上海某小厂面试,差点没扛住。。。

大家好,我是小林。
之前有同学反馈想看看小厂Java后端的面试难度,准备也差不多了,想找个小厂投一下看一下效果。
今天给大家分享一位同学上海某小厂的后端面经,面 30 分钟,没有算法,主要是技术八股和项目为主。

考察的知识点,我也帮大家罗列了下:
- Java:equals、integer、集合、volatile、hashmap
- 基础:jwt、tcp 和 udp、零拷贝、红黑树
- 项目:二级缓存、数据一致性、缓存穿透、netty 架构
小厂八股
== 与 equals 有什么区别?
对于字符串变量来说,使用"=="和"equals"比较字符串时,其比较方法不同。
"=="比较两个变量本身的值,即两个对象在内存中的首地址,"equals"比较字符串包含内容是否相同。
对于非字符串变量来说,如果没有对equals()进行重写的话,"==" 和 "equals"方法的作用是相同的,都是用来比较对象在堆内存中的首地址,即用来比较两个引用变量是否指向同一个对象。
- ==:比较的是两个字符串内存地址(堆内存)的数值是否相等,属于数值比较;
- equals():比较的是两个字符串的内容,属于内容比较。
说一下 integer的缓存
Java的Integer类内部实现了一个静态缓存池,用于存储特定范围内的整数值对应的Integer对象。
默认情况下,这个范围是-128至127。当通过Integer.valueOf(int)方法创建一个在这个范围内的整数对象时,并不会每次都生成新的对象实例,而是复用缓存中的现有对象,会直接从内存中取出,不需要新建一个对象.
数组与集合区别,用过哪些?
数组和集合的区别:
- 数组是固定长度的数据结构,一旦创建长度就无法改变,而集合是动态长度的数据结构,可以根据需要动态增加或减少元素。
- 数组可以包含基本数据类型和对象,而集合只能包含对象。
- 数组可以直接访问元素,而集合需要通过迭代器或其他方法访问元素。
我用过的一些 Java 集合类:
- ArrayList: 动态数组,实现了List接口,支持动态增长。
- LinkedList: 双向链表,也实现了List接口,支持快速的插入和删除操作。
- HashMap: 基于哈希表的Map实现,存储键值对,通过键快速查找值。
- HashSet: 基于HashMap实现的Set集合,用于存储唯一元素。
- TreeMap: 基于红黑树实现的有序Map集合,可以按照键的顺序进行排序。
- LinkedHashMap: 基于哈希表和双向链表实现的Map集合,保持插入顺序或访问顺序。
- PriorityQueue: 优先队列,可以按照比较器或元素的自然顺序进行排序。
集合遍历的方法有哪些?
在Java中,集合的遍历方法主要有以下几种:
- 普通 for 循环: 可以使用带有索引的普通 for 循环来遍历 List。
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
list.add("C");
for (int i = 0; i < list.size(); i++) {
String element = list.get(i);
System.out.println(element);
}
- 增强 for 循环(for-each循环): 用于循环访问数组或集合中的元素。
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
list.add("C");
for (String element : list) {
System.out.println(element);
}
- Iterator 迭代器: 可以使用迭代器来遍历集合,特别适用于需要删除元素的情况。
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
list.add("C");
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()) {
String element = iterator.next();
System.out.println(element);
}
- ListIterator 列表迭代器: ListIterator是迭代器的子类,可以双向访问列表并在迭代过程中修改元素。
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
list.add("C");
ListIterator<String> listIterator= list.listIterator();
while(listIterator.hasNext()) {
String element = listIterator.next();
System.out.println(element);
}
- 使用 forEach 方法: Java 8引入了 forEach 方法,可以对集合进行快速遍历。
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
list.add("C");
list.forEach(element -> System.out.println(element));
- Stream API: Java 8的Stream API提供了丰富的功能,可以对集合进行函数式操作,如过滤、映射等。
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
list.add("C");
list.stream().forEach(element -> System.out.println(element));
这些是常用的集合遍历方法,根据情况选择合适的方法来遍历和操作集合。
volatile的作用是什么?
