每日学术速递4.15(全新改版)

标题:使用时空深度神经网络的季节性火灾预测
作者: Dimitrios Michail, Lefki-Ioanna Panagiotou, Charalampos Davalas, Ioannis Prapas, Spyros Kondylatos, Nikolaos Ioannis Bountos, Ioannis Papoutsis
文章链接:https://arxiv.org/abs/2404.06437
项目代码:https://rl-at-scale.github.io/
摘要:
由于气候变化预计将加剧火灾天气状况,因此准确预测全球范围内的野火对于减灾变得越来越重要。在这项研究中,我们利用 SeasFire,一个包含气候、植被、海洋指数和人类相关变量的综合性全球野火数据集,通过机器学习实现季节性野火预测。对于预测分析,我们训练具有不同架构的深度学习模型,以捕获导致野火的时空环境。我们的调查重点是评估这些模型在预测全球不同预测时间范围内(长达六个月)存在烧毁区域方面的有效性,以及不同的空间或/和时间背景如何影响模型的性能。我们的研究结果证明了深度学习模型在季节性火灾预测中的巨大潜力;更长的输入时间序列可以在不同的预测范围内进行更稳健的预测,同时集成空间信息以捕获野火时空动态可提高性能。最后,我们的研究结果表明,为了提高更长的预测范围的性能,需要考虑更大的空间感受野。
这篇论文试图解决什么问题?
这篇论文试图解决的问题是如何利用深度学习模型来提高全球范围内野火季节性预测的准确性。随着气候变化预期会加剧火险天气条件,对野火的准确预测变得越来越关键,这对于全球范围内的灾害缓解至关重要。研究的目标是通过应用和测试不同的深度学习架构(例如门控循环单元(GRU)、卷积长短期记忆网络(Conv-LSTM)以及时间启用的图神经网络(TGNN))到环境数据中,来提高野火预测的能力。研究的重点在于评估这些模型在不同预测时间范围内(最长可达六个月)预测全球烧毁区域存在性的有效性,以及不同的空间或/和时间上下文如何影响模型性能。
论文如何解决这个问题?
论文通过以下步骤解决季节性野火预测的问题:
- 数据集准备:使用名为SeasFire的全球野火数据集,该数据集包含气候、植被、海洋指数和与人类相关的变量,覆盖21年(2001-2021)的数据,具有8天的时间分辨率和1度的空间分辨率。
- 问题构建:将野火预测问题构建为二元分类任务,即在特定的时间和地点预测是否会发生野火。
