Elasticsearch open Inference API 增加了对 Cohere Rerank 3 模型的支持
Elasticsearch open Inference API 增加了对 Cohere Rerank 3 模型的支持

在最近的技术更新中,我们探索了一项新模型的集成,该模型旨在提升搜索结果的相关性和精确度。这一模型被称为“重排”(reranking),它通过对接现有的搜索系统提供的“前 n 个”搜索结果进行语义上的增强,从而改善了用户的搜索体验。
重排技术的工作原理是,它接收初步的搜索结果,并在此基础上进行进一步的优化,以提供更为精准的“前 n 个”结果。这个过程不需要对现有的模型或数据索引进行任何改动,从而降低了技术门槛,并能够直接提升搜索质量。
为了实现这一技术,我们与一个知名的技术团队进行了合作。他们提供了Cohere Rerank 3 模型,使得开发者可以轻松地在自己的系统中应用这种重排技术。这一合作的成果是,我们现在能够在 open Inference API 中无缝地支持这一新模型。
通过这种集成,我们希望能够为用户提供更加精细化的搜索结果,从而提升整体的搜索体验。这不仅能够提高搜索结果的相关性,还能够为大型语言模型(LLMs)提供更加丰富的上下文信息,进一步推动人工智能技术的发展。
Cohere 的 Rerank 3 模型可以添加到任何现有的 Elasticsearch 检索流程中,而无需进行任何重大的代码更改。鉴于 Elastic 的向量数据库和混合搜索能力,用户还可以将任何第三方模型的嵌入带入 Elastic,与 Rerank 3 一起使用。
Elastic 的混合搜索方法
在寻求实现 RAG(检索增强生成)时,检索和重排的策略是客户锚定 LLMs 并实现准确结果的关键优化。多年来,客户一直信任 Elastic 来处理他们的私有数据,并能够利用几种初级检索算法(例如,针对 BM25/关键词、密集和稀疏向量检索)。更重要的是,大多数现实世界的搜索用例都受益于 混合搜索,这是我们自 Elasticsearch 8.9 以来一直支持的。
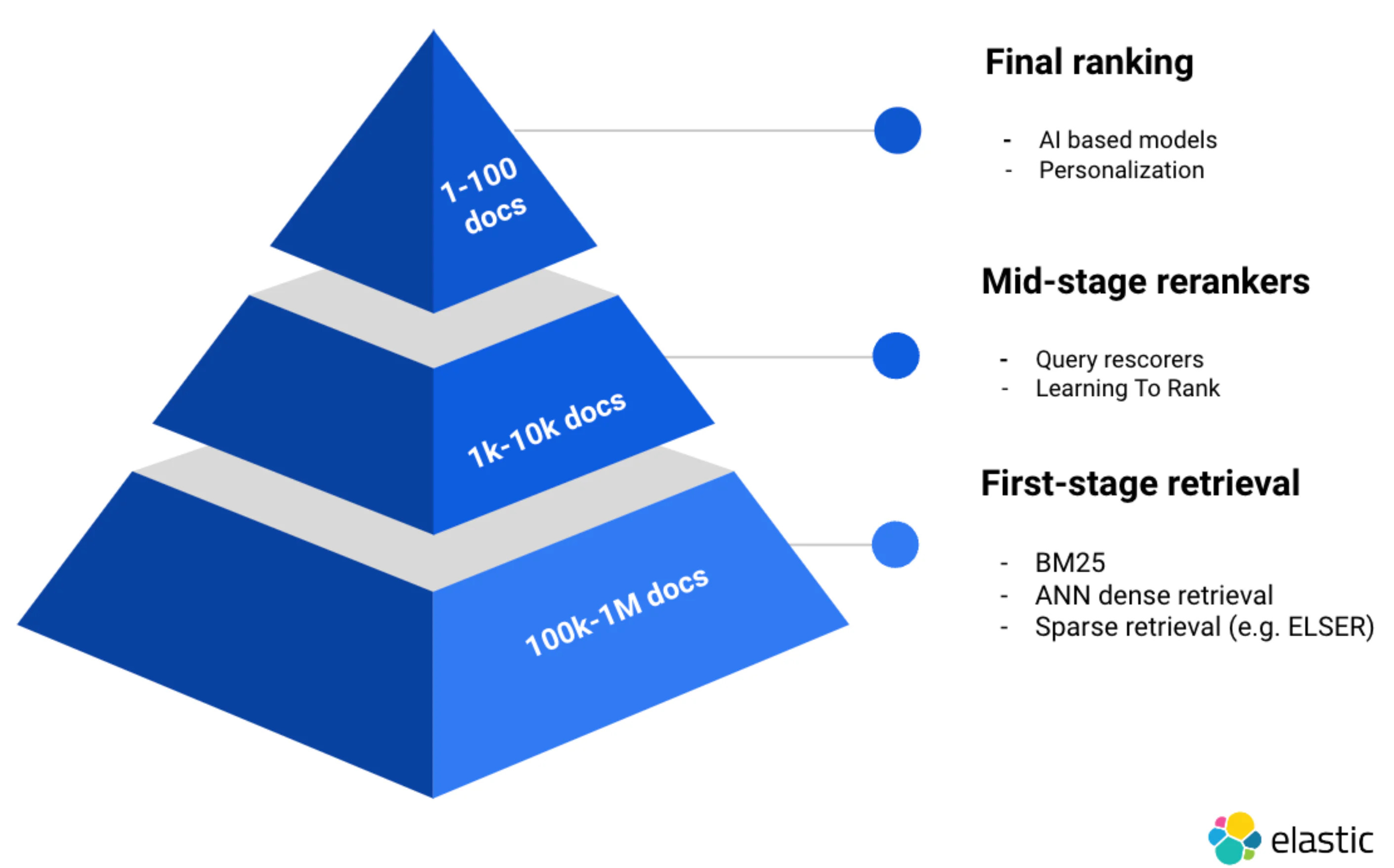
对于中级阶段的重排,我们还提供了对 Learning To Rank 和 查询重排 的原生支持。在这篇教程中,我们将重点关注 Cohere 的最后阶段重排能力,并将在后续的博客文章中涵盖 Elastic 的中级阶段重排能力!
Cohere 的重排方法
