浙大 & 蚂蚁 | 提出MyGO框架,旨在提升多模态知识图谱(MMKG)完整性!
浙大 & 蚂蚁 | 提出MyGO框架,旨在提升多模态知识图谱(MMKG)完整性!

引言
如何有效融合图像、文本等多模态信息以提高多模态知识图谱(MMKG)完整性,一直是多模态知识图谱的研究热点。当前MMKG补全方法往往忽略了多模态数据中的细粒度语义细节,进而影响了模型性能。
为此,本文作者提出了MyGO框架,旨在提升多模态知识图谱的完整性。MyGO通过将图像和文本等多模态数据转换为详细的标记序列,并利用这些信息来学习更精确的实体表示,有效提升了模型性能,超越了现有技术。

https://arxiv.org/pdf/2404.09468v1.pdf
背景介绍
多模态知识图谱(MMKGs)是一种结构化的知识表示方式,它通过将复杂的世界知识以结构化三元组的形式(头实体、关系、尾实体)进行封装,并结合多模态数据(图像、文本等)来提供额外的实体上下文信息,「这些丰富的三元组及其多模态内容共同构成了一个庞大的多模态语义网络」。MMKGs可以作为一个重要的事实知识数据库,应用各个业务场景领域,例如大模型知识更新、多模态理解、推荐系统等。
尽管如此,MMKGs在构建过程中经常会遇到知识构建不充分问题,为此很多研究人员提出了很多多模态知识图谱补全(MMKGC)方法,旨在自动从给定的MMKGs中识别出新的知识。传统的知识图谱补全主要侧重于三元组结构建模,而「MMKGC 需要额外的多模态信息,从各个角度丰富实体描述」,其本质是将三元组的结构信息与与实体相关的丰富的多模态特征整合起来。这种协同作用对于嵌入空间内的知识推理至关重要,在这一空间中,实体的丰富多模态信息作为补充信息,为三元组预测提供了强大而有效的多模态特征。
目前的多模态知识图谱补全(MMKGC)方法通常使用预训练模型生成单一的模态信息嵌入,并通过融合和预测模块来评估三元组的可信度。「但这种方法过于简单,不能很好地捕捉模态数据中的复杂细节」。在处理多个模态实例时,如多个图像,这些方法可能会丢失重要信息。原始的模态数据包含了丰富的语义单元,这些单元是理解实体特征的关键。但是,现有的方法往往通过生成静态嵌入来处理这些数据,导致有价值的细节信息丢失,限制了模型性能。
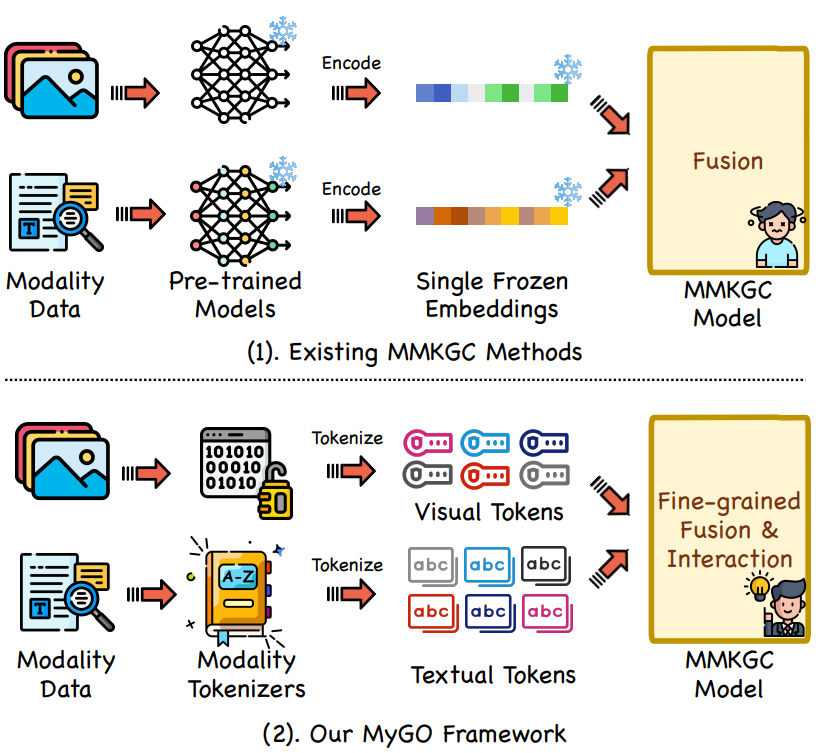
为此,本文提出了一个更细粒度的框架:MyGO(「M」odalit「Y」 information as fine-「G」rained tOkens),该框架允许MMKGC模型通过详细的交互捕捉数据中嵌入的微妙、共享的信息。通过更精细地处理和分析模态数据,MMKGC模型可以更好地理解和利用数据中的复杂关系和细节,从而提高补全的准确性和可靠性。
MyGO框架
