DDIA:日志和消息队列只有一线之隔

通过网络发送数据包或者给一个服务发送网络请求都是透明的操作,不会留下任何永久痕迹。尽管,我们可以将其永久地记下来(通过抓包工具或者日志工具),但通常不会这么做。即使消息代理会暂时地将消息写到外存中,但在其被消费后也通常会删除,这一切是因为,我们认为消息是一种暂态数据。
与之相对,数据库和文件系统是另外一种思想:一旦数据被写入数据库或者文件中,就会被认为是持久数据,直到其他人将其显式地删除。
这两种不同的思路,对我们如何生成衍生数据有很大的影响。我们在第十章中讨论过,批处理的一个核心特点是,你可以针对同一个输入,做不同实验、跑多次处理,而不用担心输入会发生变化(因为输入是只读的)。但在 AMQP/JMS 协议下,事件或者说消息,并不具有此类特性。因为一旦消息被确认消费后,就会被删除。因此,你不能再将消费者重新跑一遍,并期望相同结果。
时间回溯。在某个时刻 t,如果你往消息系统中新加入一个消费者,则该消费者只能消费时刻 t 以后新到来的消息;所有之前的消息都已经不在了,且不能恢复。与之相对,对于文件系统和数据库,当你新加入一个客户端时,它可以读取之前任意时刻写入的数据(只要该数据没有被显式删除)。
于是一个想法就出现了——我们能不能取两者之长,造一个系统,兼有数据库的持久存储特性和消息系统的低时延通知特性?这就是基于日志的消息代理(log-based message brokers)的基本思想。
使用日志作为消息存储
日志是一种基于硬盘的、只允许追加的记录序列。我们在第三章讨论基于日志结构的存储引擎时,讨论过写前日志(WAL),在第五章的讨论冗余时,也提过。
这种结构也能够用于实现消息代理:
- 生产:生产者将消息追加到日志的末尾
- 消费:消费者顺序读取日志序列,读到末尾时阻塞等待
Unix 工具 tail -f 就是使用的类似的思想,以监视是否有新数据追加到文件末尾。
为了对 IO 平滑扩容以突破单机硬盘限制,日志可以被切片(Partition)。进而,将不同的日志切片摊到不同的机器上去,从而让不同机器上的日志分片能够独立的应对读写负载。这样,一个逻辑上的 topic,在物理上可以表现为分散在多机上的,存有同样类型消息的多个日志分片的集合。如下图所示:
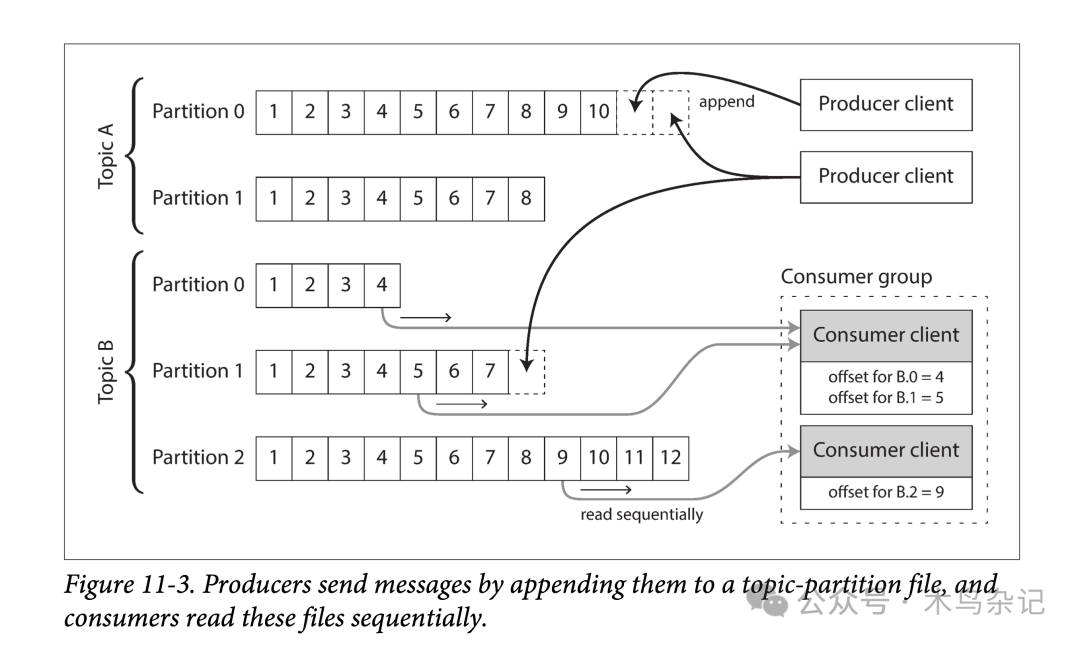
基于 topic 和消费者组的生产消费
在每个日志分片内部,消息代理会给每条消息安排一个全局递增的序列号(或称为偏移量,offset),由于每个分片都是只允许追加的,因此在分片内,其消息是按序号局部有序的。但在不同分片间,消息的顺序是没有办法保证的。
Apache Kafka,Amazon Kinesis Streams 和 Twitter 的 DistributedLog 背后都是类似的原理。谷歌云的上的 Pub/Sub 在架构上更像 JMS 风格的 API,而不是日志的抽象。即使这些消息代理会将所有消息落盘,但由于多机、顺序写等特点,总体仍然能够达到每秒数百万条消息的吞吐,且能够通过多机冗余进行容错。