Cohere 通过他们的新 Rerank 模型取得了惊人的成果。在测试中,Cohere 报告称,特别是重排模型从长上下文中受益。为了适应模型令牌限制,对文档进行分块是进行密集向量检索时的必要约束。但是,基于 Cohere 的重排方法,可以基于整个文档中包含的上下文,而不仅仅是文档中的特定块,看到重排带来的显著好处。Rerank 有一个 4k 令牌限制,以输入更多的上下文,解锁将此模型纳入您的基于 Elasticsearch 的搜索系统中的全部相关性优势。
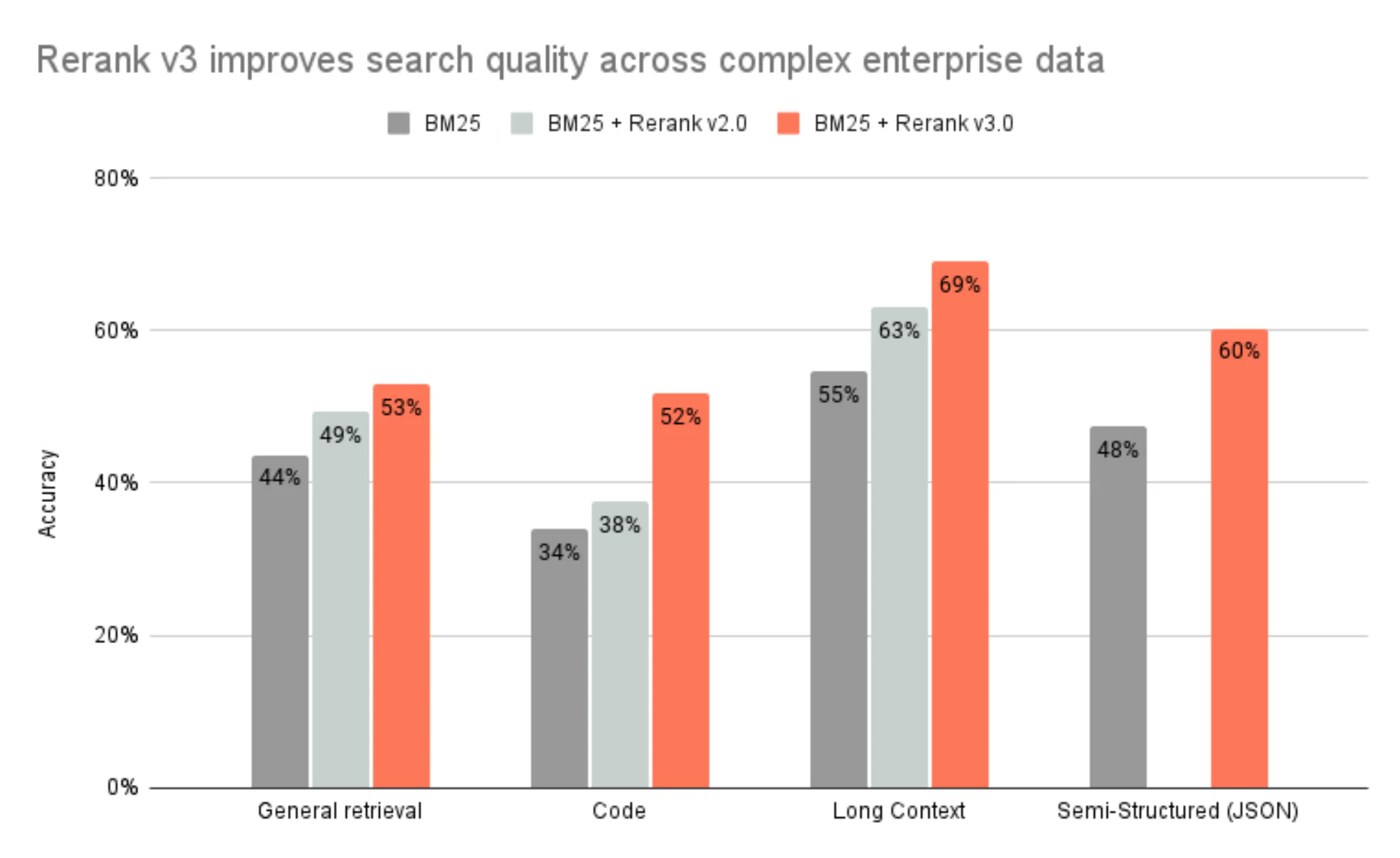
(i) 基于 BEIR 基准的一般检索;准确性以 nDCG@10 衡量
(ii) 基于 6 个常见代码基准的代码检索;准确性以 nDCG@10 衡量
(iii) 基于 7 个常见基准的长上下文检索;准确性以 nDCG@10 衡量
(iv) 基于 4 个常见基准的半结构化(JSON)检索;准确性以 nDCG@10 衡量
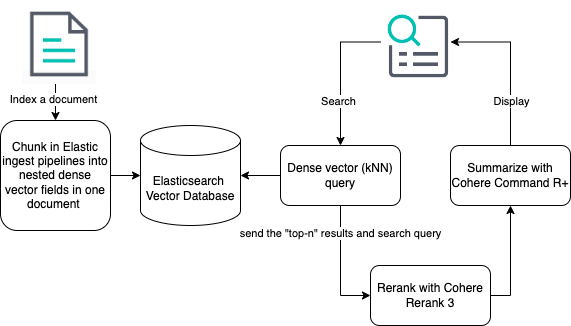
如果您对如何使用 LangChain 和 LlamaIndex 进行分块感兴趣,我们在 Search Labs 中提供了聊天应用程序参考代码、集成等,并在我们的开源 仓库 中提供了更多信息。或者,您可以利用 Elastic 的 段落检索 能力,并使用 摄取管道 进行分块。
使用 Elasticsearch 和 Cohere 构建 RAG 实现
现在您已经对如何利用这些能力有了一般性的了解,让我们来看一个使用 Elasticsearch 和 Cohere 构建 RAG 实现的例子。
您需要一个 Cohere 账户,并且需要对 Cohere Rerank 端点 有一定的了解。如果您打算使用 Cohere 的最新生成模型 Command R+,请熟悉 Chat 端点。在 Kibana 中,您将获得一个控制台,即使没有设置 IDE,也可以在 Elasticsearch 中输入以下步骤。如果您更喜欢使用语言客户端,您可以在 提供的指南 中重新审视这些步骤。
Elasticsearch 向量数据库
在之前的公告中,我们有一些步骤可以帮助您开始使用 Elasticsearch 向量数据库。您可以通过阅读 公告 来回顾如何摄取一个示例 books 目录,并使用 Cohere 的嵌入功能生成嵌入。或者,如果您更喜欢,我们还提供了一个 教程 和 Jupyter 笔记本 来开始这个过程。
Cohere 重排
以下部分假设您已经摄取了数据并执行了第一次搜索。这将为您提供一个基线,以了解在您第一次密集向量检索时搜索结果是如何排名的。
现在,假设目前我们已对样本books目录的查询结束,并根据查询字符串 "Snow "生成了以下结果。这些结果按相关性降序返回。
