《Prometheus 监控实践:从零到英雄》
《Prometheus 监控实践:从零到英雄》

猫头虎
发布于 2024-04-09 14:30:12
发布于 2024-04-09 14:30:12
摘要
? 猫头虎博主回来了!在现代的微服务架构中,有效的监控解决方案已经成为了关键的组件。我发现许多开发和运维朋友在搜索 “Prometheus 基础”、“Prometheus 监控实践” 或 “Prometheus 部署指南”。于是,我决定为大家深入解析 Prometheus,从最基础的概念到生产环境中的应用实践,一路带你成为监控领域的英雄!?
引言
在快速发展的云原生领域,有效的监控工具可以帮助团队在第一时间发现和解决问题。Prometheus,作为一个开源的系统监控和警报工具包,已经得到了广泛的应用。但如何正确地使用它呢?跟随我,一起探索!
正文
1. Prometheus 简介

1.1 什么是 Prometheus?
Prometheus 是一个开源的系统监控和警报工具包,最初是在 SoundCloud 开发的,现在已经成为了 Cloud Native Computing Foundation 的一部分。
1.2 核心特性
- 多维数据模型: 使用键值对来标识时间序列数据。
- 灵活的查询语言: PromQL 允许进行复杂的查询和聚合。
- 无依赖性: Prometheus 的主服务器是独立的,不依赖于分布式存储。
2. Prometheus 架构与组件
2.1 主要组件
- Prometheus Server: 负责数据拉取和存储。
- Pushgateway: 用于短期作业。
- Alertmanager: 负责处理警报。
- 各种 Exporters: 用于暴露常见服务的指标。
2.2 数据拉取与存储
Prometheus 主要使用拉取(pull)模型来收集指标,但也支持推送(push)模型。
# Prometheus 配置示例
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'example'
static_configs:
- targets: ['localhost:8080']3. Prometheus 在生产中的实践
3.1 安装与部署
Prometheus 可以作为一个独立的二进制文件运行,也可以在容器中运行。
# 使用 Docker 运行 Prometheus
docker run -p 9090:9090 prom/prometheus3.2 设置警报
使用 Alertmanager 和 PromQL,你可以轻松定义和管理警报。
# 警报规则示例
groups:
- name: example
rules:
- alert: HighRequestLatency
expr: job:request_latency_seconds:mean5m{job="myjob"} > 0.5
for: 10m
labels:
severity: page
annotations:
description: '{{ $labels.instance }} has a high request latency'3.3 可视化与 Grafana
Prometheus 与 Grafana 完美结合,提供了丰富的可视化选项。

4. Prometheus 面临的挑战
4.1 长期存储
Prometheus 默认的存储引擎不适合长期存储,但可以与其他系统整合。
4.2 高可用性
为了实现高可用性,可能需要运行多个 Prometheus 实例。
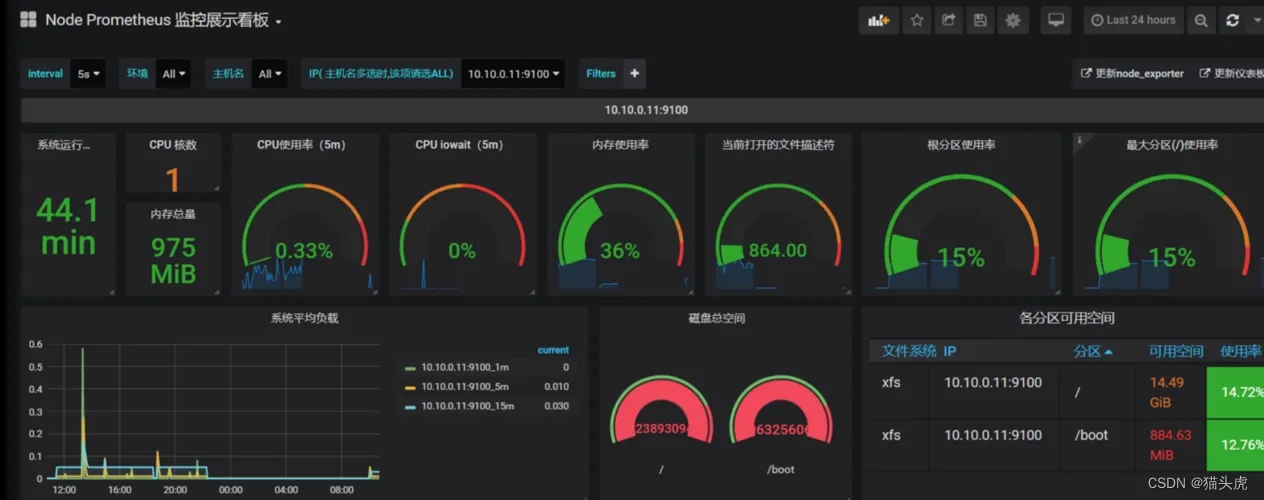
总结
Prometheus 提供了一个强大的框架,用于监控现代应用和基础设施。通过深入理解其核心概念和实践,我们可以更好地利用它来保障系统的稳定性和可靠性。?
参考资料
- Prometheus 官方文档: https://prometheus.io/docs/introduction/overview/
- Grafana 官方文档: https://grafana.com/docs/
- Cloud Native Computing Foundation: https://www.cncf.io/
本文参与?腾讯云自媒体分享计划,分享自作者个人站点/博客。
原始发表:2023-09-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
相关产品与服务
对象存储
对象存储(Cloud Object Storage,COS)是由腾讯云推出的无目录层次结构、无数据格式限制,可容纳海量数据且支持 HTTP/HTTPS 协议访问的分布式存储服务。腾讯云 COS 的存储桶空间无容量上限,无需分区管理,适用于 CDN 数据分发、数据万象处理或大数据计算与分析的数据湖等多种场景。