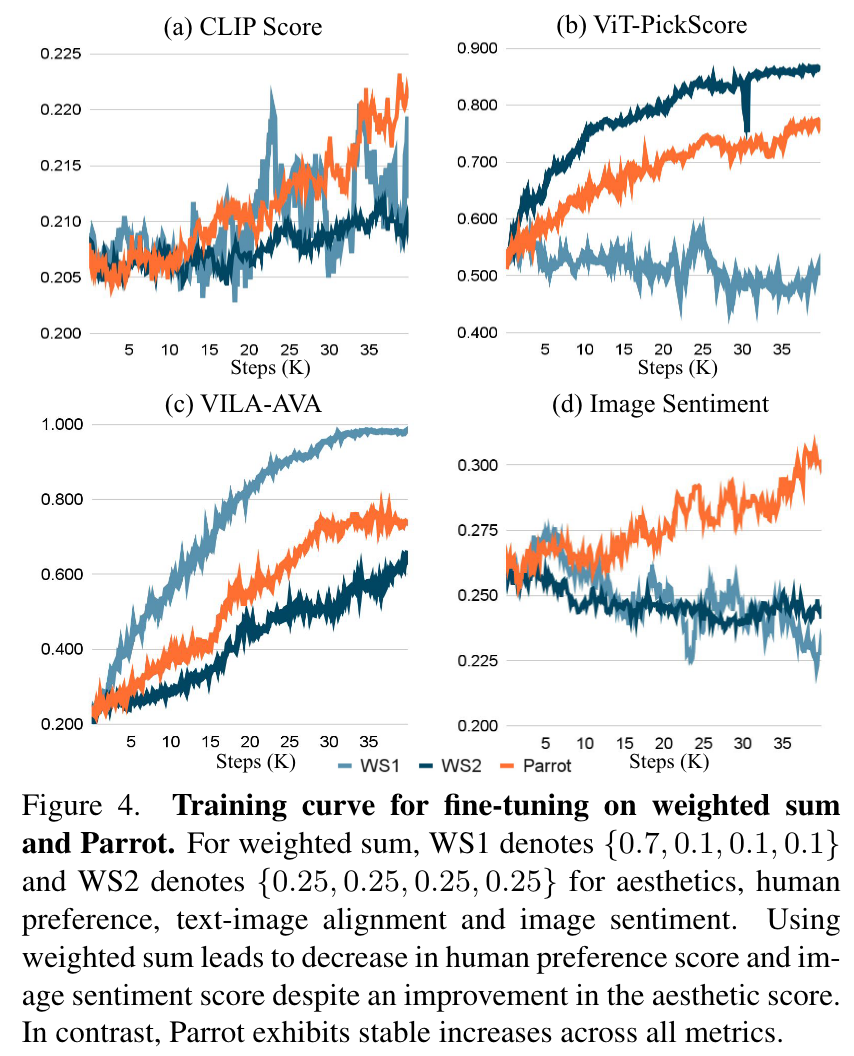
图 4
定量评价
与基线比较:下表展示了在四种质量奖励中的质量得分结果:文本图像对齐得分、审美得分、人类偏好得分、和情绪得分。Parrot 在每个子组中都显示出更好的文本-图像对齐。

表 1
消融实验
帕累托最优多重奖励强化学习的效果:为了展示帕累托最优多重奖励强化学习的有效性,通过一次删除一个奖励模型来进行消融研究。下图显示了 Parrot、具有单一奖励的 Parrot 和未选择批量帕累托最优解的 Parrot 之间的视觉比较。使用单一奖励模型往往会导致另一个奖励的退化,尤其是文本图像对齐。例如,在第三列中,第一行的结果缺少提示高帽,即使稳定扩散结果包含该属性。另一方面,Parrot 结果捕获了所有提示,改善了其他质量信号,例如美观、图像情感和人类偏好。

图 5
原始以提示为中心的指导的效果:下图显示了所提出的原始以提示为中心的指导的效果。从图中可以明显看出,仅使用扩展提示作为输入通常会导致主要内容被添加的上下文淹没。例如,给定原始提示“A shiba inu”,扩展提示的结果显示缩小的图像,并且预期的主要主题(shiba inu)变小。所提出的以提示为中心的原始指南有效地解决了这个问题,生成一个忠实捕捉原始提示的图像,同时融入视觉上更令人愉悦的细节。

图 6
总结
本文提出了 Parrot,这是一个旨在通过使用 RL 有效优化多个质量奖励来改进 T2I 生成的框架。通过批量帕累托最优选择,有效地平衡了多个质量奖励的优化过程,提高了每个质量指标。此外,通过协同训练 T2I 模型和即时扩展模型,Parrot 可以生成更高质量的图像。此外,本文原创的以提示为中心的引导技术可以控制用户输入中主要内容的持久性,确保生成的图像保持忠实于用户提示。用户研究结果表明,Parrot 显着提高了生成图像的质量,涵盖多个标准,包括文本图像对齐、人类偏好、美学和图像情感。虽然 Parrot 已证明在增强生成图像质量方面是有效的,但其功效受到其所依赖的质量指标的限制。因此,生成的图像质量指标的进步将直接增强 Parrot 的功能。此外,Parrot 还可以适应更广泛的奖励,以量化生成的图像质量。