每日学术速递4.16(全新改版)


标题: UMBRAE:大脑信号的统一多模态解码
作者:Weihao Xia, Raoul de Charette, Cengiz ?ztireli, Jing-Hao Xue
文章链接:https://arxiv.org/abs/2404.07202
项目代码:https://weihaox.github.io/UMBRAE/






摘要:
我们解决了脑力研究的普遍挑战,偏离了文献几乎无法恢复准确的空间信息并且需要特定主题模型的观察。为了应对这些挑战,我们提出了UMBRAE,一种统一的大脑信号多模态解码。首先,为了从神经信号中提取实例级的概念和空间细节,我们引入了一个高效的通用脑编码器,用于多模态-大脑对齐,并从后续的多模态大型语言模型(MLLM)中恢复多粒度级别的对象描述。其次,我们引入了一种跨学科训练策略,将特定学科的特征映射到一个共同的特征空间。这允许模型在没有额外资源的情况下在多个主题上进行训练,与特定主题的模型相比,甚至可以产生更好的结果。此外,我们证明这支持弱监督适应新受试者,仅占总训练数据的一小部分。实验表明,UMBRAE不仅在新引入的任务中取得了优异的成绩,而且在成熟的任务中也优于方法。为了评估我们的方法,我们构建了一个全面的大脑理解基准 BrainHub 并与社区共享。我们的代码和基准测试可在此 https URL 中找到。
这篇论文试图解决什么问题?
这篇论文试图解决的主要问题是大脑信号解码研究中存在的挑战,特别是在以下几个方面:
- 空间信息的准确性:现有的大脑解码研究往往难以准确捕捉到大脑活动中的空间信息,例如物体的特定外观或空间位置。这对于理解大脑如何编码复杂场景和指导大脑-计算机接口设备(如帮助瘫痪病人交流)至关重要。
- 个体差异:大脑活动模式在不同个体间存在显著差异,这导致现有方法通常需要为每个个体训练特定的模型,这不仅耗时耗力,而且难以泛化到新的个体。