MyGO主要由三个模块组成:Modality Tokenization(MT)模块、Hierarchical Triple Modeling(HTM)模块和细粒度对比学习(FGCL)模块,分别旨在处理、融合和增强MMKG中的细粒度信息。如下图所示:
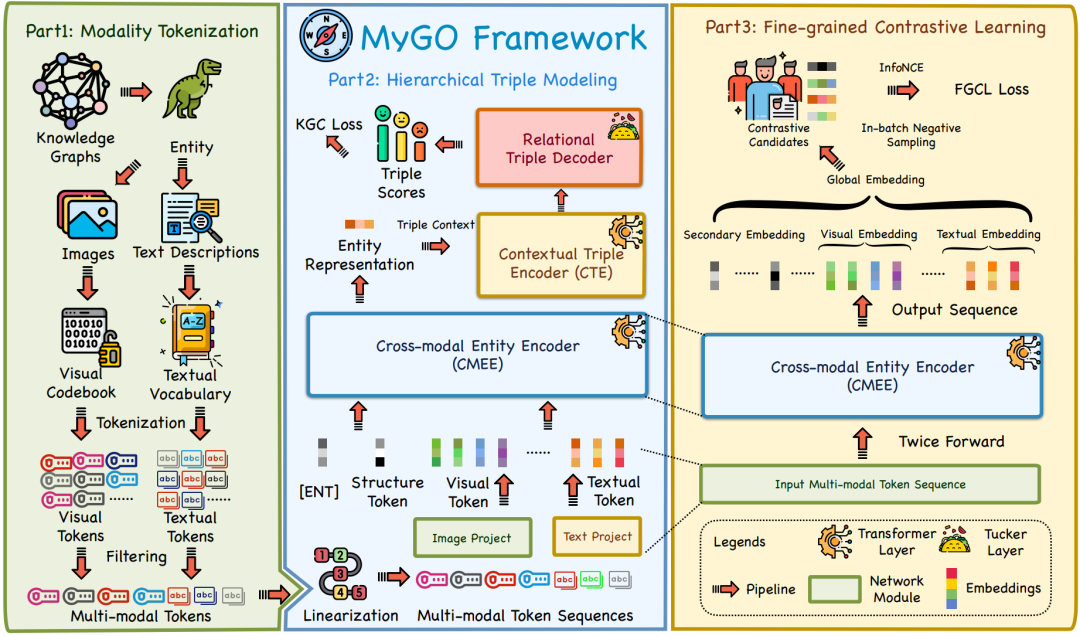
「MT模块」 主要负责捕捉多模态知识图谱中的细粒度语义信息。具体来说:它将实体的图像和文本信息转换为细粒度的标记序列。通过使用预训练的视觉和文本Token器,MT模块能够捕捉到每个实体中的关键视觉和语义特征,并将它们表示为一系列的视觉和文本Token。这些标记经过筛选和优化,去除了重复和不重要的元素,保留了最有价值的信息。
每个标记都被赋予一个可学习的嵌入向量,使得相同标记在不同实体间可以共享表示,同时保留了上下文的细微差异。MT模块生成的标记序列随后被用于跨模态实体编码器,以实现不同模态间的细粒度交互和特征融合。
「HTM模块」 负责处理和融合来自不同模态的信息,以学习和推断实体间的关系。HTM模块采用分层的方法来逐步构建和优化实体的表示,并预测知识图谱中的三元组。它主要包含三大组件:CMEE、CTE、Relational Decoder(关系解码器),如上图蓝底所示。
- 「CMEE」 用于捕捉实体的多模态表示。CMEE使用Transformer层来处理这些标记序列,并通过自注意力机制和前馈网络来学习实体的表示。CMEE的输入包括特殊的[ENT]标记、实体的结构信息、以及来自不同模态的标记序列。
- 「CTE」 用于编码给定查询的上下文嵌入。CTE的输入包括特殊标记[CXT]、实体?的输出表示,以及关系r的嵌入。这样,CTE能够捕捉到实体和关系的上下文信息,并为关系预测提供支持。
- 「关系解码器」 用于计算三元组的合理性得分。该组件通过张量积将实体和关系的嵌入结合起来,生成一个标量得分。模型使用交叉熵损失函数进行训练,并通过正负样本对比来优化。
「FGCL模块」 用于进一步提升实体表示质量的模块。该模块的目标是通过对比学习的方法,增强实体表示的区分性和鲁棒性,从而提高多模态知识图谱完成(MMKGC)任务的性能。
具体来说,FGCL 模块首先通过 CMEE 获得实体的两个表示,这两个表示由于 Transformer 编码器中的 dropout 层而具有细微的差异。此外,FGCL 模块还会从 Transformer 的输出中提取额外的表示,以捕捉实体特征的不同方面。这些表示被用来构建实体的候选集,用于对比学习。
实验结果
下表展示了MyGO与其他基线模型在DB15K和MKG-W数据集上的MMKGC主要结果,可以看到MyGO在DB15K和MKG-W数据集上的MRR和Hit@1、Hit@3、Hit@10指标上都实现了显著的提升。说明了MyGO在准确推理和细粒度信息处理方面的优势。