对比日志和传统消息
日志和传统消息的一个很大不同是,不会在消费者消费完后立即删除。因此基于分区日志的消息系统可以很容易的支持并行消费( fan-out)。由于有分区的存在,支持负载均衡( load-balance) 也很方便,可以将每个分区直接给某个消费者进行消费。
每个客户端会消费分配给他的所有分区的消息。通常来说,在一个分区内部,消费者会对所有消息进行单线程、顺序地消费。这种基于分区粒度的负载均衡有一些缺点:
- 并发限制:由于一个分区最多安排给一个消费者,因此互斥消费一个 topic 的消费者数量不能多于分区数。
- 单条阻塞:如果某个消息处理过慢,则会阻塞其所在分区后续所有消息的消费。
因此,总结来说:
- 如果每条消息的处理代价很高,你不关心消费的顺序,但想在消息粒度进行并行的处理以加快整体处理速度,则 JMS/AMQP 风格的消息代理更合适。
- 如果你想要高吞吐,每条消息能够很快处理,且消息间顺序很重要,则基于日志的消息代理工作得更好。
消费者偏移量
在分区内顺序消费使得追踪消费者的消费进度非常容易:只需要记住一个偏移量即可,所有小于该偏移量的消息都被消费了,所有大于该偏移量的消息尚未被消费。因此,消息代理无需在消息粒度上追踪其是否被确认,只需要定期持久化消费偏移量即可。这种方法减少了元信息开销,但同时也降低了 batch 化(将一批消息一块发送出去,乱序确认)和流水线化(不等确认就给 Consumer 发送下一条)以提高系统吞吐的可能性。
这种偏移量的记录方式,很像单主模型数据库中的序列号(log sequence number),我们在新增副本一节中讨论过。在多副本数据库中,使用序列号能让从副本在宕机重启后,从固定位置重新消费,以不错过任何写。同样的原则也适用于此,本质上,消息代理就类似主节点,而消费者就类似从节点。
如果一个消费者节点挂掉之后,会从消费者组中另挑选消费者来分担其原负责分区,并且从上次记录的偏移量处继续消费。如果之前的消费者处理了某些消息,但还没来得及更新消费偏移量。则这些消息会被其他节点重复消费,本章稍后我们会讨论解决这个问题的一些方法。
硬盘空间用量
如果你无休止地在硬盘上追加日志,最终硬盘空间会被耗尽。为了回收硬盘空间,日志通常会被切分成多段(segments),旧的日志段会被定期删掉。(之后我们会讨论一些更复杂的硬盘空间释放策略)
这意味着,如果一个消费者过于慢,以至于日志段都要被删掉了还没消费完。这种情况下,消费者可能会丢失一些消息。通常来说,我们会将日志组织成固定尺寸的消息序列,称为环形缓冲区(circular buffer 或者 ring buffer)。当然,我们的缓冲区是基于磁盘的,因此尺寸可以做到非常大。