为了应对这些挑战,论文提出了一个统一的多模态大脑信号解码框架(UMBRAE),它包括以下几个关键点:
- 通用大脑编码器:用于从神经信号中提取概念和空间细节,并与多模态大型语言模型(MLLM)对齐,以恢复不同粒度级别的对象描述。
- 跨个体训练策略:通过将个体特定的特征映射到一个共同的特征空间,使得模型能够在多个个体上进行训练,而不需要额外的资源,甚至在某些情况下比个体特定的模型表现更好。
- 弱监督适应:支持对新个体的适应性训练,只需要一小部分训练数据即可。
此外,论文还构建了一个全面的大脑理解基准(BrainHub),用于评估和改进大脑解码方法,并公开了代码和基准数据集,以促进社区的进一步研究。
论文如何解决这个问题?
论文提出了一个名为UMBRAE(Unified Multimodal Decoding of Brain Signals)的框架来解决大脑信号解码的问题。UMBRAE框架的关键组成部分和解决策略如下:
- 通用大脑编码器(Universal Brain Encoder):
- 为了从神经信号中提取概念和空间细节,论文引入了一个高效的通用大脑编码器,用于多模态大脑对齐。这个编码器能够从大脑信号中恢复出多层次的语义信息。
- 跨个体训练策略(Cross-Subject Training Strategy):
- 为了解决个体间大脑活动模式的差异,论文提出了一种跨个体训练策略。这种策略允许模型在多个个体上进行训练,而不需要为每个个体单独训练模型。这通过在批次采样中引入主题概率来实现,确保模型能够从用户多样性中受益。
- 弱监督适应(Weakly-Supervised Adaptation):
- UMBRAE支持弱监督适应,这意味着可以仅使用一小部分训练数据就能为新个体训练模型。这是通过在预训练的模型上进行微调来实现的,显著降低了收集大量新个体数据的需求。
- 多模态对齐(Multimodal Alignment):
