知识图谱增强的KG-RAG框架
知识图谱增强的KG-RAG框架

昨天我们聊到KG在RAG中如何发挥作用,今天我们来看一个具体的例子。 我们找到一篇论文: https://arxiv.org/abs/2311.17330 ,论文的研究人员开发了一种名为知识图谱增强的提示生成(KG-RAG)框架(https://github.com/BaranziniLab/KG_RAG),该框架利用生物医学知识图谱SPOKE与大型语言模型相结合,有效的提升了LLM在医疗领域的问答效果。
KG-RAG框架介绍
KG-RAG框架,较好的结合了生物医学知识图谱SPOKE和LLM的优势。SPOKE是一个开放知识图谱,提供数据下载和开放API,整合了超过40个公开可用的生物医学知识源,涵盖了基因、蛋白质、药物、化合物、疾病等概念和概念之间的关系,可以为LLM提供一个强大的医疗领域知识。
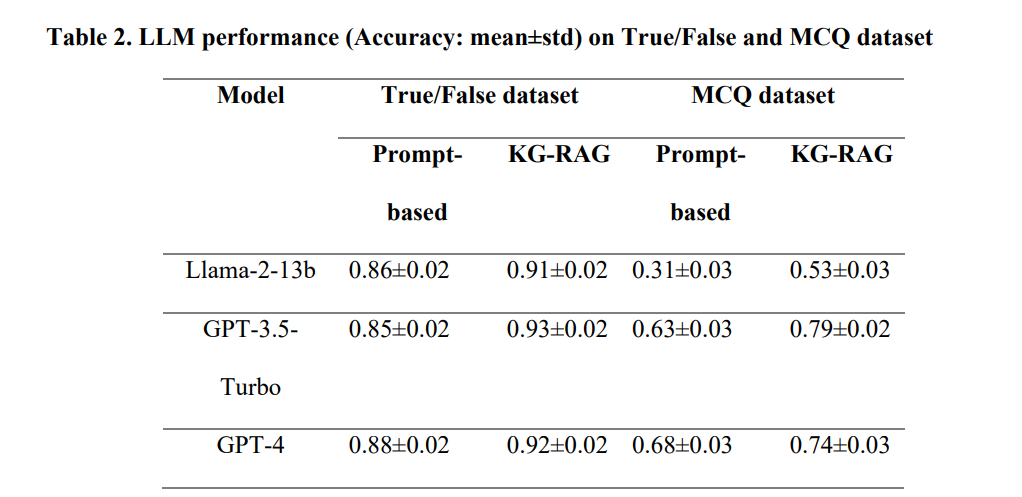
研究人员对KG-RAG框架进行了广泛的测试,包括单跳和双跳提示、药物再利用查询、生物医学真假问题和多项选择题。结果表明,KG-RAG显著提高了LLMs的性能,特别是在具有挑战性的多项选择题数据集上,LLMs都取得了较大的提升。此外,KG-RAG还能够提供有意义的药物再利用建议,并在回答中体现出对临床试验必要性的谨慎态度。
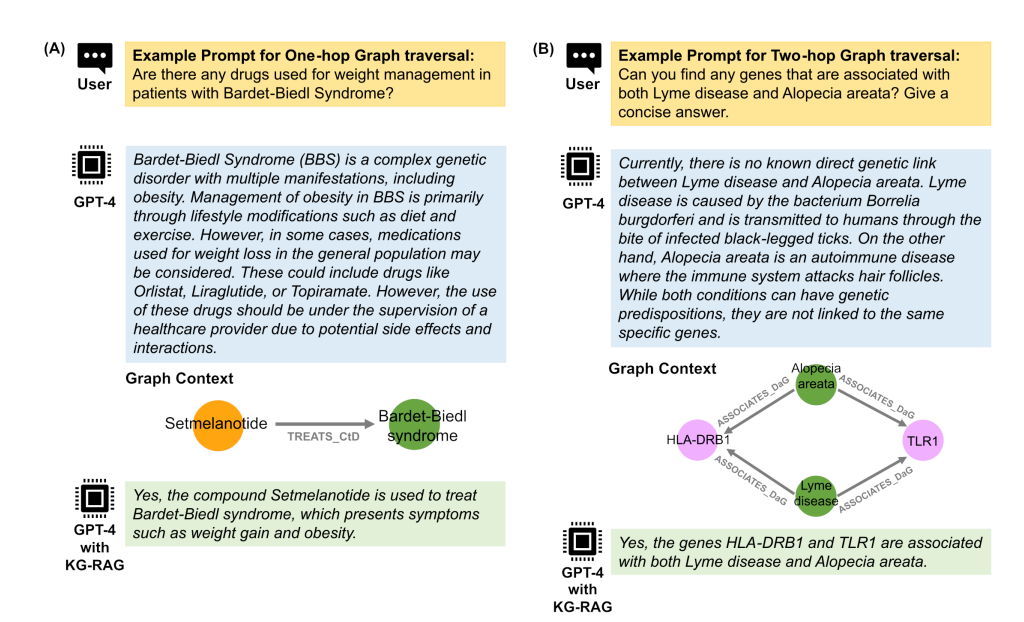
相关测试结果:
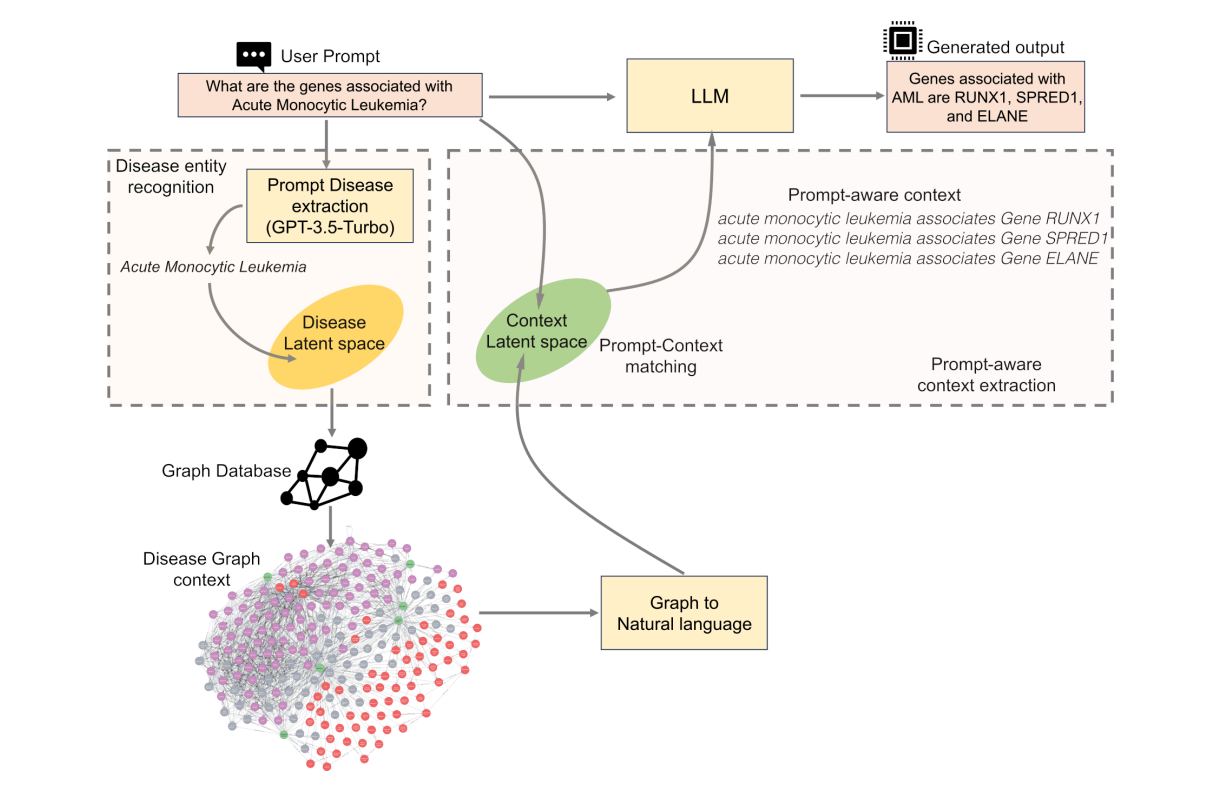
工作原理
KG-RAG框架的工作原理包括以下步骤:
- 实体识别:从用户输入的query中识别出疾病实体,然后在SPOKE知识图谱中找到相应的节点。
- 上下文提取:从SPOKE知识图谱中提取与疾病节点相关的上下文信息,并将其转换为自然语言。
- 提示组装:将提取的上下文与原始prompt结合。
- 文本生成:使用LLM(如Llama-2-13b、GPT-3.5-Turbo或GPT-4)生成有意义的生物医学文本。
实体识别
区别于用小模型去做NER,KG-RAG里使用LLM识别实体。
1. 实体抽取(Disease Entity Extraction)
在KG-RAG框架中,这一过程是通过零样本提示(zero-shot prompting)实现的。研究人员设计了一个高效的抽取prompt,引导大型语言模型(如GPT-3.5-Turbo)从输入文本中提取疾病实体,并将结果以JSON格式返回。
def disease_entity_extractor_v2(text):
chat_model_id, chat_deployment_id = get_gpt35()
prompt_updated = system_prompts["DISEASE_ENTITY_EXTRACTION"] + "\n" + "Sentence : " + text
