《最新出炉》系列初窥篇-Python+Playwright自动化测试-38-如何截图-下篇
原创《最新出炉》系列初窥篇-Python+Playwright自动化测试-38-如何截图-下篇
原创
1.简介
这个系列的文章也讲解和分享了差不多三分之一吧,突然有小伙伴或者童鞋们问道playwright有没有截图的方法。答案当然是:肯定有的。宏哥回过头来看看确实这个非常基础的知识点还没有讲解和分享。那么在这个契机下就把它插队分享和讲解一下。Playwright提供了一个截屏的API:page.screenshot。使用该API,只需要指定截图的图片的保存路径及文件名即可。如果仅指定文件名,默认保存在当前目录。
2.截图语法
截图介绍官方API的文档地址:https://playwright.dev/python/docs/screenshots
2.1截图参数
screenshot方法可以进行截图,参数如下:
timeout:以毫秒为单位的超时时间,0为禁用超时
path:设置截图的路径
type:图片类型,默认jpg
quality:像素,不适用于jpg
omit_background: 隐藏默认白色背景,并允许捕获具有透明度的屏幕截图。不适用于“jpeg”图像。
full_page:如果为true,则获取完整可滚动页面的屏幕截图,而不是当前可见的视口。默认为
`假`。
clip:指定结果图像剪裁的对象clip={'x': 10 , 'y': 10, 'width': 10, 'height': 10}3.按照元素截图(截取页面一部分)
有时候,我们可能只想截取页面的一部分,那么,Playwright也支持将想要截取的部分筛选出来,然后调用截图API进行截图。参数同上,只是调用截图方法的对象不同,快速截图是page,按照元素截图是page下的元素,有时截取单个元素的屏幕截图很有用。语法如下:
page.locator(".header").screenshot(path="screenshot.png")3.1代码设计
使用示例,截图百度页面的form 表单输入框和搜索按钮,如下图所示:

3.2参考代码
