字节都到三面了,结果还是凉了。。。

大家好,我是小林。
今天给大家分享一个校招同学字节后端一二三面的面经,同学顺利通过一二面,可惜最后一轮三面的时候挂了。
一二面八股比较多,三面主要问项目去了,可惜没稳住,能走到三面已经很不容易了,字节每一轮都有算法,面试强度还是比较大的。
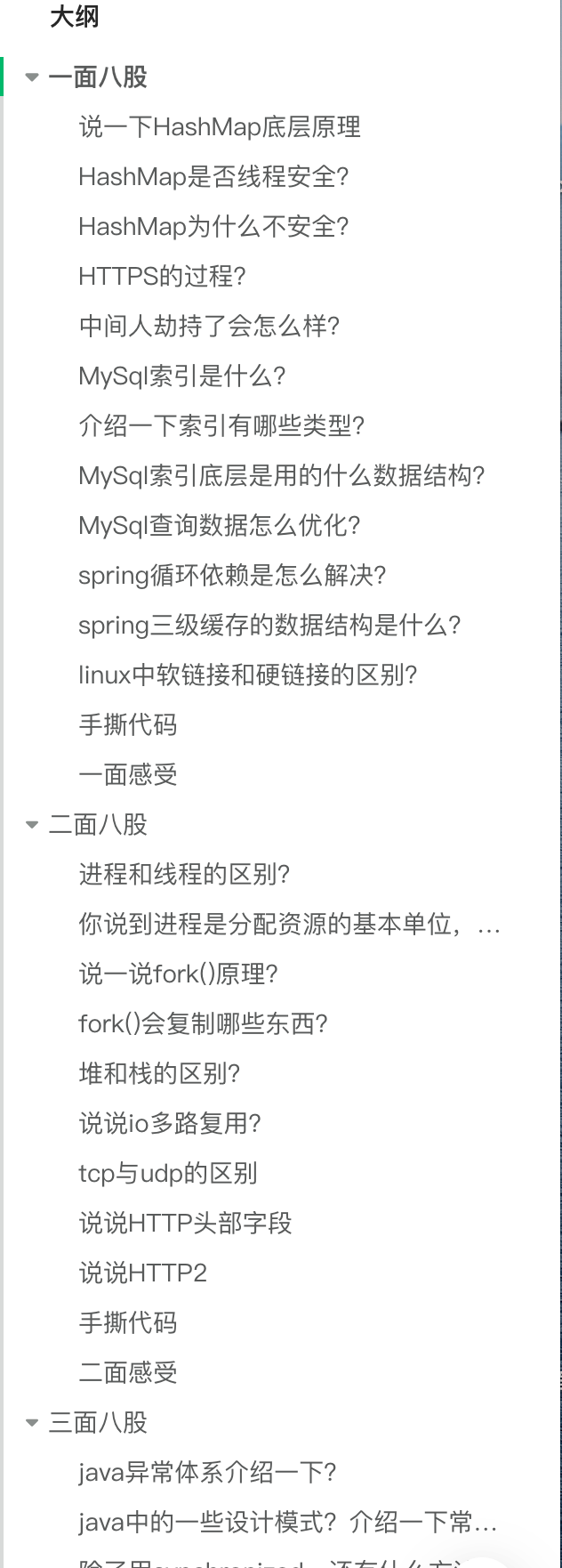
我把这一二三面考察的知识点给大家罗列了 一下,可以很清晰看到,哪些知识点是重要的:
- Java:HashMap、异常、spring 循环依赖、设计模式、synchronized
- mysql:索引、SQL优化、b+树
- 操作系统:进程线程、软链接和硬链接、io 多路复用、fork原理、堆栈区别
- 网络:tcp 和 udp、https 握手、http2、断点续传、头部字段
- 手撕:算法(每一面都有)、单例模式(三面出现)
一面八股
说一下HashMap底层原理
从 JDK 1.7 和 JDK 1.8 版本区别回答:
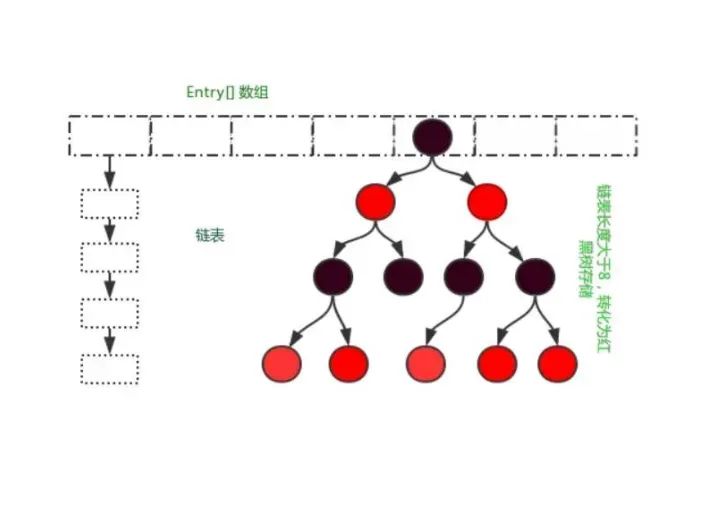
- 在 JDK 1.7 版本之前, HashMap 数据结构是数组和链表,HashMap通过哈希算法将元素的键(Key)映射到数组中的槽位(Bucket)。如果多个键映射到同一个槽位,它们会以链表的形式存储在同一个槽位上,因为链表的查询时间是O(n),所以冲突很严重,一个索引上的链表非常长,效率就很低了。
- 所以在 JDK 1.8 版本的时候做了优化,当一个链表的长度超过8的时候就转换数据结构,不再使用链表存储,而是使用红黑树,查找时使用红黑树,时间复杂度O(log n),可以提高查询性能,但是在数量较少时,即数量小于6时,会将红黑树转换回链表。
HashMap是否线程安全?