resp = get_GPT_response(prompt_updated, system_prompts["DISEASE_ENTITY_EXTRACTION"], chat_model_id, chat_deployment_id, temperature=0)
try:
entity_dict = json.loads(resp)
return entity_dict["Diseases"]
except:
return None这里的DISEASE_ENTITY_EXTRACTION:
You are an expert disease entity extractor from a sentence and report it as JSON in the following format:
Diseases: <List of extracted entities>
Please report only Diseases. Do not report any other entities like Genes, Proteins, Enzymes etc.2. 实体链接(Entity Matching to SPOKE)
疾病实体抽取出来后,下一步就是将这些实体与SPOKE知识图谱中的疾病实体进行匹配,也就是传统NLP任务中的实体链接,KG-RAG这个框架中采用的方法是,用语义相似度的方式来做。
- 实体embedding计算:首先,使用Embedding模型(如'all-MiniLM-L6-v2')为SPOKE知识图谱中的所有疾病概念节点计算embedding向量
- 将计算出的疾病embedding存储在向量数据库(如'Chroma')中,以便快速检索。
- 语义搜索匹配:将LLM提取的疾病实体与向量数据库中的疾病实体进行比较,选择最相似的
当然,如果零样本方法未能识别出疾病实体,采取的办法是直接拿原始query去匹配,取top 5。
最终,实体匹配过程会输出与输入文本提示中的疾病实体最相关的SPOKE知识图谱节点。这些节点及其相关信息将用于后续的上下文提取和文本生成步骤。通过这种方法,KG-RAG框架能够有效地从专业文本中提取和识别疾病实体,并将其与丰富的生物医学知识库相连接,从而生成准确、可靠的生物医学相关信息。
子图查询与剪枝
子图查询
在得到具体的实体后,紧接着就是从KG中去查询这个实体关联的子图,这些信息通常以三元组(Subject, Predicate, Object)的形式存在,表示不同的生物医学关系。通常情况下,可以查询1~3跳内的三元组信息,这里借助图数据库可以比较容易的实现。
得到的三元组信息,LLM可能不太能比较好的理解,这里就需要将三元组转换成自然语言,以便与输入提示结合并用于后续的文本生成。举个例子:
(Disease hypertension, ASSOCIATES_DaG, Gene VHL) → `Disease hypertension associates Gene VHL`上下文剪枝
