面向程序员的 Mojo? 入门指南


前言
学习一门新的编程语言很难。必须学习新的语法、关键字和最佳实践,所有这些在刚刚开始学习时都会令人沮丧。
Mojo 是作为 Python 的超集而设计的。因此,如果了解 Python,那么很多 Mojo 代码看起来都会很熟悉。然而,Mojo 首先是为高性能系统编程而设计的,它具有强大的类型检查、内存安全、新一代编译器技术等特性。因此,Mojo 与 C++ 和 Rust 等语言有很多共同之处。
然而,Mojo 设计非常灵活,因此可以根据需要逐步采用强类型检查等系统编程特性--Mojo 并不要求强类型检查。
Mojo?: 熟悉的方法
对于任何 Python 程序员来说,Mojo应该是相当熟悉的,因为它与 Python 共享语法。然而,当我们尝试将一个简单的 Python 程序移植到 Mojo 时,会发现一些重要的区别。首先,Mojo在性能方面表现非常出色。
你可能会说:"但 Python 也不是省油的灯--NumPy 真的很快!"
但是,如果仔细观察 NumPy 优雅的 Python API 的底层实现,就会发现所有计算密集型代码都是用 C/C++ 编写的,这正是其性能的秘密所在。
有了Mojo,可以编写类似 Python 的高级代码,并利用Mojo的底层功能来显式管理内存、添加类型等,从而获得接近甚至更优于C语言的性能。这意味着可以在Mojo中获得两个世界的最佳性能,而无需用多种语言编写算法。
从 Python 到 Mojo
让我们从一个简单的例子开始,计算两个向量之间的欧氏距离。在数学上,欧氏距离表示为差分向量的 L2 范数,记作 || a - b || ,其中 a 和 b 是两个 n 维向量。
欧氏距离计算是科学计算和机器学习中最基本的计算之一,用于 k 近邻和相似性搜索等算法。在本示例中,将看到如何利用 Mojo 的高维向量在这项任务中获得比 NumPy 更快的性能。这是一个计算密集型问题,因此我们将从头开始,用 Python 构建一个解决方案,并将其引入 Mojo 以提高性能。
算法实现
- 计算两个向量之间的元素差,创建一个差向量;
- 对差分向量中的每个元素进行平方;
- 求出差分向量中所有元素的平方和;
- 取总和的平方根;
这 4 个步骤如下图所示:

添加描述
在我们的实现中,向量 n 的维数就是数组或列表中元素的个数。在纯 Python 中,可以这样写
def python_naive_dist(a,b):
s = 0.0
n = len(a)
for i in range(n):
dist = a[i] - b[i]
s += dist*dist
return sqrt(s)复制运行
Python 中的欧氏距离
首先,让我们通过运行和基准测试纯 Python 的欧氏距离计算性能来设定基准。为了验证距离计算在 Python 和 Mojo 实现中的数值准确性,我们将创建两个随机的 NumPy 数组,每个数组有 1000 万个元素,并在整个示例中重复使用。对于纯 Python 实现,我们将把这些 NumPy 数组转换为 Python 列表,因此我们只使用 Python 原生数据结构。
Mojo Playground 提示:在 Jupyter 的顶部添加 %%python,以指示 Mojo Jupyter 内核以 Python 解释型代码而非 Mojo 编译型代码运行此代码。
首先,让我们用下面的代码创建 2 个包含 10,000,000 个元素的随机向量。
%%python
import time
import numpy as np
from math import sqrt
from timeit import timeit
n = 10000000
anp = np.random.rand(n)
bnp = np.random.rand(n)
alist = anp.tolist()
blist = bnp.tolist()
def print_formatter(string, value):
print(f"{string}: {value:5.5f}")
# 纯 Python 迭代实现 计算欧氏距离了
def python_naive_dist(a,b):
s = 0.0
n = len(a)
for i in range(n):
dist = a[i] - b[i]
s += dist*dist
return sqrt(s)
secs = timeit(lambda: python_naive_dist(alist,blist), number=5)/5
print_formatter("python_naive_dist value:", python_naive_dist(alist,blist))
print_formatter("python_naive_dist time (ms):", 1000*secs)复制运行
输出:
python_naive_dist value:: 1300.99809
python_naive_dist time (ms):: 791.53060复制
Python 实现的运行时间约为 ~790 毫秒。请注意欧氏距离值 1290.91809,我们将用它来验证后续实现在数值上的准确性。
Python & NumPy 的实现
Python 程序员很少将 Python 原生数据结构用于机器学习和科学计算。此类用例的事实标准是 NumPy 软件包,它提供了 n 维数组数据结构和对其进行操作的优化函数。由于我们在上一步中已经创建了一个随机 NumPy 向量,因此我们将使用相同的 NumPy 数组,并使用 NumPy 的向量化函数 numpy.linalg.norm 来计算欧氏距离,该函数用于计算差分向量上的规范。