volatile关键字通过两种机制来保证内存可见性:
- 禁止指令重排序:在程序运行时,为了提高性能,编译器和处理器可能会对指令进行重排序,这可能会导致变量的更新操作被延迟执行或者乱序执行,从而使得其他线程无法立即看到最新的值。使用volatile关键字修饰的变量会禁止指令重排序,保证变量的更新操作按照代码顺序执行。
- 内存屏障:在多核处理器架构下,每个线程都有自己的缓存,volatile关键字会在写操作后插入写屏障(Write Barrier),在读操作前插入读屏障(Read Barrier),确保变量的更新能够立即被其他线程看到,保证内存可见性。
通过禁止指令重排序和插入内存屏障,volatile关键字能够保证被修饰变量的更新操作对其他线程是可见的,从而有效解决了多线程环境下的内存可见性问题。
指令重排序的原理
在执行程序时,为了提高性能,处理器和编译器常常会对指令进行重排序,但是重排序要满足下面 2 个条件才能进行:
- 在单线程环境下不能改变程序运行的结果
- 存在数据依赖关系的不允许重排序。
所以重排序不会对单线程有影响,只会破坏多线程的执行语义。
我们看这个例子,A和C之间存在数据依赖关系,同时B和C之间也存在数据依赖关系。因此在最终执行的指令序列中,C不能被重排序到A和B的前面,如果C排到A和B的前面,那么程序的结果将会被改变。但A和B之间没有数据依赖关系,编译器和处理器可以重排序A和B之间的执行顺序。

hashmap 的 数据结构
- 在 JDK 1.7 版本之前, HashMap 数据结构是数组和链表,HashMap通过哈希算法将元素的键(Key)映射到数组中的槽位(Bucket)。如果多个键映射到同一个槽位,它们会以链表的形式存储在同一个槽位上,因为链表的查询时间是O(n),所以冲突很严重,一个索引上的链表非常长,效率就很低了。
- 所以在 JDK 1.8 版本的时候做了优化,当一个链表的长度超过8的时候就转换数据结构,不再使用链表存储,而是使用红黑树,查找时使用红黑树,时间复杂度O(log n),可以提高查询性能,但是在数量较少时,即数量小于6时,会将红黑树转换回链表。
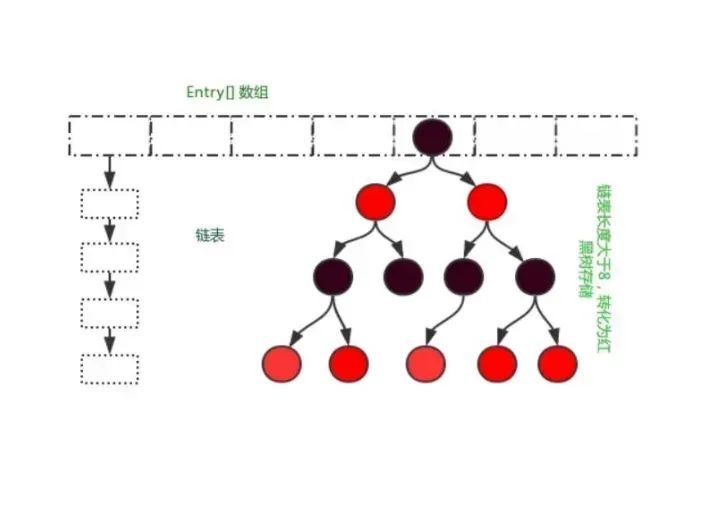
红黑树为什么好?怎么保持平衡的?
- 红黑树的增删查改的时间复杂度是Ologn,相比链表的时间复杂度On 高效很多,所以 hashmap 在哈希冲突链表比较长的情况下,会把链表转为红黑树。
- 红黑树主要通过旋转、变色等操作来保持树的平衡性。
jwt的缺点是什么?