不是线程安全的,如果要保证线程安全,可以通过这些方法来保证:
- 使用同步代码块(synchronized)或同步方法来保护共享资源,确保在同一时刻只有一个线程访问。
- 使用线程安全的集合类,如ConcurrentHashMap、CopyOnWriteArrayList等。
- 使用Lock接口及其实现类(如ReentrantLock)来进行线程同步
- 使用ThreadLocal来保证每个线程都有自己独立的变量副本
HashMap为什么不安全?
- JDK 1.7 HashMap 采用数组 + 链表的数据结构,多线程背景下,在数组扩容的时候,存在 Entry 链死循环和数据丢失问题。
- JDK 1.8 HashMap 采用数组 + 链表 + 红黑二叉树的数据结构,优化了 1.7 中数组扩容的方案,解决了 Entry 链死循环和数据丢失问题。但是多线程背景下,put 方法存在数据覆盖的问题。
HTTPS的过程?
传统的 TLS 握手基本都是使用 RSA 算法来实现密钥交换的,在将 TLS 证书部署服务端时,证书文件其实就是服务端的公钥,会在 TLS 握手阶段传递给客户端,而服务端的私钥则一直留在服务端,一定要确保私钥不能被窃取。
在 RSA 密钥协商算法中,客户端会生成随机密钥,并使用服务端的公钥加密后再传给服务端。根据非对称加密算法,公钥加密的消息仅能通过私钥解密,这样服务端解密后,双方就得到了相同的密钥,再用它加密应用消息。
我用 Wireshark 工具抓了用 RSA 密钥交换的 TLS 握手过程,你可以从下面看到,一共经历了四次握手:


TLS 第一次握手
首先,由客户端向服务器发起加密通信请求,也就是 ClientHello 请求。在这一步,客户端主要向服务器发送以下信息:
- (1)客户端支持的 TLS 协议版本,如 TLS 1.2 版本。
- (2)客户端生产的随机数(Client Random),后面用于生成「会话秘钥」条件之一。
- (3)客户端支持的密码套件列表,如 RSA 加密算法。
TLS 第二次握手
服务器收到客户端请求后,向客户端发出响应,也就是 SeverHello。服务器回应的内容有如下内容:
- (1)确认 TLS 协议版本,如果浏览器不支持,则关闭加密通信。
- (2)服务器生产的随机数(Server Random),也是后面用于生产「会话秘钥」条件之一。
- (3)确认的密码套件列表,如 RSA 加密算法。(4)服务器的数字证书。
TLS 第三次握手
客户端收到服务器的回应之后,首先通过浏览器或者操作系统中的 CA 公钥,确认服务器的数字证书的真实性。
如果证书没有问题,客户端会从数字证书中取出服务器的公钥,然后使用它加密报文,向服务器发送如下信息:
- (1)一个随机数(pre-master key)。该随机数会被服务器公钥加密。
- (2)加密通信算法改变通知,表示随后的信息都将用「会话秘钥」加密通信。
- (3)客户端握手结束通知,表示客户端的握手阶段已经结束。这一项同时把之前所有内容的发生的数据做个摘要,用来供服务端校验。
上面第一项的随机数是整个握手阶段的第三个随机数,会发给服务端,所以这个随机数客户端和服务端都是一样的。
服务器和客户端有了这三个随机数(Client Random、Server Random、pre-master key),接着就用双方协商的加密算法,各自生成本次通信的「会话秘钥」。
TLS 第四次握手
服务器收到客户端的第三个随机数(pre-master key)之后,通过协商的加密算法,计算出本次通信的「会话秘钥」。
然后,向客户端发送最后的信息:
- (1)加密通信算法改变通知,表示随后的信息都将用「会话秘钥」加密通信。
- (2)服务器握手结束通知,表示服务器的握手阶段已经结束。这一项同时把之前所有内容的发生的数据做个摘要,用来供客户端校验。
至此,整个 TLS 的握手阶段全部结束。接下来,客户端与服务器进入加密通信,就完全是使用普通的 HTTP 协议,只不过用「会话秘钥」加密内容。
中间人劫持了会怎么样?