# coding=utf-8?
# 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行
# 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2023-11-23
@author: 北京-宏哥
公众号:北京宏哥
Project: 《最新出炉》系列初窥篇-Python+Playwright自动化测试-36-如何截图
'''
# 3.导入模块
from playwright.sync_api import Playwright, sync_playwright, expect
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("https://www.baidu.com/")
element_handle = page.query_selector("#form") # 按照元素截图
element_handle.screenshot(path="screenshot.png")
print(page.title())
page.wait_for_timeout(1000)
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)3.3运行代码
1.运行代码,右键Run'Test',控制台输出,如下图所示:
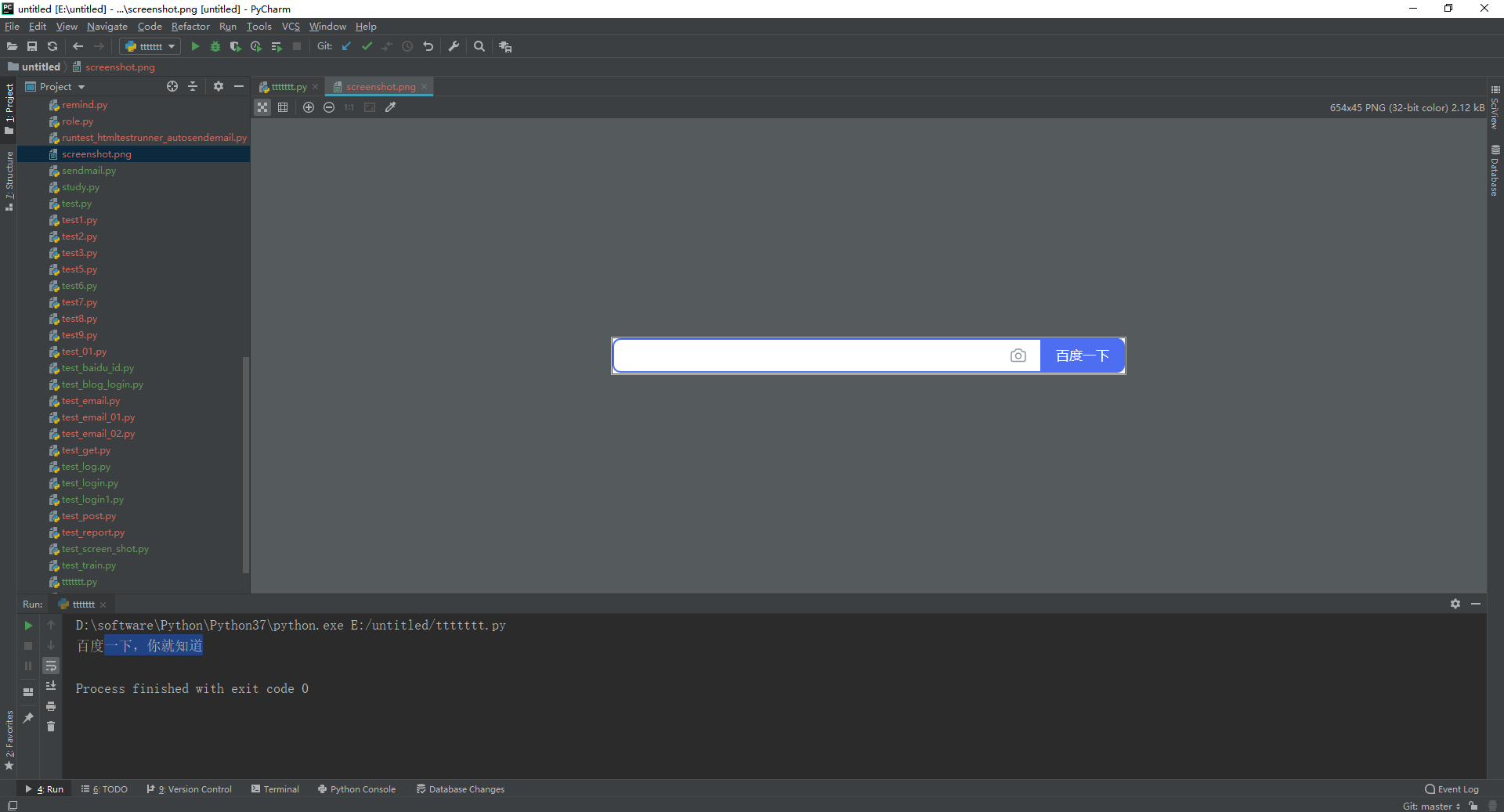
2.运行代码后电脑端的浏览器的动作。如下图所示:
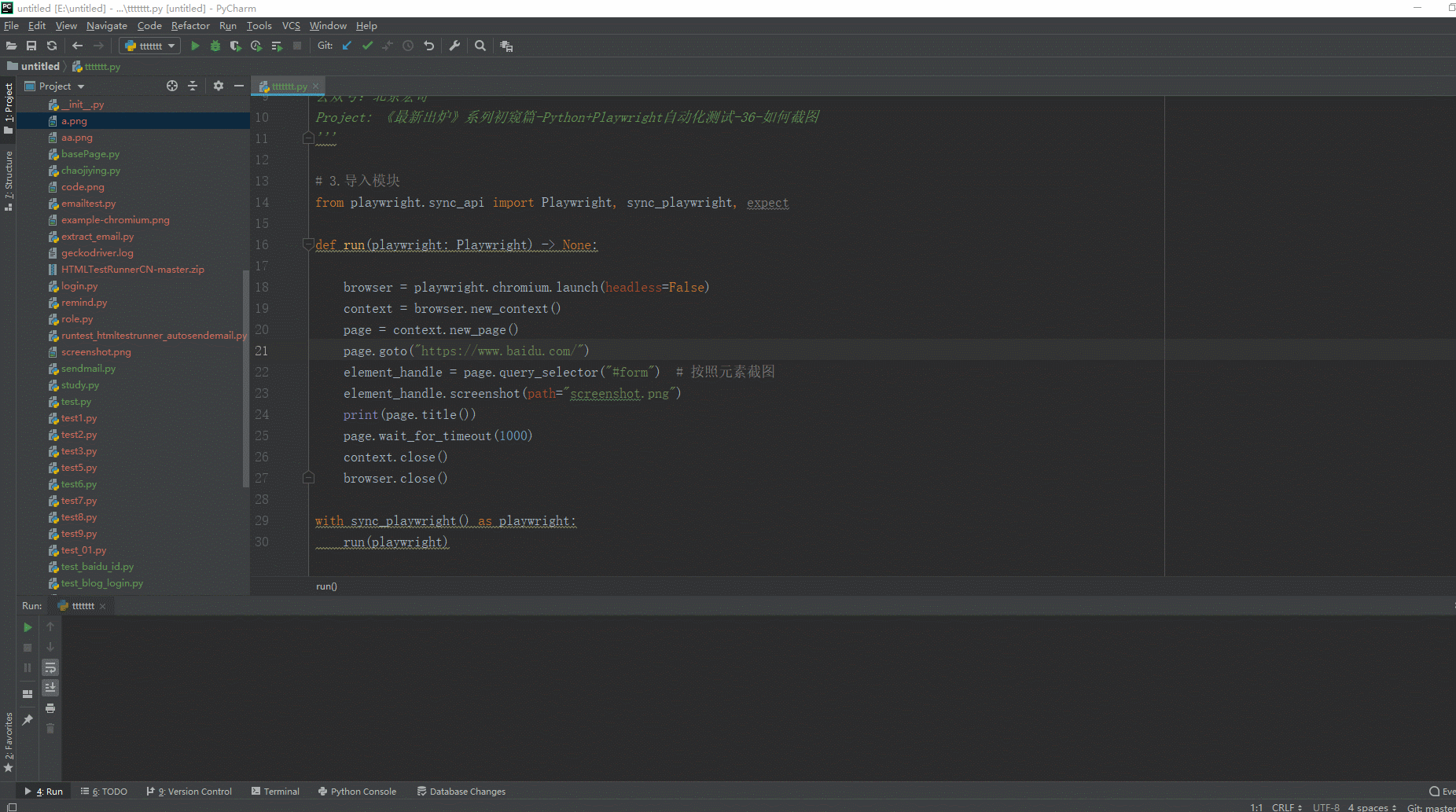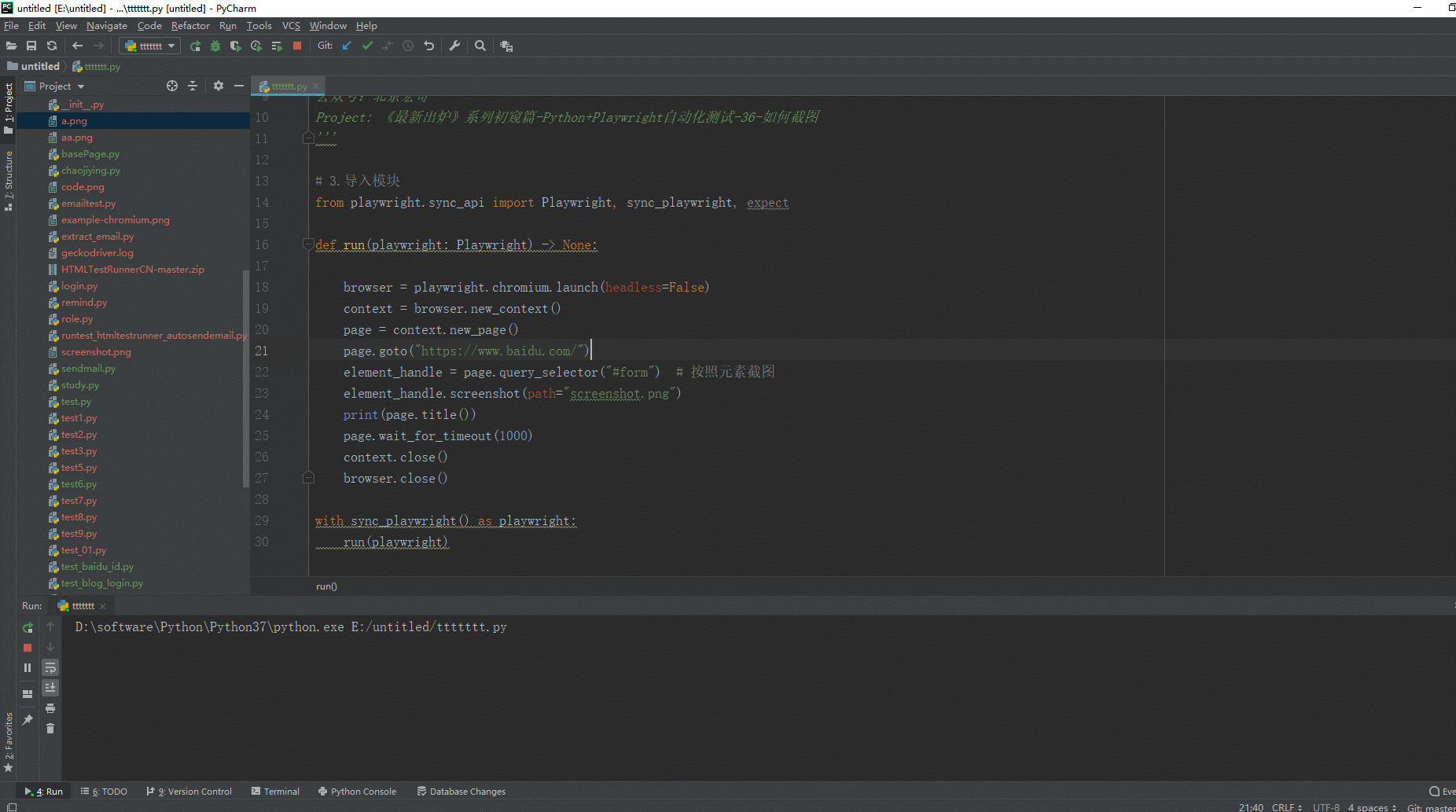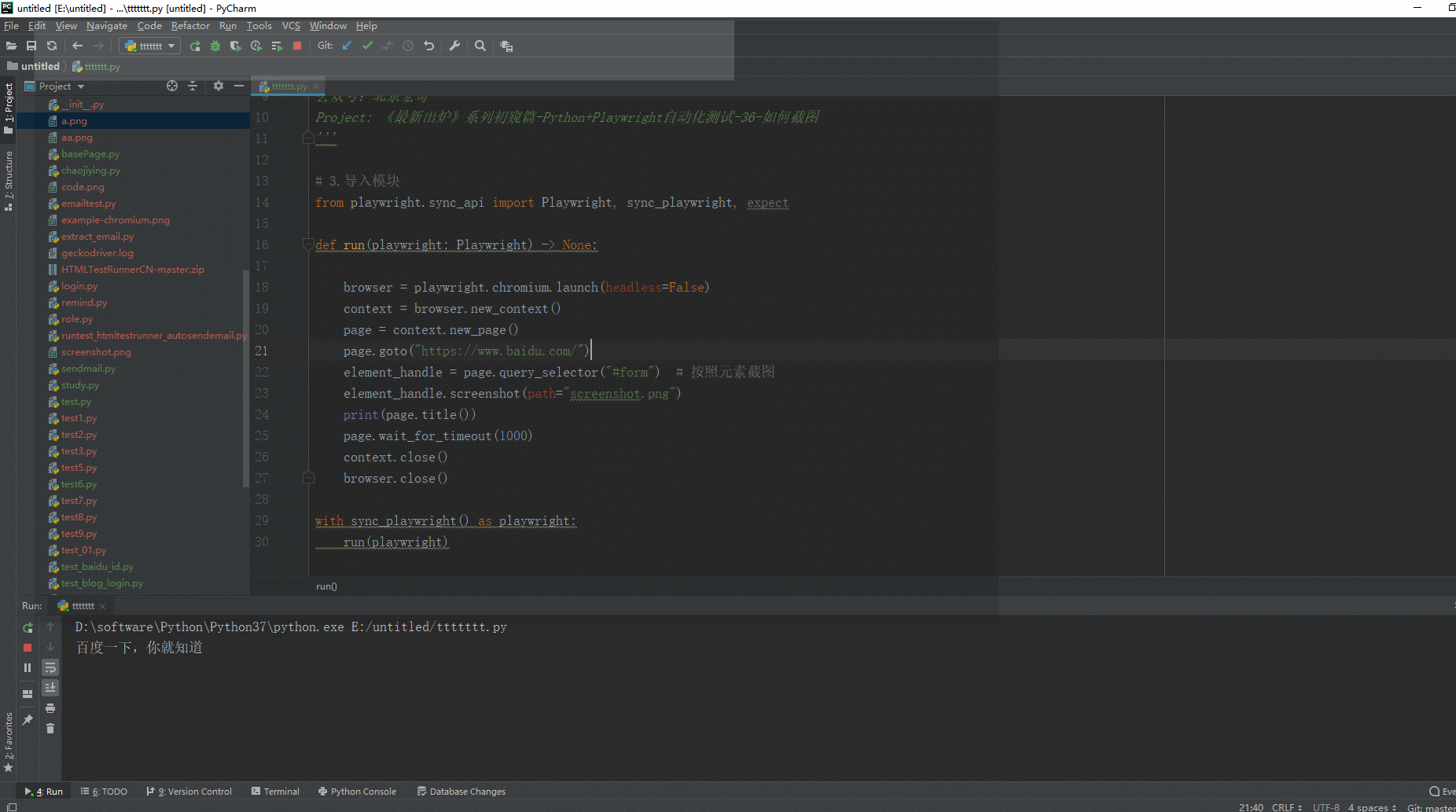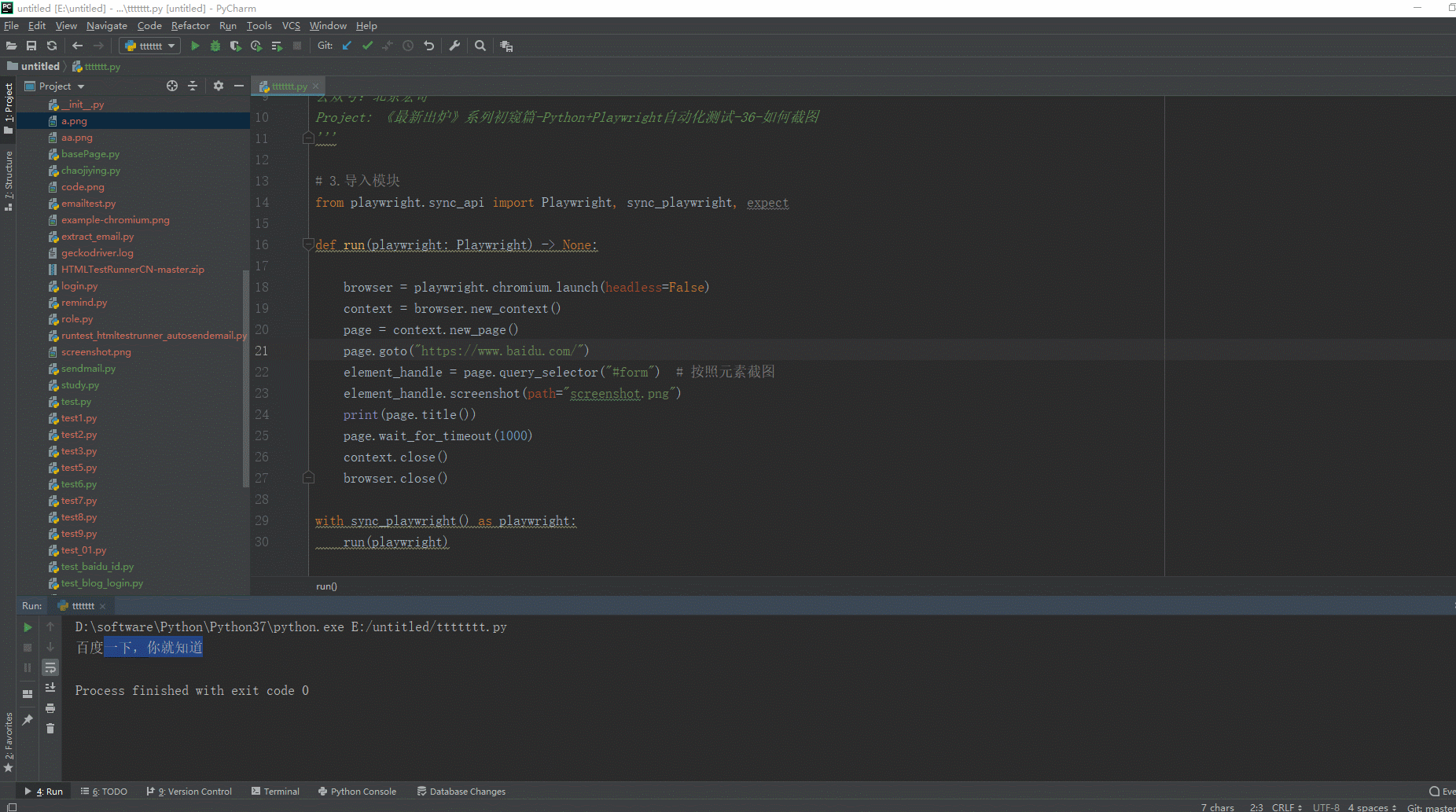
4.捕捉到缓冲区
使用base64对图片数据进行加密、解密。除了可以将页面截图保存为图片之外,也可以使用base64对图片数据进行加密和解密,将图片转换为一串字符。您可以获取包含图像的缓冲区并对其进行后处理或将其传递给第三方像素差异工具,而不是写入文件。语法如下:
screenshot_bytes = page.screenshot()