JWT 一旦派发出去,在失效之前都是有效的,没办法即使撤销JWT。
要解决这个问题的话,得在业务层增加判断逻辑,比如增加黑名单机制。使用内存数据库比如 Redis 维护一个黑名单,如果想让某个 JWT 失效的话就直接将这个 JWT 加入到 黑名单 即可。然后,每次使用 JWT 进行请求的话都会先判断这个 JWT 是否存在于黑名单中。
tcp与udp区别
- 连接:TCP 是面向连接的传输层协议,传输数据前先要建立连接;UDP 是不需要连接,即刻传输数据。
- 服务对象:TCP 是一对一的两点服务,即一条连接只有两个端点。UDP 支持一对一、一对多、多对多的交互通信
- 可靠性:TCP 是可靠交付数据的,数据可以无差错、不丢失、不重复、按序到达。UDP 是尽最大努力交付,不保证可靠交付数据。但是我们可以基于 UDP 传输协议实现一个可靠的传输协议,比如 QUIC 协议
- 拥塞控制、流量控制:TCP 有拥塞控制和流量控制机制,保证数据传输的安全性。UDP 则没有,即使网络非常拥堵了,也不会影响 UDP 的发送速率。
- 首部开销:TCP 首部长度较长,会有一定的开销,首部在没有使用「选项」字段时是 20 个字节,如果使用了「选项」字段则会变长的。UDP 首部只有 8 个字节,并且是固定不变的,开销较小。
- 传输方式:TCP 是流式传输,没有边界,但保证顺序和可靠。UDP 是一个包一个包的发送,是有边界的,但可能会丢包和乱序。
- 应用场景:TCP 是面向连接,能保证数据的可靠性交付,因此经常用于:FTP、HTTP/HTTPS协议。UDP 面向无连接,它可以随时发送数据,再加上 UDP 本身的处理既简单又高效,经常用于视频、音频等多媒体通信等。