下面我们将测量 NumPy 实现的执行时间。
%%python
# Numpy 的向量化 linalg.standard 实现
def python_numpy_dist(a,b):
return np.linalg.norm(a-b)
secs = timeit(lambda: python_numpy_dist(anp,bnp), number=5)/5
print_formatter("python_numpy_dist value:", python_numpy_dist(anp,bnp))
print_formatter("python_numpy_dist time (ms):", 1000*secs)复制运行
输出:
python_numpy_dist value: 1300.99809
python_numpy_dist time (ms): 25.39805复制
计算与 1290.91809 完全相同的欧氏距离所需的时间从 ~790 ms 缩短到 ~24 ms:使用 NumPy 更快的 C/C++ 引擎实现,速度提高了约 30 倍。
Mojo ? 实现
Mojo 提供了 Python 的易用性,以及像 C 语言一样的可选底层控制。让我们从在 Mojo 中实现类似 Python 的功能开始,看看我们能获得怎样的性能。
首先,我们需要一个向量数据结构。Mojo 提供的 Tensor 数据结构允许我们使用 n 维数组,在本例中,我们将创建两个 1 维 Tensors,并将 NumPy 数组数据复制到 Tensors 中。
from SIMD import SIMD
from Math import sqrt
from Time import now
from Tensor import Tensor
from DType import DType
from Range import range
let n: Int = 10_000_000
var a = Tensor[DType.float64](n)
var b = Tensor[DType.float64](n)
for i in range(n):
a[i] = anp[i].to_float64()
b[i] = bnp[i].to_float64()复制运行
让我们来剖析一下这段 Mojo 代码。首先,你会注意到我们有了新的变量声明 let 和 var,乍一看可能会觉得奇怪,因为这不是我们熟悉的 Python 语法。Mojo 提供了可选的变量声明(某些情况除外,稍后详述),可以用 let 将变量声明为不可变(即创建后不可修改),也可以用 var 将变量声明为可变(即可以修改)。使用变量声明有两个好处:类型安全和性能。其次,你还会注意到 Tensor 函数的方括号 [] 和圆括号 ()
都是这种格式:Function[parameters](arguments)
在 Mojo 中,"parameters" 代表编译时的值。在本例中,我们要告诉编译器,Tensor 是一个 64-bit 浮点数值的容器。而 Mojo 中的参数代表运行时值,在本例中,我们将 n=10000000 传递给 Tensor 的构造函数,以实例化一个包含 1000 万个值的一维数组。 最后,在 for 循环中,我们将 NumPy 数组的值分配给 Mojo Tensor 。现在,我们可以在 Mojo 中计算欧氏距离了。
Mojo ? 中计算欧氏距离
让我们将 Python 示例移植到 Mojo 中,并对其进行一些修改。
下面是计算欧氏距离的 Mojo 函数。我们可以能发现与 Python 函数的几个主要区别吗?
def mojo_naive_dist(a: Tensor[DType.float64], b: Tensor[DType.float64]) -> Float64:
var s: Float64 = 0.0
n = a.num_elements()
for i in range(n):
dist = a[i] - b[i]
s += dist*dist
return sqrt(s)复制运行
请注意,这与我们的 Python 代码非常相似,只是我们在函数参数中添加了类型:a: TensorDType.float64, b: TensorDType.float64 和返回类型 Float64: TensorDType.float64, b: TensorDType.float64。
与 Python 不同,Mojo 是一种编译语言,尽管可以像在 Python 中一样使用灵活的类型,但 Mojo 允许声明类型,这样编译器就可以根据这些类型优化代码并提高性能。 在这里,Tensor 的 DType.float64 参数指定它包含 64 位浮点数值。Float64 返回类型代表 Mojo SIMD 类型,是机器寄存器上的低级标量值。我们还用 var 关键字声明了变量 s,告诉 Mojo 编译器 s 是 Float64 类型的可变变量。现在,我们可以对 Mojo 代码进行基准测试了。
请注意,这与我们的 Python 代码非常相似,只是我们在函数参数中添加了类型:a. TensorDType.float64, b: TensorDType.float64 和返回类型 Float64: TensorDType.float64, b: TensorDType.float64 和返回类型 Float64。与 Python 不同,Mojo 是一种编译语言,尽管仍然可以像在 Python 中一样使用灵活的类型,但 Mojo 允许声明类型,这样编译器就可以根据这些类型优化代码并提高性能。
