使用C++ STL库统计一散文中单词出现次数和行号
使用C++ STL库统计一散文中单词出现次数和行号

在开发过程中经常会遇到文件处理的情形,例如统计一篇文章单词的数量、行数、出现频率最高的几个单词等等。这篇文章主要通过C++来解析一篇文章,实现每个单词(不区分大小写)出现的总次数和出现的行号的统计。
1 演示程序
文件处理能比较好地考验对开发语言基础技能的掌握能力,因为这需要去考虑数据的读取、数据的存储方式、数据的处理等等,可能不同的处理方法会得到不同的效率和结果。
下面的代码主要是使用C++的STL库解析一篇英文散文(网上看到不错就wget下来了),涉及的编程基本点如下:
1、STL容器中的map和vector容器;
2、ifstream库文件流的操作;
3、string的分割查找find、获取子串substr、去除非法字符等待;
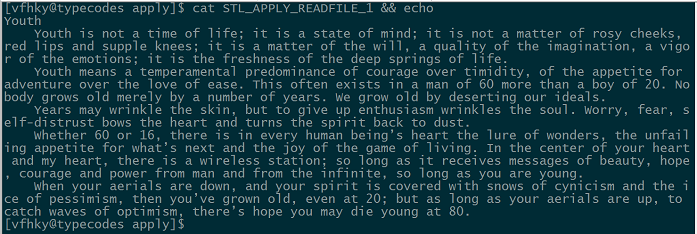
4、c++中的基本知识点:构造函数(包括常量的初始化)、引用、对象的构造和析构等等。文章内容如上图所示,下面直接呈上代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 | /** * @FileName stl_apply_readfile_1.cpp * @Describe A simple example for using c++ STL to calculate words and line numbers in an article. * @Author vfhky 2017-04-16 16:44 https://typecodes.com/cseries/stlcalcarticlewordlines1.html * @Compile g++ stl_apply_readfile_1.cpp -o stl_apply_readfile_1 */ #include <iostream> #include <map> #include <vector> #include <fstream> #include <algorithm> #include <string> #include <assert.h> #include <string.h> using namespace std; class CFileHandle { public: CFileHandle( const string &s_file_name ) : s_m_file_name(s_file_name) { i_m_line_number = 0; } //读取每行的数据,然后进行处理 void ReadFile( const string &s_file_name ) { ifstream inFile; //以二进制可读的方式打开文件,也可以使用: inFile.open( s_file_name.data() ); inFile.open( s_file_name.c_str(), ios::in | ios::binary ); //Checks if the file stream has an associated file. assert( inFile.is_open() ); //每一行的数据 string s_line_buf; //读取一行内容 getline( inFile, s_line_buf ) while( getline( inFile, s_line_buf, inFile.widen('\n') ) ) { ++i_m_line_number; //统一转换成大写:也可以使用 transform( s_line_buf.begin(), s_line_buf.end(), s_line_buf.begin(), ::toupper ); transform( s_line_buf.begin(), s_line_buf.end(), s_line_buf.begin(), (int (*)(int))toupper ); //开始数据处理 HandleLine( s_line_buf ); } //关闭文件流 inFile.close(); } //对每行的数据进行解析 void HandleLine( const string &s_line_buf ) { string s_word_buf; int i_start=0, i_last=s_line_buf.size(); //std::size_t i_split_pos; int i_split_pos = 0; while( i_start < i_last ) { i_split_pos = s_line_buf.find( ' ', i_start ); string s_word; //if( i_split_pos == std::string::npos ) if( i_split_pos == -1 ) { s_word = s_line_buf.substr( i_start, i_last ); HandleUnkind( s_word ); HandleWord( s_word ); break; } /** 避免空格,也可以使用下面这两行来去掉行首和行尾的空格 s_line_buf.erase( 0, s_line_buf.find_first_not_of(" ") ); s_line_buf.erase( s_line_buf.find_last_not_of(" ") + 