使用 LlamaIndex、Elasticsearch 和 Mistral 进行检索增强生成(RAG)
原创使用 LlamaIndex、Elasticsearch 和 Mistral 进行检索增强生成(RAG)
原创
在这篇文章中,我们将探讨如何使用Elasticsearch作为向量数据库,结合RAG技术(检索增强生成)来实现问答体验。我们会使用LlamaIndex和一个本地运行的Mistral LLM模型。
在开始之前,让我们先了解一下相关术语。
术语解释
LlamaIndex 是构建LLM(大型语言模型)应用的领先数据框架。LlamaIndex为构建RAG(检索增强生成)应用的各个阶段提供了抽象。像LlamaIndex和LangChain这样的框架提供了抽象层,使得应用程序不会紧密绑定到任何特定LLM的API上。
Elasticsearch 是由Elastic提供的一项服务。Elastic是Elasticsearch背后的行业领导者,这是一个支持全文搜索以实现精确性、向量搜索以实现语义理解和混合搜索以获得两者最佳效果的搜索和分析引擎。Elasticsearch是一个功能齐全的向量数据库。本文中使用的Elasticsearch功能可在腾讯云 Elasticsearch Service上体验。
检索增强生成(RAG) 是一种AI技术/模式,其中LLM被提供外部知识以生成对用户查询的响应。这使得LLM的响应能够针对特定上下文进行定制,从而使响应更加具体。
Mistral 提供开源和优化的企业级LLM模型。在本教程中,我们将使用他们的开源模型mistral-7b,它可以在你的笔记本电脑上运行。如果你不想在本地运行模型,你也可以选择使用他们的云版本,这种情况下你需要修改本文中的代码以使用正确的API密钥和包。
Ollama 帮助在本地笔记本电脑上运行LLM。我们将使用Ollama来本地运行开源的Mistral-7b模型。
嵌入(Embeddings) 是文本/媒体含义的数值表示。它们是高维信息的低维表示。
我们将要构建什么?
场景:
我们有一个虚构的家庭保险公司呼叫中心对话的样本数据集(作为一个JSON文件)。我们将构建一个简单的RAG应用,它可以回答如下问题:
给我概述一下与水有关的问题。
高层次流程
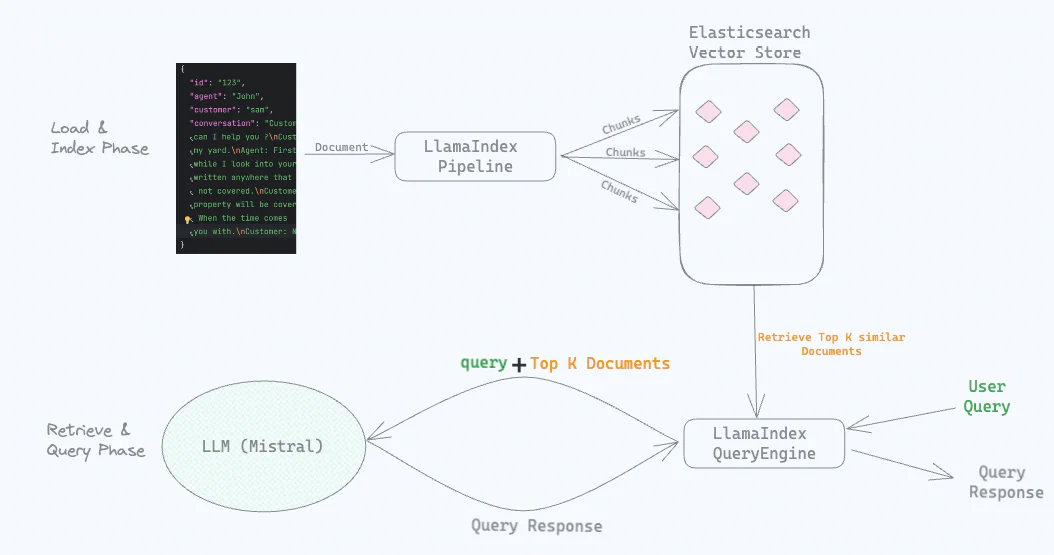
我们使用Ollama在本地运行Mistral LLM。
接下来,我们将从JSON文件中加载“对话”作为文档进入ElasticsearchStore(这是一个由Elasticsearch支持的向量存储)。在加载文档的同时,我们使用本地运行的Mistral模型创建嵌入,并将其与“对话”一起存储在LlamaIndex Elasticsearch向量存储中。
我们配置了一个LlamaIndex的摄取管道(IngestionPipeline),并提供了我们在此案例中使用的本地LLM,即通过Ollama运行的Mistral。
当我们提出问题,如“给我概述一下与水有关的问题”时,Elasticsearch进行语义搜索并返回与水问题相关的“对话”。这些“对话”连同原始问题一起被发送到本地运行的LLM以生成答案。
构建RAG应用的步骤
本地运行Mistral
下载并安装Ollama。安装完Ollama后,运行以下命令以下载并运行mistral:
ollama run mistral第一次在本地下载和运行模型可能需要几分钟时间。通过提出类似“写一首关于云的诗”这样的问题来验证mistral是否运行正常,并确保诗歌符合你的喜好。在后续的代码交互中我们需要保持Ollama运行。
安装Elasticsearch
通过创建云部署(安装指南)或在docker中运行(安装指南)来启动并运行Elasticsearch。你也可以从这里开始创建一个生产级别的自托管Elasticsearch部署。
假设你使用的是云部署,根据指南获取API密钥和云ID。我们将在后续步骤中使用它们。
RAG应用
参考代码可以在Github仓库中找到。克隆仓库是可选的,因为我们将在下面逐步介绍代码。
在你最喜欢的IDE中,创建一个新的Python应用程序,并包含以下3个文件:
index.py,与索引数据相关的代码。query.py,与查询和LLM交互相关的代码。.env,存储配置属性,如API密钥。
我们需要安装一些包。首先,在应用程序的根目录下创建一个新的Python 虚拟环境。
