利用客户端的计算资源,为现代大型模型开发提供新的动力
利用客户端的计算资源,为现代大型模型开发提供新的动力

运维开发王义杰
发布于 2024-04-15 13:52:35
发布于 2024-04-15 13:52:35
引言
随着技术的发展,大型模型在处理复杂任务时表现出越来越强的能力,无论是在自然语言处理、图像识别还是其他领域。然而,这些模型往往需要巨大的计算资源,这对于许多企业和个人来说,是一笔不小的开销。当前,绝大多数的大型模型运算都在服务器端完成,客户端仅作为发送请求和接收结果的媒介。如果能有效地利用客户端的计算资源,不仅可以减轻服务器的计算压力,还能提高响应速度,优化用户体验。
客户端计算资源的优势与挑战
优势
- 降低服务器压力:通过分散计算任务到客户端,服务器可以处理更多的请求,提高整体的服务能力。
- 加快响应速度:对于一些处理结果需要实时反馈的任务,利用客户端进行部分计算可以显著提高响应速度。
- 提升数据隐私保护:通过在客户端处理敏感数据,减少数据在网络中的传输,有利于提高数据的安全性和隐私性。
挑战
- 客户端性能差异大:不同的客户端设备,其计算能力差异显著,需要动态调整计算任务的分配。
- 网络状态不稳定:客户端与服务器之间的网络状态不稳定可能会影响计算任务的分发和结果的收集。
- 开发和维护成本增加:需要开发额外的客户端计算框架和算法,以适应不同性能的设备,并保证计算的正确性和安全性。
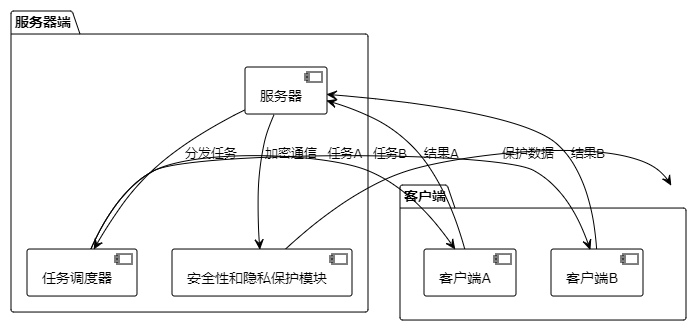
实现策略
轻量级模型分发
针对不同能力的客户端,服务器可以分发不同规模的模型,确保在不超过客户端处理能力的前提下,最大限度地利用其计算资源。
任务拆分与合作计算
将大型计算任务拆分成多个小任务,分发到多个客户端并行处理,最后将结果汇总。这要求有高效的任务调度算法和稳定的网络通信机制。
缓存与预计算
对于一些重复性高的计算任务,可以在客户端缓存结果,或者在客户端空闲时进行预计算和存储,以便于快速响应。
安全性与隐私保护
在设计客户端计算框架时,需要特别注意数据的安全性和隐私保护,避免敏感信息泄露和被恶意利用。
结论
随着设备性能的提升和计算需求的增长,利用客户端的计算资源,不仅可以提升大型模型的运算效率和用户体验,还有助于降低运维成本和保护用户隐私。然而,这也带来了不少挑战,需要在保证计算正确性、安全性和效率的基础上,探索出一套合理的计算资源分配和利用机制。未来,随着技术的不断进步,客户端计算无疑将在大型模型的应用中发挥越来越重要的作用。
本文参与?腾讯云自媒体分享计划,分享自微信公众号。
原始发表:2024-04-06,如有侵权请联系?cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读