- 论文通过将大脑特征与预训练图像编码器的中间特征进行元素级重建来实现大脑信号与图像特征之间的对齐。这样可以保持空间信息,同时提高大脑表示的泛化能力。
- 大脑提示接口(Brain Prompting Interface):
- 在训练和推理过程中,UMBRAE使用大脑提示接口与多模态大型语言模型(MLLM)进行交互。通过标准化的大脑表示和用户指令提示,模型能够执行下游任务,如大脑字幕、检索和视觉解码。
- 构建BrainHub基准:
- 为了评估UMBRAE的性能,论文构建了一个多模态大脑理解基准(BrainHub),它扩展了现有的自然场景数据集(NSD),并提供了用于评估的任务和指标。
通过这些策略,UMBRAE能够在不同个体间泛化,同时保持对大脑信号中编码的复杂语义和空间信息的敏感性。论文的实验结果表明,UMBRAE在多个任务上取得了优越的性能,并且能够适应新的个体,只需极少的训练数据。
论文的主要内容:
这篇论文的主要内容可以总结如下:
- 问题陈述:论文针对大脑信号解码领域中的空间信息丢失和个体差异问题提出了挑战,并介绍了UMBRAE框架来解决这些问题。
- UMBRAE框架:
- 通用大脑编码器:用于从大脑信号中提取概念和空间细节。
- 跨个体训练策略:允许模型在多个个体上进行训练,提高泛化能力。
- 弱监督适应:支持使用少量数据对新个体进行快速适应。
- 实验验证:
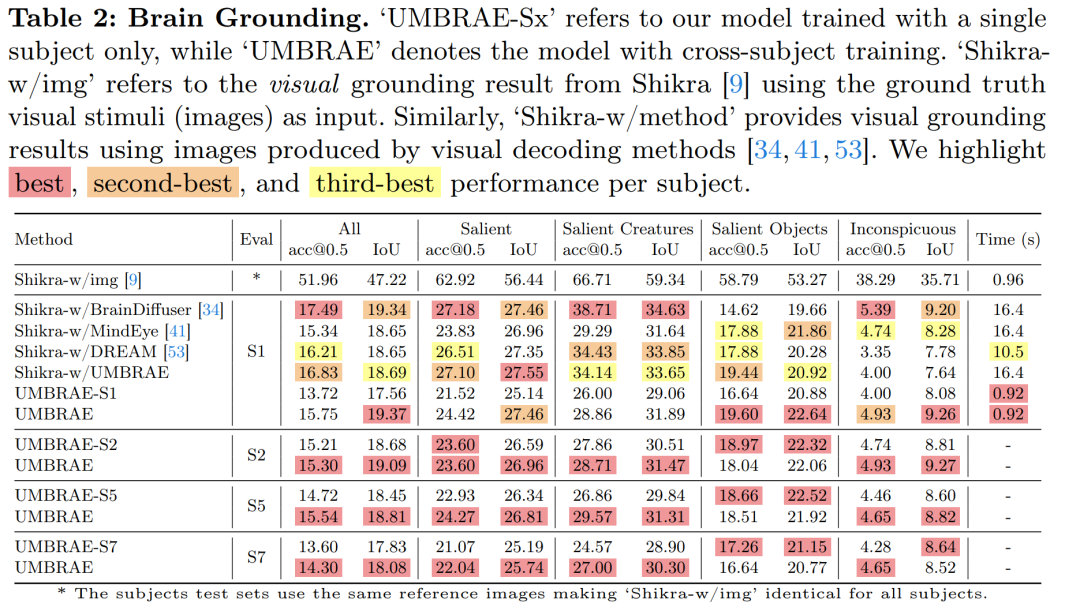
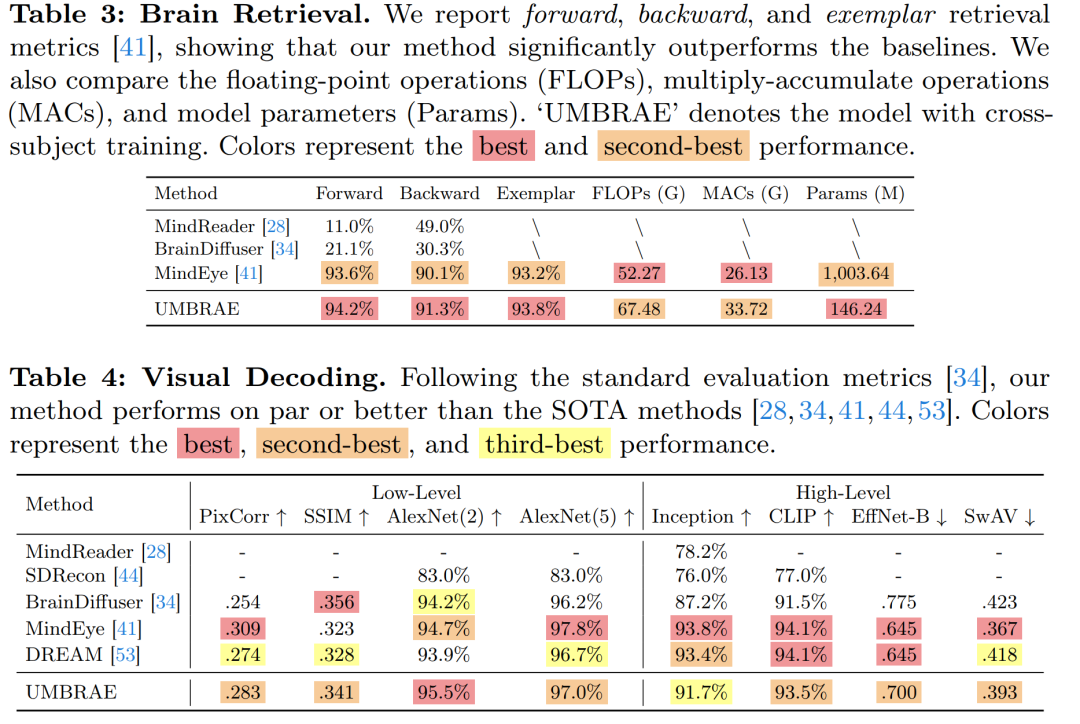
- 进行了大脑字幕、大脑定位、大脑检索和视觉解码等任务的实验。
- 展示了UMBRAE在多个任务上相较于现有方法的性能优势。
- 通过弱监督适应实验,证明了模型对新个体的适应性。
- 基准构建:
- 构建了BrainHub基准,用于评估大脑解码模型的性能。
- 提供了一个多模态大脑理解的测试平台,包含扩展的自然场景数据集(NSD)和COCO数据集的标注。