客户端通过浏览器向服务端发起 HTTPS 请求时,被「假基站」转发到了一个「中间人服务器」,于是客户端是和「中间人服务器」完成了 TLS 握手,然后这个「中间人服务器」再与真正的服务端完成 TLS 握手。
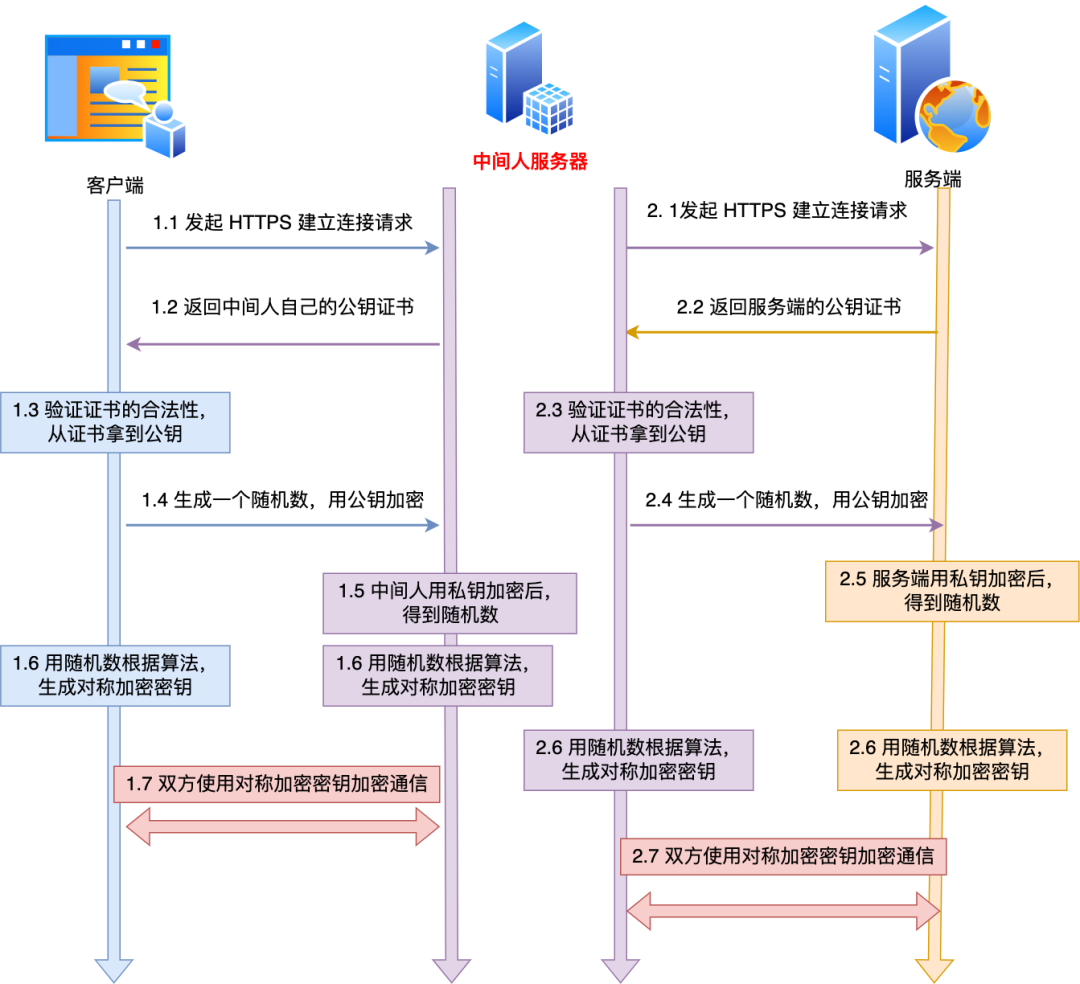
具体过程如下:
- 客户端向服务端发起 HTTPS 建立连接请求时,然后被「假基站」转发到了一个「中间人服务器」,接着中间人向服务端发起 HTTPS 建立连接请求,此时客户端与中间人进行 TLS 握手,中间人与服务端进行 TLS 握手;
- 在客户端与中间人进行 TLS 握手过程中,中间人会发送自己的公钥证书给客户端,客户端验证证书的真伪,然后从证书拿到公钥,并生成一个随机数,用公钥加密随机数发送给中间人,中间人使用私钥解密,得到随机数,此时双方都有随机数,然后通过算法生成对称加密密钥(A),后续客户端与中间人通信就用这个对称加密密钥来加密数据了。
- 在中间人与服务端进行 TLS 握手过程中,服务端会发送从 CA 机构签发的公钥证书给中间人,从证书拿到公钥,并生成一个随机数,用公钥加密随机数发送给服务端,服务端使用私钥解密,得到随机数,此时双方都有随机数,然后通过算法生成对称加密密钥(B),后续中间人与服务端通信就用这个对称加密密钥来加密数据了。
- 后续的通信过程中,中间人用对称加密密钥(A)解密客户端的 HTTPS 请求的数据,然后用对称加密密钥(B)加密 HTTPS 请求后,转发给服务端,接着服务端发送 HTTPS 响应数据给中间人,中间人用对称加密密钥(B)解密 HTTPS 响应数据,然后再用对称加密密钥(A)加密后,转发给客户端。
从客户端的角度看,其实并不知道网络中存在中间人服务器这个角色。那么中间人就可以解开浏览器发起的 HTTPS 请求里的数据,也可以解开服务端响应给浏览器的 HTTPS 响应数据。相当于,中间人能够 “偷看” 浏览器与服务端之间的 HTTPS 请求和响应的数据。
但是要发生这种场景是有前提的,前提是用户点击接受了中间人服务器的证书。
中间人服务器与客户端在 TLS 握手过程中,实际上发送了自己伪造的证书给浏览器,而这个伪造的证书是能被浏览器(客户端)识别出是非法的,于是就会提醒用户该证书存在问题。