netty的架构原理是什么?
Netty主要基于主从Reactors多线程模型,做了一定的修改,其中主从Reactor多线程模型有多个Reactor:MainReactor和SubReactor:
- MainReactor负责客户端的连接请求,并将请求转交给SubReactor
- SubReactor负责相应通道的IO读写请求
- 非IO请求(具体逻辑处理)的任务则会直接写入队列,等待worker threads进行处理
这里引用Doug Lee大神的图:
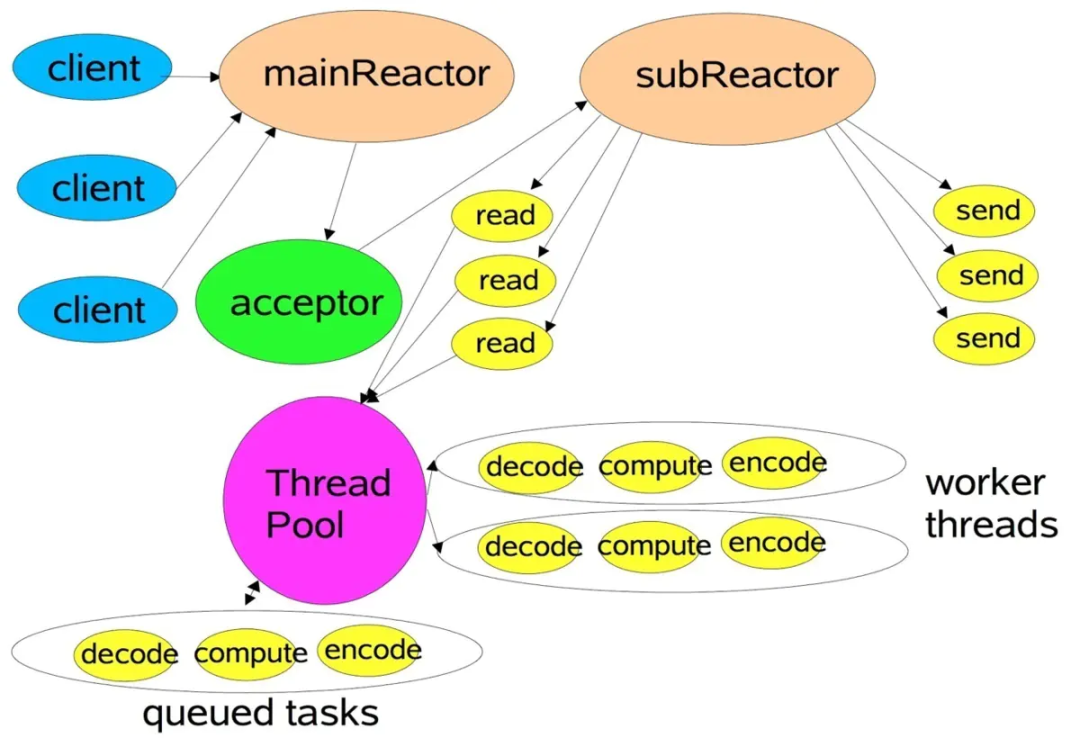
虽然Netty的线程模型基于主从Reactor多线程,借用了MainReactor和SubReactor的结构,但是实际实现上,SubReactor和Worker线程在同一个线程池中:
EventLoopGroup bossGroup = new NioEventLoopGroup();
EventLoopGroup workerGroup = new NioEventLoopGroup();
ServerBootstrap server = new ServerBootstrap();
server.group(bossGroup, workerGroup).channel(NioServerSocketChannel.class)
上面代码中的bossGroup 和workerGroup是Bootstrap构造方法中传入的两个对象,这两个group均是线程池。
- bossGroup线程池则只是在bind某个端口后,获得其中一个线程作为MainReactor,专门处理端口的accept事件,每个端口对应一个boss线程