在KG-RAG框架中,Context Pruning(上下文剪枝)是一个关键步骤,就和dfs遍历时,需要剪枝来减少遍历时间一样,这里的剪枝可以减少给LLM的信息,减少token数量,同时过滤掉一些无用信心,还能提升LLM回答的精确性。
Context Pruning的具体做法还是会基于embedding来计算语义相似度,大概就是使用embedding模型计算三元组和query的cos相似度,最后选择策略:
- 条件一:上下文关联的余弦相似度必须大于所有提取上下文关联的相似度分布的75%分位
- 条件二:余弦相似度的最小值必须达到0.5
通过这个0.5 和 75%,可以有效减少给LLM的无效信息,有助于提高后续文本生成的准确性和相关性。
提示组装与文本生成
这里就简单了,就是和question一起,组合为propmt,再加上SYSTEM_PROMPT,送给LLM回答:
question = row["text"]
#检索
context = retrieve_context(question, vectorstore, embedding_function_for_context_retrieval, node_context_df, context_volume, QUESTION_VS_CONTEXT_SIMILARITY_PERCENTILE_THRESHOLD, QUESTION_VS_CONTEXT_MINIMUM_SIMILARITY, edge_evidence)
#
enriched_prompt = "Context: "+ context + "\n" + "Question: " + question
output = get_GPT_response(enriched_prompt, SYSTEM_PROMPT, CHAT_MODEL_ID, CHAT_DEPLOYMENT_ID, temperature=TEMPERATURE)
if not output:
enriched_prompt = "Context: "+ context + "\n" + "Question: "+ question这里的SYSTEM_PROMPT:
# One-Hop Validation
SINGLE_DISEASE_ENTITY_VALIDATION: |
You are an expert biomedical researcher. For answering the Question at the end, you need to first read the Context provided.
Then give your final answer by considering the context and your inherent knowledge on the topic. Give your answer in the following JSON format:
{Compounds: <list of compounds>, Diseases: <list of diseases>}