在这里,Tensor 的 DType.float64 参数指定它包含 64 位浮点数值。Float64 返回类型代表 Mojo SIMD 类型,是机器寄存器上的低级标量值。我们还用 var 关键字声明了变量 s,告诉 Mojo 编译器 s 是 Float64 类型的可变变量。现在,我们可以对 Mojo 代码进行基准测试了。
let eval_begin = now()
let naive_dist = mojo_naive_dist(a, b)
let eval_end = now()
print_formatter("mojo_naive_dist value", naive_dist)
print_formatter("mojo_naive_dist time (ms)",Float64((eval_end - eval_begin)) / 1e6)复制运行
输出:
mojo_naive_dist value: 1412.54389
mojo_naive_dist time (ms): 69.77153复制
?执行时间从 Python 的 ~790 毫秒下降到 ~70 毫秒,大约快了 11 倍。不过,这仍然比 Python+NumPy 的 ~40 毫秒慢,但无需用 C/C++ 重写函数就已经很不错了。但我们还没完!我们还需要对代码做一些小改动,以提高性能。让我们看看如何做到。
加速的 Mojo? 代码
就像 Python 中、一样,Mojo 中的 def 函数是动态的、灵活的,并且类型是可选的,这使得将 Python 函数移植到 Mojo 变得更加容易。然而,在处理参数的方式上有一些关键的不同。在 Python 中,函数的参数是对对象的引用,如果被修改,其变化在函数之外是可见的。而在 Mojo 中,def 函数会复制所有参数,这在处理像我们这样的大型 Tensor 时会产生开销。因此,为了进一步加快代码速度,我们需要:
- 通过引用传递Tensor 值,因此不会产生副本
- 引入严格类型并声明所有变量
以下是我们更新后的函数,同时解决了 1 和 2 两个问题
fn mojo_fn_dist(a: Tensor[DType.float64], b: Tensor[DType.float64]) -> Float64:
var s: Float64 = 0.0
let n = a.num_elements()
for i in range(n):
let dist = a[i] - b[i]
s += dist*dist
return sqrt(s)复制运行
注意到的第一个变化是 def 被替换为 fn。在 Mojo 中,fn 函数强制执行严格的类型检查和变量声明。fn 的默认行为是,参数和返回值必须包含类型,并且 fn 的参数是不可变的变量。虽然 def 允许编写更加动态的代码,但 fn 函数可以通过降低在运行时确定数据类型的开销来提高性能,并帮助避免各种潜在的运行时错误。可以在 Mojo 编程手册中阅读更多关于 fn 和 def 之间区别的信息。
由于 fn 函数中的所有变量都必须声明,因此我们也用 let 声明 n 和 dist,然后就可以对更新后的代码进行基准测试了。
let eval_begin = now()
let naive_dist = mojo_fn_dist(a, b)
let eval_end = now()
print_formatter("mojo_fn_dist value", naive_dist)
print_formatter("mojo_fn_dist time (ms)",Float64((eval_end - eval_begin)) / 1e6)复制运行
输出:
mojo_naive_dist value: 1405.6852
mojo_naive_dist time (ms): 12.99901复制
Mojo 代码执行时间降至约 13 毫秒。这比用 C/C++ 实现的 NumPy 快了近 2 倍,比 Python 实现快了 60 倍。
让我们并排看一下 Python 和 Mojo 代码,这样就可以了解只需更改代码即可看到性能改进。

用于计算欧几里得距离的 Python 函数
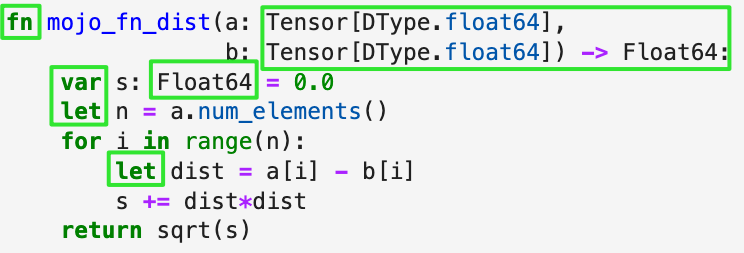
用于计算欧几里得距离的 Mojo 函数。Python 实现的更改以绿色框突出显示。
结论
关于 Mojo,还有很多东西要讨论。还可以尝试更多方法来加快代码速度,包括分配内存的更好方法、矢量化、多核并行化等。完整的 Jupyter 笔记本可在 Mojo Playground 上找到,可以前往 Playground 并亲自运行示例!
参考链接
https://www.modular.com/max/mojo
https://docs.modular.com/mojo/manual
https://www.modular.com/blog/an-easy-introduction-to-mojo-for-python-programmers
本文系外文翻译,前往查看
如有侵权,请联系?cloudcommunity@tencent.com?删除。
本文系外文翻译,前往查看
如有侵权,请联系?cloudcommunity@tencent.com 删除。