python3 -m venv .venv激活虚拟环境并安装以下所需包。
source .venv/bin/activate
pip install llama-index
pip install llama-index-embeddings-ollama
pip install llama-index-llms-ollama
pip install llama-index-vector-stores-elasticsearch
pip install sentence-transformers
pip install python-dotenv配置Elasticsearch端点和API密钥。
索引数据
下载conversations.json文件,其中包含了我们虚构的家庭保险公司的顾客和呼叫中心代理之间的“对话”。将文件放置在应用程序的根目录下,与之前创建的两个Python文件和.env文件一起。下面是文件内容的一个示例。
{
"conversation_id": 103,
"customer_name": "Sophia Jones",
"agent_name": "Emily Wilson",
"policy_number": "JKL0123",
"conversation": "顾客:嗨,我是Sophia Jones。我的出生日期是1985年11月15日,地址是303 Cedar St, Miami, FL 33101,我的保单号是JKL0123。\n代理:你好,Sophia。今天有什么可以帮助你的吗?\n顾客:你好,Emily。我有关于我的保单的问题。\n顾客:我家发生了入室盗窃,一些贵重物品丢失了。这些物品有保险覆盖吗?\n代理:让我检查一下你的保单涵盖的盗窃相关保险。\n代理:是的,个人财物的盗窃在你的保单下是有保险覆盖的。\n顾客:这真是个好消息。我需要为被盗物品提出索赔。\n代理:我们会协助你进行索赔流程,Sophia。还有其他我可以帮助你的吗?\n顾客:没有了,现在就这样。感谢你的帮助,Emily。\n代理:不客气,Sophia。如果你有任何其他问题或疑虑,请随时联系我。\n顾客:我会的。祝你有个愉快的一天!\n代理:你也一样,Sophia。保重。",
"summary": "一位顾客在入室盗窃后询问了有关被盗物品保险覆盖的问题,代理确认个人财物的盗窃在保单下是有保险覆盖的。代理提供了索赔流程的协助,顾客表示了宽慰和感激。"
}我们在index.py中定义了一个名为get_documents_from_file的函数,它读取json文件并创建一个文档列表。文档对象是LlamaIndex处理信息的基本单位。
# index.py
import json, os
from llama_index.core import Document, Settings
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.ingestion import IngestionPipeline
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.vector_stores.elasticsearch import ElasticsearchStore
from dotenv import load_dotenv
def get_documents_from_file(file):
"""读取json文件并返回文档列表"""
with open(file=file, mode='rt') as f:
conversations_dict = json.loads(f.read())
# 使用感兴趣的字段构建文档对象。
documents = [Document(text=item['conversation'], metadata={"conversation_id": item['conversation_id']}) for item in conversations_dict]
return documents创建摄取管道
首先,在.env文件中添加你在安装Elasticsearch部分获得的Elasticsearch CloudID和API密钥。你的.env文件应该如下所示(使用真实值)。
ELASTIC_CLOUD_ID=<替换为你的云ID>
ELASTIC_API_KEY=<替换为你的API密钥>LlamaIndex的摄取管道允许你使用多个组件来构建一个管道。将以下代码添加到index.py文件中。