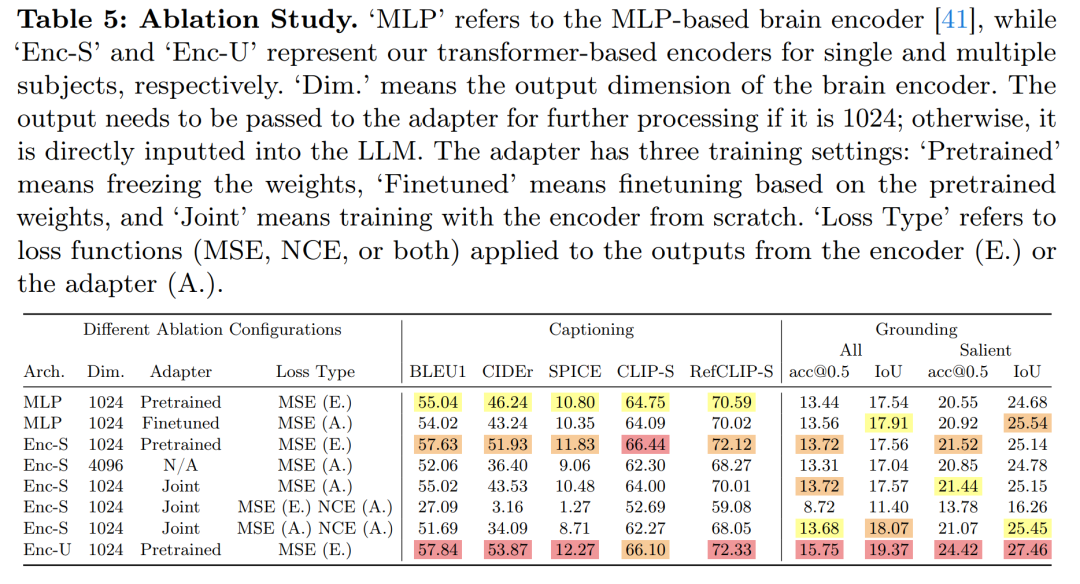
- 消融研究:
- 通过消融研究评估了不同组件对模型性能的影响。
- 分析了不同训练策略和大脑编码器架构的效果。
- 未来方向:
- 论文提出了进一步研究的潜在方向,包括改进大脑编码器、跨模态融合、个体适应性、实时大脑解码、解释性和可视化技术,以及伦理和社会影响的考量。
2.Self-supervised Monocular Depth Estimation on Water Scenes via Specular Reflection Prior

标题:基于镜面反射的自监督单目水景深度估计
作者:Zhengyang Lu, Ying Chen
文章链接:https://arxiv.org/abs/2404.07176




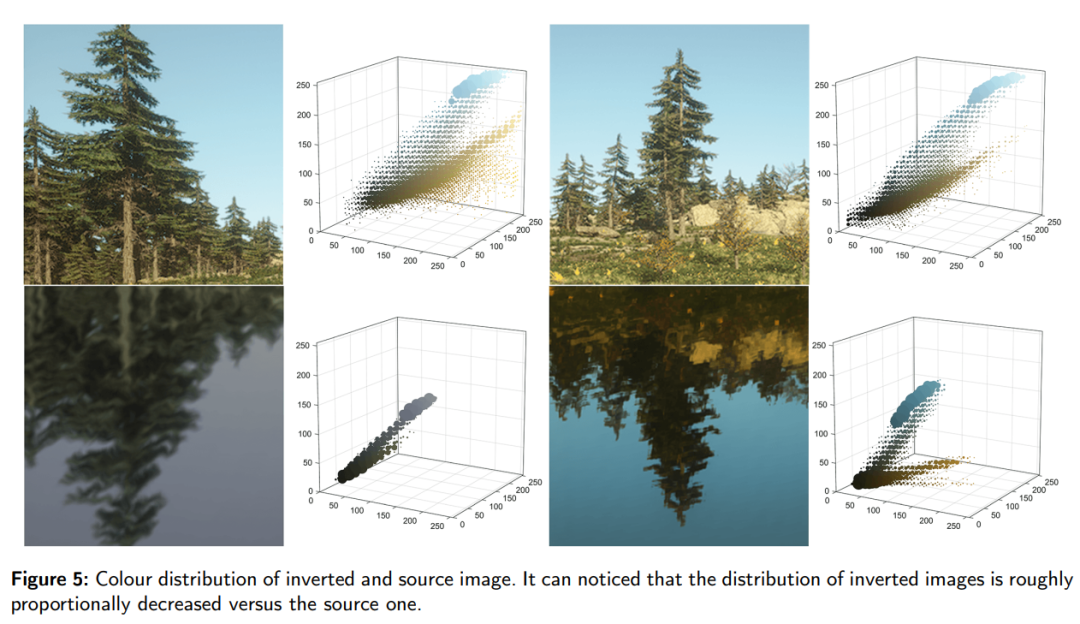
摘要:
对于计算机视觉来说,从单个图像进行单目深度估计是一个不恰当的问题,因为作为先验知识的可靠线索不足。除了帧间监控(即立体声和相邻帧)外,同一帧中还提供大量的先验信息。来自镜面反射的反射,信息丰富的帧内先验,使我们能够将摆错位置的深度估计任务重新表述为多视图合成。本文提出了第一个通过帧内先验对水场景进行深度学习深度估计的自监督方法,称为反射监督和几何约束。在第一阶段,执行水分割网络以将反射分量与整个图像分离。接下来,我们构建了一个自我监督框架,从反射中预测目标外观,感知为其他角度。结合 SmoothL1 和新型光度自适应 SSIM,制定了光度重投影误差,通过对齐转换后的虚拟深度和源深度来优化姿态和深度估计。作为补充,水面是从真实和虚拟摄像机位置确定的,这与水区的深度相辅相成。此外,为了减轻这些费力的地面实况注释,我们引入了一个从虚幻引擎4渲染的大规模水反射场景(WRS)数据集。在WRS数据集上的大量实验证明了所提方法与最先进的深度估计技术相比的可行性。
这篇论文试图解决什么问题?