print(base64.b64encode(screenshot_bytes).decode())4.1代码设计
示例:截取页面后,转换为一串字符并输出。
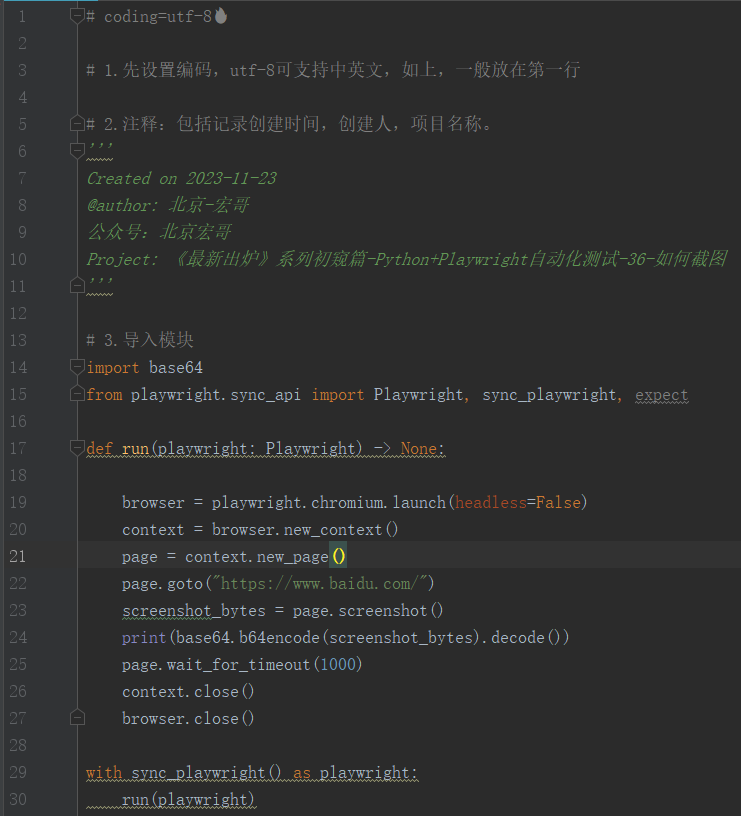
4.2参考代码
# coding=utf-8?
# 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行
# 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2023-11-23
@author: 北京-宏哥
公众号:北京宏哥
