Elasticsearch: 向量相似性计算 - 极速
原创Elasticsearch: 向量相似性计算 - 极速
原创
任何向量数据库的核心都是决定两个向量接近程度的距离函数。这些距离函数在索引和搜索过程中被多次执行。当合并数据段或在图中寻找最近邻居时,大部分的执行时间都花在了比较向量的相似性上。对这些距离函数进行微优化是值得的,我们已经从以前类似的优化中获益,例如,参见 SIMD,FMA。
随着最近对Lucene和Elasticsearch中标量量化的支持,我们现在更多地依赖这些距离函数的byte版本。我们从以前的经验中知道,这些版本还有很大的性能改进潜力。
目前的状况
当我们利用Panama Vector API来加速Lucene中的距离函数时,主要关注的是float(32位)版本。我们对于这些版本的性能改进感到非常满意。然而,对于byte(8位)版本的改进有点令人失望 - 相信我,我们努力了!byte版本的根本问题在于它们没有充分利用CPU上可用的最优SIMD指令。
当在Java中进行算术运算时,最窄的类型是int(32位)。JVM会自动将byte值扩展为int类型的值。考虑这个简单的标量点积实现:
int dotProduct(byte[] a, byte[] b) {
int res = 0;
for (int i = 0; i < a.length; i++) {
res += a[i] * b[i];
}
return res;
}元素a和b的乘法运算是按照a和b是int类型来执行的,其值是从相应数组索引加载的字节值扩展为int。
我们的SIMD化实现必须是等价的,所以我们需要小心确保当乘以大的byte值时不会丢失溢出。我们通过明确地将加载的byte值扩展为short(16位)来做到这一点,因为我们知道所有的带符号字节值在乘法时都可以无损地适应带符号的short。然后我们需要进一步扩展为int(32位)来进行累加。
以下是Lucene的128位点积代码的内循环主体的摘录:
ByteVector va8 = ByteVector.fromArray(ByteVector.SPECIES_64, a, i);
ByteVector vb8 = ByteVector.fromArray(ByteVector.SPECIES_64, b, i);
// process first "half" only: 16-bit multiply
Vector<Short> va16 = va8.convert(B2S, 0); // B2S Byte2Short
Vector<Short> vb16 = vb8.convert(B2S, 0);
