MySQL怎样进行多表设计与查询?什么是MySQL的事务和索引?
MySQL怎样进行多表设计与查询?什么是MySQL的事务和索引?

前面说完了数据库的DDL,DML和DQL,今天主要来看一下MySQL的多表设计与查询。本篇将带你快速了解MySQL的多表设计与查询,以及了解MySQL事务和索引相关的内容。
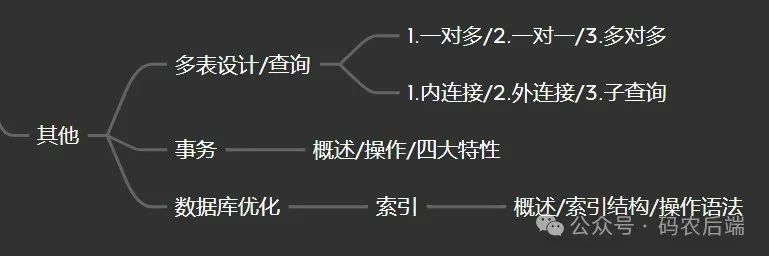
一、多表设计
1、一对多
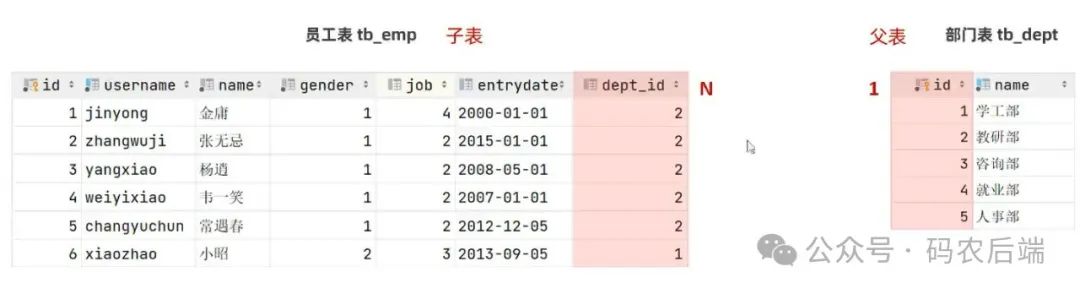
例如,部门和员工即为一对多的关系。一个部门可以有多个员工,但一个员工只能归属于一个部门。
2、一对多-外键
2.1 问题分析
思考:在员工表和部门表中,部门数据可以直接删除,然而还有部分员工归属于该部门下,此时如果强行删除就会出现数据的不完整、不一致问题。
要操作的两张或多张表,如果在数据库层面并未建立关联,就无法保证数据的一致性和完整性的。(添加外键约束解决)
2.2 添加外键约束
1)语法
-- 创建表时指定
create table表名(
字段名 数据类型,
...
[constraint] [外键名称] foreign key (外键字段名) references 主表(字段名)
);
--建完表后,添加外键
alter table 表名 add constraint外键名称 foreign key (外键字段名) references 主表(字段名);
2)物理外键
使用foreign key定义外键关联另外一张表。
缺点:影响增、删、改的效率(需要检查外键关系)。仅用于单节点数据库,不适用与分布式、集群场景。容易引发数据库的死锁问题,消耗性能。
3)逻辑外键
在业务层逻辑中,解决外键关联。
通过逻辑外键,可以很方便的解决上述问题。
3、一对一
1)概述
一对一的关系也非常常见,如用户登录时,一个用户只能对应一个密码。又如一个用户只能有一个身份证号。
2)关系
一对一关系,多用于单表拆分,将一张表的基础字段放在一张表中,其他字段放在另一张表中,以提升操作效率。
如对用户基本信息查询的频率很高,而对用户身份信息查询很少,此时就可以将用户表拆分为基本信息和身份信息两张表,以提高查询效率,如下

3)实现
在任意一方加入外键,关联另外一方的主键,并且设置外键为唯一(UNIQUE)