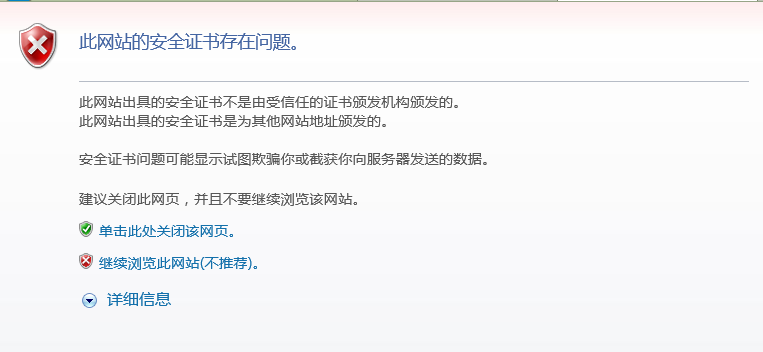
如果用户执意点击「继续浏览此网站」,相当于用户接受了中间人伪造的证书,那么后续整个 HTTPS 通信都能被中间人监听了。
MySql索引是什么?
MySQL索引是数据库表中的一种数据结构,可以提高数据检索的速度。
索引存储了指向表中数据的指针,这样数据库在查找数据时可以使用索引来快速定位到表中的特定行,而不必扫描整个表。使用索引可以显著提高查询的效率,特别是在处理大量数据时。
介绍一下索引有哪些类型?
可以按照四个角度来分类索引。
- 按「数据结构」分类:B+tree索引、Hash索引、Full-text索引。
- 按「物理存储」分类:聚簇索引(主键索引)、二级索引(辅助索引)。
- 按「字段特性」分类:主键索引、唯一索引、普通索引、前缀索引。
- 按「字段个数」分类:单列索引、联合索引。
MySql索引底层是用的什么数据结构?
从数据结构的角度来看,MySQL 常见索引有 B+Tree 索引、HASH 索引、Full-Text 索引。
每一种存储引擎支持的索引类型不一定相同,我在表中总结了 MySQL 常见的存储引擎 InnoDB、MyISAM 和 Memory 分别支持的索引类型。

InnoDB 是在 MySQL 5.5 之后成为默认的 MySQL 存储引擎,B+Tree 索引类型也是 MySQL 存储引擎采用最多的索引类型。
MySql查询数据怎么优化?
- 通过 explain 执行结果,查看 sql 是否走索引,如果不走索引,考虑增加索引。
- 可以通过建立联合索引,实现覆盖索引优化,减少回表
- 联合索引符合最左匹配原则,不然会索引失效
- 避免索引失效,比如不要用左模糊匹配、函数计算、表达式计算等等。
- 联表查询最好要以小表驱动大表,并且被驱动表的字段要有索引,当然最好通过冗余字段的设计,避免联表查询。
- 针对 limit n,y 深分页的查询优化,可以把Limit查询转换成某个位置的查询:select * from tb_sku where id>20000 limit 10;,该方案适用于主键自增的表,
- 将字段多的表分解成多个表,有些字段使用频率高,有些低,数据量大时,会由于使用频率低的存在而变慢,可以考虑分开
spring循环依赖是怎么解决?
