深度学习500问——Chapter05: 卷积神经网络(CNN)(2)
深度学习500问——Chapter05: 卷积神经网络(CNN)(2)

5.6 有哪些池化方法
池化操作通常也叫做子采样(Subsampling)或降采样(Downsampling),在构建卷积神经网络时,往往会用在卷积层之后,通过池化来降低卷积层输出的特征维度,有效减少网络参数的同时还可以防止过拟合现象。池化操作可以降低图像维度的原因,本质上是因为图像具有一种“静态性”的属性,这个意思是说在一个图像区域有用的特征极有可能在另一个区域同样有用。因此,为了描述一个大的图像,很直观的想法就是对不同位置的特征进行聚合统计。例如,可以计算图像在固定区域特征上的平均值(或最大值)来代表这个区域的特征。
表5.6 池化分类
池化类型 | 示意图 | 作用 |
|---|---|---|
一般池化(General Pooling) | 通常包括最大池化(Max Pooling)和平均池化(Mean Pooling)。以最大池化为例,池化范围和滑窗步长相同,仅提取一次相同区域的范化特征。 | |
重叠池化(Overlapping Pooling) | 与一般池化操作相同,但是池化范围与滑窗步长关系为,同一区域内的像素特征可以参与多次滑窗提取,得到的特征表达能力更强,但计算量更大。 | |
空间金字塔池化^*(Spatial Pyramid Pooling) | 在进行多尺度目标的训练时,卷积层允许输入的图像特征尺度是可变的,紧接的池化层若采用一般的池化方法会使得不同的输入特征输出相应变化尺度的特征,而卷积神经网络中最后的全连接层则无法对可变尺度进行运算,因此需要对不同尺度的输出特征采样到相同输出尺度。 |

SPPNet[3]就引入了空间池化的组合,对不同输出尺度采用不同的滑窗大小和步长以确保输出尺度相同
,同时用如金字塔式叠加的多种池化尺度组合,以提取更加丰富的图像特征。常用于多尺度训练和目标检测中的区域提议网络(Region Proposal Network)的兴趣区域(Region of Interest)提取。
5.7 1x1卷积作用
NIN(Network in Network)[4]是第一篇探索
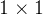
卷积核的论文,这篇论文通过在卷积层中使用MLP替代传统线性的卷积核,使单层卷积层内具有非线性映射的能力,也因其网络结构中嵌套MLP子网络而得名NIN。NIN对不同通道的特征整合到MLP自网络中,让不同通道的特征能够交互整合,使通道之间的信息得以流通,其中的MLP子网络恰恰可以用
的卷积进行代替。
GoogLeNet[5]则采用
卷积核来减少模型的参数量。在原始版本的Inception模块中,由于每一层网络采用了更多的卷积核,大大增加了模型的参数量。此时在每一个较大卷积核的卷积层前引入
卷积,可以通过分离通道与宽高卷积来减少模型参数量。
以图5.2为例,在不考虑参数偏置项的情况下,若输入和输出的通道数为
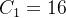
,则左半边网络模块所需的参数为:
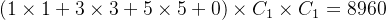
;假定右半边网络模块采用的
卷积通道数为
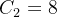
(满足
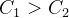
),则右半部分的网络结构所需参数量为:
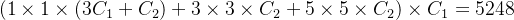
,可以在不改变模型表达能力的前提下大大减少所使用的参数量。
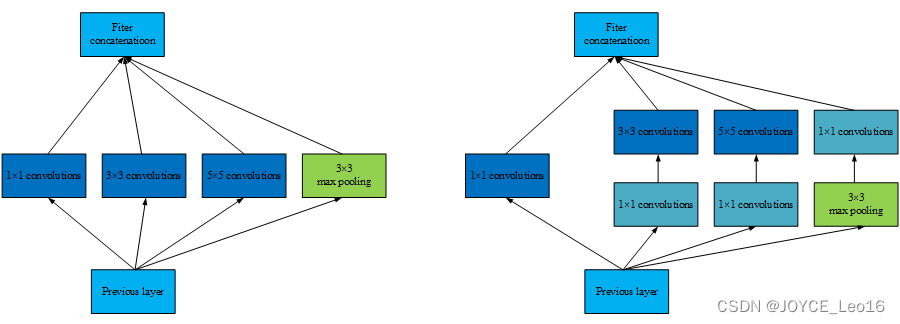
图5.2 Inception模块
综上所述,
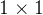
卷积的作用主要为以下两点:
- 实现信息的跨通道交互和整合;
- 对卷积核通道数进行降维和升维,减小参数量。
5.8 卷积层和池化层有什么区别
卷积层和池化层在结构上具有一定的相似性,都是对感受域内的特征进行提取,并且根据步长设置获取到不同维度的输出,但是其内在操作是有本质区别的,如表5.7所示。
卷积层 | 池化层 | |
|---|---|---|
结构 | 零填充时输出维度不变,而通道数改变 | 通常特征维度会降低,通道数不变 |
稳定性 | 输入特征发生细微改变时,输出结果会改变 | 感受域内的细微变化不影响输出结果 |
作用 | 感受域内提取局部关联特征 | 感受域内提取泛化特征,降低维度 |
参数量 | 与卷积核尺寸、卷积核个数相关 | 不引入额外参 |
5.9 卷积核是否一定越大越好
在早期的卷积神经网络中(如LeNet-5、AlexNet),用到了一些较大的卷积核(
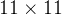
和
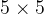
),受限于当时的计算能力和模型结构的设计,无法将网络叠加的很深,因此卷积网络中的卷积层需要设置较大的卷积核以获取更大的感受域。但是这种大卷积核反而会导致计算量大幅增加,不利于训练更深层的模型,相应的计算性能也会降低。后来的卷积神经网络(VGG、GoogLeNet等),发现通过堆叠2个
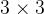
卷积核可以获得与
的卷积核相同的感受野,同时参数量会更少(
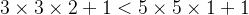
),
卷积核被广泛应用于许多卷积神经网络中。因此可以认为,在大多数情况下通过堆叠较小的卷积核比直接采用单个更大的卷积核会更加有效。
但是,这并不是表示更大的卷积核就没有作用,在某些领域应用卷积神经网络时仍然可以采用较大的卷积核。譬如在自然语言处理领域,由于文本内容不像图像数据可以对特征进行很深层的抽象,往往在该领域的特征提取只需要较浅层的神经网络即可。在将卷积神经网络应用在自然语言处理领域时,通常都是较为浅层的卷积层组成,但是文本特征有时又需要有较广的感受域让模型能够组合更多的特征(如词组和字符),此时直接采用较大的卷积核将是更好的选择。
综上所述,卷积核的大小并没有绝对的优劣,需要视具体的应用场景而定,但是极大和极小的卷积核都是不合适的,单独的
极小卷积核只能用作分离卷积而不能对输入的原始特征进行有效的组合,极大的卷积核通常会组合过多的无意义特征从而浪费了大量的计算资源。
5.10 每层卷积是否只能用一种尺寸的卷积核
经典的神经网络一般都属于层叠式网络,每层仅用一个尺寸的卷积核,如VGG结构中使用了大量的
卷积层。事实上,同一层特征图可以分别使用多个不同尺寸的卷积核,以获得不同尺度的特征,再把这些特征结合起来,得到的特征往往比使用单一卷积核的要好,如GoogLeNet、Inception系列的网络,均是每层使用了多个卷积核的结构。如图5.3所示,输入的特征在同一层分别经过
、
和
三种不同尺寸的卷积核,再将分别得到的特征进行整合,得到的新特征可以看作不同感受域提取的特征组合,相比于单一卷积核会有更强的表达能力。
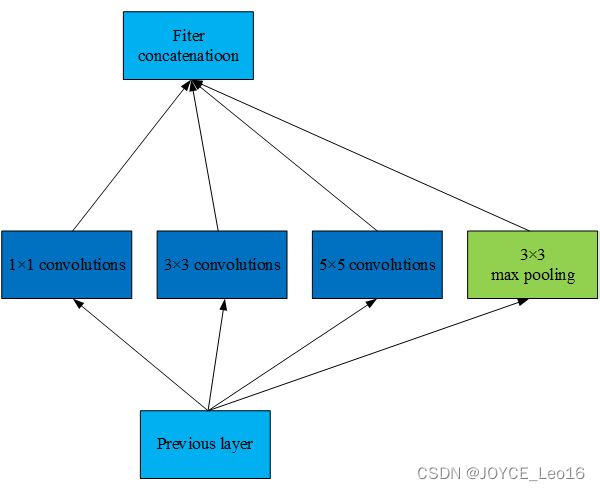
图5.3 Inception模块结构
5.11 怎样才能减少卷积层参数量
- 减少卷积层参数量的方法可以简要地归为以下几点:
- 使用堆叠小卷积核代替大卷积核:VGG网络中2个
的卷积核可以代替一个
的卷积核。
- 使用分离卷积操作:将原本
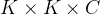
的卷积操作分离为
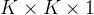
和
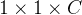
的两部分操作。
- 添加
的卷积操作:与分离卷积类似,但是通道数可变,在
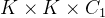
卷积前添加
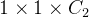
的卷积核(满足
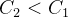
)。
- 在卷积层前使用池化操作:池化可以降低卷积层的输入特征维度。
5.12 在进行卷积操作时,必须同时考虑通道和区域吗
标准卷积中,采用区域与通道同时处理的操作,如下图所示:

这样做可以简化卷积层内部的结构,每一个输出的特征像素都由所有通道的同一个区域提取而来。
但是这种方式缺乏灵活性,并且在深层的网络结构中使得运算变得相对低效,更为灵活的方式是使区域和通道的卷积分离开来,通道分离(深度分离)卷积网络由此诞生。如下图所示,Xception网络可解决上述问题。

我们首先对每一个通道进行各自的卷积操作,有多少个通道就有多少个过滤器。得到新的通道特征矩阵之后,再对这批通道特征进行标准的
跨通道卷积操作。
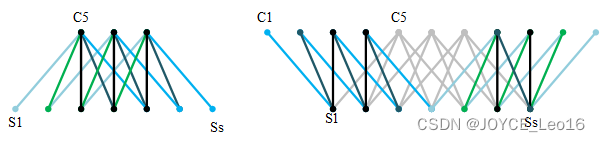
5.13 采用宽卷积的好处有什么
宽卷积对应是窄卷积,实际上并不是卷积操作的类型,指的是卷积过程中的填充方法,对应的是“SAME”填充和“VALID”填充。“SAME”填充通常采用零填充的方式对卷积核不满足整除条件的输入特征进行补全,以使卷积层的输出维度保持与输入特征维度一致;“VALID”填充的方式则相反,实际并不进行任何填充,在输入特征边缘位置若不足以进行卷积操作,则对边缘信息进行舍弃,因此在步长为1的情况下该填充方式的卷积层输出特征维度可能会略小于输入特征的维度。此外,由于前一种方式通过补零来进行完整的卷积操作,可以有效地保留原始的输入特征信息。
比如下图左部分的窄卷积。注意到越在边缘的位置被卷积的次数越少。宽卷积可以看作在卷积之前在边缘用0补充,常见的有两种情况,一个是全补充,如下图右部分,这样输出大于输入的维度。另一种常用的方法是补充一部分0值,使得输出核输入的维度一致。