4、多对多
1)概述
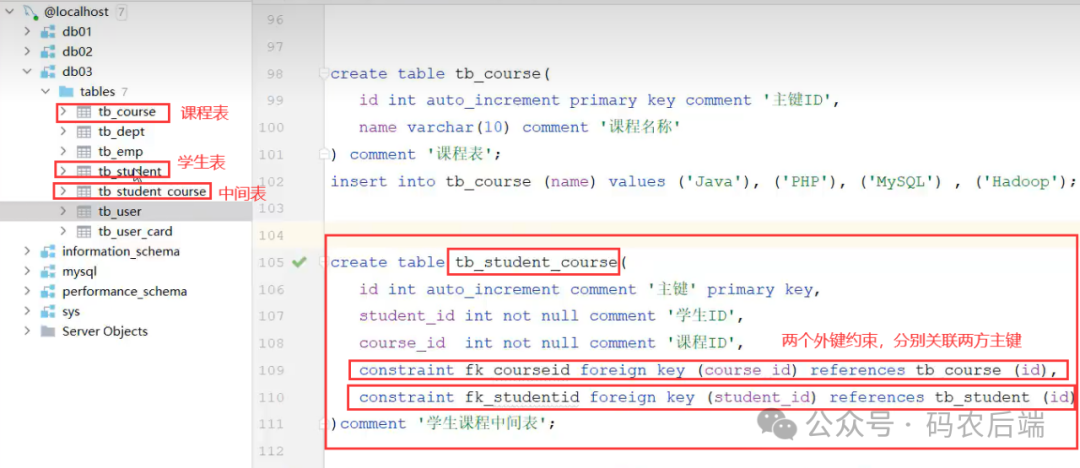
多对多的关系同样很常见,如学生与课程的关系,一个学生可以选修多门课程,一门课程也可供多个学生选择。

2)实现
建立第三张中间表,中间表至少包含两个外键,分别关联两方主键
5、三种关系总结
- 一对多
- 在多的一方添加外键,关联另外一方的主键。
- 一对一
- 任意一方,添加外键,关联另外一方的主键。
- 多对多
- 通过中间表来维护,中间表的两个外键,分别关联另外两张表的主键。
二、多表查询
1、概述
1)多表查询: 指从多张表中查询数据
2)笛卡尔积: 是指在数学中,两个集合(A集合和B集合)的所有组合情况。
注:在多表查询时,需要消除无效的笛卡尔积
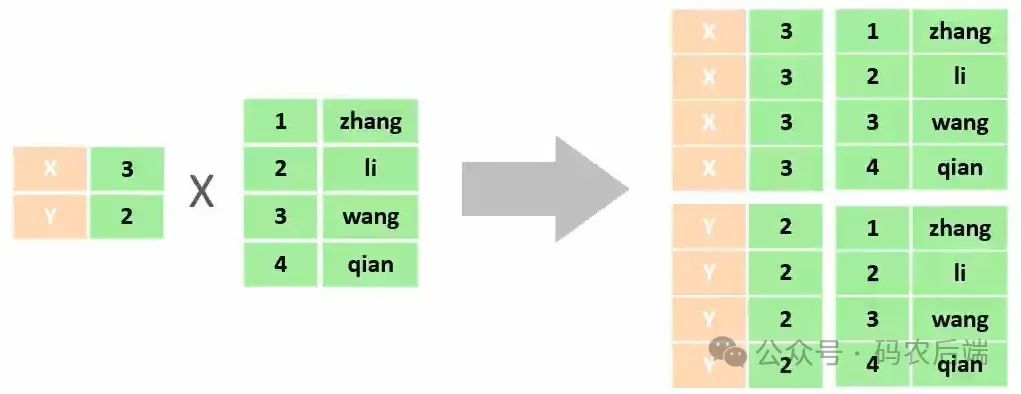
消除后的效果如下

3)主要内容
多表的查询主要有连接查询和子查询,连接查询又可细分为如下
- 1、连接查询
- 左外连接: 查询左表所有数据(包括两张表交集部分数据)
- 右外连接: 查询右表所有数据(包括两张表交集部分数据)
- 内连接: 相当于查询A、B交集部分数据
- 外连接
- 2、子查询