循环依赖指的是两个类中的属性相互依赖对方:例如 A 类中有 B 属性,B 类中有 A属性,从而形成了一个依赖闭环,如下图。

循环依赖问题在Spring中主要有三种情况:
- 第一种:通过构造方法进行依赖注入时产生的循环依赖问题。
- 第二种:通过setter方法进行依赖注入且是在多例(原型)模式下产生的循环依赖问题。
- 第三种:通过setter方法进行依赖注入且是在单例模式下产生的循环依赖问题。
只有【第三种方式】的循环依赖问题被 Spring 解决了,其他两种方式在遇到循环依赖问题时,Spring都会产生异常。
Spring 解决单例模式下的setter循环依赖问题的主要方式是通过三级缓存解决循环依赖。三级缓存指的是 Spring 在创建 Bean 的过程中,通过三级缓存来缓存正在创建的 Bean,以及已经创建完成的 Bean 实例。具体步骤如下:
- 实例化 Bean:Spring 在实例化 Bean 时,会先创建一个空的 Bean 对象,并将其放入一级缓存中。
- 属性赋值:Spring 开始对 Bean 进行属性赋值,如果发现循环依赖,会将当前 Bean 对象提前暴露给后续需要依赖的 Bean(通过提前暴露的方式解决循环依赖)。
- 初始化 Bean:完成属性赋值后,Spring 将 Bean 进行初始化,并将其放入二级缓存中。
- 注入依赖:Spring 继续对 Bean 进行依赖注入,如果发现循环依赖,会从二级缓存中获取已经完成初始化的 Bean 实例。
通过三级缓存的机制,Spring 能够在处理循环依赖时,确保及时暴露正在创建的 Bean 对象,并能够正确地注入已经初始化的 Bean 实例,从而解决循环依赖问题,保证应用程序的正常运行。
spring三级缓存的数据结构是什么?
都是 Map类型的缓存,比如Map {k:name; v:bean}。
- 一级缓存(Singleton Objects):这是一个Map类型的缓存,存储的是已经完全初始化好的bean,即完全准备好可以使用的bean实例。键是bean的名称,值是bean的实例。这个缓存在
DefaultSingletonBeanRegistry类中的singletonObjects属性中。 - 二级缓存(Early Singleton Objects):这同样是一个Map类型的缓存,存储的是早期的bean引用,即已经实例化但还未完全初始化的bean。这些bean已经被实例化,但是可能还没有进行属性注入等操作。这个缓存在
DefaultSingletonBeanRegistry类中的earlySingletonObjects属性中。 - 三级缓存(Singleton Factories):这也是一个Map类型的缓存,存储的是ObjectFactory对象,这些对象可以生成早期的bean引用。当一个bean正在创建过程中,如果它被其他bean依赖,那么这个正在创建的bean就会通过这个ObjectFactory来创建一个早期引用,从而解决循环依赖的问题。这个缓存在
DefaultSingletonBeanRegistry类中的singletonFactories属性中。
linux中软链接和硬链接的区别?
有时候我们希望给某个文件取个别名,那么在 Linux 中可以通过硬链接(_Hard Link_) 和软链接(_Symbolic Link_) 的方式来实现,它们都是比较特殊的文件,但是实现方式也是不相同的。
硬链接是多个目录项中的「索引节点」指向一个文件,也就是指向同一个 inode,但是 inode 是不可能跨越文件系统的,每个文件系统都有各自的 inode 数据结构和列表,所以硬链接是不可用于跨文件系统的。由于多个目录项都是指向一个 inode,那么只有删除文件的所有硬链接以及源文件时,系统才会彻底删除该文件。
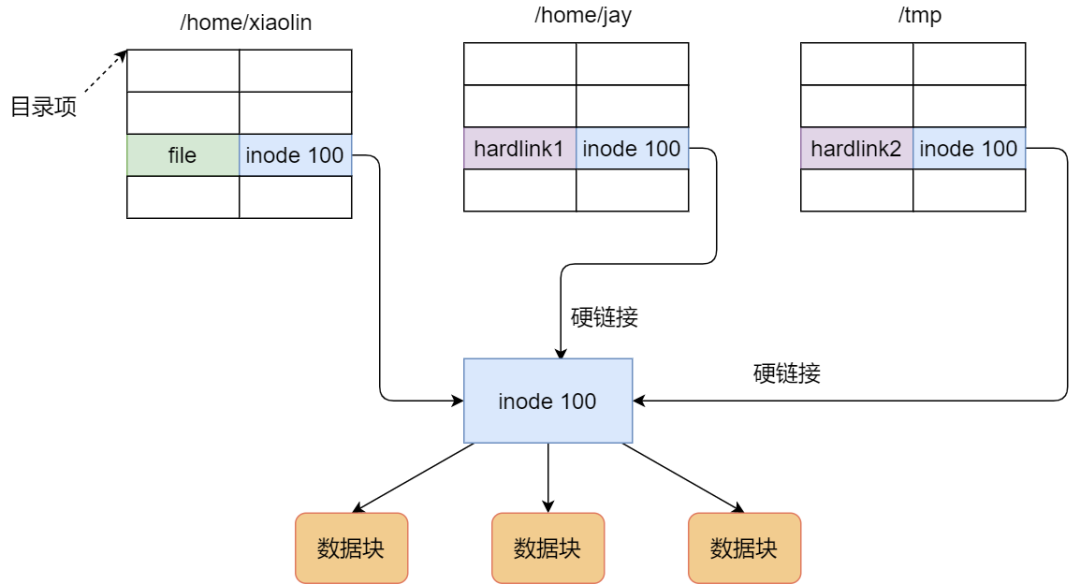
软链接相当于重新创建一个文件,这个文件有独立的 inode,但是这个文件的内容是另外一个文件的路径,所以访问软链接的时候,实际上相当于访问到了另外一个文件,所以软链接是可以跨文件系统的,甚至目标文件被删除了,链接文件还是在的,只不过指向的文件找不到了而已。

手撕代码
- 链表向右循环K个数
一面感受
体验很好,面试官很会引导。面试官说我准备的很充分,快要结束时直接让我准备二面,说一面直接给我过了。
二面八股
进程和线程的区别?