{
"took": 201,
"timed_out": false,
"_shards": {
"total": 3,
"successful": 3,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 6,
"relation": "eq"
},
"max_score": 0.80008936,
"hits": [
{
"_index": "cohere-embeddings",
"_id": "3VAixI4Bi8x57NL3O03c",
"_score": 0.80008936,
"_source": {
"name": "Snow Crash",
"author": "Neal Stephenson"
}
},
{
"_index": "cohere-embeddings",
"_id": "4FAixI4Bi8x57NL3O03c",
"_score": 0.6495671,
"_source": {
"name": "Fahrenheit 451",
"author": "Ray Bradbury"
}
},
{
"_index": "cohere-embeddings",
"_id": "31AixI4Bi8x57NL3O03c",
"_score": 0.62768984,
"_source": {
"name": "1984",
"author": "George Orwell"
}
},
{
"_index": "cohere-embeddings",
"_id": "4VAixI4Bi8x57NL3O03c",
"_score": 0.6197722,
"_source": {
"name": "Brave New World",
"author": "Aldous Huxley"
}
},
{
"_index": "cohere-embeddings",
"_id": "3lAixI4Bi8x57NL3O03c",
"_score": 0.61449933,
"_source": {
"name": "Revelation Space",
"author": "Alastair Reynolds"
}
},
{
"_index": "cohere-embeddings",
"_id": "4lAixI4Bi8x57NL3O03c",
"_score": 0.59593034,
"_source": {
"name": "The Handmaid's Tale",