2、内连接
1)隐式内连接
select 字段列表 from 表1,表2 where 条件...;
2)显式内连接
select 字段列表 from 表1 [inner] join 表2 on 连接条件...;
3)示例
eg1:查询员工的姓名,及所属的部门名称(隐式内连接实现)
select tb_emp.name,tb_dept.name from tb_emp,tb_dept where tb_emp.dept_id = tb_dept.id;
或者(当表名较长时,通过起别名的方式)
-- 起别名
select e.name,d.name from tb_emp e , tb_dept d where e.dept_id = d.id;
eg2:查面员工的姓名,及所属的部门名称(显式内连接交现)
select tb_emp.name,tb_dept.name from tb_emp inner join tb_dept on tb_emp.dept_id = tb_dept.id;
3、外连接
1)左外连接
select 字段列表 from 表1 left [outer] join 表2 on 连接条件...;
2)右外连接
select 字段列表 from 表1 right [outer] join 表2 on 连接条件...;
3)示例
eg1:查询员工表所有员工的姓名,和对应的部门名称(左外连接)
select e.name, d.name from tb_emp e left join tb_dept d on e.dept_id = d.id;
eg2:查询部门表所有部门的名称,和对应的员工名称(右外连接)
select e.name, d.name from tb_emp e right join tb_dept d on e.dept_id = d.id;
4、子查询
4.1 概述
1)定义
子查询,又称嵌套查询,即SQL语句中嵌套select语句。
2)形式
select * from t1 where column1 = ( select column1 from t2 ...);
子查询外部的语句可以是insert / update / delete / select的任何一个,最常见的是select。
3)分类
- 标量子查询: 子查询返回的结果为单个值
- 列子查询: 子查询返回的结果为一列
- 行子查询: 子查询返回的结果为一行
- 表子查询: 子查询返回的结果为多行多列
4.2 标量子查询
1)子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式
2)常用的操作符:=,<>,>=,<,<=
3)示例
eg1:查询教研部的所有员工信息,可分为两步,如下
首先,查询教研部的部门ID(tb_dept)
select id from tb_dept where name ='教研部';
其次,再查询该部门ID下的员工信息(tb_emp),将上述两个综合起来如下
select * from tb_emp where dept_id = (select id from tb_dept where name = '教研部');
4.3 列子查询
1)概述
- 子查询返回的结果是一列(可以是多行)
- 常用的操作符: in,not in等
2)示例
eg1:查询教研部和咨询部的所有员工信息,同样可分为两步,如下
首先,查询教研部和咨询部的部门ID(tb_dept)
select id from tb_dept where name = '教研部' or name = '咨询部';
其次,根据部门ID,查询该部门下的员工信息(tb_emp),将上述两个综合起来如下
select * from tb_emp where dept_id in (select id from tb_dept where name = '教研部' or name = '咨询部');
4.3 行子查询
1)概述
- 子查询返回的结果是一行(可以是多列)。
- 常用的操作符: = ,<> ,in ,not in
2)示例
eg1:查询与'韦一笑'的入职日期及职位都相同的员工信息,同样可分为两步,如下
首先,查询'韦一笑'的入职日期及职位
select entrydate,job from tb_emp where name = '韦一笑";
其次,查询与其入职日期及职位都相同的员工信息,将上述两个综合起来如下
select * from tb_emp where (entrydate, job)=(select entrydate,job from tb_emp where name = '韦一笑');
4.4 表子查询
1)概述
- 子查询返回的结果是多行多列,常作为临时表
- 常用的操作符: in
2)示例
eg1:查询入职日期是'2006-01-01'之后的员工信息,及其部门名称。同样可分为两步,如下
首先,查询入职时期是'2006-01-01'之后的员工信息
select * from tb_emp where entrydate > '2006-01-01';
其次,查询这部分员工信息及其部门名称 (tb_dept)
select e.* , d.name from (select * from tb_emp where entrydate > '2006-01-01') e, tb_dept d where e.dept_id = d.id
注:e.*代表员工表的所有数据
三、事务
1、概念
事务是一组操作的集合,是一个不可分割的工作单位。
事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
MySQL的事务默认是自动提交的,所以当执行一条DML语句时,MySQL会立即隐式的提交事务。
如删除部门和删除部门下的员工就是一个事务
删除部门:(删除编号为1的部门)
delete from tb_dept where id = 1;
删除部门下的员工:(删除编号为1的部门下的员工)
delete from tb_emp where dept_id = 1;
2、操作
1)事务控制
开启事务:start transaction; 或 begin;
提交事务:commit;
回滚事务:rollback;
在事务操作前,先开启事务。当所有的操作都执行成功后,再通过 commit提交事务。只要有一个操作失败,就需要执行 rollback回滚事务
3、事务的四大特性
1)原子性(Atomicity)
事务是不可分割的最小单元,要么全部成功,要么全部失败
2)一致性(Consistency)
事务完成时,必须使所有的数据都保持一致状态
3)隔离性(lsolation)
数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行
4)持久性(Durability)
事务一旦提交或回滚,它对数据库中数据的改变就是永久的
四、索引
1、概述
索引(index)是帮助数据库高效获取数据的数据结构。比如下面这个查询语句
select * from user where age = 45;
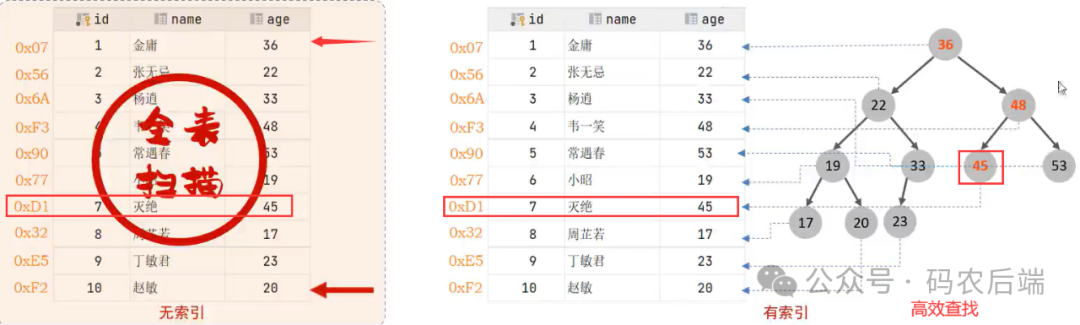
简单分析一下:
1)当没有索引时,指针默认从表头依次向下查找匹配,当匹配成功时,如果还没到表尾,则不能立即返回,需要一直扫描,直到表尾才结束查找。
这种方式也称为全表扫描,可以看出非常低效
2)有索引时,会维护一个索引对应的数据结构。如通过一个二叉搜索树来提高搜索效率。
注:二叉搜索树(BST,Binary Search Tree),也称二叉排序树或二叉查找树,需要满足:
1、结点的值:左<根<右,也就是中序遍历得到的结果是递增的。如上图中序遍历(左根右)的结果为:17,19,20,22,23,33,36,45,48,53。中序遍历很好理解,也很形象,想象自己一脚从最上面的那个根节点踩下去,把它展平,得到的就是我们中序遍历的结果。
2、左右子树仍然是一个颗二叉排序树。
如上说了一些二叉搜索树相关的内容,在理解了二叉搜索树之后再回过头来分析,是如何进行查找的呢?
其实也非常简单,拿我们要查找的数据从根节点开始依次往下对比,比根节点的值小的,往左走;比根节点的值大的,往右走,直到查找成功或查找失败。很形象,所以叫二叉搜索树,其近似于折半查找,每次比较可以将搜索范围减小一半,使得搜索效率相对较高。
2、优缺点
2.1 优点
1)索引能提高数据查询的效率,降低数据库的IO成本。
2)通过索引列对数据进行排序,可以降低数据排序的成本以及降低CPU消耗。
2.2 缺点
1)索引会占用存储空间。
2)索引大大提高了查询效率,却同时也降低了insert、update、delete的效率。
这是因为在增删改的过程中数据发生了变化,就可能需要重新维护索引这个数据结构
3、索引结构
MySQL支持的索引结构有很多,如 Hash索引、B+Tree索引、Ful-Text索引等。
我们平常所说的索引一般默认是B+Tree。