# Two-Hop Validation
TWO_DISEASE_ENTITY_VALIDATION: |
You are an expert biomedical researcher. For answering the Question at the end, you need to first read the Context provided.
Then give your final answer by considering the context and your inherent knowledge on the topic. Give your answer in the following JSON format:
{Nodes: <list of nodes>}运行的结果举例:
question = 'Does drug dependence have any genetic factors? Do you have any statistical evidence from trustworthy sources for this?'
KG_RAG_FLAG = True
EDGE_EVIDENCE_FLAG = True
generate_response(question, LLM_TO_USE, KG_RAG_FLAG, evidence_flag=EDGE_EVIDENCE_FLAG, temperature=TEMPERATURE)Yes, drug dependence does have genetic factors. The genes KAT2B and SLC25A16 have been associated with drug dependence. This information is backed by statistical evidence from the GWAS Catalog, with p-values of 4e-10 and 1e-09 respectively.
KG-RAG 在应用中落地思考
KG-RAG 给出了如何结合KG来做RAG的一个有效方案,但这里再工业场景中落地,还有很多是我们细致去思考的。比如NER实体识别这里,通过LLM来抽取,再来做entity link,这里的效率肯定是感人的,其实这里传统的bert模型就可以了,成本可以忽略不计。
再则,剪枝这里,原始的实现效率是很低的,这里的embedding模型也需要专门去微调训练。三元组转换成自然语言,这里也是有讲究,如何生成更通顺的自然语言,更好的做法LLM+人工,确定好模版,通过模版生成。另外,是先是被实体,然后去查询实体的关联子图,还是全图查询,通过实体来过滤,都是可以考虑的点。
总结
KG-RAG框架通过结合生物医学知识图谱和LLM,为生物医学领域的问题提供了通用的解决方案。不仅提高了模型的性能,而且简化了流程,使其更具成本效益和时间效率。
在其他领域如何去应用KG做RAG,一方面可以扩展该框架,另外一方面,也要结合自己的实际场景去定制具体的策略。