这篇论文试图解决的问题是单目深度估计在水场景中的不准确性问题,特别是在存在镜面反射的情况下。由于镜面反射提供了丰富的内在帧先验信息,这些信息可以用来重新构建深度信息,从而将单帧图像的深度估计问题重新定义为一个多视角合成问题。具体来说,论文提出了一种基于镜面反射先验的自监督单目深度估计方法,旨在通过利用水场景中的反射信息来提高深度估计的准确性。
论文如何解决这个问题?
论文通过以下步骤解决单目深度估计在水场景中的问题:
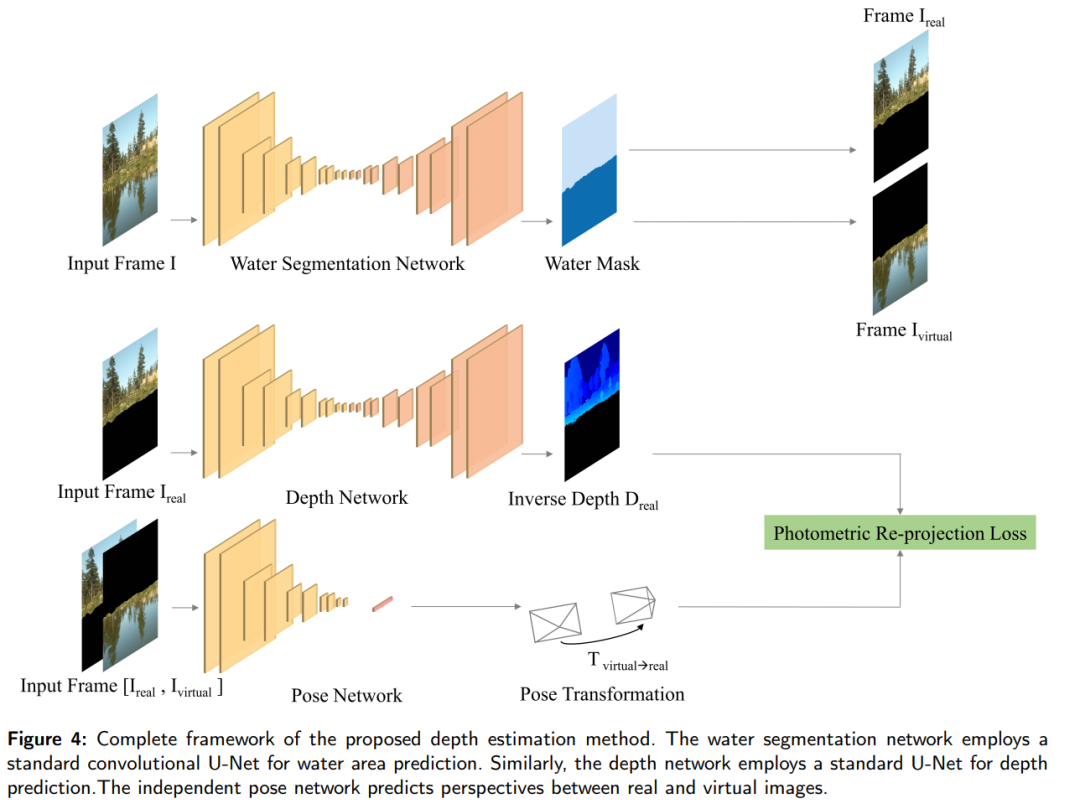
- 水体分割网络:首先,使用一个标准的端到端U-Net网络来分割出水体区域和图像中的其他部分。这一步骤的目的是将反射成分从整张图像中分离出来,为后续的深度估计提供准确的输入。
- 自监督框架:接着,构建了一个自监督框架来预测目标外观,这些目标外观是从反射中感知到的其他视角。这个框架利用了镜面反射的内在先验信息,即反射中的图像可以被视为从另一个视角观察到的场景。
- 光度重投影误差:为了优化姿态和深度估计,论文提出了一个包含SmoothL1和新颖的光度自适应SSIM(PASSIM)的光度重投影误差。这个误差用于通过比较转换后的虚拟深度和源深度来对齐它们。
- 水平面的确定:作为补充,通过真实和虚拟相机位置来确定水面,这补充了水区域的深度信息。
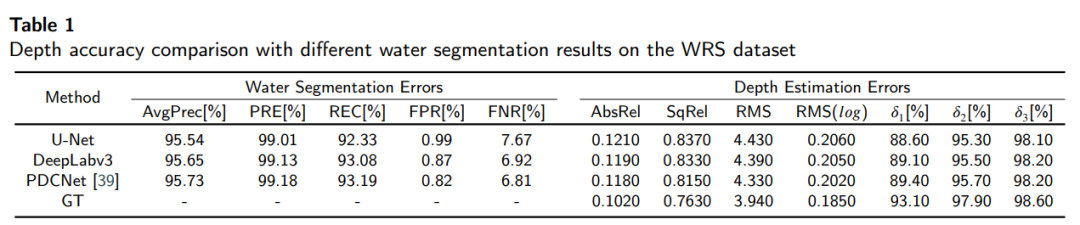