- 本质区别:进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位
- 在开销方面:每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小
- 稳定性方面:进程中某个线程如果崩溃了,可能会导致整个进程都崩溃。而进程中的子进程崩溃,并不会影响其他进程。
- 内存分配方面:系统在运行的时候会为每个进程分配不同的内存空间;而对线程而言,除了CPU外,系统不会为线程分配内存(线程所使用的资源来自其所属进程的资源),线程组之间只能共享资源
- 包含关系:没有线程的进程可以看做是单线程的,如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线(线程)共同完成的;线程是进程的一部分,所以线程也被称为轻权进程或者轻量级进程
你说到进程是分配资源的基本单位,那么这个资源指的是什么?
虚拟内存、文件句柄、信号量等资源。
说一说fork()原理?
主进程在执行 fork 的时候,操作系统会把主进程的「页表」复制一份给子进程,这个页表记录着虚拟地址和物理地址映射关系,而不会复制物理内存,也就是说,两者的虚拟空间不同,但其对应的物理空间是同一个。

这样一来,子进程就共享了父进程的物理内存数据了,这样能够节约物理内存资源,页表对应的页表项的属性会标记该物理内存的权限为只读。
不过,当父进程或者子进程在向这个内存发起写操作时,CPU 就会触发写保护中断,这个写保护中断是由于违反权限导致的,然后操作系统会在「写保护中断处理函数」里进行物理内存的复制,并重新设置其内存映射关系,将父子进程的内存读写权限设置为可读写,最后才会对内存进行写操作,这个过程被称为「写时复制(Copy On Write)」。
写时复制顾名思义,在发生写操作的时候,操作系统才会去复制物理内存,这样是为了防止 fork 创建子进程时,由于物理内存数据的复制时间过长而导致父进程长时间阻塞的问题。
fork()会复制哪些东西?
- fork 阶段会复制父进程的页表(虚拟内存)
- fork 之后,如果发生了写时复制,就会复制物理内存
堆和栈的区别?
- 分配方式:堆是动态分配内存,由程序员手动申请和释放内存,通常用于存储动态数据结构和对象。栈是静态分配内存,由编译器自动分配和释放内存,用于存储函数的局部变量和函数调用信息。
- 内存管理:堆需要程序员手动管理内存的分配和释放,如果管理不当可能会导致内存泄漏或内存溢出。栈由编译器自动管理内存,遵循后进先出的原则,变量的生命周期由其作用域决定,函数调用时分配内存,函数返回时释放内存。
- 大小和速度:堆通常比栈大,内存空间较大,动态分配和释放内存需要时间开销。栈大小有限,通常比较小,内存分配和释放速度较快,因为是编译器自动管理。
说说io多路复用?
I/O 多路复用可以只使用一个进程来维护多个 Socket 。
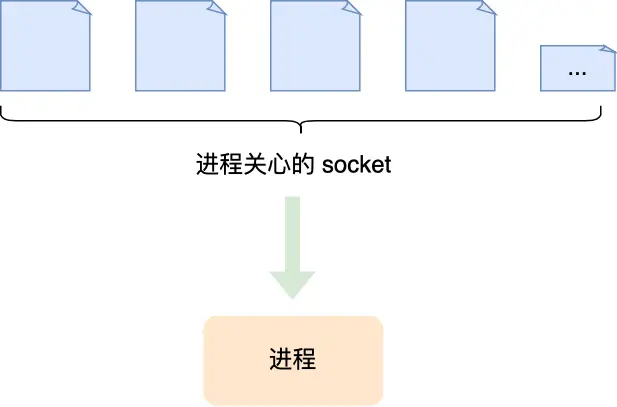
一个进程虽然任一时刻只能处理一个请求,但是处理每个请求的事件时,耗时控制在 1 毫秒以内,这样 1 秒内就可以处理上千个请求,把时间拉长来看,多个请求复用了一个进程,这就是多路复用,这种思想很类似一个 CPU 并发多个进程,所以也叫做时分多路复用。
select/poll/epoll 内核提供给用户态的多路复用系统调用,进程可以通过一个系统调用函数从内核中获取多个事件。在获取事件时,先把所有连接(文件描述符)传给内核,再由内核返回产生了事件的连接,然后在用户态中再处理这些连接对应的请求即可。
tcp与udp的区别
- 连接:TCP 是面向连接的传输层协议,传输数据前先要建立连接;UDP 是不需要连接,即刻传输数据。
- 服务对象:TCP 是一对一的两点服务,即一条连接只有两个端点。UDP 支持一对一、一对多、多对多的交互通信
- 可靠性:TCP 是可靠交付数据的,数据可以无差错、不丢失、不重复、按序到达。UDP 是尽最大努力交付,不保证可靠交付数据。但是我们可以基于 UDP 传输协议实现一个可靠的传输协议,比如 QUIC 协议
- 拥塞控制、流量控制:TCP 有拥塞控制和流量控制机制,保证数据传输的安全性。UDP 则没有,即使网络非常拥堵了,也不会影响 UDP 的发送速率。
