pymilvus创建IVF_ScaNN向量索引
原创pymilvus创建IVF_ScaNN向量索引
原创
索引简介
索引的作用是加速大型数据集上的查询。
目前,向量字段仅支持一种索引类型,即只能创建一个索引。
milvus支持的向量索引类型大部分使用近似最近邻搜索算法(ANNS,approximate nearest neighbors search) 。ANNS 的核心思想不再局限于返回最准确的结果,而是仅搜索目标的邻居。 ANNS 通过在可接受的范围内牺牲准确性来提高检索效率。
ScaNN索引
可扩展最近邻scaNN(Scalable Nearest Neighbors)索引:
ScaNN的paper:
https://arxiv.org/pdf/1908.10396.pdf
ScaNN的代码:
https://github.com/google-research/google-research/tree/master/scann
ScaNN算法的基础是IVF_PQ。
IVF就是通过kmeans聚类将数据分成若干个bucket,搜索时query向量和聚类中心的距离排序,选择nprobe个bucket进行计算即可。
ScaNN针对IVFPQ两点做了优化:
- 量化的时候选择kmeans聚类中心来代替subvector的方式,是否有更好的方式
- 搜索时的查表操作是一个内存瓶颈的事情,是否可以更高效
Score-aware quantization loss
ScaNN针对的metric是IP(点积),定义量化loss为query和原始向量,query和量化后的向量之间的差距。 也支持L2 metric。
离query更近的点对结果的影响更大。
加权。
4bit PQ
回顾下PQ的计算过程,查询时预计算query和subvector的聚类中心,构建Lookup table,计算距离时通过查表拿到分段距离做加和。
但是频繁的读内存操作还是不够高效,如果可以把Lookup table做到足够小,小到可以在寄存器里放得下,就可以把读内存的操作变成cpu高效的SIMD指令。
有用的是4bit PQ的部分。
对比HNSW的QPS有20%提升。
索引构建参数:
nlist:集群单元数量
使用attu创建ScaNN索引
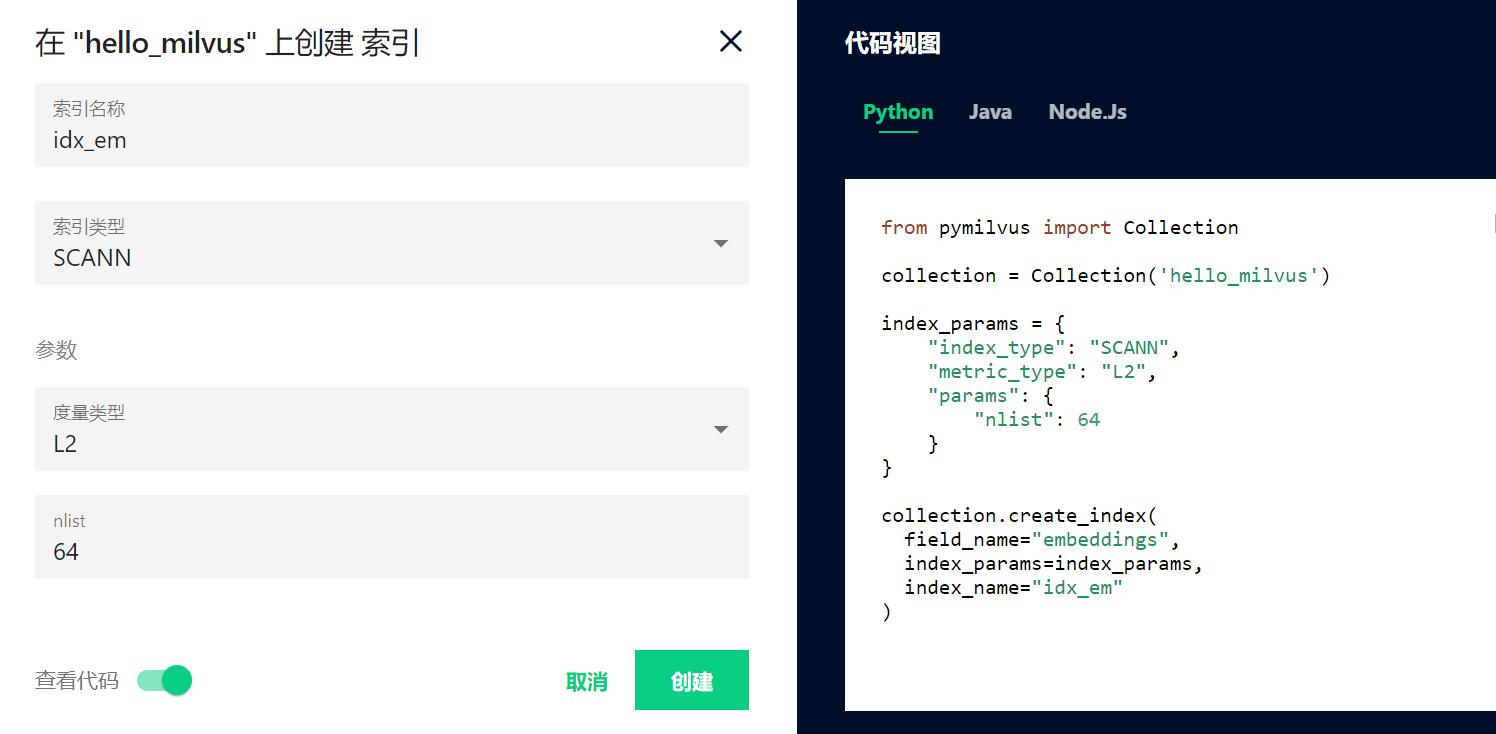

使用pymilvus创建ScaNN索引
from pymilvus import (
connections,
Collection,
)
collection_name = "hello_milvus"
host = "192.168.230.71"
port = 19530
username = ""
password = ""
print("start connecting to Milvus")
connections.connect("default", host=host, port=port,user=username,password=password)
coll = Collection(collection_name, consistency_level="Bounded",shards_num=1)
print("Start creating index")
index_params = {
"index_type": "SCANN",
"metric_type": "IP",
"params": {
"nlist": 64
}
}
coll.create_index(
field_name="embeddings",
index_params=index_params,
index_name="idx_em"
)
print("done")原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。