"author": "Margaret Atwood"
}
}
]
}
}接下来,您将希望为 Cohere Rerank 配置一个推理端点,指定 Rerank 3 模型和 API 密钥。
PUT _inference/rerank/cohere_rerank {
"service": "cohere",
"service_settings": {
"api_key": <API-KEY>,
"model_id": "rerank-english-v3.0"
},
"task_settings": {
"top_n": 10,
"return_documents": true
}
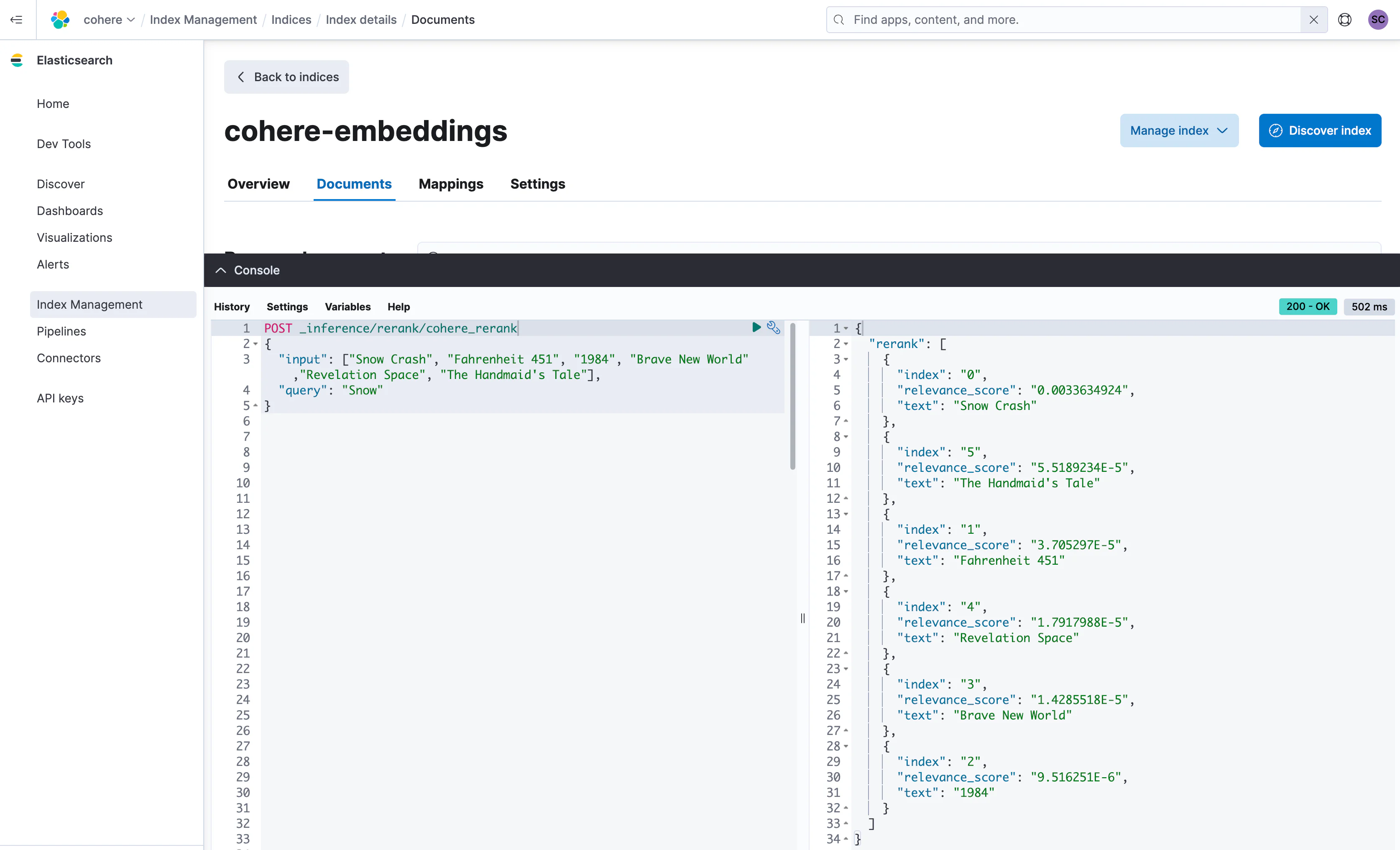
}一旦这个推理端点被指定,您现在可以通过传入用于检索的原始查询“Snow”以及我们刚刚使用 kNN 搜索检索到的文档来重新对结果进行排名。记住,您也可以使用任何 混合 搜索 查询来重复这个过程!
为了在 dev console 中演示这一点,我们将对上面的 JSON 响应进行一些清理。
取 JSON 响应中的 hits,形成以下 JSON 的 input,然后 POST 到我们刚刚配置的 cohere_rerank 端点。
POST _inference/rerank/cohere_rerank {
"input": ["Snow Crash", "Fahrenheit 451", "1984", "Brave New World", "Revelation Space", "The Handmaid's Tale"],
"query": "Snow"
}就这样,您的结果已经使用 Cohere 的 Rerank 3 模型进行了重排。
我们用于说明这些能力的 books 语料库并不包含大段落,是一个相对简单的例子。当您将此应用于自己的搜索体验时,我们建议您遵循 Cohere 的方法,用从第一次检索结果集中返回的完整文档中的上下文填充您的 input,而不仅仅是文档中的检索块。
Elasticsearch 加速路线图,实现语义重排和检索器
在 即将到来的 Elasticsearch 版本中,我们将继续为中阶段和最终阶段的重排器构建无缝支持。我们的最终目标是使开发人员能够使用语义重排来改善任何搜索的结果,无论是 BM25、密集或稀疏向量检索,还是与混合检索的组合。为了提供这种体验,我们正在构建一个名为 retrievers 的概念到查询 DSL 中。Retrievers 将提供一种直观的方式来执行语义重排,并且还将使直接执行您在 Elasticsearch 栈中的开放推理 API 中配置的内容成为可能,而不需要您在应用程序逻辑中执行此操作。
