基于VPP的第4层高密度可扩展负载均衡器
基于VPP的第4层高密度可扩展负载均衡器

本文翻译于Intel技术文档:高密度可扩展负载均衡器 - 基于VPP的第4层负载均衡器 的部分内容;点击文末阅读原文可直接跳转原文内容。
背景:自2006年起,构建运行于x86核心的软件型第4层负载均衡器(LB)的努力便已展开。此类LB以虚拟机形式部署,也应用于裸金属实现。超大规模云服务提供商(CSP)已在裸金属上开发出成本更低、易于部署和扩展的解决方案。CSP利用这些LB优化内部基础设施,并将其出售给订阅用户用于租赁实例。其中一种解决方案由谷歌开发并开源,名为MAGLEV,是一款云网络LB。MAGLEV是一款针对超大规模部署设计的通用LB,采用独特的加速技术提升性能。雅虎日本基于FD.io VPP开发了一款优化LB,并添加功能以实现LB即服务(LBaaS)的规模扩展。该实现使用4个核心即可达到10 Gbps的线速。现有的开源软件LB对当前用户存在性能与可扩展性限制,通常每个核心仅限约100万个并发连接和约200万包每秒(Mpps)的吞吐量。终端用户已投入大量资源试图克服以下局限,但尚未达到理想性能水平:
- 高性能:实现单节点150 Mpps的吞吐量和1亿会话能力
- 可扩展性:随着CPU核心数增加,吞吐量能线性增长
本文介绍了基于FD.io/VPP(矢量包处理)的L4 LB解决方案,充分利用了英特尔?架构及英特尔?以太网适配器特色功能。文中阐述了解决方案的架构,为提升性能与可扩展性所采取的四项关键优化策略(利用网卡的流导向器、优化图节点路径、矢量处理以及数据结构优化以减少缓存未命中),以及应用这些优化方法后的效果。相较于行业标准软件LB,面向英特尔?架构优化的LB能够实现每秒三倍的包处理能力、十倍的连接速率,且随着CPU核心数量提升,吞吐量近乎线性增长。
HDSLB-VPP 是一款基于英特尔专有许可(IPL)的软件级第4层负载均衡器项目。其目标在于打造业内性能领先的负载均衡器,实现每秒150百万包Mpps的吞吐量、每节点千万级别并发连接、每秒10百万次连接(CPS)处理能力,以及卓越的线性扩展性。HDSLB-VPP以Fd.io/VPP为基础进行轻量化定制,充分汲取VPP的优势,如并行性、可扩展性、丰富的网络栈以及独立的软件许可,并基于先进的英特尔架构(IA)特性开发了丰富的负载均衡功能。关键特性在英特尔主流平台(如第三代英特尔?至强?可扩展处理器、第四代英特尔?至强?可扩展处理器、英特尔?至强?D处理器等)上进行了深度优化,涵盖了英特尔?高级向量扩展2(Intel? AVX2)、英特尔?高级向量扩展512(Intel? AVX-512)、英特尔?以太网流导向技术(Intel? Ethernet FD)等技术。