- workerGroup线程池会被各个SubReactor和worker线程充分利用
服务端Netty的工作架构图:
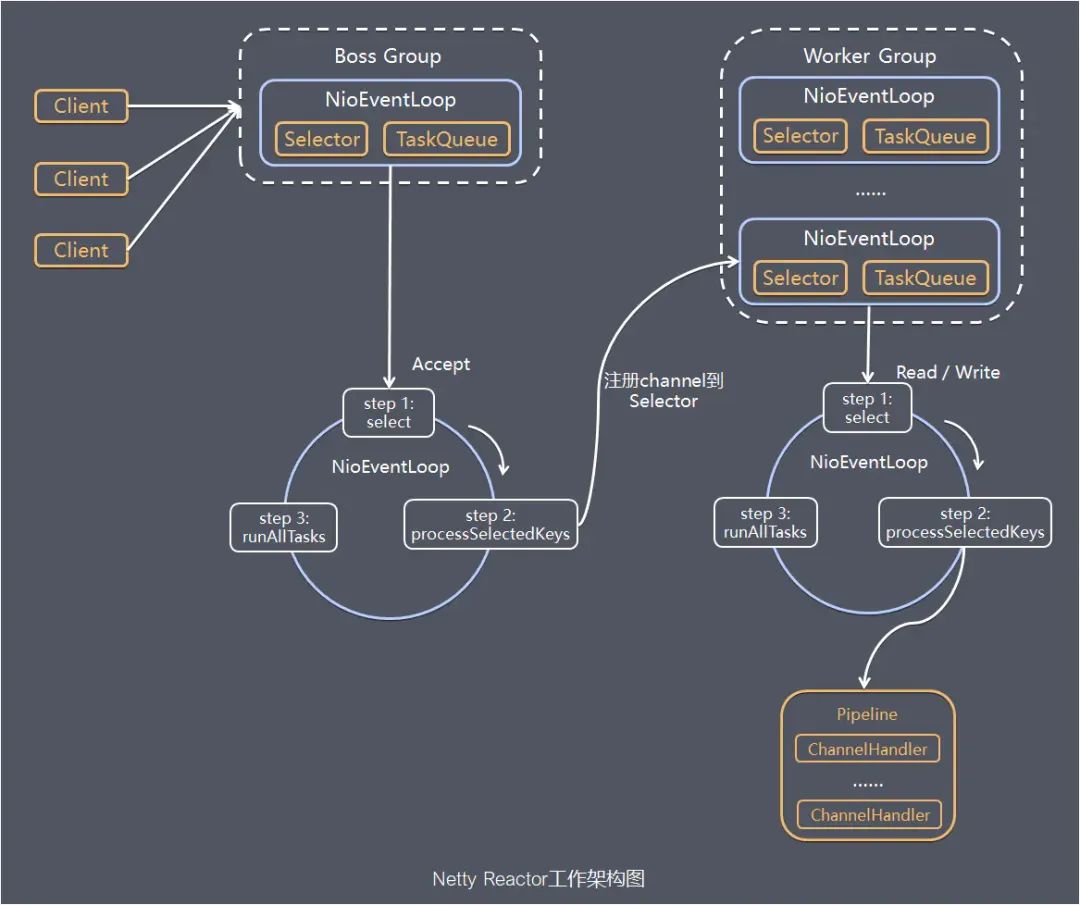
server端包含1个Boss NioEventLoopGroup和1个Worker NioEventLoopGroup,NioEventLoopGroup相当于1个事件循环组,这个组里包含多个事件循环NioEventLoop,每个NioEventLoop包含1个selector和1个事件循环线程。每个Boss NioEventLoop循环执行的任务包含3步:
- 1 轮询accept事件
- 2 处理accept I/O事件,与Client建立连接,生成NioSocketChannel,并将NioSocketChannel注册到某个Worker NioEventLoop的Selector上
- 3 处理任务队列中的任务,runAllTasks。任务队列中的任务包括用户调用eventloop.execute或schedule执行的任务,或者其它线程提交到该eventloop的任务
每个Worker NioEventLoop循环执行的任务包含3步:
- 1 轮询read、write事件
- 2 处理I/O事件,即read、write事件,在NioSocketChannel可读、可写事件发生时进行处理
- 3 处理任务队列中的任务,runAllTasks
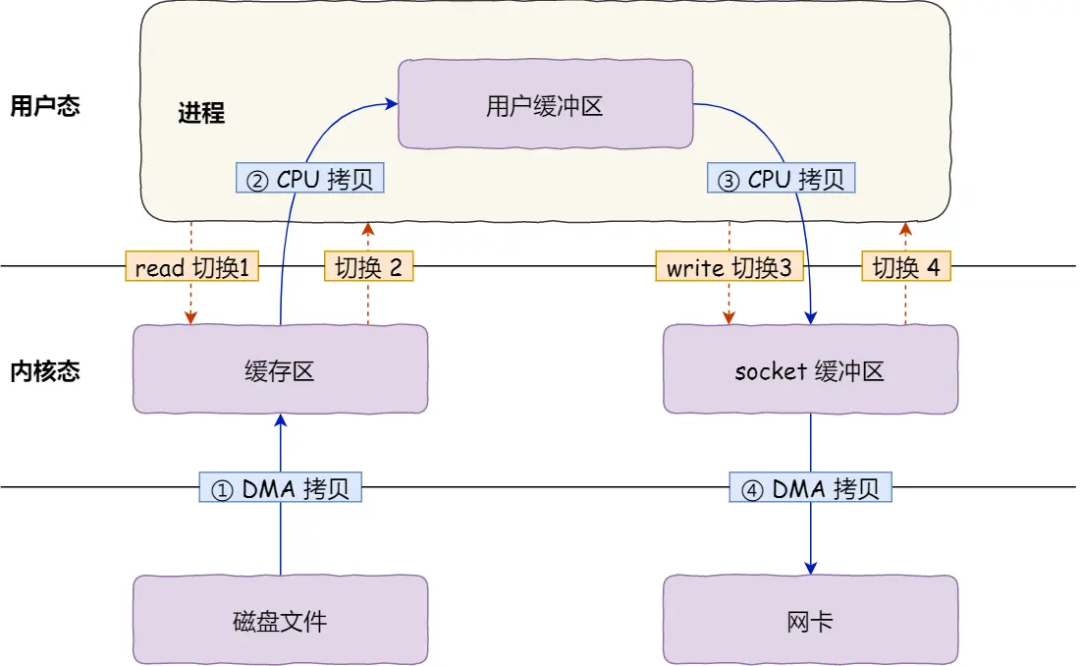
零拷贝是什么?
