Spark SQL 整体介绍

一. 简介
二. 架构
1. 核心
sparksession rdd sparkcontext sparksql sqlcontent dstream streammingcontext hivesql hivecontext
sparksql->Catalyst hive->Calcite
2. 关系数据库中sql执行流程
那么在关系数据库中,当我们写完一个查询语句进行执行时,发生的过程如下: 整个执行流程是:query -> Parse -> Bind -> Optimize -> Execute
1、写完sql查询语句,sql的查询引擎首先把我们的查询语句进行解析,也就是Parse过程,解析的过程是把我们写的查询语句进行分割,把project,DataSource和Filter三个部分解析出来从而形成一个逻辑解析tree,在解析的过程中还会检查我们的sql语法是否有错误,比如缺少指标字段、数据库中不包含这张数据表等。当发现有错误时立即停止解析,并报错。当顺利完成解析时,会进入到Bind过程。
2、Bind过程,通过单词我们可看出,这个过程是一个绑定的过程。为什么需要绑定过程?这个问题需要我们从软件实现的角度去思考,如果让我们来实现这个sql查询引擎,我们应该怎么做?他们采用的策略是首先把sql查询语句分割,分割不同的部分,再进行解析从而形成逻辑解析tree,然后需要知道我们需要取数据的数据表在哪里,需要哪些字段,执行什么逻辑,这些都保存在数据库的数据字典中,因此bind过程,其实就是把Parse过程后形成的逻辑解析tree,与数据库的数据字典绑定的过程。绑定后会形成一个执行tree,从而让程序知道表在哪里,需要什么字段等等
3、完成了Bind过程后,数据库查询引擎会提供几个查询执行计划,并且给出了查询执行计划的一些统计信息,既然提供了几个执行计划,那么有比较就有优劣,数据库会根据这些执行计划的统计信息选择一个最优的执行计划,因此这个过程是Optimize(优化)过程。
4、选择了一个最优的执行计划,那么就剩下最后一步执行Execute,最后执行的过程和我们解析的过程是不一样的,当我们知道执行的顺序,对我们以后写sql以及优化都是有很大的帮助的.执行查询后,他是先执行where部分,然后找到数据源之数据表,最后生成select的部分,我们的最终结果。执行的顺序是:operation->DataSource->Result
虽然以上部分对sparkSQL没有什么联系,但是知道这些,对我们理解sparkSQL还是很有帮助的。
3. Catalyst流程解析
Sql -> Unresolved Logical Plan -> Logical Plan -> Optimized LogicalPlan -> Physical Plan -> executed Physical Plan -> RDD (Antlr4) (analyzer|catalog) (optimizer) (SparkPlan) (prepareForExecution) (execute)
3.1 主要流程大概可以分为以下几步: Sql语句经过Antlr4解析,生成Unresolved Logical Plan(有使用过Antlr4的童鞋肯定对这一过程不陌生) analyzer与catalog进行绑定(catlog存储元数据),生成Logical Plan; optimizer对Logical Plan优化,生成Optimized LogicalPlan; SparkPlan将Optimized LogicalPlan转换成 Physical Plan; prepareForExecution()将 Physical Plan 转换成 executed Physical Plan; execute()执行可执行物理计划,得到RDD;