Project: 《最新出炉》系列初窥篇-Python+Playwright自动化测试-36-如何截图
'''
# 3.导入模块
import base64
from playwright.sync_api import Playwright, sync_playwright, expect
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("https://www.baidu.com/")
screenshot_bytes = page.screenshot()
print(base64.b64encode(screenshot_bytes).decode())
page.wait_for_timeout(1000)
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)4.3运行代码
1.运行代码,右键Run'Test',控制台输出(转换为一串字符并输出),如下图所示:
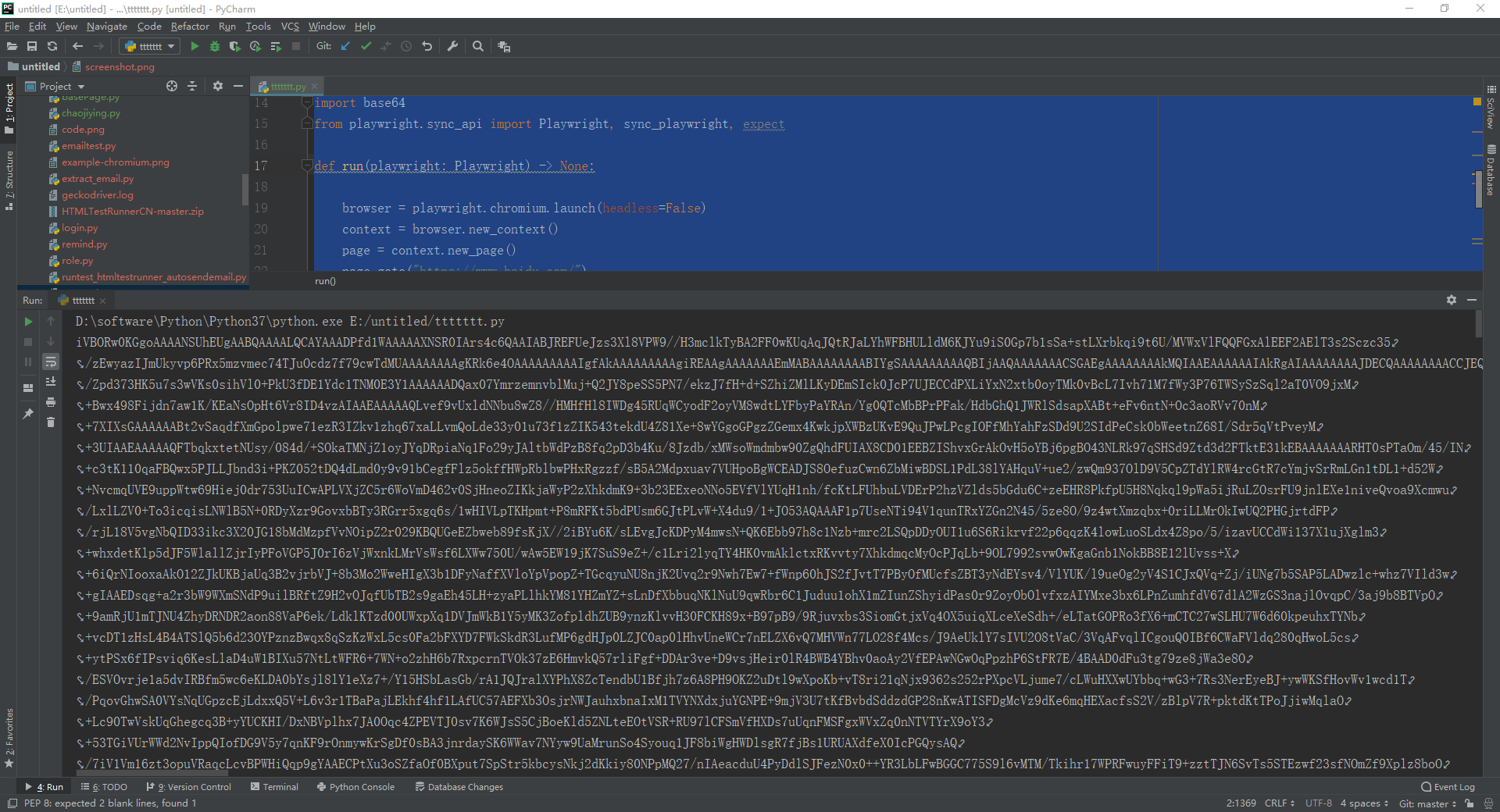
2.运行代码后电脑端的浏览器的动作。如下图所示:
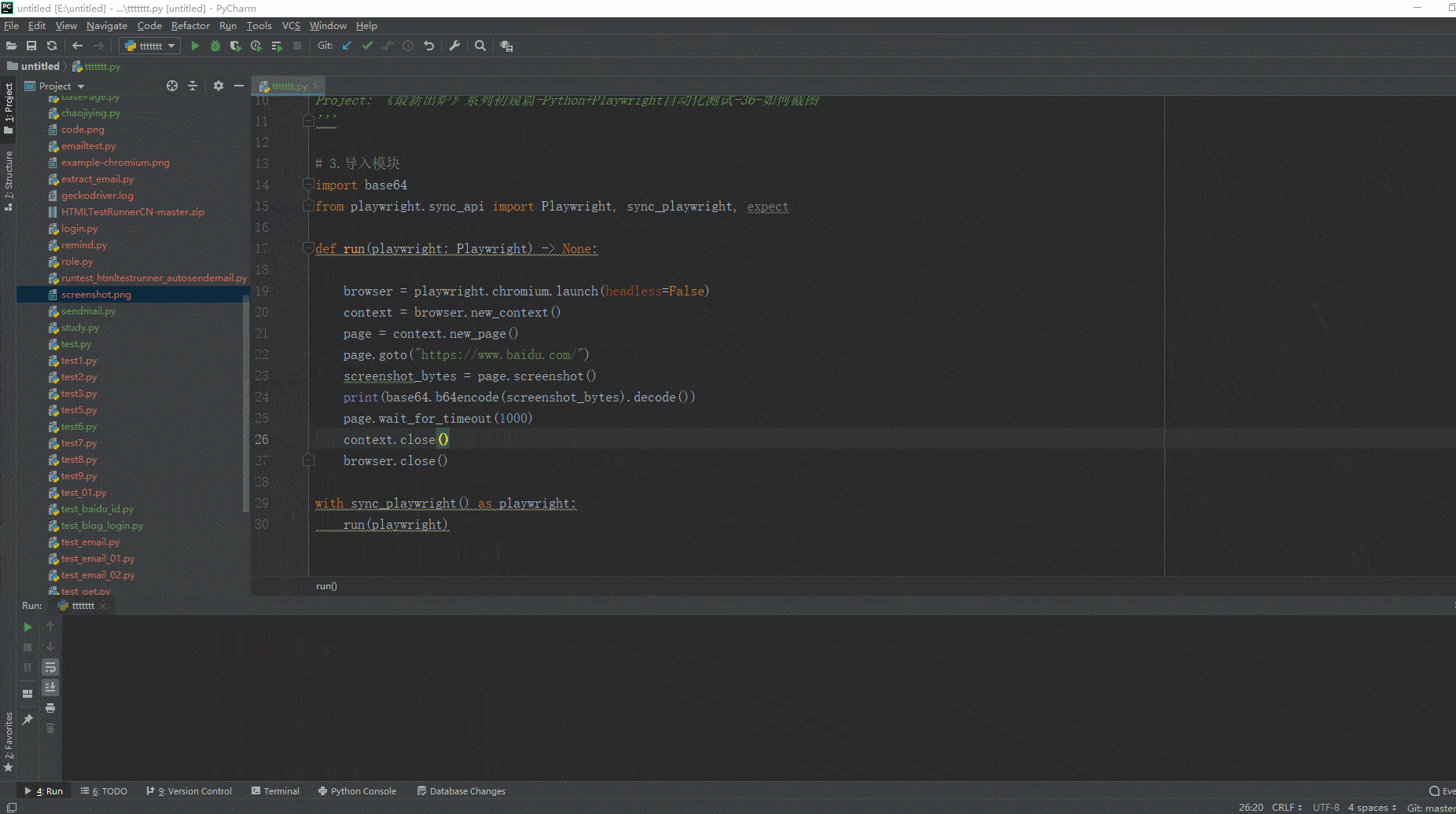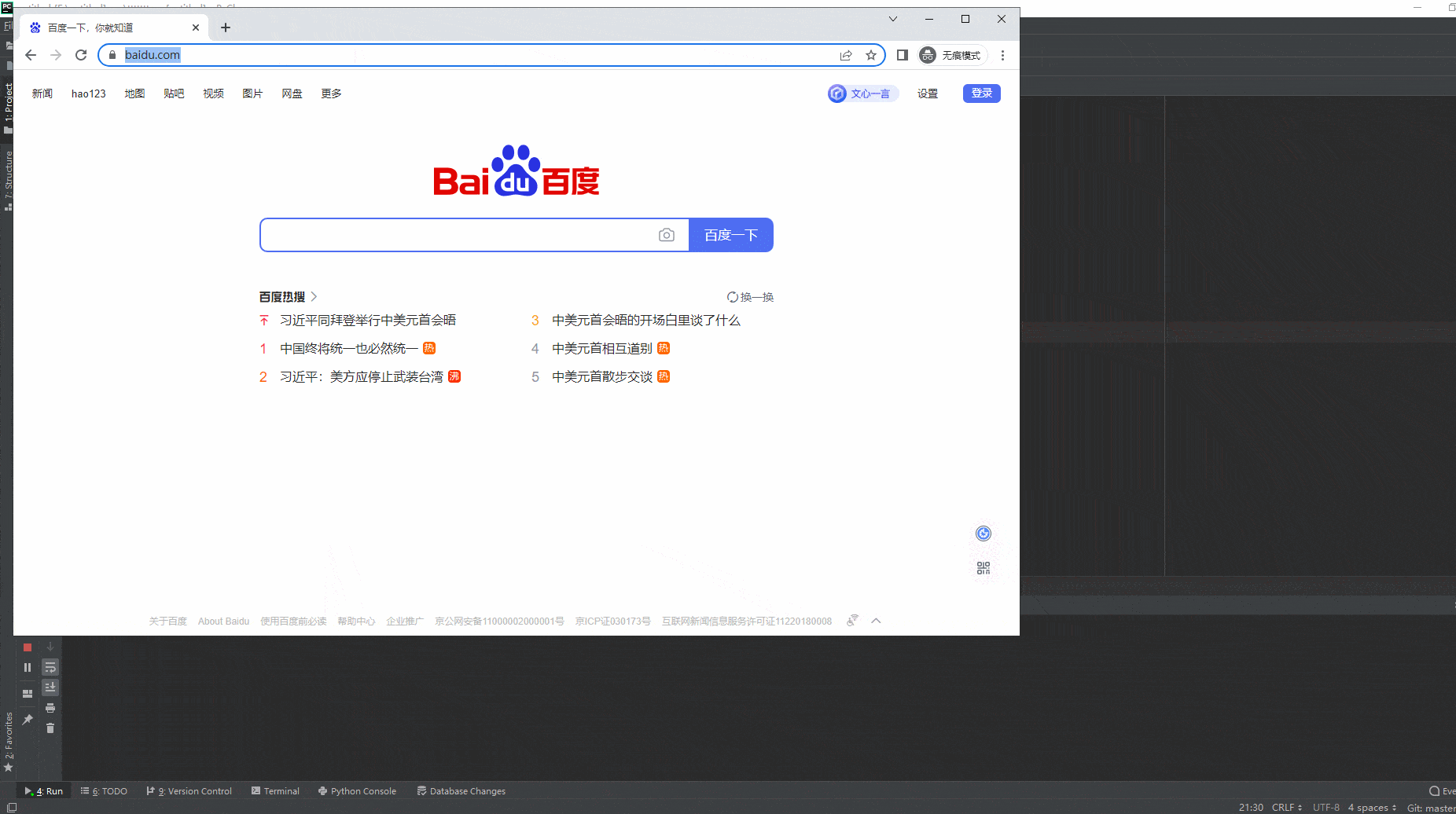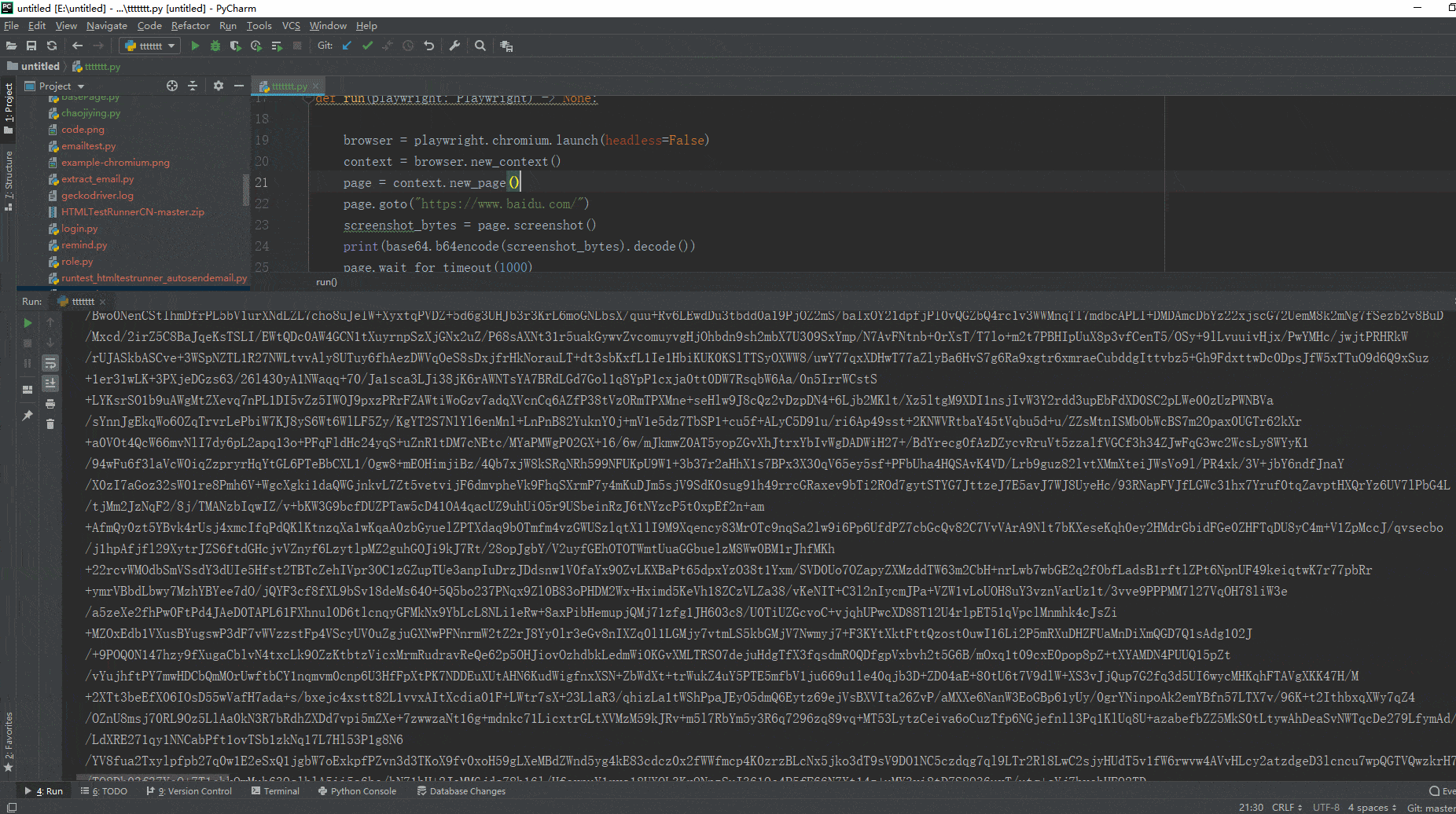