传统 IO 的工作方式,从硬盘读取数据,然后再通过网卡向外发送,我们需要进行 4 上下文切换,和 4 次数据拷贝,其中 2 次数据拷贝发生在内存里的缓冲区和对应的硬件设备之间,这个是由 DMA 完成,另外 2 次则发生在内核态和用户态之间,这个数据搬移工作是由 CPU 完成的。
为了提高文件传输的性能,于是就出现了零拷贝技术,它通过一次系统调用(sendfile 方法)合并了磁盘读取与网络发送两个操作,降低了上下文切换次数。另外,拷贝数据都是发生在内核中的,天然就降低了数据拷贝的次数。
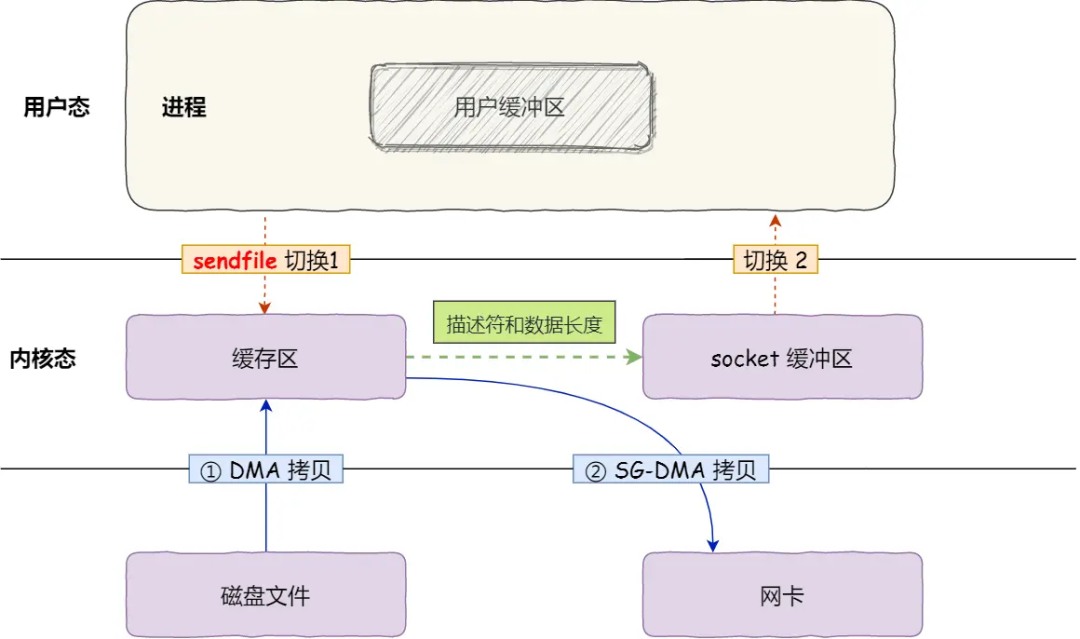
零拷贝技术的文件传输方式相比传统文件传输的方式,减少了 2 次上下文切换和数据拷贝次数,只需要 2 次上下文切换和数据拷贝次数,就可以完成文件的传输,而且 2 次的数据拷贝过程,都不需要通过 CPU,2 次都是由 DMA 来搬运。
总体来看,零拷贝技术可以把文件传输的性能提高至少一倍以上。
completableFuture怎么用的?
CompletableFuture是由Java 8引入的,在Java8之前我们一般通过Future实现异步。
- Future用于表示异步计算的结果,只能通过阻塞或者轮询的方式获取结果,而且不支持设置回调方法,Java 8之前若要设置回调一般会使用guava的ListenableFuture,回调的引入又会导致臭名昭著的回调地狱(下面的例子会通过ListenableFuture的使用来具体进行展示)。
- CompletableFuture对Future进行了扩展,可以通过设置回调的方式处理计算结果,同时也支持组合操作,支持进一步的编排,同时一定程度解决了回调地狱的问题。
下面将举例来说明,我们通过ListenableFuture、CompletableFuture来实现异步的差异。假设有三个操作step1、step2、step3存在依赖关系,其中step3的执行依赖step1和step2的结果。
Future(ListenableFuture)的实现(回调地狱)如下:
ExecutorService executor = Executors.newFixedThreadPool(5);
ListeningExecutorService guavaExecutor = MoreExecutors.listeningDecorator(executor);
ListenableFuture<String> future1 = guavaExecutor.submit(() -> {
//step 1
System.out.println("执行step 1");
return "step1 result";
});
ListenableFuture<String> future2 = guavaExecutor.submit(() -> {
//step 2
System.out.println("执行step 2");
return "step2 result";
});
ListenableFuture<List<String>> future1And2 = Futures.allAsList(future1, future2);
Futures.addCallback(future1And2, new FutureCallback<List<String>>() {