- 模型训练:训练具有不同架构的深度学习模型来捕捉导致野火的时空上下文,包括:
- 门控循环单元(GRU):使用简单的GRU层来捕捉时间依赖性。
- 卷积长短期记忆网络(Conv-LSTM):结合时间和空间依赖性,使用3D张量和卷积操作来处理空间维度。
- 时间图卷积网络(T-GCN):结合图卷积网络(GCN)和门控循环单元(GRU)来同时捕捉空间结构和时间动态。
- 实验设计:进行一系列实验来评估不同模型在不同预测时间范围(从1天到24天)内预测烧毁区域的能力,并研究不同的空间和时间上下文对模型性能的影响。
- 模型评估:使用精确度-召回率曲线下的面积(AUPRC)作为性能评估指标,以应对数据集的不平衡性。
- 结果分析:分析模型的性能,发现较长的输入时间序列和整合空间信息可以提高预测的稳健性。此外,研究还发现,为了提高更长预测范围的性能,需要考虑更大的空间接收场。
- 讨论与结论:论文讨论了长时间序列数据的重要性,并指出在超过12个8天周期的预测范围内,模型性能趋于平均。这表明可能需要考虑长距离遥相关和额外的全球信息以进一步提高预测能力。论文还指出,与Conv-LSTM相比,GNNs在连接远程节点和考虑全局信息方面展现出显著的灵活性,这在需要全球上下文的场景中尤其重要。
论文的主要内容:
这篇论文的主要内容可以总结如下:
- 背景与动机:随着气候变化加剧,全球范围内对野火的准确预测变得越来越重要。论文旨在通过机器学习方法提高季节性野火预测的准确性。
- 数据集:使用SeasFire数据集,这是一个包含气候、植被、海洋指数和人类活动变量的全球野火数据集,时间跨度为2001-2021年。
- 方法论:
- 将野火预测问题构建为二元分类任务。
- 应用不同的深度学习架构,包括GRU、Conv-LSTM和T-GCN,来捕捉野火的时空上下文。
- 训练模型预测未来不同时间范围内的烧毁区域存在性。
- 实验:
- 对比了不同模型在全球尺度上的预测性能。
- 研究了时间序列长度和空间上下文对模型性能的影响。
- 分析了不同空间半径对Conv-LSTM和T-GCN模型性能的影响。
- 结果:
- 发现较长的输入时间序列和整合空间信息可以提高预测的稳健性。
- 在长期预测中,模型性能趋于平均,表明可能需要考虑更大的空间接收场和全球信息。
- 结论:
- 深度学习模型在季节性野火预测中具有潜力。
- 需要进一步研究以提高长期预测的性能,包括探索更大的空间范围和GNNs的应用。
- 未来工作:
- 建议进一步探索GNNs的潜力,以及如何整合长距离遥相关性和全球信息。