HDSLB-VPP作为一款授权产品交付,附带在英特尔架构(IA)平台上部署负载均衡解决方案的最佳实践。它是现有顶级云服务提供商(CSPs)、通信服务提供商(CoSPs)客户扩展至边缘场景(如网络安全、电信及企业级供应商)的强大解决方案。下图展示了HDSLB的功能支持与体系架构。

Vector Packet Processing (VPP) 构建了网络数据平面进程的基础框架,并得到英特尔公司的专项技术投入以实现加速。HDSLB-VPP 即是以高性能、模块化及功能丰富的 VPP 框架为基础构建的。VPP 提供全面的 IPv4/IPv6 双栈协议支持,使我们能够快速实现定制化的第 3 层(L3)功能。作为 HDSLB-VPP 的核心特性之一,第 4 层(L4)负载均衡器易于集成,并通过运用英特尔硬件对LB场景进行了关键性能优化,从而达到业界领先的性能水平。
HDSLB-VPP 的整体软件架构划分为四个主要部分:
- 基础设施层:主要包括 VPP 向量化处理框架、配置接口、内存管理以及一些高性能基础库。
- 网络设备层:负责系统的输入输出流量。HDSLB-VPP 建议采用 VPP 原生 AVF 驱动程序。相较于 DPDK 插件驱动,原生驱动能实现更优性能。 HDSLB-VPP 推荐使用 VPP Native AVF (Accelerated Virtual Function) 驱动程序,相对于使用 DPDK (Data Plane Development Kit) 插件的驱动程序,主要有以下几个优势:更低延迟: Native AVF 驱动直接与硬件交互,通常具有更短的数据路径和更少的软件栈层级,从而减少数据包处理时的延迟。这对于对延迟敏感的应用(如金融交易、实时通信、云计算等)至关重要。CPU利用率: 由于原生驱动能更好地利用硬件特性(如硬件队列、中断卸载等),减少了 CPU 在处理 I/O 操作上的开销,使得 CPU 能够更专注于数据包处理或业务逻辑,提高了整体系统的资源利用率。集成 Intel 硬件加速技术: HDSLB-VPP 整合了丰富的 Intel 硬件加速特性,如 E810 网卡支持的 RSS (Receive Side Scaling, 接收方扩展)、Checksum Offload (校验和卸载)、FDIR (Flow Director, 流导向器) 等。这些功能允许网络设备自行处理一些复杂的网络任务,如负载均衡、校验计算、流分类等,减轻了主机 CPU 的负担,进一步提升数据包处理速度和整体系统性能。减少额外依赖: 使用 Native AVF 驱动可以避免引入额外的 DPDK 层,简化了软件栈,降低了配置、编译、部署和维护的复杂性。这不仅节省了开发和运维成本,还可能减少潜在的软件冲突或兼容性问题。
- 协议栈层:以负载均衡服务为核心,本层提供诸如 IPv4、IPv6、TCP、UDP等必要的协议交互,并支持 ICMP以适应更多应用场景。