# index.py
# 加载.env文件内容到env
# ELASTIC_CLOUD_ID和ELASTIC_API_KEY预期在.env文件中
load_dotenv('.env')
# ElasticsearchStore是一个VectorStore,负责ES索引和数据管理。
es_vector_store = ElasticsearchStore(index_name="calls", vector_field='conversation_vector', text_field='conversation', es_cloud_id=os.getenv("ELASTIC_CLOUD_ID"), es_api_key=os.getenv("ELASTIC_API_KEY"))
def main():
# 使用Ollama进行本地嵌入的嵌入模型。
ollama_embedding = OllamaEmbedding("mistral")
# LlamaIndex管道配置,处理分块、嵌入,并将嵌入存储在向量存储中。
pipeline = IngestionPipeline(transformations=[SentenceSplitter(chunk_size=350, chunk_overlap=50), ollama_embedding,], vector_store=es_vector_store)
# 从json文件加载数据到LlamaIndex文档列表
documents = get_documents_from_file(file="conversations.json")
pipeline.run(documents=documents)
print("....管道运行完成.....\n")
if __name__ == "__main__":
main()如前所述,LlamaIndex的摄取管道可以由多个组件组成。我们在pipeline = IngestionPipeline(...)这行代码中添加了3个组件。
- SentenceSplitter:如
get_documents_from_file()的定义所示,每个文档都有一个文本字段,其中包含json文件中的对话。这个文本字段是一段很长的文本。为了使语义搜索能够良好工作,需要将其分解成更小的文本块。SentenceSplitter类为我们完成了这项工作。这些块在LlamaIndex术语中被称为节点。节点中有元数据指向它们所属的文档。或者,你也可以使用Elasticsearch的摄取管道进行分块,如这篇博客所示。 - OllamaEmbedding:嵌入模型将文本转换为数字(也称为向量)。有了数值表示,我们就可以运行语义搜索,搜索结果匹配的是词的含义,而不仅仅是文本搜索。我们为摄取管道提供了
OllamaEmbedding("mistral")。我们使用SentenceSplitter分割的块被发送到通过Ollama在本地机器上运行的Mistral模型,然后mistral为这些块创建嵌入。 - ElasticsearchStore:LlamaIndex的ElasticsearchStore向量存储将创建的嵌入存储到Elasticsearch索引中。创建ElasticsearchStore时(由
es_vector_store引用),我们提供了我们想要创建的Elasticsearch索引的名称(在我们的例子中是calls),我们希望存储嵌入的字段(在我们的例子中是conversation_vector),以及我们想要存储文本的字段(在我们的例子中是conversation)。总之,根据我们的配置,ElasticsearchStore在Elasticsearch中创建了一个新的索引,其中conversation_vector和conversation作为字段(还有其它自动创建的字段)。
将所有这些都结合起来,我们通过调用pipeline.run(documents=documents)来运行管道。
运行index.py脚本以执行摄取管道:
python index.py一旦管道运行完成,我们应该在Elasticsearch中看到一个名为calls的新索引。使用Dev Console运行一个简单的elasticsearch查询,你应该能够看到加载的数据以及嵌入。