- 首部开销:TCP 首部长度较长,会有一定的开销,首部在没有使用「选项」字段时是 20 个字节,如果使用了「选项」字段则会变长的。UDP 首部只有 8 个字节,并且是固定不变的,开销较小。
- 传输方式:TCP 是流式传输,没有边界,但保证顺序和可靠。UDP 是一个包一个包的发送,是有边界的,但可能会丢包和乱序。
- 应用场景:TCP 是面向连接,能保证数据的可靠性交付,因此经常用于:FTP、HTTP/HTTPS协议。UDP 面向无连接,它可以随时发送数据,再加上 UDP 本身的处理既简单又高效,经常用于视频、音频等多媒体通信等。
说说HTTP头部字段
Host 字段
客户端发送请求时,用来指定服务器的域名。

Host: www.A.com
有了 Host 字段,就可以将请求发往「同一台」服务器上的不同网站。
Content-Length 字段
服务器在返回数据时,会有 Content-Length 字段,表明本次回应的数据长度。

Content-Length: 1000
如上面则是告诉浏览器,本次服务器回应的数据长度是 1000 个字节,后面的字节就属于下一个回应了。大家应该都知道 HTTP 是基于 TCP 传输协议进行通信的,而使用了 TCP 传输协议,就会存在一个“粘包”的问题,HTTP 协议通过设置回车符、换行符作为 HTTP header 的边界,通过 Content-Length 字段作为 HTTP body 的边界,这两个方式都是为了解决“粘包”的问题。
Connection 字段
Connection 字段最常用于客户端要求服务器使用「HTTP 长连接」机制,以便其他请求复用。

HTTP 长连接的特点是,只要任意一端没有明确提出断开连接,则保持 TCP 连接状态。

HTTP/1.1 版本的默认连接都是长连接,但为了兼容老版本的 HTTP,需要指定 Connection 首部字段的值为 Keep-Alive。
Connection: Keep-Alive
开启了 HTTP Keep-Alive 机制后, 连接就不会中断,而是保持连接。当客户端发送另一个请求时,它会使用同一个连接,一直持续到客户端或服务器端提出断开连接。
Content-Type 字段
Content-Type 字段用于服务器回应时,告诉客户端,本次数据是什么格式。

Content-Type: text/html; Charset=utf-8
上面的类型表明,发送的是网页,而且编码是UTF-8。客户端请求的时候,可以使用 Accept 字段声明自己可以接受哪些数据格式。
Accept: */*
上面代码中,客户端声明自己可以接受任何格式的数据。
说说HTTP2
HTTP/2 相比 HTTP/1.1 性能上的改进:
- 头部压缩:HTTP/2 会压缩头(Header)如果你同时发出多个请求,他们的头是一样的或是相似的,那么,协议会帮你消除重复的部分。这就是所谓的 HPACK 算法:在客户端和服务器同时维护一张头信息表,所有字段都会存入这个表,生成一个索引号,以后就不发送同样字段了,只发送索引号,这样就提高速度了。
- 二进制格式:HTTP/2 不再像 HTTP/1.1 里的纯文本形式的报文,而是全面采用了二进制格式,头信息和数据体都是二进制,并且统称为帧(frame):头信息帧(Headers Frame)和数据帧(Data Frame)。这样虽然对人不友好,但是对计算机非常友好,因为计算机只懂二进制,那么收到报文后,无需再将明文的报文转成二进制,而是直接解析二进制报文,这增加了数据传输的效率。
- 并发传输:引出了 Stream 概念,多个 Stream 复用在一条 TCP 连接。解决了HTTP/1.1 队头阻塞的问题:
- 服务器主动推送资源:HTTP/2 还在一定程度上改善了传统的「请求 - 应答」工作模式,服务端不再是被动地响应,可以主动向客户端发送消息。
手撕代码
- 算法:求最长无重复字符串
- 智力题:64匹马,8个赛道,如何找出最快的四匹?
二面感受
- 总结:二面答得不太行,经典智力题没答出最优方法(听说字节面试官出智力题就是想挂人...)。
三面八股
java异常体系介绍一下?