- 大规模水反射场景数据集(WRS):为了缓解对繁琐的真值标注的需求,论文介绍了一个由Unreal Engine 4渲染的大规模水反射场景数据集(WRS)。这个数据集包含了3251个RGB图像和深度对,为深度估计方法提供了一个有价值的资源。
- 实验验证:论文通过在WRS数据集上进行广泛的实验来证明所提出方法的可行性,并与最先进的深度估计技术进行了比较。
通过这些步骤,论文成功地将单帧图像的深度估计问题转换为一个多视角合成问题,并通过自监督学习方法利用了镜面反射中的丰富信息,从而提高了深度估计的准确性。
论文的主要内容:
这篇论文主要内容的总结如下:
- 问题定义:论文针对单目深度估计在水场景中的不准确性问题,特别是存在镜面反射时的挑战,提出了一种新的解决方案。
- 方法提出:论文提出了一种自监督的单目深度估计方法,该方法利用水场景中的镜面反射信息作为内在帧先验,将深度估计问题重新定义为多视角合成问题。
- 技术框架:
- 使用端到端的U-Net网络进行水体分割。
- 构建自监督框架预测目标外观,利用镜面反射中的信息。
- 引入光度重投影误差,结合SmoothL1和新颖的光度自适应SSIM(PASSIM)进行优化。
- 确定水面深度,补充水区域的深度信息。
- 数据集创建:为了支持方法的训练和评估,论文创建了一个大规模的水反射场景数据集(WRS),包含3251个RGB图像和深度对。
- 实验验证:
- 对比不同网络结构的水体分割效果。
- 评估自监督深度估计的性能。
- 与现有深度估计方法进行比较,展示所提方法的优越性。
- 在真实世界场景中验证方法的有效性。
- 未来工作:论文指出了未来研究的可能方向,包括扩展到更多反射场景、构建更多样化的数据集、提高模型鲁棒性、探索新的自监督学习方法等。