1 ); */ else if( i_start != i_split_pos ) { s_word = s_line_buf.substr( i_start, i_split_pos-i_start ); HandleUnkind( s_word ); HandleWord( s_word ); i_start = i_split_pos + 1; } //对于行首的空格不进行处理 else { i_start = i_split_pos + 1; } } } //去除每个单词可能包含的非字符(除0~9和A~Z外的数据) void HandleUnkind( string &s_word_buf ) { assert( s_word_buf.size() ); //char c_word_bufs_word_buf.size()+1; 在vs中会报错:error C2131: 表达式的计算结果不是常数 char *c_word_buf = new chars_word_buf.size()+1; unsigned int j = 0; for( unsigned int i=0; i<s_word_buf.size(); ++i ) { if( ( s_word_bufi >= 0x30 && s_word_bufi <= 0x39 ) || ( s_word_bufi >= 0x41 && s_word_bufi <= 0x5A ) ) { c_word_bufj++ = s_word_bufi; } } s_word_buf = c_word_buf; delete c_word_buf; } //对每个单词的处理 void HandleWord( const string &s_word_buf ) { map<string, vector<int> >::iterator mapit = mapobj.find( s_word_buf ); //如果该单词不存在 if( mapit == mapobj.end() ) { vector<int> vect; vect.push_back( i_m_line_number ); mapobj.insert( make_pair( s_word_buf, vect ) ); } else { mapit->second.push_back( i_m_line_number ); } } //遍历map对象 void Traverse() { map< string, vector<int> >::iterator mapit = mapobj.begin(); cout << "Words\t\t\t\tCounts\t\t\t\tLines" << endl; cout << "---------------------------------------------------------------------" << endl; for( ; mapit != mapobj.end(); ++mapit ) { cout << mapit->first << "\t\t\t\t" << mapit->second.size() << "\t\t\t\t"; for( vector<int>::iterator vectorit = mapit->second.begin(); vectorit != mapit->second.end(); ++vectorit ) { cout << *vectorit << " "; } cout << endl; } } //获取文件总行数 const unsigned int GetTotalLines() const { return i_m_line_number; } private: map<string, vector<int> > mapobj; unsigned int i_m_line_number; const string s_m_file_name; }; int main( int argc, char **argv ) { //文件所在路径 const string s_file_name = "STL_APPLY_READFILE_1"; CFileHandle *pCFileHandle = new CFileHandle( s_file_name ); //开始处理文件 pCFileHandle->ReadFile( s_file_name ); //打印总行数 cout << "" << __FILE__ << ":" << __LINE__ << " Total Lines=" << pCFileHandle->GetTotalLines() << "." << endl; //遍历结果 pCFileHandle->Traverse(); delete pCFileHandle; return 0; } |
|---|
2 使用g++编译器进行编译并执行
使用g++或者之前写的这个Makefile文件进行编译,结果如下图所示。

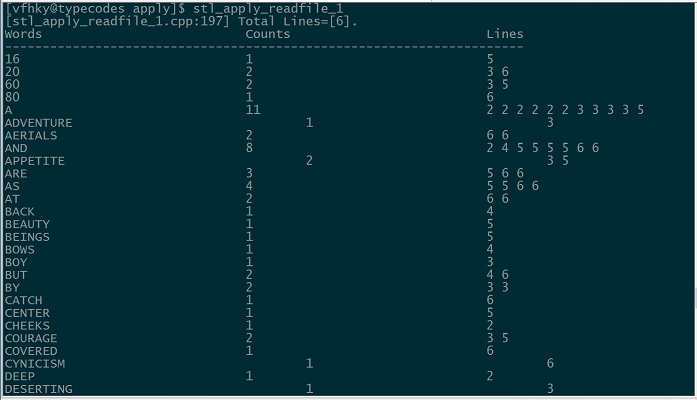
接着执行程序stl_apply_readfile_1,效果如下图所示(图片大小的限制只显示了一部分结果)。另外,上面C++程序中的数据处理函数HandleUnkind相对比较粗略:只简单过滤了非数字和字母的字符。这样会出现类似把YOU'R这样的数据处理成YOUR的情况,大家可以进行代码改进做更精细化的处理。