4. Spark SQL核心—Catalyst查询编译器
Spark SQL的核心是一个叫做Catalyst的查询编译器,它将用户程序中的SQL/Dataset/DataFrame经过一系列操作,最终转化为Spark系统中执行的RDD。
sparksql catalyst 框架.png
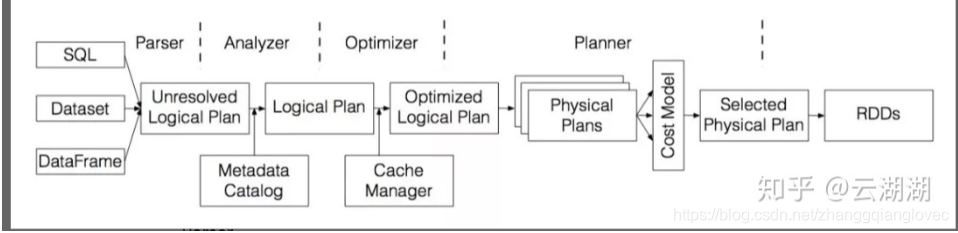
Parser 兼容ANSI SQL 2003标准和HiveQL。将SQL/Dataset/DataFrame转化成一棵未经解析(Unresolved)的树,在Spark中称为逻辑计划(Logical Plan),它是用户程序的一种抽象。
Analyzer 利用目录(Catalog)中的信息,对Parser中生成的树进行解析。Analyzer有一系列规则(Rule)组成,每个规则负责某项检查或者转换操作,如解析SQL中的表名、列名,同时判断它们是否存在。通过Analyzer,我们可以得到解析后的逻辑计划。
Optimizer 对解析完的逻辑计划进行树结构的优化,以获得更高的执行效率。优化过程也是通过一系列的规则来完成,常用的规则如谓词下推(Predicate Pushdown)、列裁剪(Column Pruning)、连接重排序(Join Reordering)等。此外,Spark SQL中还有一个基于成本的优化器(Cost-based Optmizer),是由DLI内部开发并贡献给开源社区的重要组件。该优化器可以基于数据分布情况,自动生成最优的计划。
Planner 将优化后的逻辑计划转化成物理执行计划(Physical Plan)。由一系列的策略(Strategy)组成,每个策略将某个逻辑算子转化成对应的物理执行算子,并最终变成RDD的具体操作。注意在转化过程中,一个逻辑算子可能对应多个物理算子的实现,如join可以实现成SortMergeJoin或者BroadcastHashJoin,这时候需要基于成本模型(Cost Model)来选择较优的算子。上面提到的基于成本的优化器在这个选择过程中也能起到关键的作用。
经过上述的一整个流程,就完成了从用户编写的SQL语句(或DataFrame/Dataset),到Spark内部RDD的具体操作逻辑的转化。 整个Catalyst框架拥有良好的可扩展性,开发者可以根据不同的需求,灵活地添加自己的语法、解析规则、优化规则和转换策略。
参考学习:https://zhuanlan.zhihu.com/p/58428916
5. Spark SQL运行架构
sparksql 整体模块.png
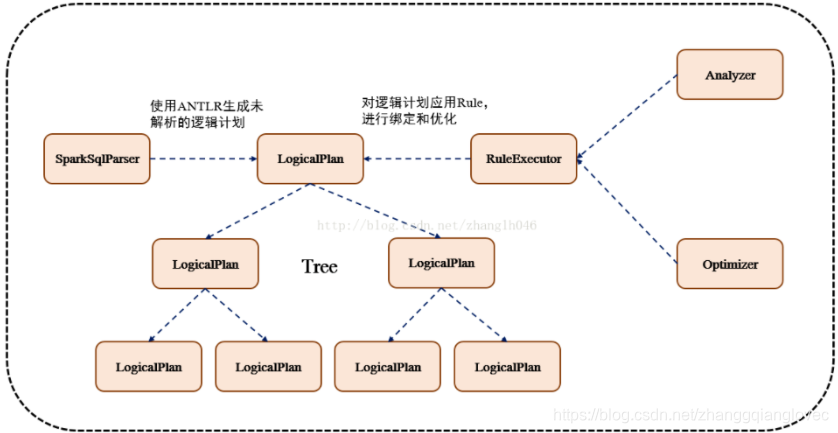
TreeNode 逻辑计划、表达式等都可以用tree来表示,它只是在内存中维护,并不会进行磁盘的持久化,分析器和优化器对树的修改只是替换已有节点。
TreeNode有2个直接子类,QueryPlan和Expression。QueryPlam下又有LogicalPlan和SparkPlan. Expression是表达式体系,不需要执行引擎计算而是可以直接处理或者计算的节点,包括投影操作,操作符运算等
Rule & RuleExecutor Rule就是指对逻辑计划要应用的规则,以到达绑定和优化。他的实现类就是RuleExecutor。优化器和分析器都需要继承RuleExecutor。每一个子类中都会定义Batch、Once、FixPoint. 其中每一个Batch代表着一套规则,Once表示对树进行一次操作,FixPoint表示对树进行多次的迭代操作。RuleExecutor内部提供一个Seq[Batch]属性,里面定义的是RuleExecutor的处理逻辑,具体的处理逻辑由具体的Rule子类实现。
