金三银四跳槽redis复习篇(三):redis的底层数据结构,看起来很复杂,其实一点也不简单
金三银四跳槽redis复习篇(三):redis的底层数据结构,看起来很复杂,其实一点也不简单

众所周知,redis有String、List、Hash、Set、Sorted Set这五大基本数据类型,不同的数据类型适用不同的场景。不过相信大多数程序员用得最多的还是String,看起来String像是万能的,但你以为String就是简单的字符串吗?其实不然,redis每个数据类型的底层结构都大有文章。
给大家丢个图就明白了,上面是基本类型,下面是底层结构。像有序集合Sorted Set就用到了压缩列表和跳表。
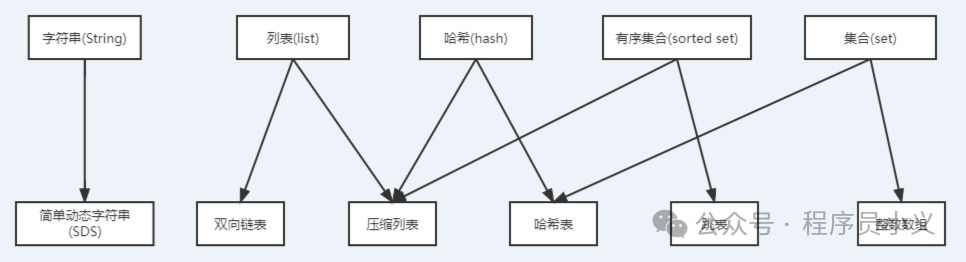
现在知道面试官为啥喜欢问redis底层数据结构跳表之类的了吧,原来知识点都在这呢,还不赶紧来复习一下。
一、redis实体对象
在介绍SDS之前,得先对redis有个基本认知,即redis是一个kv键值数据库,由一张大的哈希表组成,存储的每个字典条目(dictEntry)都是一组kv键值对,dictEntry结构中有三个8字节的指针,分别指向key、value 以及下一个dictEntry,三个指针共 24 字节。key和value都是redis对象(redisObject)。
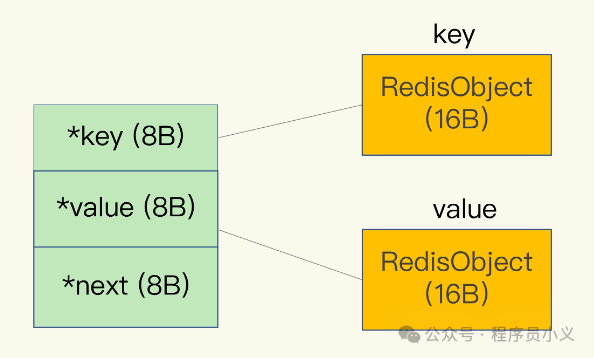
一个redisObject会包含一个8B的元数据信息及一个8B的指针。具体来讲,8字节的元数据可能包括如下信息:
- 类型(type):RedisObject所存储的数据类型,例如字符串、列表、集合等。
- 编码(encoding):具体数据是如何被编码的,比如int、raw、hastable等。
- LRU(最少最近使用):用于实现近似LRU淘汰策略的时间戳或者计数器。
- 引用计数(refcount):这是一个引用计数器,用于记录有多少个指针正在引用该对象的数据部分,以便正确进行内存管理。
8字节指针指的是一个指向实际数据结构的指针,比如指向SDS的指针或者是其他复杂数据结构的指针。
二、简单动态字符串
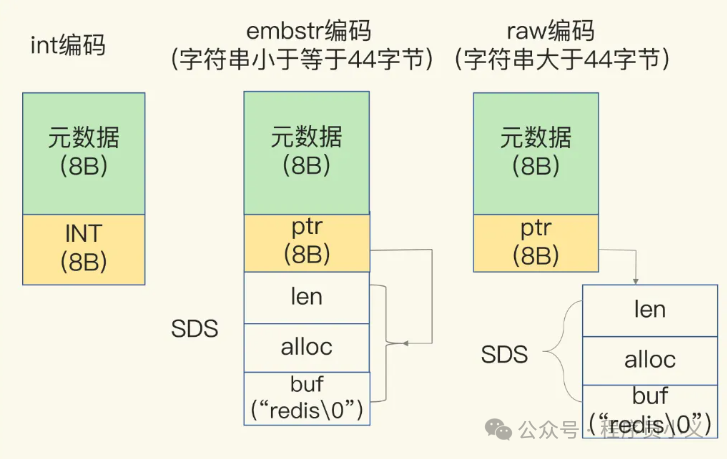
String数据类型背后使用的是自定义的动态字符串类型,也就是我们常说的SDS(Simple Dynamic String),它有int、embstr和raw这三种编码模式。
- int编码:当保存的是 Long 类型整数时,RedisObject 中的指针就直接赋值为整数数据了,这样就不用额外的指针再指向整数了,节省了指针的空间开销。
- embstr编码:当保存的是字符串数据,并且字符串小于等于 44 字节时,RedisObject 中的元数据、指针和 SDS 是一块连续的内存区域,这样就可以避免内存碎片。
- raw编码:当字符串大于 44 字节时,SDS 的数据量就开始变多了,Redis 就不再把 SDS 和 RedisObject 布局在一起了,而是会给 SDS 分配独立的空间,并用指针指向 SDS 结构。