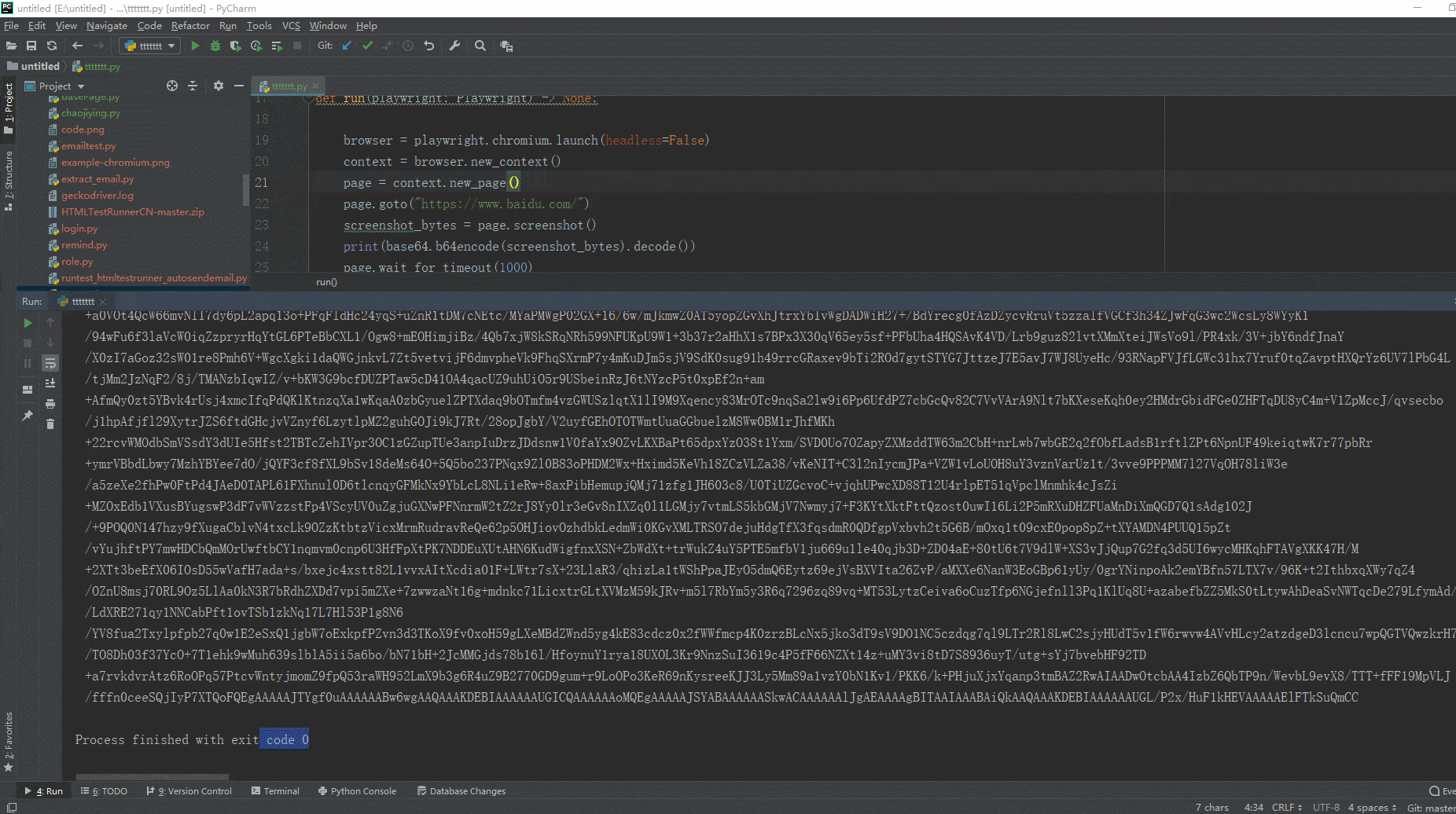
4.4在线Base64转图片
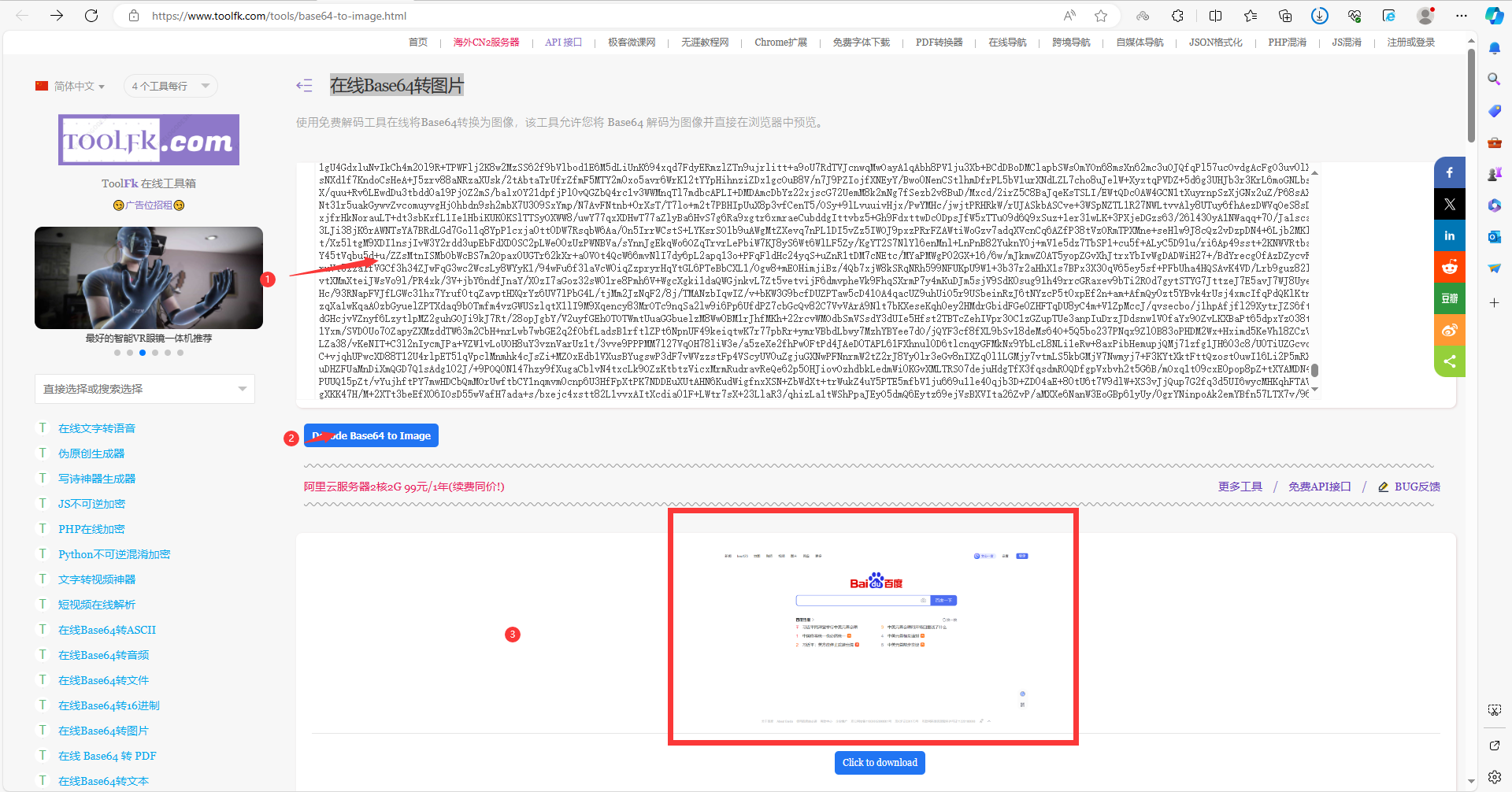
随便百度一个在线Base64转图片的地址,然后将我们上边控制台打印的Base64的字符串复制后,粘贴到工具里,将其转换成图片看看是不是我们的截图结果,如下图所示:
5.小结
好了,今天时间不早了,关于playwright的截图就先介绍讲解到这里,到此截图基础知识就差不多了,感谢您耐心的阅读!!!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。