采用上述两种数据结构(二叉搜索树和红黑树)存在的问题
大数据量情况下,层级深,检索速度慢。
B+树,又称多路平衡搜索树,其结构以及查找示意图,如下
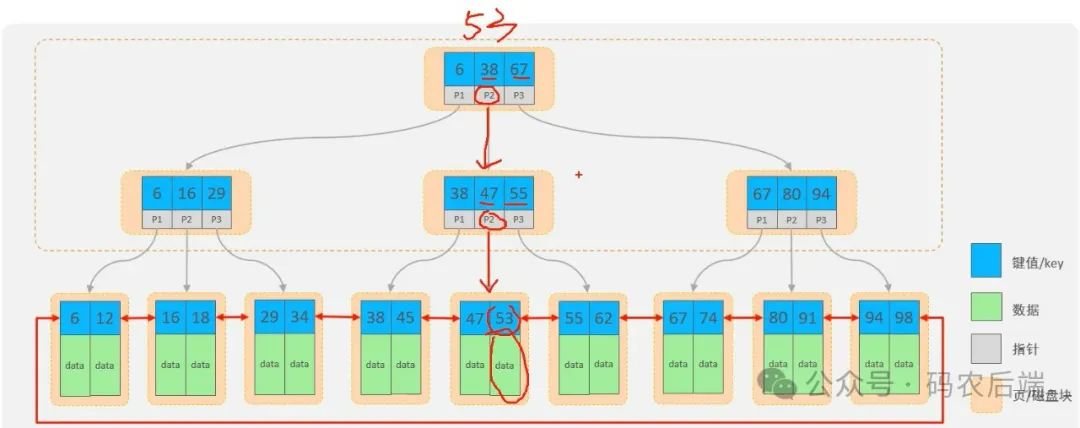
几点注意:
1、每个节点可以存储多个key(有n个key,就有n个指针)。
2、非叶子节点仅用于索引数据,所有的数据都存储在叶子节点(最底下那一层)。
3、叶子节点形成了一颗双向链表,便于数据的排序及区间范围查询。
4、操作语法
4.1 语法
1)创建索引
create [unique] index 索引名 on 表名(字段名...);
2)查看索引
show index from 表名;
3)删除索引
drop index 索引名 on 表名;
4.2 示例
1)为 tb_user表的 name字段建立一个索引
create index idx_user_name on tb_user(name);
2)查询 tb_user表的索引信息
show index from tb_user;
3)删除 tb_user表的 name字段的索引
drop index idx_user_name on tb_user;
两点注意:
主键字段,在建表时,会自动创建主键索引。并且主键索引的性能是最高的。
添加唯一约束(unique)时,数据库实际上会添加唯一索引。