让我们来粗估一下。截至成书时(2017),一块用于存储的大磁盘通常为 6T 大小,并提供 150 M/s 的吞吐。如果我们的日志追加能够打满 IO 带宽,则大概需要 11 个小时能将硬盘全部写满。这意味着,硬盘可以存 11 小时的消息,之后旧的数据就会被新数据覆写。即使我们用多机、多盘,但是这个单盘的指标不会变。但实际上,我们通常不可能时刻都能打满磁盘带宽,因此一块盘通常能够保存更长时间的消息,数天甚至数周。
但在基于日志的消息代理中,日志保存的长短,并不会影响消息的吞吐。因为所有的消息都是要落盘的。但对于之前讨论的无代理的消息系统则不然,因为在那些系统中,会优先把消息缓存在内存中,只有内存装不下了才会往外存写。因此,缓存的数据一多,吞吐就会降下来。
消费者落后生产者时
在消息系统小节一开始,我们讨论过如果消费者不能跟上生产者速率后的几种选择:丢消息、缓存或者使用背压。在基于日志的消息系统中,我们无疑采用了缓存的方式,使用固定但巨大的缓存(受限于磁盘空间)。
如果某个消费者掉队太远,以至于消费进度调出本机所存日志范围,则该消费者就不能再消费这些已经被丢弃的消息——因为消息代理已经把他们删掉了。一种解决办法是,你可以监控每个消费者的进度,如果某个消费者落后太多,就及时进行报警,让运维人员介入来看下为啥这个消费者这么慢,能不能修复或者干脆重新分配。通常来说,硬盘能够容纳足够长时间的消息,因此运维人员通常有充足的时间来介入。
即使一个消费者掉队太远,也只会影响他自己;而不会干扰其他消费者。这对运维同学来说是重大利好:你可以任意的针对线上日志进行消费、测试、调试,而不用担心影响线上服务。当一个消费者主动下线或者意外宕机时,它不会对线上系统造成任何影响——除了留下一个专属于它的消费者偏移量外。
这种设定与传统的消息代理形成鲜明对比。在那些不基于日志的消息代理中,你需要小心的回收每个已下线的消费者的相应队列缓存,否则即使他们下线了,他们所占的资源(每个消费者都会维护不少元信息)也会慢慢耗尽消息代理的内存。
回放旧消息
我们注意到,在之前的 AMQP 和 JMS 风格消息代理中,对消息的处理和确认是一个破坏性的操作——会导致消息被删除。另一方面,在基于日志的消息代理中,消费消息更像读取一个文件:消费是一个只读操作,并不会对日志本身造成任何改变。
除了产生输出外,消费者进行消费的唯一副作用就是——更新消费偏移量。但偏移量是受消费者本身控制的(不像 AMQP 的消息删除操作并不是受消费者直接控制),举个例子,如果想重新消费昨天的数据,你可以启动一个消费者,从昨天的偏移量开始消费,并将消费输出放到不同的地方,以重放昨天的消息处理。你可以修改调试代码,将这个过程重复任意多次。
从这个方面看,基于日志的消息系统很像上一章讨论的批处理——衍生数据和输入数据通过可重复的变换过程连接,但总体上来说是解耦的。这种特性可以让我们很容易的对相关消息数据做实验,并且很方便地从错误和 bug 中恢复过来,从而让这种类型日志系统很容易被整合到企业中其他的数据流里。
参考资料
[1]
DDIA 读书分享会: https://ddia.qtmuniao.com/