当在早期的密集向量示例中加入检索器的使用时,这是重排体验可能有多么不同的样子:
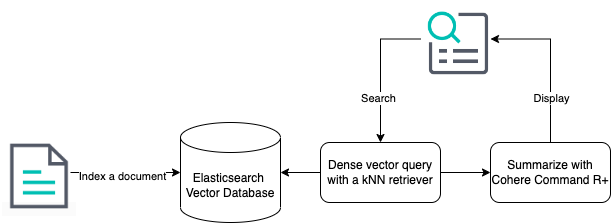
(i) Elastic 的路线图: 索引步骤通过添加 Elastic 未来的能力来自动分块索引数据而得到简化
(ii) Elastic 的路线图: kNN 检索器指定了配置为推理端点的模型(在本例中为 Cohere 的 Rerank 3)
(iii) Cohere 的路线图: 发送结果数据到 Cohere 的 Command R+ 之间的步骤将从计划中名为 extractive snippets 的功能中受益,该功能将使用户能够返回重排文档的相关块到 Command R+ 模型
这是我们在 books 语料库上执行的原始 kNN 密集向量搜索,返回了“Snow”的第一个结果集。
GET cohere-embeddings/_search {
"knn": {
"field": "name_embedding",
"query_vector_builder": {
"text_embedding": {
"model_id": "cohere_embeddings",
"model_text": "Snow"
}
},
"k": 10,
"num_candidates": 100
},
"_source": [
"name",
"author"
]
}正如本博客所解释的,有几个步骤来检索文档并将正确的响应传递给推理端点。在本文发表时,这个逻辑应该在您的应用程序代码中处理。
在未来,检索器可以直接在单个 API 调用中配置为使用 Cohere rerank 推理端点。
{
"retriever": {
"text_similarity_rank": {
"retriever": {
"knn": {
"field": "name_embedding",
"query_vector_builder": {
"text_embedding": {
"model_id": "cohere_embeddings",
"model_text": "Snow"
}
},
"k": 10,
"num_candidates": 100
}
},
"field": "name",
"window_size": 10,
"inference_id": "cohere_rerank",
"inference_text": "Snow"
}
},
"_source": [