3.Driver Attention Tracking and Analysis

标题: 驾驶员注意力跟踪和分析
作者:Dat Viet Thanh Nguyen, Anh Tran, Nam Vu, Cuong Pham, Minh Hoai
文章链接:https://arxiv.org/abs/2404.07122



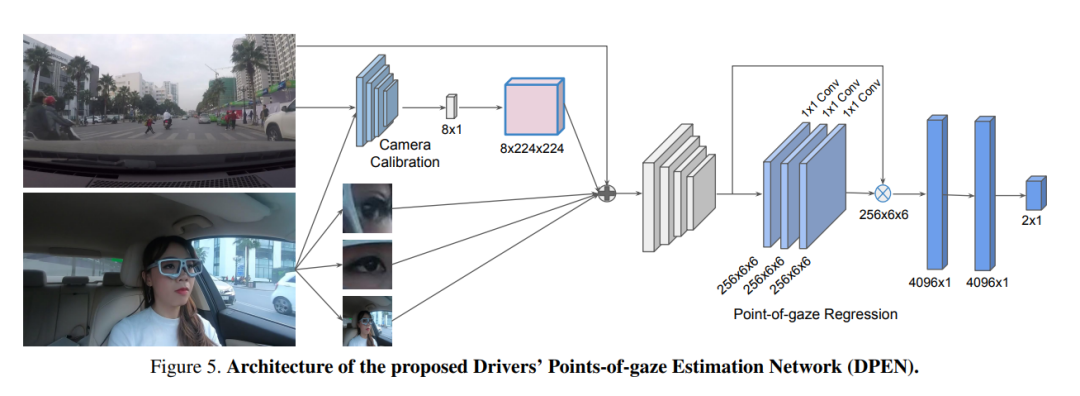


摘要:
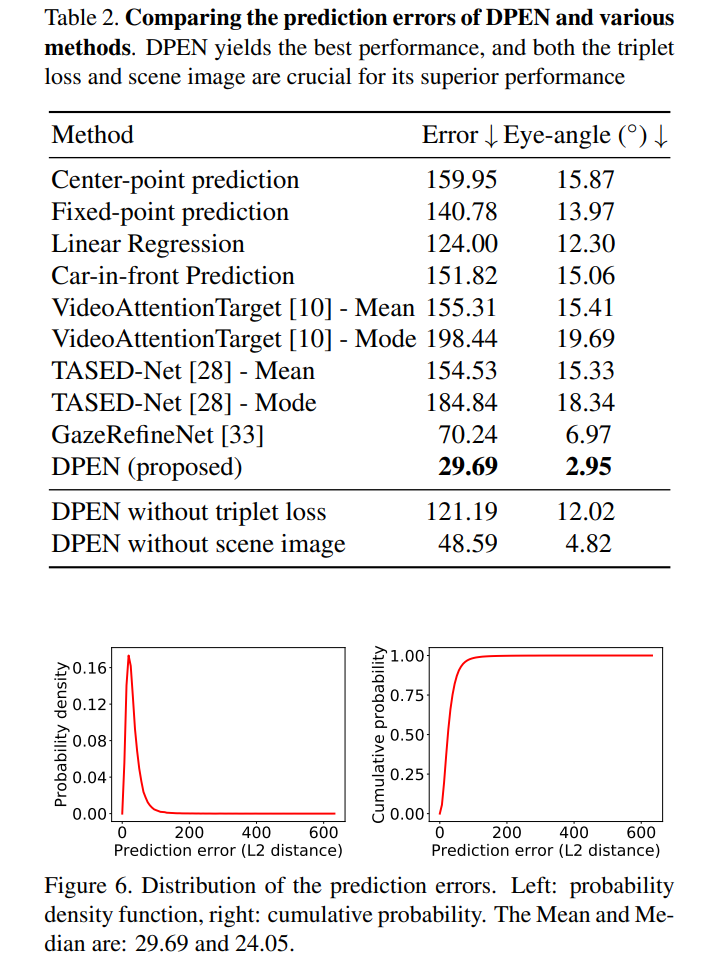
我们提出了一种新的方法,使用安装在汽车挡风玻璃和仪表板上的一对普通摄像头来估计驾驶员的视线点。这是一个具有挑战性的问题,因为交通环境的动态与未知深度的 3D 场景。由于驾驶员和摄像头系统之间的不稳定距离,这个问题变得更加复杂。为了应对这些挑战,我们开发了一种新颖的卷积网络,可以同时分析场景图像和驾驶员面部图像。该网络具有一个摄像头校准模块,该模块可以计算表示驱动器和摄像头系统之间空间配置的嵌入向量。该校准模块提高了整个网络的性能,可以端到端地联合训练。我们还通过引入具有凝视点注释的大规模驾驶数据集来解决缺乏用于训练和评估的注释数据的问题。这是一个城市真实驾驶会话的原位数据集,包含驾驶场景的同步图像以及驾驶员的面部和凝视。在该数据集上的实验表明,所提方法优于各种基线方法,平均预测误差为29.69像素,与场景相机 1280×720 的分辨率相比相对较小。
这篇论文试图解决什么问题?