二、压缩列表
当列表、哈希、有序集合存储的数据量较少时,redis就会考虑用ziplist来存储。表结构如下:

压缩列表实际上类似于一个数组,数组中的每一个元素都对应保存一个数据。和数组不同的是,ziplist每个元素长度可以不同,并且在表头有三个字段 zlbytes、zltail 和 zllen,分别表示列表长度、列表尾的偏移量和列表中的 entry 个数;压缩列表在表尾还有一个 zlend,表示列表结束。
在压缩列表中,如果我们要查找第一个元素和最后一个元素,可以通过表头三个字段的长度直接定位,复杂度是 O(1)。而查找其他元素时,就没有这么高效了,只能逐个查找,此时的复杂度就是 O(N) 。
三、跳表
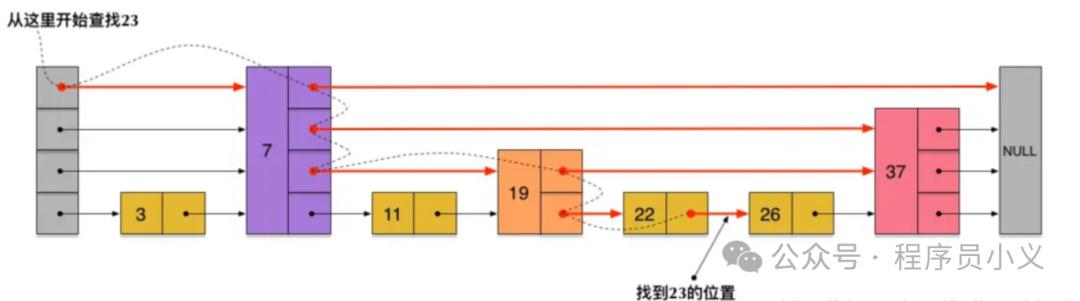
跳表(skiplist)是在有序链表的基础上,增加了多级索引,通过索引位置的几个跳转,实现数据的快速定位。建立索引可以每隔2个数据建立索引,也可以隔3个或5个。
像下面这一个有序列表,3,7,11,19,22,26,37。不用跳表需要查找6次,而利用跳表建立的索引,只需要比较4次,时间复杂度可以从原来的O(N)降到O(logN)。
总结
好了,SDS、ziplist、skiplist都介绍完了。至于其他的,像hash和set用到的哈希表就是一个hashMap的kv键值对,相当于redis弄了一个嵌套的哈希结构。整数数组和双向链表的操作特征都是顺序读写,也就是通过数组下标或者链表的指针逐个元素访问,操作复杂度基本是O(N),操作效率比较低。
显然,整数数组和压缩列表在查找时间复杂度方面并没有很大的优势,那为什么Redis还会把它们作为底层数据结构呢?主要出于以下两点考虑:
- 内存利用率,数组和压缩列表都是非常紧凑的数据结构,它比链表占用的内存要更少。Redis是内存数据库,大量数据存到内存中,此时需要做尽可能的优化,提高内存的利用率。
- 数组对CPU高速缓存支持更友好,所以Redis在设计时,集合数据元素较少情况下,默认采用内存紧凑排列的方式存储,同时利用CPU高速缓存不会降低访问速度。当数据元素超过设定阈值后,避免查询时间复杂度太高,转为哈希和跳表数据结构存储,保证查询效率。
以上就是全部内容,通过深刻理解Redis的底层数据结构,我们可以更加明确地选择适合自己业务场景的数据类型,从而充分发挥Redis的性能优势。