GET calls/_search?size=1到目前为止,我们所做的是从JSON文件创建文档,我们将它们分块,为这些块创建嵌入,并将嵌入(和文本对话)存储在一个向量存储(ElasticsearchStore)中。
查询
llamaIndex的VectorStoreIndex允许你检索相关文档和查询数据。默认情况下,VectorStoreIndex将嵌入存储在内存中的一个SimpleVectorStore。然而,也可以使用外部向量存储(如ElasticsearchStore)来使嵌入持久化。
打开query.py并粘贴以下代码:
# query.py
from llama_index.core import VectorStoreIndex, QueryBundle, Response, Settings
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.llms.ollama import Ollama
from index import es_vector_store
# 本地LLM用于发送用户查询
local_llm = Ollama(model="mistral")
Settings.embed_model = OllamaEmbedding("mistral")
index = VectorStoreIndex.from_vector_store(es_vector_store)
query_engine = index.as_query_engine(local_llm, similarity_top_k=10)
query="给我概述一下与水有关的问题"
bundle = QueryBundle(query, embedding=Settings.embed_model.get_query_embedding(query))
result = query_engine.query(bundle)
print(result)我们定义了一个本地LLM(local_llm),指向运行在Ollama上的Mistral模型。接下来,我们从之前创建的ElasticsearchStore向量存储创建了一个VectorStoreIndex(index),然后我们从索引中获取一个查询引擎。在创建查询引擎时,我们引用了应该用于响应的本地LLM,我们还提供了(similarity_top_k=10)来配置应该从向量存储中检索并发送到LLM以获得响应的文档数量。
运行query.py脚本以执行RAG流程:
python query.py我们发送查询给我概述一下与水有关的问题(你可以自由定制query),LLM的响应应该是类似于以下内容。
在提供的上下文中,我们看到了几个顾客询问有关水损保险覆盖的问题。在两个案例中,洪水导致了地下室的损坏,另一个案例中,屋顶漏水是问题所在。代理确认这两种类型的水损都在他们的保单覆盖范围内。因此,水相关问题包括洪水和屋顶漏水通常都在家庭保险政策的覆盖范围内。
一些注意事项:
这篇博客文章是对RAG技术与Elasticsearch的初学者介绍,因此省略了一些功能的配置,这些功能将使你能够将这个起点提升到生产级别。在为生产用例构建时,你可能会考虑更复杂的方面,比如能够使用文档级安全来保护你的数据,作为Elasticsearch 摄取管道的一部分进行数据分块,或者甚至在用于GenAI/Chat/Q&A用例的同一数据上运行其他ML作业。
你可能还想考虑使用Elastic连接器从各种外部源(例如Azure Blob Storage、Dropbox、Gmail等)获取数据并创建嵌入。
Elastic使得上述所有功能以及更多成为可能,并为GenAI用例及其它方面提供了一个全面的企业级解决方案。
下一步是什么?
- 你可能已经注意到,我们将10个相关的对话与用户问题一起发送给LLM以制定响应。这些对话可能包含PII(个人可识别信息)如姓名、出生日期、地址等。在我们的情况下,LLM是本地的,所以数据泄露不是问题。然而,当你想要使用在云中运行的LLM(例如OpenAI)时,发送包含PII信息的文本是不可取的。在后续的博客中,我们将看到如何在RAG流程中屏蔽PII信息后再发送到外部LLM。
- 在这篇文章中,我们使用了一个本地LLM,在即将推出的关于RAG中屏蔽PII数据的帖子中,我们将探讨如何从本地LLM轻松切换到公共LLM。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。