- 负载均衡实现层:HDSLB-VPP 是一款具备会话管理功能的状态化四层负载均衡器,提供如 FNAT/NAT/DR 和 IPIP 封装等多种负载均衡特性(见图 2),并支持 SNAT 协议,赋予请求服务器(RS)访问外部服务的能力。RS 调度算法支持 RR(轮询)、WRR(加权轮询)、WLC(加权最少连接)及一致哈希算法。
除了卓越的负载均衡能力外,HDSLB-VPP 在高可用性方面支持主备模式、会话同步以及健康检查。
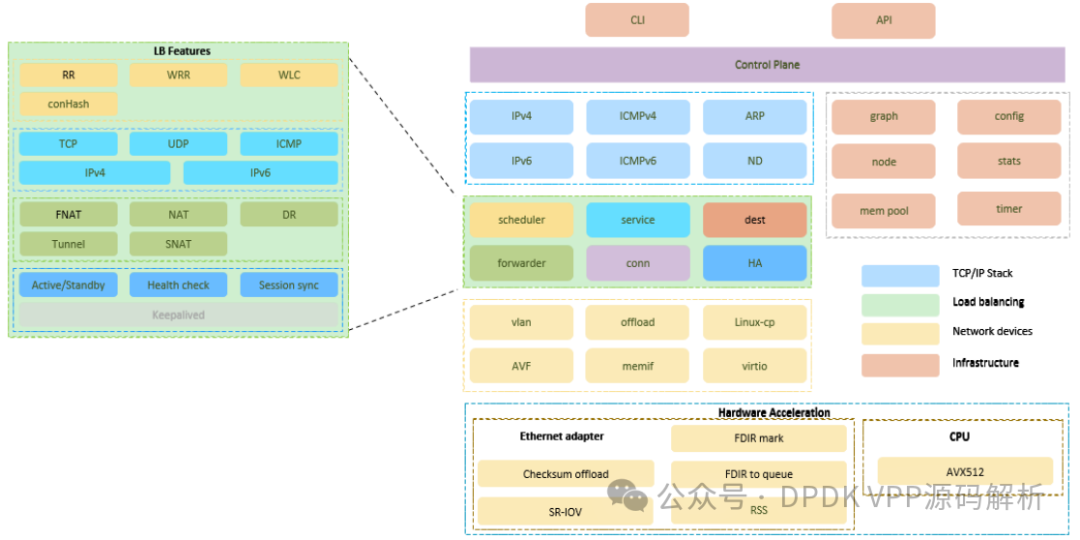
- 英特尔? 以太网 FDIR配置处理:HDSLB-VPP 利用了英特尔? 以太网 FDIR 的标记功能。当用户配置负载均衡服务时,需要用户提供以下信息:协议(IPv4/IPv6、TCP/UDP等)、IP地址以及第4层端口号。HDSLB-VPP利用这些信息来配置英特尔? 以太网 FDIR。配置完成后,英特尔? 以太网 FDIR 硬件将比较目的IP地址、目的端口以及相应的协议是否与用户指定的配置相匹配,并对相同流量进行标记。一旦驱动程序接收到该流量,HDSLB-VPP 即将之转交给负载均衡模块;而负载均衡模块在处理阶段也可通过利用已标记的流量,省去部分处理步骤。
- 数据平面处理:HDSLB-VPP 通过采用英特尔硬件加速技术得以加速。对于不具备这些硬件加速技术的平台,HDSLB-VPP 也可以通过软件模拟的方式部署并处理英特尔? 以太网 FDIR,但在此情况下性能较低。本部分仅介绍采用英特尔硬件加速技术的数据平面处理流程。
在用户配置负载均衡服务后,HDSLB-VPP 启用Intel Ethernet Flow Director(FDIR)对LB流量进行标记。被标记的LB流量将直接送往LB节点进行处理,而未被标记的流量(如ARP请求、路由协议信息或其他控制平面流量)则会被送至VPP的“以太网输入”节点。所有未标记流量随后进入VPP自身的协议栈进行处理。
在多核系统中,通过RSS(Receive Side Scaling)实现流量的分布式处理。接收到网络数据后,流量首先抵达LB模块中的LB输入节点,如上图所示。LB输入节点利用批量缓存加速网络流量处理,旨在尽量避免处理过程中零散的内存访问,以降低缓存缺失率。
接下来,在会话表中进行查找。若未能找到匹配会话,则创建新会话。创建新会话时,根据用户配置的调度算法(如RR、WRR、WLC、ConHash等)选取真实服务器。创建会话后,按照转发规则(如NAT、FNAT等)对数据包进行封装。最终,封装后的数据包被发送至底层TX硬件进行传输。
- 性能优化
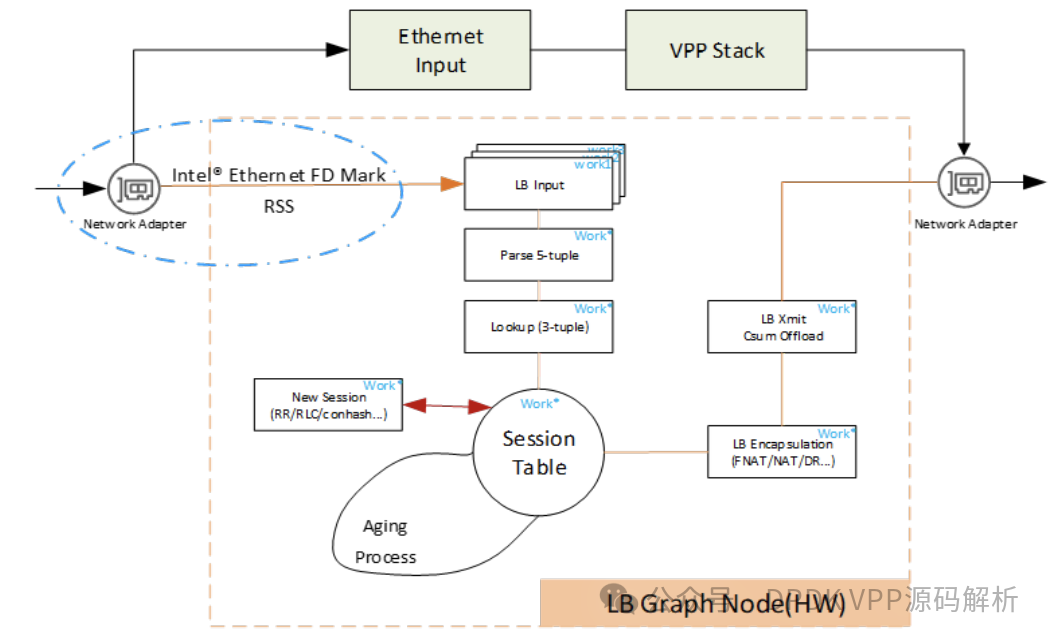
