以中文为中心!复旦 & 北大 | 从头训练中文大模型:CT-LLM
以中文为中心!复旦 & 北大 | 从头训练中文大模型:CT-LLM

引言
当前,绝大多数大模型(LLMs)基本上都是以英文语料库训练得到的,然后经过SFT来匹配不同的语种。然而,今天给大家分享的这篇文章旨在从头开始训练中文大模型,在训练过程中「主要纳入中文文本数据」,最终作者得到了一个2B规模的中文Tiny LLM(CT-LLM)。结果表明,该模型在中文任务上表现出色,且通过SFT也能很好的支持英文。

https://arxiv.org/pdf/2404.04167.pdf
背景介绍
随着人工智能的快速发展,当前大模型(LLMs)已然成为了自然语言处理的基石,它们在理解、文本生成、推理等方面展现出了杰出的能力。然而,当前的主流模型大都基于英文数据集训练得到了,并以设定了很多评估基准,尽管有研究表明,大模型在多语言上面具有一定的泛化能力,但对于英文的重视会掩盖语言固有的多样性,这也将会限制LLM的使用和创新性发展。目前,关于非英语大模型的探索仍然是一个未知的领域。
「泛化不确定性」 随着对于精通双语或多语功能的模型的需求日益增长,特别是能够适应中文语言应用的模型。为满足这种需求,人们已经采取了多种策略来增强LLMs的多语言能力,特别强调在预训练阶段加入更高比例的中文Token,或者采用监督式微调(SFT)等技术来激活大模型的中文语言功能。ChatGLM是一个早期的例子,它在预训练阶段采用了中文和英文Token的等量分布,最终形成了一个精通双语的模型。尽管如此,以中文为基础训练的LLM进行多语言泛化仍然具有不确定性。
「中文数据集缺乏」 预训练数据对于开发语言模型至关重要,它为模型学习和理解人类语言提供了基础。尽管大量的英语数据显著推动了英语大型语言模型(LLMs)的发展,但中文预训练数据的情况却呈现出巨大潜力与显著缺乏的对比。尽管中文互联网上有大量的数据可用,但中文预训练数据集相对较少,这引起了对多样性和质量的担忧。总之,现有的预训练数据集要么在数量上缺乏,要么在质量上有所妥协,这强调了探索以中文为中心的大模型预训练的重要性。这样的探索对于理解当代中文语言数据的特点和中文语言的识别应用至关重要。
基于以上考虑,「本文作者挑战以英语为中心的主流模型训练范式,考虑以中文为基础的预训练模型是否可以激活对其它语言的能力」。以中文为中心的方法如果成功,可能会显著推动语言技术的民主化,为创造反映全球语言多样性的包容性模型提供洞见。
CT-LLM预训练
CT-LLM(Chinese Tiny LLM)的预训练是非常重要的一步,它为模型提供了理解和处理中文文本的基础。
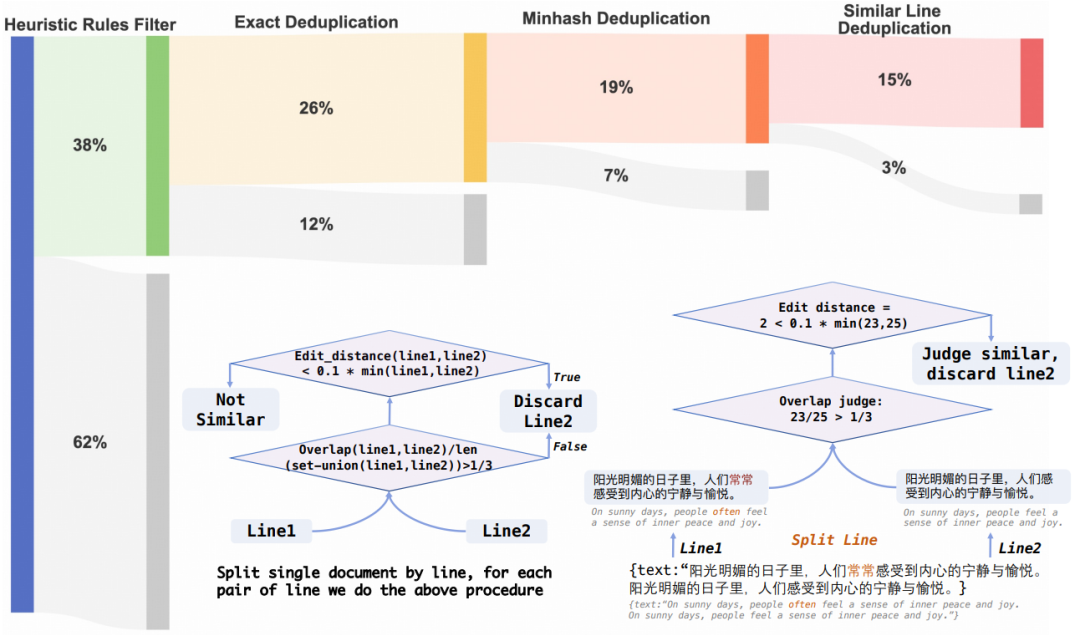
「数据准备」 作者收集了1254.68亿个token,其中包括840.48亿个中文token、314.88亿个英文token和99.3亿个代码token。这些数据来源于多样化的渠道,如Common Crawl的网络文档、学术论文、百科全书和书籍等。通过精心设计的启发式规则,对数据进行了过滤和去重,以确保数据集的质量和多样性。数据处理过程如下所示:
「模型架构」 CT-LLM的架构基于Transformer解码器,模型的关键参数设置如下所示:

为了提高模型的性能,作者采用了多头注意力机制,并引入了RoPE(Rotary Positional Embeddings)嵌入来替代绝对位置嵌入,同时在各层之间共享嵌入,以减少模型大小。此外,模型使用了SwiGLU激活函数和RMSNorm归一化处理,这些都是为了优化模型的训练和性能。
「预训练」 模型在4096个token的上下文长度上进行训练,这有助于模型捕捉长距离依赖关系。为了有效地处理大量的数据,CT-LLM使用了baichuan2分词器进行数据token化,该分词器利用SentencePiece的字节对编码(BPE)方法,并特别设计了对数字的编码方式,以增强对数值数据的处理能力。
CT-LLM微调
微调过程不仅增强了模型的语言理解能力,还通过直接从人类偏好中学习,提高了模型的实用性和安全性。
「监督微调」 为了进行监督式微调,研究者们使用了包括中文和英文数据的多种数据集。中文数据集包括CQIA、OL-CC以及从COIG-PC中采样的高质量数据。英文数据则来自OpenHermesPreferences数据集。
除此之外,根据中文数据的体量,英文数据的比例进行了调整,比例设置为1:1、2:1、4:1和8:1,同时还有只包含中文数据和只包含英文数据的配置。这样的多样性比例旨在模拟不同语言环境下的实际应用场景。
「DPO」 采用了直接偏好优化(DPO)技术,通过比较响应对的排名直接从人类偏好中学习。偏好数据集包括公开可用的数据集和LLM生成的合成数据。为了构建更高质量的偏好数据集,研究者们采用了alpaca-gpt4生成的"chosen"响应和baichuan-6B生成的"reject"响应。数据集总共包含183k个中文对和46k个英文对。
实验结果
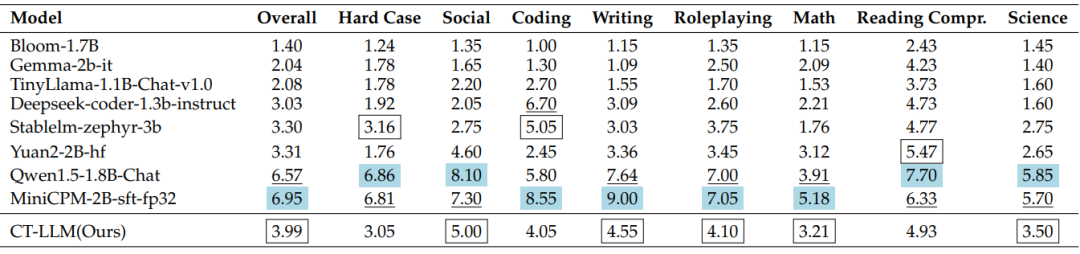
如下图所示,CT-LLM与其他类似规模的基线模型进行了性能比较。CT-LLM在多数任务上展现出了竞争力,尤其是在中文任务上的表现尤为突出,这表明了模型在处理中文文本方面的有效性和适应性。

CT-LLM在CHC-Bench基准测试中的表现如下图所示。模型在社会理解和写作方面表现出色,这反映了其在处理与中国文化相关的语境时的强大能力。