6. 流程架构
sparksql 流程架构图.png
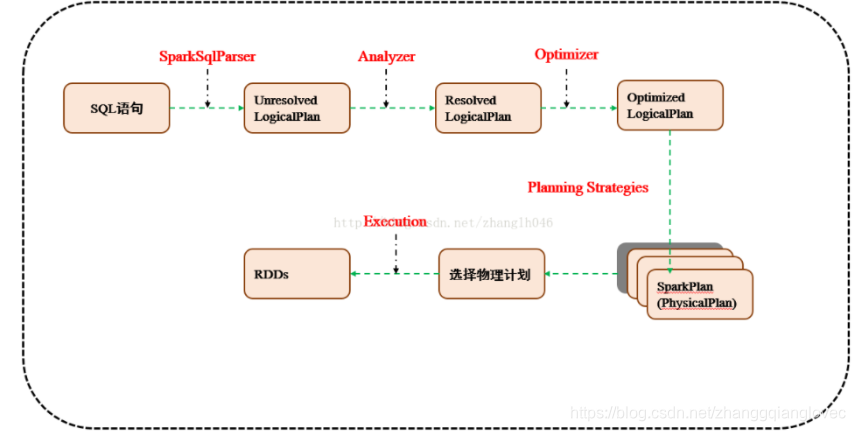
2.1 使用SessionCatalog保存元数据 在解析SQL语句之前,会创建SparkSession,或者如果是2.0之前的版本初始化SQLContext,SparkSession只是封装了SparkContext和SQLContext的创建而已。会把元数据保存在SessionCatalog中,涉及到表名,字段名称和字段类型。创建临时表或者视图,其实就会往SessionCatalog注册
2.2 解析SQL,使用ANTLR生成未绑定的逻辑计划 当调用SparkSession的sql或者SQLContext的sql方法,我们以2.0为准,就会使用SparkSqlParser进行解析SQL. 使用的ANTLR进行词法解析和语法解析。它分为2个步骤来生成Unresolved LogicalPlan: 1.词法分析:Lexical Analysis,负责将token分组成符号类 2.构建一个分析树或者语法树AST
2.3 使用分析器Analyzer绑定逻辑计划 在该阶段,Analyzer会使用Analyzer Rules,并结合SessionCatalog,对未绑定的逻辑计划进行解析,生成已绑定的逻辑计划。
2.4 使用优化器Optimizer优化逻辑计划 优化器也是会定义一套Rules,利用这些Rule对逻辑计划和Exepression进行迭代处理,从而使得树的节点进行和并和优化
2.5 使用SparkPlanner生成物理计划 SparkSpanner使用Planning Strategies,对优化后的逻辑计划进行转换,生成可以执行的物理计划SparkPlan.
2.6 使用QueryExecution执行物理计划 此时调用SparkPlan的execute方法,底层其实已经再触发JOB了,然后返回RDD
参考学习: https://blog.csdn.net/zhanglh046/article/details/78505038 ***
7. HiveContext 和 Spark Sql Content 执行流程比较
sparksql 执行流程图
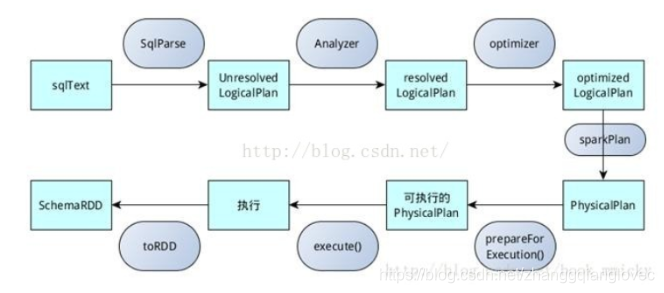
sqlContext总的一个过程如下图所示
1.SQL语句经过SqlParse解析成UnresolvedLogicalPlan; 2.使用analyzer结合数据数据字典(catalog)进行绑定,生成resolvedLogicalPlan; 3.使用optimizer对resolvedLogicalPlan进行优化,生成optimizedLogicalPlan; 4.使用SparkPlan将LogicalPlan转换成PhysicalPlan; 5.使用prepareForExecution()将PhysicalPlan转换成可执行物理计划; 6.使用execute()执行可执行物理计划; 7.生成SchemaRDD。 在整个运行过程中涉及到多个SparkSQL的组件,如SqlParse、analyzer、optimizer、SparkPlan等等