- 提出了模型集成、特征工程、模型解释性、实时数据集成等未来研究方向。
2.Audio-Visual Generalized Zero-Shot Learning using Pre-Trained Large Multi-Modal Models

标题:A使用预训练大型多模态模型的视听广义零样本学习
作者:David Kurzend?rfer, Otniel-Bogdan Mercea, A. Sophia Koepke, Zeynep Akata
文章链接:https://arxiv.org/abs/2404.06309
项目代码:https://github.com/dkurzend/ClipClap-GZSL
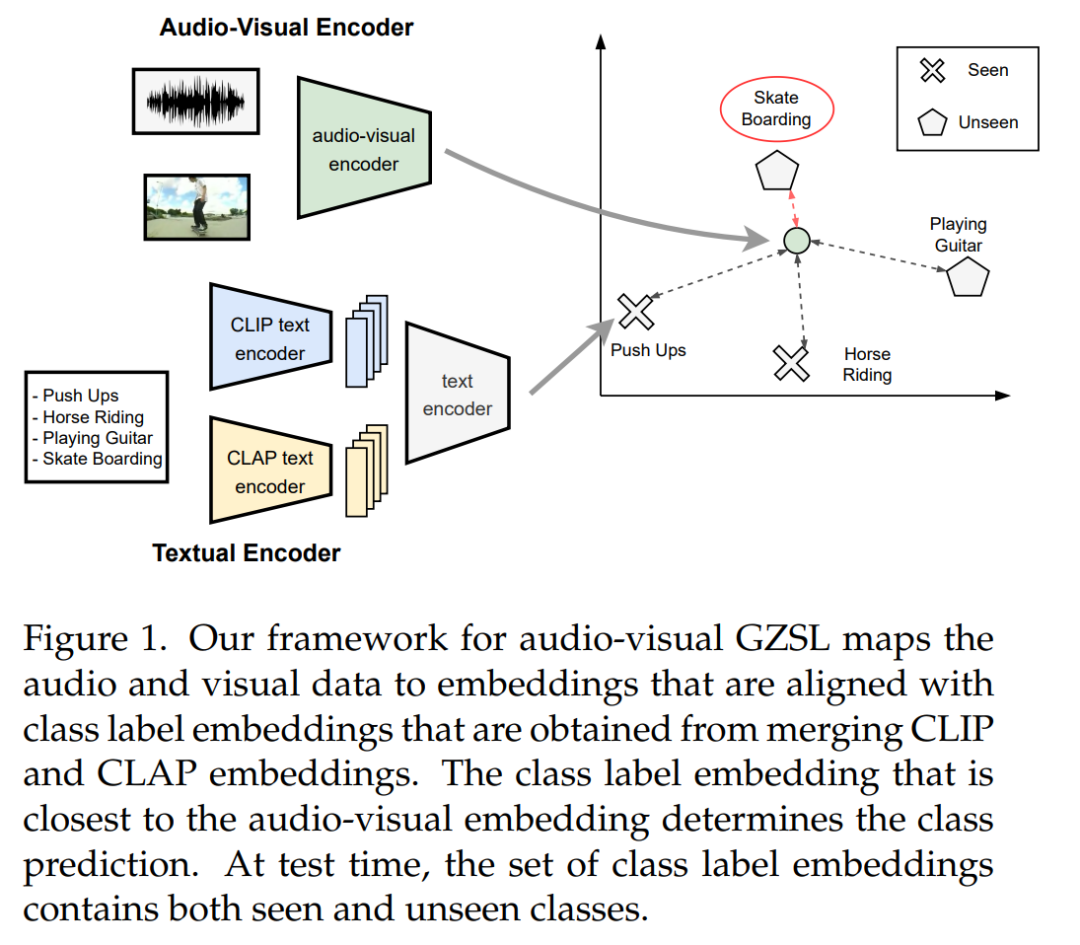

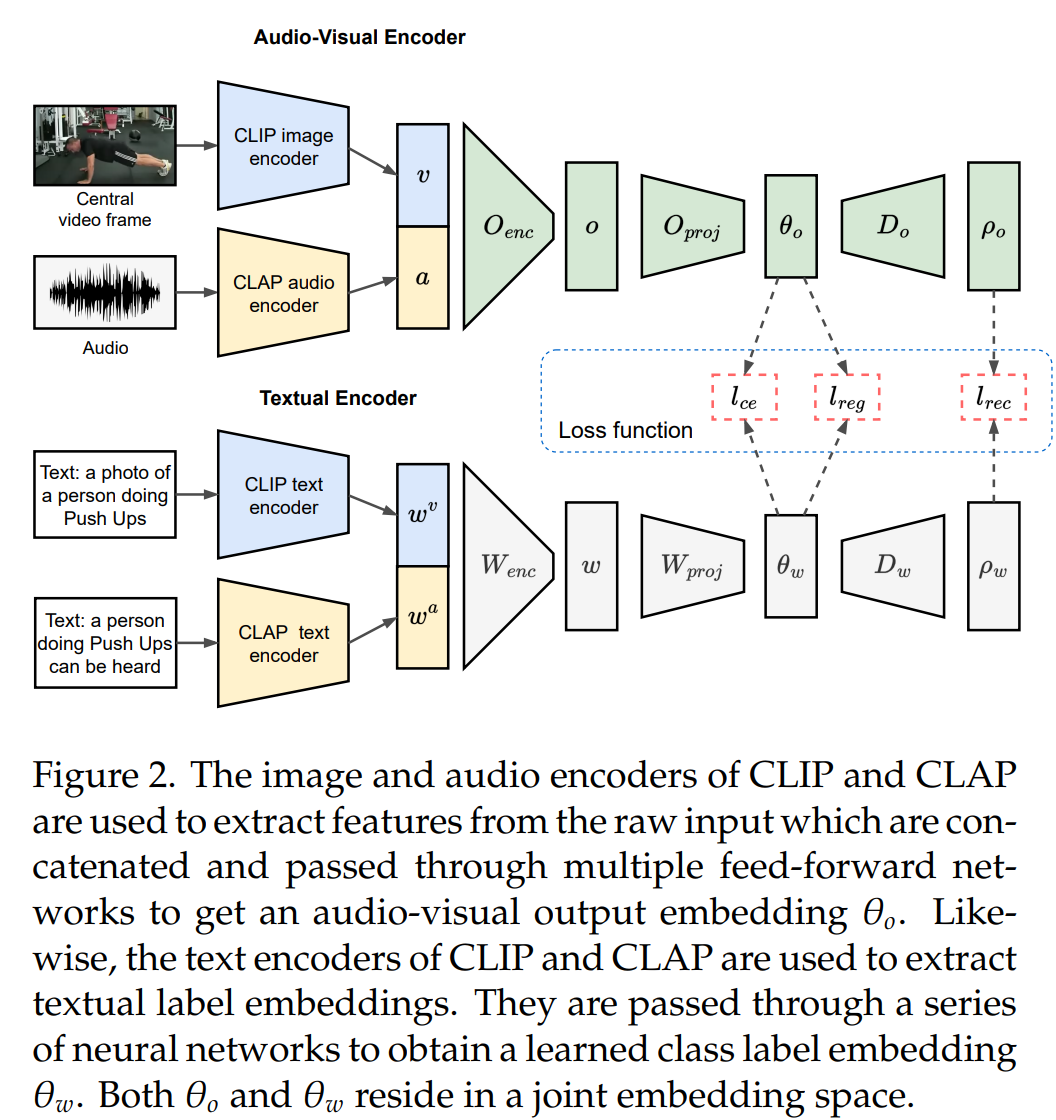
摘要:
视听零样本学习方法通常建立在从预训练模型(例如视频或音频分类模型)中提取的特征之上。然而,现有的基准早于大型多模态模型(如CLIP和CLAP)的普及。在这项工作中,我们探索了如此大型的预训练模型来获得特征,即用于视觉特征的 CLIP 和用于音频特征的 CLAP。此外,CLIP 和 CLAP 文本编码器提供类标签嵌入,这些嵌入组合可提高系统的性能。我们提出了一个简单而有效的模型,该模型仅依赖于前馈神经网络,利用了新的音频、视觉和文本特征的强大泛化能力。我们的框架通过我们的新功能在 VGGSound-GZSL、UCF-GZSL 和 ActivityNet-GZSL 上实现了最先进的性能。
这篇论文试图解决什么问题?
这篇论文试图解决的问题是音频-视觉广义零样本学习(Audio-Visual Generalized Zero-Shot Learning, GZSL)的挑战。在实际深度学习应用中,模型经常会遇到新的、未见过的音频和视觉数据,例如在训练数据中未出现的对象或场景。这种挑战源于现实世界数据的多样性以及为每种可能的变化准备模型的不切实际性。一个设计良好的深度学习模型应该展现出从熟悉的类别向未见类别转移知识的能力。音频-视觉GZSL旨在使用音频和视觉输入对视频进行分类。然而,现有的音频-视觉GZSL方法在特征提取方面已经过时,没有反映出当前大型多模态模型(如CLIP和CLAP)的最新进展。因此,论文提出了一种新的框架,利用这些大型预训练模型的高泛化能力来提高GZSL的性能。
论文如何解决这个问题?