Java异常类层次结构图:

Java的异常体系主要基于两大类:Throwable类及其子类。Throwable有两个重要的子类:Error和Exception,它们分别代表了不同类型的异常情况。
- Error(错误):表示运行时环境的错误。错误是程序无法处理的严重问题,如系统崩溃、虚拟机错误、动态链接失败等。通常,程序不应该尝试捕获这类错误。例如,
OutOfMemoryError、StackOverflowError等。 - Exception(异常):表示程序本身可以处理的异常条件。异常分为两大类:
- 非运行时异常:这类异常在编译时期就必须被捕获或者声明抛出。它们通常是外部错误,如文件不存在(
FileNotFoundException)、类未找到(ClassNotFoundException)等。非运行时异常强制程序员处理这些可能出现的问题,增强了程序的健壮性。 - 运行时异常:这类异常包括运行时异常(
RuntimeException)和错误(Error)。运行时异常由程序错误导致,如空指针访问(NullPointerException)、数组越界(ArrayIndexOutOfBoundsException)等。运行时异常是不需要在编译时强制捕获或声明的。
- 非运行时异常:这类异常在编译时期就必须被捕获或者声明抛出。它们通常是外部错误,如文件不存在(
java中的一些设计模式?介绍一下常用的一些?
我比较熟悉的是单例模式和工厂模式:
- 单例模式:确保一个类只有一个实例,并提供一个全局访问点。
- 工厂方法模式:定义一个创建对象的接口,但让实现这个接口的类来决定实例化哪个类。
- 抽象工厂模式:提供一个接口,用于创建相关或依赖对象的家族,而不需要指明具体类。
除了用synchronized,还有什么方法可以实现线程同步?
- 使用
ReentrantLock类:ReentrantLock是一个可重入的互斥锁,相比synchronized提供了更灵活的锁定和解锁操作。它还支持公平锁和非公平锁,以及可以响应中断的锁获取操作。 - 使用
volatile关键字:虽然volatile不是一种锁机制,但它可以确保变量的可见性。当一个变量被声明为volatile后,线程将直接从主内存中读取该变量的值,这样就能保证线程间变量的可见性。但它不具备原子性。 - 使用
Atomic类:Java提供了一系列的原子类,例如AtomicInteger、AtomicLong、AtomicReference等,用于实现对单个变量的原子操作,这些类在实现细节上利用了CAS(Compare-And-Swap)算法,可以用来实现无锁的线程安全。
http 断点重传是什么?
断点续传是HTTP/1.1协议支持的特性。实现断点续传的功能,需要客户端记录下当前的下载进度,并在需要续传的时候通知服务端本次需要下载的内容片段。
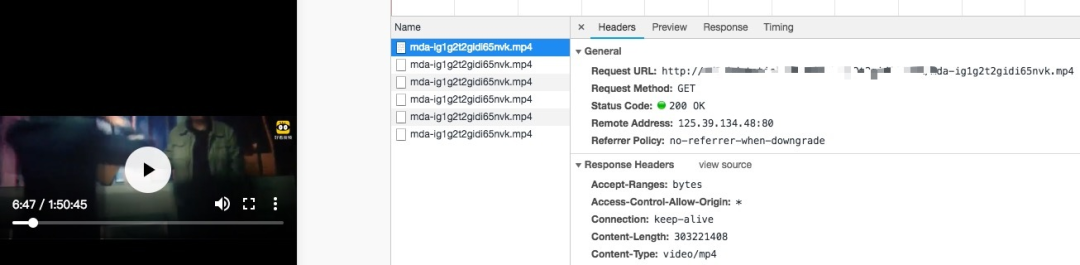
一个最简单的断点续传流程如下:
- 客户端开始下载一个1024K的文件,服务端发送Accept-Ranges: bytes来告诉客户端,其支持带Range的请求
- 假如客户端下载了其中512K时候网络突然断开了,过了一会网络可以了,客户端再下载时候,需要在HTTP头中申明本次需要续传的片段:Range:bytes=512000-这个头通知服务端从文件的512K位置开始传输文件,直到文件内容结束
- 服务端收到断点续传请求,从文件的512K位置开始传输,并且在HTTP头中增加:Content-Range:bytes 512000-/1024000,Content-Length: 512000。并且此时服务端返回的HTTP状态码应该是206 Partial Content。如果客户端传递过来的Range超过资源的大小,则响应416 Requested Range Not Satisfiable
通过上面流程可以看出:断点续传中4个HTTP头不可少的,分别是Range头、Content-Range头、Accept-Ranges头、Content-Length头。其中第一个Range头是客户端发过来的,后面3个头需要服务端发送给客户端。下面是它们的说明:
- Accept-Ranges: bytes:这个值声明了可被接受的每一个范围请求, 大多数情况下是字节数 bytes
- Range: bytes=开始位置-结束位置:Range是浏览器告知服务器所需分部分内容范围的消息头。
手撕代码
- 手撕单例模式
- 手撕算法:设计一个队列,要求底层用数组,支持动态扩容
三面感受
- 三面面试官问项目比较多,考察实际项目对自己的一些成长,面试官很好,只是我太菜了。