hiveContext总的一个过程如下图所示 1.SQL语句经过HiveQl.parseSql解析成Unresolved LogicalPlan,在这个解析过程中对hiveql语句使用getAst()获取AST树,然后再进行解析; 2.使用analyzer结合数据hive源数据Metastore(新的catalog)进行绑定,生成resolved LogicalPlan; 3.使用optimizer对resolved LogicalPlan进行优化,生成optimized LogicalPlan,优化前使用了ExtractPythonUdfs(catalog.PreInsertionCasts(catalog.CreateTables(analyzed)))进行预处理; 4.使用hivePlanner将LogicalPlan转换成PhysicalPlan; 5.使用prepareForExecution()将PhysicalPlan转换成可执行物理计划; 6.使用execute()执行可执行物理计划; 7.执行后,使用map(_.copy)将结果导入SchemaRDD。
参考: https://blog.51cto.com/9269309/1845525 ***
8. thriftserver 的优势
spark-shell、spark-sql 都是是一个独立的 spark application,启动几个就要几个application,非常耗资源 用thriftserver,无论启动多少个客户端(beeline)连接在一个thriftserver,是一个独立的spark application, 后面不用在重新申请资源。前一个beeline缓存的,下一个beeline也可以用, 用thriftserver,可在ui看执行计划,优化有优势
9. sparksql 执行全过程概述
sparksql 转换步骤
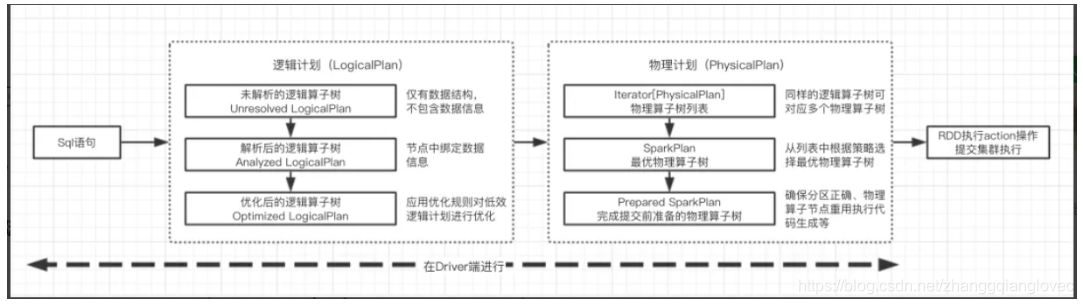
sparksql treenode 体系
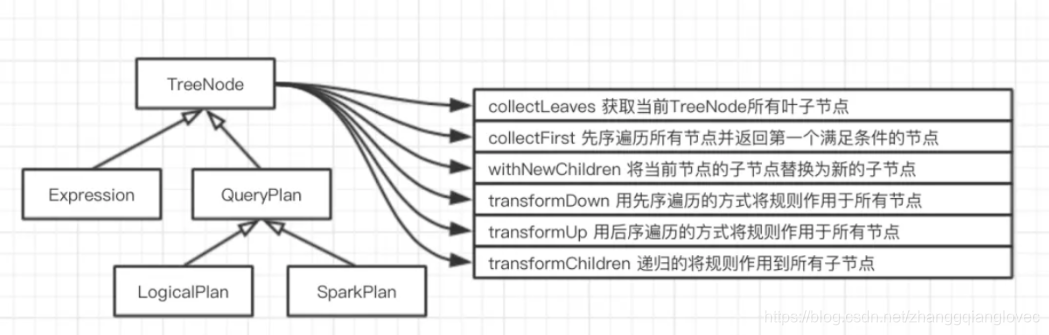
Expression是Catalyst的表达式体系 QueryPlan下包含逻辑算子树和物理执行算子树两个子类
sparksql Expression体系
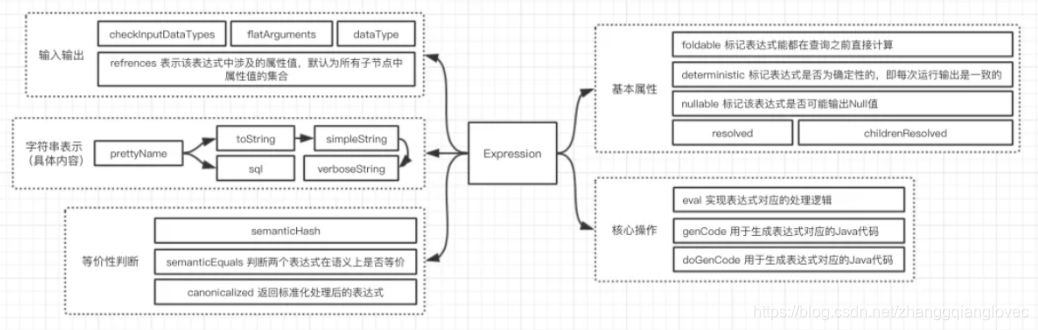
三. 其他
0. 参考
https://my.oschina.net/wangzhiwubigdata/blog/4392485 ***** https://www.debug8.com/java/t_43884.html ***
1. 注意
spark sql 可以跨数据源进行join,例如hdfs与mysql里表内容join Spark SQL运行可以不用hive,只要你连接到hive的metastore就可以
2. 问题
- 通过文件导数据到hive,默认分割时什么? |
- sql函数的返回值是什么类型? item的类型是什么? DataFrame Row
- dataframe 与dataset 怎么转换? dataframe.map()…
- 怎么通过数据集创建dataframe? spark.createDataFrame((1 to 100).map(i => Record(i, s"val_$i"))) Record 为case class
- hive文件存储格式包含几类? 区别是啥? 默认文件格式? textfile
- 如何创建外部表? create external table…
- SparkSQL 四大特性
- DataFrame与RDD的比较?
- DataFrame的构建的几种方式
- case class A??
- Spark de shuffer 机制? 俩中shuffer机制: 1.2 普通机制的Hash shuffle 原理/之后 合并机制的Hash Shuffle 原理