Vector<Short> prod16 = va16.mul(vb16);
// 32-bit add - S2I Short2Int
acc = acc.add(prod16.convertShape(S2I, IntVector.SPECIES_128, 0));通过可视化,我们可以看到我们一次只处理4个元素,例如。
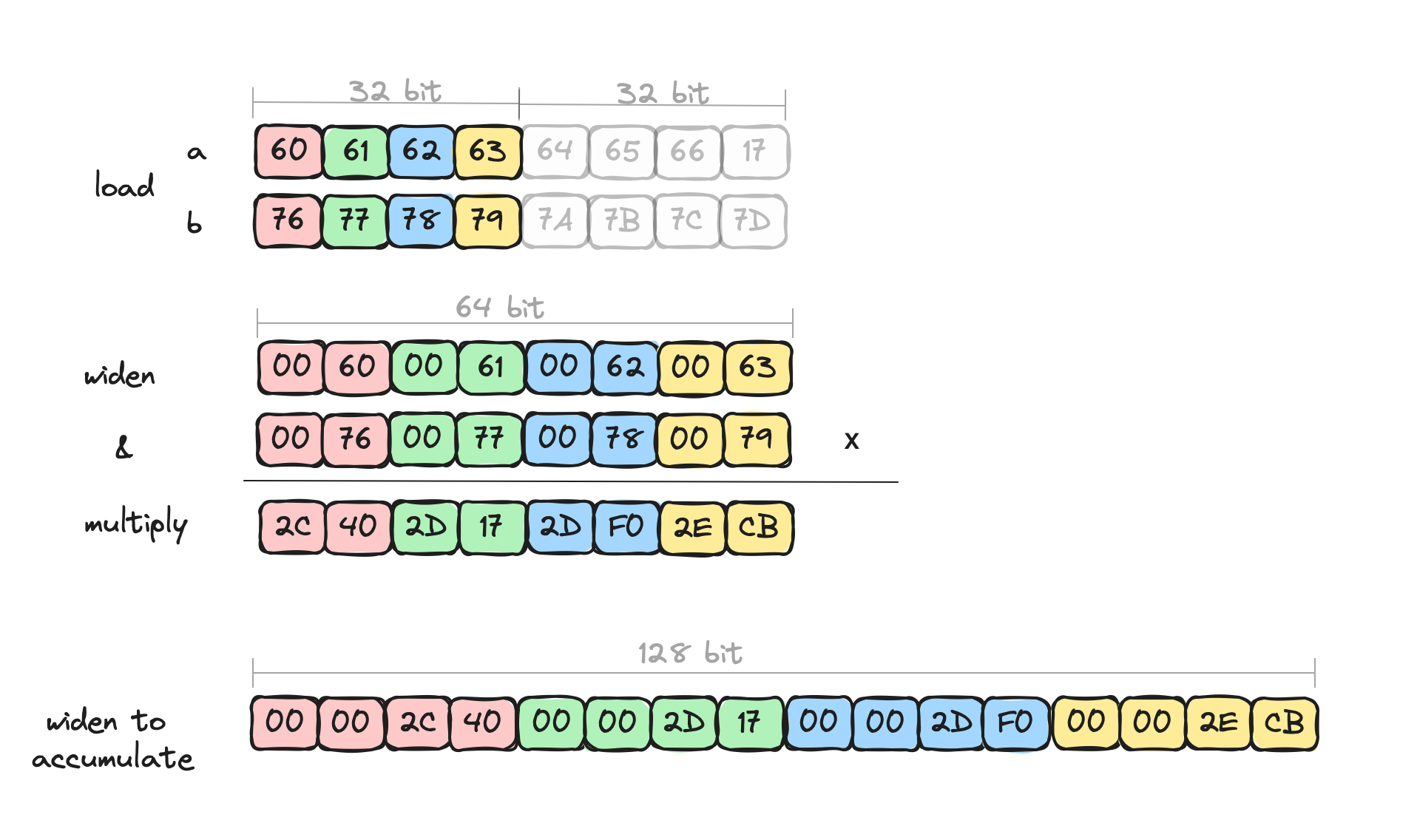
尽管有这些明确的扩宽对话,我们通过算术运算的额外数据并行性获得了一些不错的速度提升,但没有我们知道可能的提升多。我们知道还有剩余潜力的原因是,每次扩宽都会将通道数量减半,这实际上减半了算术运算的数量。显式扩宽对话没有被JVM的C2 JIT编译器优化。此外,我们只访问了数据的下半部分 - 访问除下半部分以外的任何内容都不会产生好的机器代码。这就是我们放弃潜在性能的地方。
目前,这是我们在Java中能做的最好的。长期来看,Panama Vector API和/或C2 JIT编译器应该为这样的操作提供更好的支持,但就目前而言,这是我们能做的最好的。或者是吗?
引入(另一个)Panama API - FFM
OpenJDK的Panama项目有几个不同的部分,我们已经看到了Panama Vector API的应用,但是项目的旗舰是Foreign Function & Memory API(FFM)。FFM API提供了与Java运行时外部的代码和内存交互的低开销。JVM是一项令人惊叹的工程成果,抽象了很多架构和平台之间的差异,但有时它不一定能做出最好的折衷,这是可以理解的。当JVM不能轻易做到这一点时,FFM可以通过让程序员亲自动手来解冑问题,如果她不喜欢已经做出的折衷。这就是一个这样的领域,其中Panama Vector API的折衷对于byte大小的向量来说并不是最好的。
我们已经在Lucene中利用了外部内存支持来安全地访问映射的堆外索引数据。为什么不使用外部调用支持来调用已经优化的距离计算函数呢?既然我们的距离计算函数很小,并且对于我们已经知道最优的CPU指令集的一些部署和架构,为什么不直接编写我们想要的小块本地代码呢?然后通过外部调用API来调用它。
进入外部
Elastic Cloud有一个专门为向量搜索优化的配置文件。这个配置文件针对的是ARM架构,让我们来看看我们如何为这个架构进行优化。
我们用C语言和一些ARM Neon内置函数来编写我们的距离函数,比如点积。同样,我们将重点放在循环的内部主体上。下面是它的样子:
int32x4_t acc1, acc2 // = vdupq_n_s32(0);
...