论文通过以下步骤解决了音频-视觉广义零样本学习的问题:
- 利用预训练的多模态模型:论文提出使用大型预训练模型(CLIP和CLAP)来提取音频和视觉特征。CLIP用于提取视觉特征,而CLAP用于提取音频特征。这些模型因其强大的泛化能力而闻名,能够为GZSL任务提供有力的特征表示。
- 使用文本编码器提供类标签嵌入:CLIP和CLAP模型都包含文本编码器,可以提供与类别标签对应的嵌入。这些嵌入与音频和视觉输入特征相结合,进一步提高了分类的准确性。
- 提出简单而有效的模型架构:论文提出了一个仅依赖于前馈神经网络的模型,该模型结合了强大的音频、视觉和文本特征。模型的输入是音频特征、视觉特征和类标签嵌入,通过简单的前馈网络和复合损失函数进行训练。
- 损失函数的设计:为了训练提出的框架,论文采用了一个复合损失函数,包括交叉熵损失、重构损失和回归损失。这些损失函数共同工作以优化模型,使其能够在测试时准确地将音频-视觉嵌入与正确的类标签嵌入对齐。
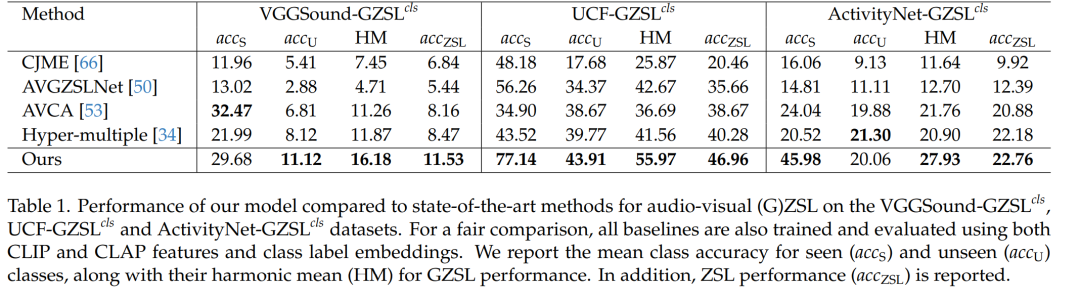
- 实验验证:论文在VGGSound-GZSLcls、UCF-GZSLcls和ActivityNet-GZSLcls数据集上进行了实验,证明了所提出方法的有效性。实验结果显示,该方法在这些数据集上达到了最先进的性能。
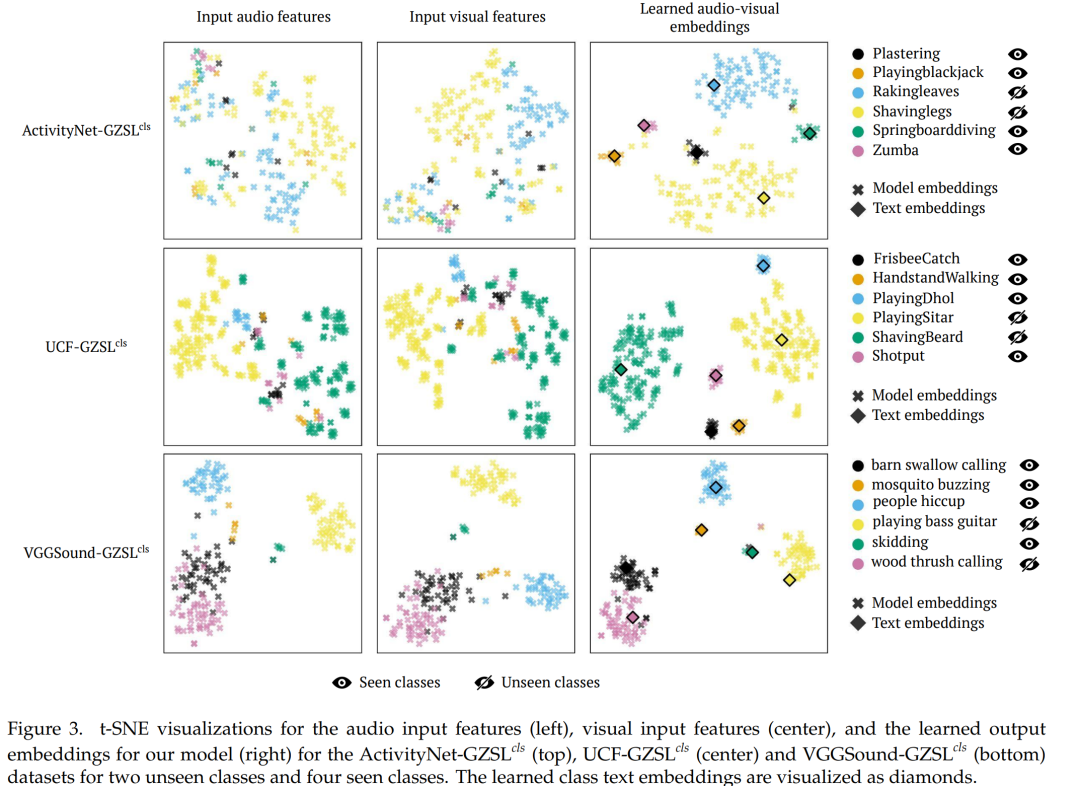
- 定性分析:通过t-SNE可视化,论文展示了模型在嵌入空间中为看到和未见类别学习到的有意义的嵌入,显示出良好的类别分离。
通过这些方法,论文成功地提出了一个有效的音频-视觉GZSL框架,该框架能够利用预训练的多模态模型的强大泛化能力,并在多个标准数据集上取得了显著的性能提升。
论文的主要内容:
这篇论文的主要内容可以总结如下:
- 问题定义:论文针对音频-视觉广义零样本学习(GZSL)问题,旨在提高模型在未见类别上的分类性能,即使在训练时没有见过这些类别的情况下。
- 方法论:
- 利用预训练的大型多模态模型CLIP和CLAP提取音频和视觉特征。
- 使用这些模型的文本编码器来获取类别标签嵌入。
- 提出了一个基于前馈神经网络的简单而有效的模型架构,结合了音频、视觉和文本特征。
- 技术贡献:
- 提出了一个新颖的音频-视觉GZSL框架,该框架利用了CLIP和CLAP模型的高泛化能力。
- 通过结合两个模型的文本编码器,创建了一个统一且强大的文本类标签嵌入。
- 在VGGSound-GZSLcls、UCF-GZSLcls和ActivityNet-GZSLcls数据集上实现了最先进的性能。
- 实验验证:
- 通过定量实验结果展示了所提方法在GZSL任务上的有效性。
- 通过定性分析(t-SNE可视化)展示了模型在嵌入空间中对类别的有效分离。
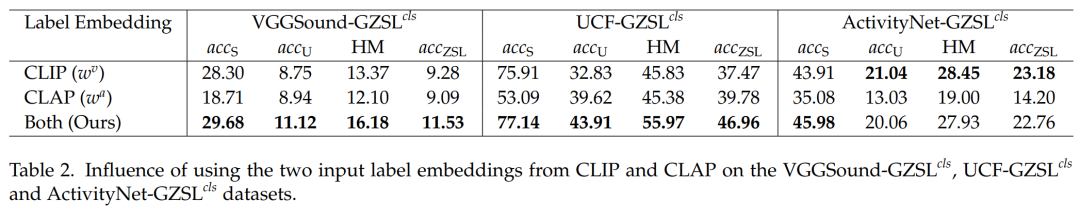
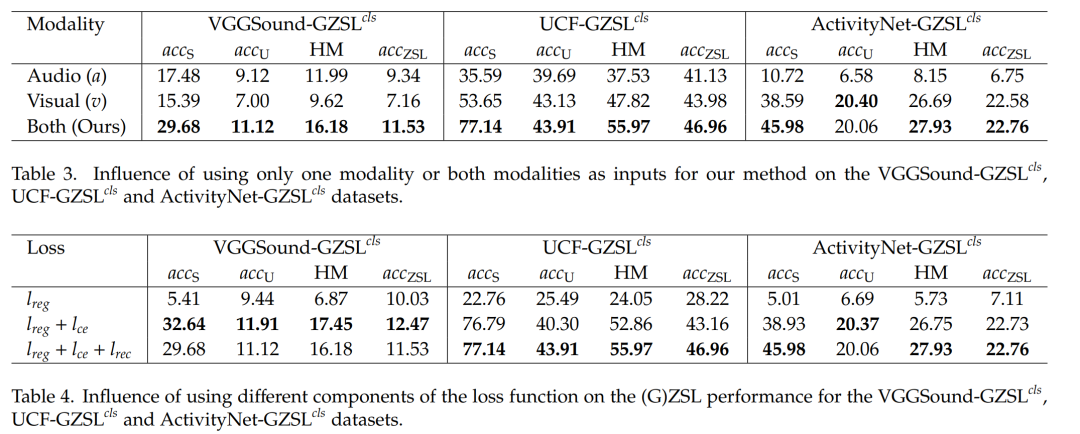
- 消融研究:
- 分析了使用两个不同的文本类标签嵌入、多模态输入以及不同损失函数组件对模型性能的影响。
- 潜在研究方向:
- 提出了进一步探索的潜在方向,包括在更广泛的数据集和场景中验证方法、提高模型的解释性、探索更先进的多模态融合策略等。
论文的核心贡献在于提出了一个利用预训练多模态模型进行音频-视觉GZSL的有效框架,并通过实验验证了其优越性能。此外,论文还探讨了未来可能的研究方向,为该领域的进一步研究提供了思路。
3.Multi-scale Dynamic and Hierarchical Relationship Modeling for Facial Action Units Recognition (CVPR 2024)

标题:面向面部动作单元识别的多尺度动态与分层关系建模
作者:Zihan Wang, Siyang Song, Cheng Luo, Songhe Deng, Weicheng Xie, Linlin Shen
文章链接:https://arxiv.org/abs/2404.06443