"name",
"author"
]
}在这种情况下,kNN 查询与我的原始查询完全相同,但是在输入到 rerank 端点之前的响应清理将不再是一项必要的步骤。检索器将知道已经执行了 kNN 查询,并无缝地使用在配置中指定的 Cohere rerank 推理端点进行重排。同样的原则可以应用于 任何 搜索,BM25、密集、稀疏和混合。
检索器作为出色语义重排的推动者,是我们积极且近期路线图的一部分。
Cohere 的生成模型能力
现在您已经准备好了一套经过语义重排的文档集,可以用来为您选择的大型语言模型的响应提供基础!我们推荐 Cohere 的最新生成模型 Command R+。在构建完整的 RAG 管道时,在您的应用程序代码中,您可以轻松地向 Cohere 的 Chat API 发出命令,附带用户查询和重排后的文档。
下面是一个如何在您的 Python 应用程序代码中实现这一点的示例:
response = co.chat(message=query, documents=documents, model='command-r-plus')
source_documents = [] for citation in response.citations: for document_id in citation.document_ids: if document_id not in source_documents: source_documents.append(document_id)
print(f"Query: {query}")
print(f"Response: {response.text}")
print("Sources:")
for document in response.documents:
if document['id'] in source_documents:
print(f"{document['title']}: {document['text']}")这种与 Cohere 的集成在 Serverless 中提供,并且很快将在 Elastic Cloud 或您的笔记本电脑或自管理环境中的版本化 Elasticsearch 版本中尝试。我们建议您使用我们的 Elastic Python 客户端 v0.2.0 来开始您的 Serverless 项目!
愉快的重排体验!
本文系外文翻译,前往查看
如有侵权,请联系?cloudcommunity@tencent.com?删除。
本文系外文翻译,前往查看
如有侵权,请联系?cloudcommunity@tencent.com 删除。