这篇论文提出了一种新颖的方法来估计驾驶员在驾驶过程中的注视点(points-of-gaze),通过在汽车的挡风玻璃和仪表盘上安装一对普通摄像头来实现。这项任务具有挑战性,因为交通环境的动态性以及未知深度的3D场景,加上驾驶员与摄像头系统之间的距离不断变化,使得问题变得更加复杂。为了解决这些挑战,论文开发了一种新颖的卷积网络,该网络能够同时分析场景图像和驾驶员面部图像。网络包含一个摄像头校准模块,可以计算表示驾驶员与摄像头系统之间空间配置的嵌入向量。这个校准模块提高了整个网络的性能,并且可以端到端地联合训练。此外,论文还通过引入一个大规模的驾驶数据集来解决训练和评估中标注数据不足的问题,该数据集包含了城市真实驾驶场景中的同步图像,以及驾驶员的面部和注视点信息。在该数据集上的实验表明,所提出的方法优于各种基线方法,平均预测误差为29.69像素,与场景摄像头的1280×720分辨率相比较小。
论文如何解决这个问题?
为了解决驾驶员注视点估计的问题,论文提出了以下解决方案:
- 数据集收集:首先,论文收集了一个名为Drivers’ Points-of-Gaze (DPoG) 的大规模驾驶数据集。这个数据集包含了11名驾驶员在城市繁忙街道上驾驶时的注视行为数据,涵盖了19个驾驶会话,反映了大多数城市驾驶员每天的真实驾驶条件。
- 硬件和设置:使用两个GoPro摄像头进行数据采集,一个安装在挡风玻璃上,指向驾驶员的面部,记录面部和头部运动;另一个安装在仪表盘上,指向车辆的前部空间。同时,使用SMI眼动跟踪眼镜来获取驾驶员的注视点,作为训练数据的真值标注。
- 摄像头校准和同步:在每个驾驶会话开始时,使用三点校准程序对眼动跟踪眼镜进行校准。GoPro摄像头则有意保持未校准状态,因为摄像头位置与驾驶员之间的空间关系较为脆弱。为了同步视频,让驾驶员在每个驾驶会话开始前拍手,利用拍手声、可听见的语音和交通噪音来同步GoPro视频。
- 注视点注释:从同步的视频片段中提取了大量同步的(场景,面部,注视)帧三元组,并通过RANSAC-Flow算法将注视点从注视帧转移到场景帧。对匹配结果进行手动验证,确保准确性。
- 网络架构设计:提出了一个名为Drivers’ Points-of-Gaze Estimation Network (DPEN) 的新型卷积网络,该网络包括摄像头校准模块和注视点回归模块。摄像头校准模块使用ResNet-18架构来计算表示驾驶员与摄像头系统空间配置的关系的嵌入向量。注视点回归模块则结合场景图像、面部ROI、眼睛ROI和摄像头校准参数来估计最终的注视点位置。
- 训练过程:DPEN网络可以端到端地进行训练,同时优化注视点回归模块和摄像头校准模块的参数。训练目标是最小化预测注视点和真实注视点之间的差异,采用基于加权欧几里得距离的损失函数,并为摄像头校准模块添加了三元组损失。
通过上述方法,论文成功地开发了一个能够在真实驾驶环境中估计驾驶员注视点的系统,并在DPoG数据集上取得了良好的性能。
论文的主要内容:
这篇论文的主要内容可以总结如下:
- 问题定义:论文旨在解决在真实驾驶环境中准确估计驾驶员注视点的问题,以提高驾驶安全和增强驾驶体验。
- 数据集创建:为了缺乏合适的训练和评估数据,作者收集了一个大规模的驾驶数据集(DPoG),包含了城市真实驾驶场景中的同步图像以及驾驶员的面部和注视点信息。
- 方法提出:提出了一种新型的卷积神经网络(DPEN),该网络包括摄像头校准模块和注视点回归模块,能够同时分析驾驶员的面部图像和道路场景图像来估计注视点。
- 技术贡献:开发了一种自校准的注视点估计方法,通过摄像头校准模块来适应驾驶员与摄像头系统之间空间配置的变化。
- 实验评估:在DPoG数据集上进行了一系列实验,包括与多种基线方法的比较、消融研究以及留一法实验,证明了所提出方法的有效性。
- 结果展示:实验结果显示,DPEN方法在注视点估计上取得了平均29.69像素的预测误差,远优于其他基线方法,并且在AUC指标上也表现优异。
- 未来工作:论文还讨论了未来可能的研究方向,包括方法的泛化、多模态数据融合、实时处理能力、用户个性化、长期稳定性、交互式应用、安全性和隐私等。