项目代码:https://github.com/CVI-SZU/MDHR

摘要:
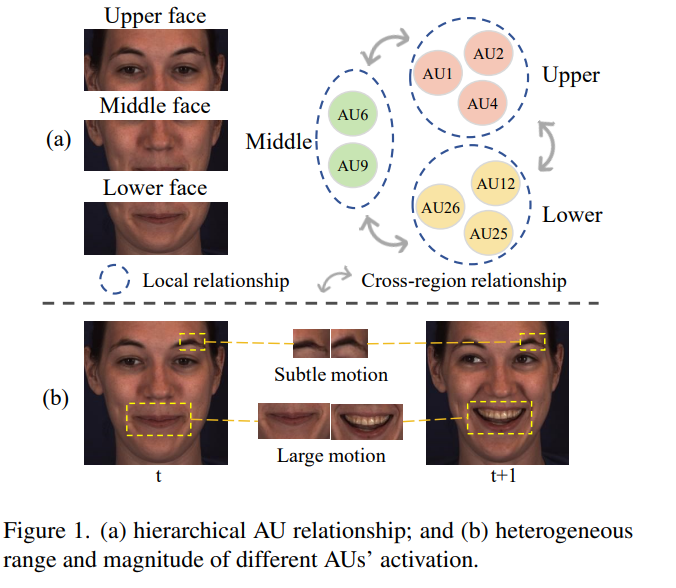
人类面部动作单元 (AU) 以分层方式相互关联,因为它们不仅在空间和时间领域相互关联,而且位于相同/近距离面部区域的 AU 比位于不同面部区域的 AU 表现出更强的关系。虽然现有方法均未对AU之间的这种层次相互依赖性进行彻底建模,但本文建议对AUs之间与AU相关的多尺度动态和分层时空关系进行综合建模,以便识别其发生。具体而言,我们首先提出了一种具有自适应加权块的新型多尺度时间差分网络,以在不同空间尺度上明确捕获跨帧的面部动态,该网络特别考虑了不同AU激活的范围和幅度的异质性。然后,引入两阶段策略,基于AU的空间分布对AU之间的关系进行分层建模(即局部和跨区域AU关系建模)。在BP4D和DISFA上取得的实验结果表明,我们的方法是AU发生识别领域的新技术。
这篇论文试图解决什么问题?
这篇论文提到了多个与面部行为单元(AUs)识别相关的研究领域和具体工作,可以归纳为以下几类:
- 静态面部图像方法:这些方法通常基于单张面部图像来预测AUs的状态。相关研究包括:
- EAC-Net [19]:提出了一个基于补丁的深度区域和多标签学习的方法。
- JAA-Net [35]:同时进行面部对齐和AU识别。
- ARL [36]:使用自适应通道和空间注意力机制。
- SMA-Net [20]:提出了一种自分化的多通道注意力机制。
- 静态AU关系建模:这些方法特别关注建模AUs之间的关系以提高识别性能。例如:
- SRERL [17]:使用语义关系引导的表示学习。
- FAUDT [13]:采用基于Transformer的AU相关性网络。
- FAN-Trans [57]:在线知识蒸馏用于AU检测。
- ME-GraphAU [29]:学习基于图的多维边特征的AU关系。
- 时空方法:这些方法考虑了面部动态信息,以增强AU识别性能。例如:
- STRAL [37]:提出了一种时空图神经网络。
- HSTR-Net [47]:异构时空关系学习网络。
- KS [21]:使用Transformer学习时空AU依赖性和帧间上下文。
- WSRTL [52]:通过联合进行辅助的AU相关任务来增强区域特征和编码面部动态。
- 其他方法:包括使用光流和动态图像等技术来显式捕捉面部运动的方法。
论文如何解决这个问题?
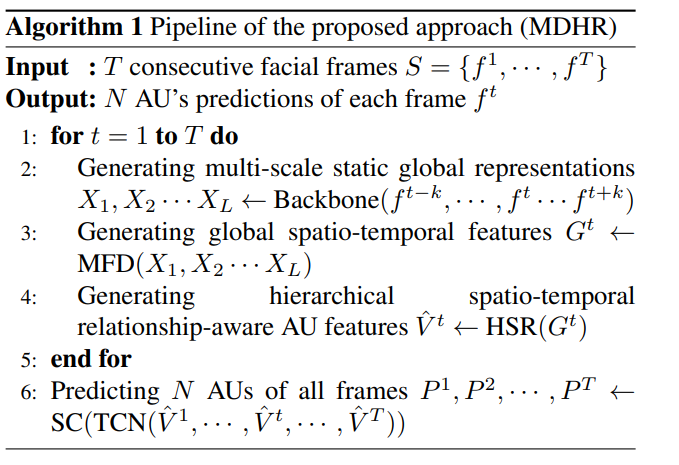
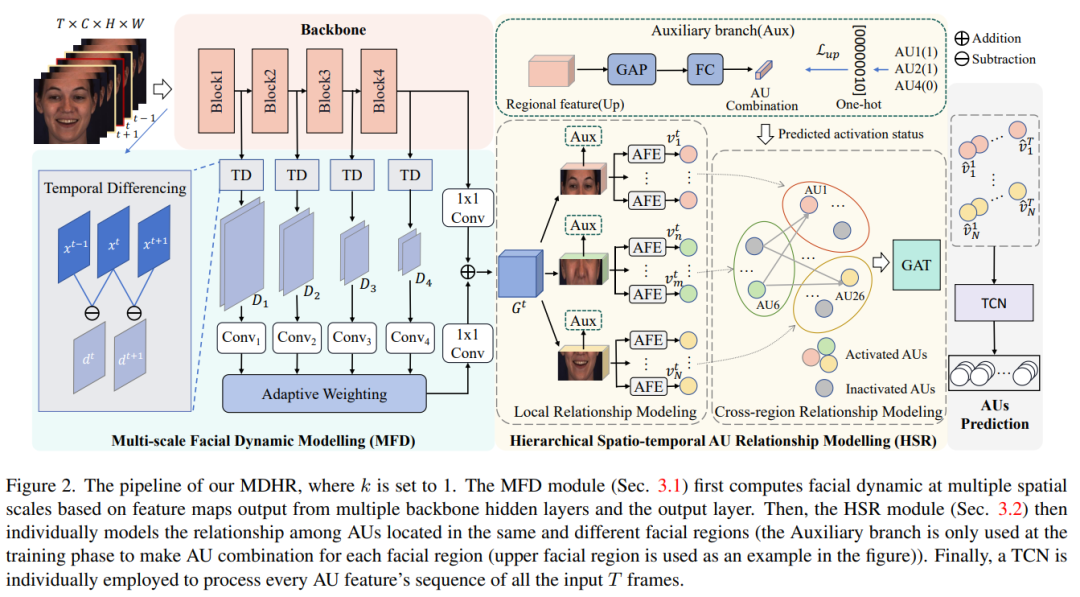
论文提出了一种名为Multi-scale Dynamic and Hierarchical Relationship (MDHR)的新颖方法来解决面部行为单元(AU)识别问题。这个方法主要包括两个关键模块:
- 多尺度面部动态建模 (Multi-scale Facial Dynamic Modelling, MFD):
- 该模块旨在捕捉不同空间尺度上的面部动态,考虑到不同AUs激活时面部运动的范围和幅度的异质性。
- 通过自适应加权块来强调与目标AU相关的多尺度面部动态特征,确保能够高效捕捉到明显和微妙的AU相关面部动态。
- 层级时空AU关系建模 (Hierarchical Spatio-temporal AU Relationship Modelling, HSR):
- 该模块通过两阶段策略层次化地建模AUs之间的关系,考虑它们在面部空间分布的自然层级结构。
- 第一阶段在局部面部区域(local AU relationship modelling)内建模AUs之间的关系,通过特征提取和预测层面的建模来捕捉同一面部区域内AUs的关联性。
- 第二阶段(cross-regional AU relationship modelling)通过图注意力网络(Graph Attention Network, GAT)来显式学习不同面部区域间AUs的关系。