相较于在VPP中使用DPDK插件,HDSLB-VPP采用了AVF插件进行数据包的接收与发送。为了提升性能,AVF插件无需将DPDK的‘rte_mbuf_t’结构转换为VPP的‘vlib_buffer_t’结构,从而节省了结构转换的时间。同时,通过利用Intel? Ethernet 800系列网卡的Intel? Ethernet FD功能,为LB流量添加标签,这些标签可以直接在AVF插件中用于区分流量,并将其直接送达LB节点进行下一步处理。
在VPP中,已存在实现LB功能的图节点。考虑到原生处理流程较为复杂,且流量需经过更多节点,这对性能造成一定影响,无法充分利用IA平台的优化潜力。在实现过程中,HDSLB-VPP对图节点进行了重新排列,通过少量图节点优化了转发性能。
在LB插件内部,LB节点运用VPP的向量化处理优化缓存未命中问题。通过预取操作,优化了会话哈希表和真实服务器对象,实施五级分布式预取,提升了d-cache和i-cache命中率,在零丢包及0.001%丢包测试中增强了稳定性。
最后,为实现高性能,HDSLB-VPP中的大多数LB场景均采用无锁设计,每个CPU核心仅访问本地数据。相较于其他平台实现,VPP采用索引化数据结构进行索引,极大地提升了内存查找效率和空间利用率。
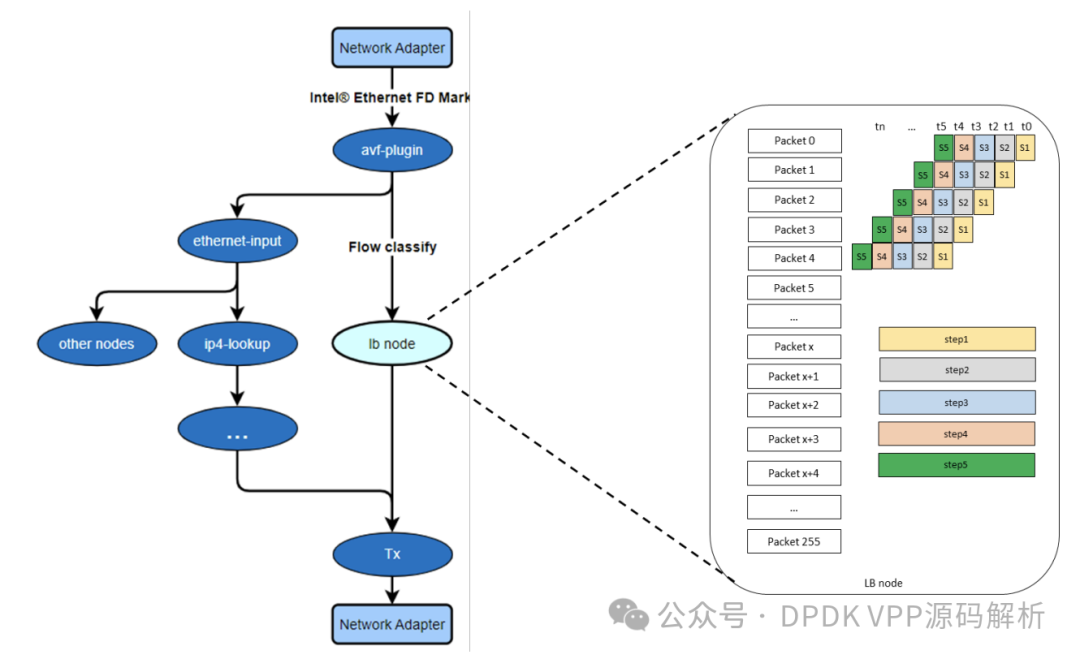
- 高可用性框架
在 HDSLB-VPP 中,我们运用 Keepalived 实现高可用(HA)功能。Keepalived 是业界广泛采纳的一种解决方案,基于 VRRP(虚拟路由冗余协议)构建,具备全面的高可用性功能覆盖。
当发生主备切换及健康检查处理时,Keepalived 必须同步 HDSLB-VPP 转发引擎状态的变动。例如,在主备状态开始转换时,VPP 与 Keepalived 的状态需保持一致。同样,当用户服务器(真实服务器)的健康检查状态发生变化时,VPP 与 Keepalived 会同步将真实服务器添加至或移出各自集群配置中。HDSLB-VPP 利用 Keepalived 的通知脚本机制,确保在 Keepalived 状态变化时自动调用相应脚本。通过 HDSLB-VPP 预留的命令接口,转发引擎可即时更新状态。
会话同步特性源于其与负载均衡(LB)业务的深度绑定,该特性通过在 LB 模块内部实现独立的会话同步节点得以实现。HDSLB-VPP 采用 UDP 数据包进行周期性的会话同步,同时感知 LB 转发节点的繁忙程度,自动调整同步会话的数量与周期,以确保主备设备间会话状态的一致性。
至此,我们介绍了HDSLB-VPP基本框架及高性能、高可用、高性能的实现细节。很可惜此软件未开源,如需商业用途,需要联系intel技术人员,可通过HDSLB开源库帮助文档中获取:https://github.com/intel/high-density-scalable-load-balancer。
关于文中提到的VPP 原生avf插件,翻看了vpp的源码并未说明支持E800网卡。此部分可以也是闭源。