@Override
public void onSuccess(List<String> result) {
System.out.println(result);
ListenableFuture<String> future3 = guavaExecutor.submit(() -> {
System.out.println("执行step 3");
return "step3 result";
});
Futures.addCallback(future3, new FutureCallback<String>() {
@Override
public void onSuccess(String result) {
System.out.println(result);
}
@Override
public void onFailure(Throwable t) {
}
}, guavaExecutor);
}
@Override
public void onFailure(Throwable t) {
}}, guavaExecutor);
CompletableFuture的实现如下:
ExecutorService executor = Executors.newFixedThreadPool(5);
CompletableFuture<String> cf1 = CompletableFuture.supplyAsync(() -> {
System.out.println("执行step 1");
return "step1 result";
}, executor);
CompletableFuture<String> cf2 = CompletableFuture.supplyAsync(() -> {
System.out.println("执行step 2");
return "step2 result";
});
cf1.thenCombine(cf2, (result1, result2) -> {
System.out.println(result1 + " , " + result2);
System.out.println("执行step 3");
return "step3 result";
}).thenAccept(result3 -> System.out.println(result3));
显然,CompletableFuture的实现更为简洁,可读性更好。
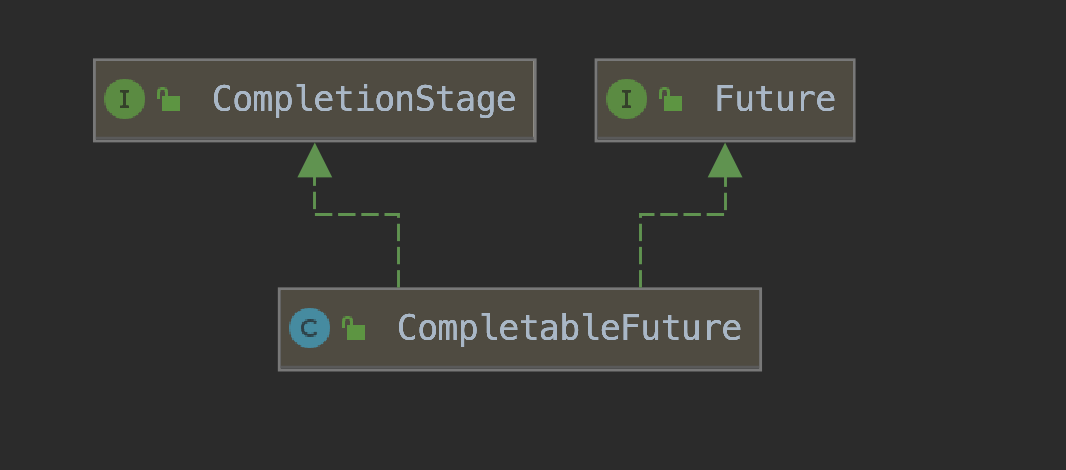
CompletableFuture实现了两个接口(如上图所示):Future、CompletionStage。
- Future表示异步计算的结果,CompletionStage用于表示异步执行过程中的一个步骤(Stage),这个步骤可能是由另外一个CompletionStage触发的,随着当前步骤的完成,也可能会触发其他一系列CompletionStage的执行。
- 从而我们可以根据实际业务对这些步骤进行多样化的编排组合,CompletionStage接口正是定义了这样的能力,我们可以通过其提供的thenAppy、thenCompose等函数式编程方法来组合编排这些步骤。
二级缓存怎么实现的?
使用 Spring Cache 相关的注解和接口来实现二级缓存的。
为什么用本地缓存?哪些场景适用?