// Read into 16 x 8 bit vectors.
int8x16_t va8 = vld1q_s8((const void*)(a + i));
int8x16_t vb8 = vld1q_s8((const void*)(b + i));
int16x8_t va16 = vmull_s8(vget_low_s8(va8), vget_low_s8(vb8));
int16x8_t vb16 = vmull_s8(vget_high_s8(va8), vget_high_s8(vb8));
// Accumulate 4 x 32 bit vectors (adding adjacent 16 bit lanes).
acc1 = vpadalq_s16(acc1, va16);
acc2 = vpadalq_s16(acc2, vb16);我们将a和b向量中的16个8位值加载到va8和vb8中。然后我们乘以下半部分并将结果存储在va16中 - 这个结果包含8个16位的值,操作隐含地处理了扩宽。对于上半部分也是类似的。最后,由于我们对所有原始的16个值进行了操作,使用两个累加器来存储结果更快。vpadalq_s16加和累积内置函数知道如何在累积为4个32位值时隐含地扩宽。总之,我们每次循环迭代都对所有16个byte值进行了操作。很好!
这个的汇编很干净,反映了上面的内置函数。
ldr q2, [x1, x8] # loads first vector data into 128-bit q2
ldr q3, [x2, x8] # loads second vector data into 128-bit q3
smull.8h v4, v2, v3 # multiplies low half, result in v4
smull2.8h v2, v2, v3 # multiplies high half, result in v2
sadalp.4s v0, v4 # accumulates into v0
sadalp.4s v1, v2 # accumulates into v1ARM上的Neon SIMD有提供我们想要的语义的算术指令,无需进行额外的明确扩宽。C内置函数使我们能够使用这些指令。在寄存器中密集打包的值的操作比我们可以用Panama Vector API做的要干净得多。
回到Java-land
解谜的最后一块是Java中的一个小的"shim"层,它使用FFM API链接到我们的外部代码。我们的向量数据是堆外的,我们用MemorySegment映射它,并根据向量维度确定偏移量和内存地址。
点积方法如下:
static int dot8s(MemorySegment a, MemorySegment b, int dims) {
var mh$ = dot8s$MH();
try {
return (int)mh$.invokeExact(a, b, dims);
} catch (Throwable ex$) {
...
}
}我们在这里还有更多的工作要做,因为这现在是平台特定的Java代码,所以我们只在aarch64平台上执行它,在其他平台上使用另一种实现。
那么,它比Panama Vector代码实际上更快吗?
性能
对上面的有符号字节值的点积的微观基准测试显示,性能提高了大约6倍,比Panama Vector代码快。这包括了外部调用的开销。速度提升的主要原因是我们能够将满128位的寄存器打包成值,并在不明确移动或扩宽数据的情况下对所有这些值进行操作。
宏观基准测试,SO_Dense_Vector启用了标量量化,显示出在合并时间上有显著的改进,大约快3倍 - 实验只将优化的点积插入到段合并中。我们预计搜索基准测试也会显示出改进。
总结
Java的最近进步,即FFM API,允许我们以比以前更高的性能和更直接的方式与本地代码进行互操作。通过提供微优化的平台特定的向量距离函数,这些函数通过FFM调用,可以获得显著的性能优势。
我们期待未来版本的Elasticsearch能够利用这种性能改进,使标量量化向量受益。当然,我们也在深思熟虑如何将这种关系应用到Lucene甚至Panama Vector API上,以确定如何改进它们。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。