此外,论文还采用了以下策略来增强模型性能:
- 使用时间卷积网络(Temporal Convolution Networks, TCN)和相似性计算策略(similarity calculating strategy)来预测输入视频中每一帧的AU发生情况。
- 应用不对称损失函数来解决AU识别中的类别不平衡问题,即大部分AUs在大多数帧中是不激活的。
通过结合MFD和HSR模块,论文提出的方法能够综合考虑AUs的动态特征和它们之间的层级关系,从而在AU发生识别任务上取得了新的最佳性能。
论文的主要内容:
这篇论文主要内容的总结如下:
- 问题定义:论文旨在解决面部行为单元(AUs)识别问题,特别是如何捕捉AUs在空间和时间上的层级性和相互依赖性。
- 方法提出:提出了一种名为Multi-scale Dynamic and Hierarchical Relationship (MDHR)的新方法,该方法包括两个关键模块:
- 多尺度面部动态建模 (MFD):通过自适应加权捕捉不同空间尺度上的面部动态。
- 层级时空AU关系建模 (HSR):通过两阶段策略层次化地建模AUs之间的关系,包括局部和跨区域关系。
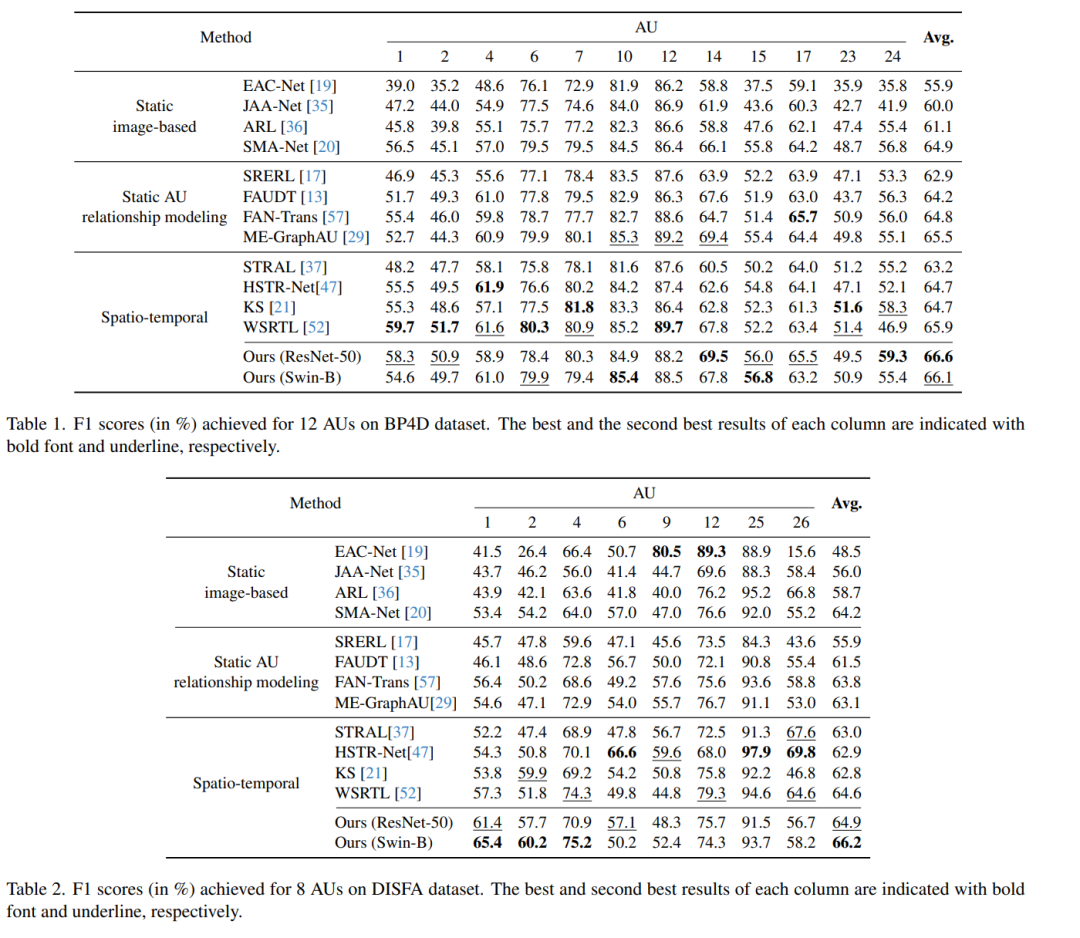
- 实验验证:在BP4D和DISFA两个基准数据集上进行实验,与现有方法相比较,证明了MDHR方法在AU识别上取得了新的最佳性能。
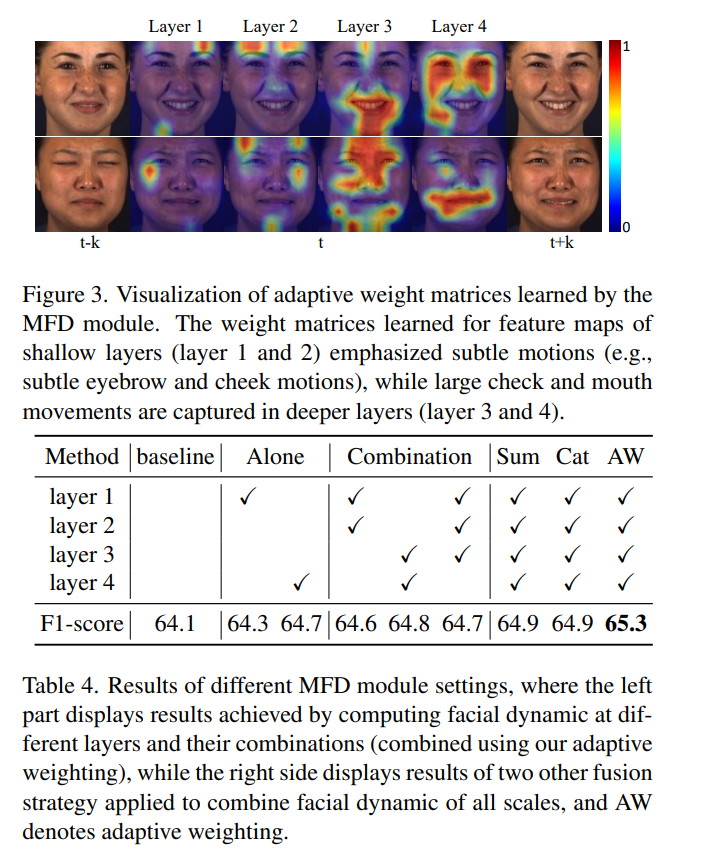
- 消融研究:通过消融实验验证了MFD和HSR模块中各个组成部分的有效性,并展示了它们对提高AU识别性能的贡献。
- 未来方向:论文讨论了可能的改进方向,包括面部区域划分策略的改进、图结构学习的探索、多模态数据融合、实时应用、跨人群和场景的泛化能力、模型解释性和可视化、以及长期学习和持续学习等。
- 贡献总结:论文的主要贡献在于提出了一种能够有效捕捉AU相关动态特征和层级关系的新方法,为面部行为单元识别领域提供了新的视角和技术路径。