我们知道关系数据库(Mysql)数据最终存储在磁盘上,如果每次都从数据库里去读取,会因为磁盘本身的IO影响读取速度,所以就有了像redis这种的内存缓存。
通过内存缓存确实能够很大程度的提高查询速度,但如果同一查询并发量非常的大,频繁的查询redis,也会有明显的网络IO上的消耗。
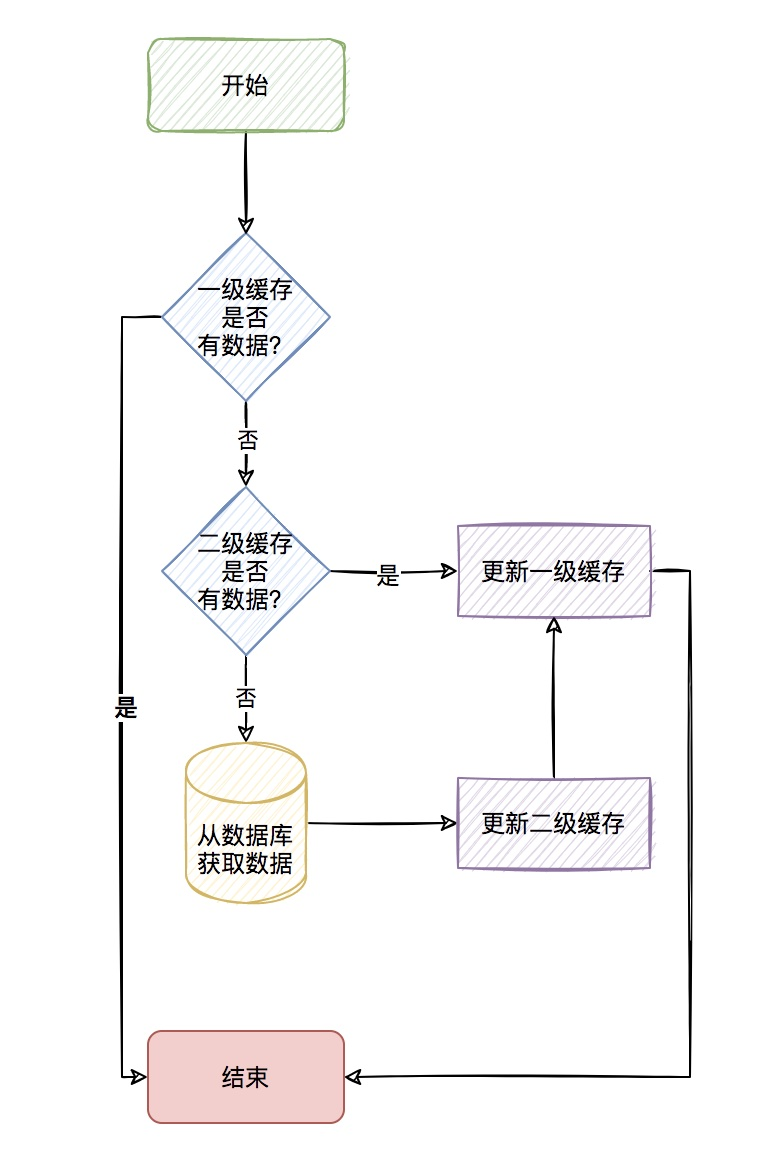
那我们针对这种查询非常频繁的数据(热点key),我们是不是可以考虑存到应用内缓存,如:caffeine。
当应用内缓存有符合条件的数据时,就可以直接使用,而不用通过网络到redis中去获取,这样就形成了两级缓存。
应用内缓存叫做一级缓存,远程缓存(如redis)叫做二级缓存。
整个流程如下:
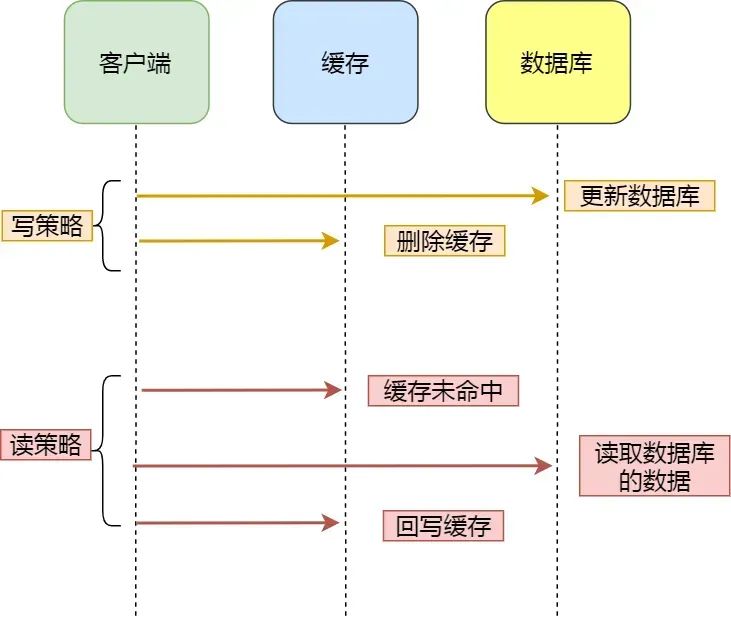
如何保持redis与数据库一致?
对于读数据,我会选择旁路缓存策略,如果 cache 不命中,会从 db 加载数据到 cache。对于写数据,我会选择更新 db 后,再删除缓存。
针对删除缓存异常的情况,我还会对 key 设置过期时间兜底,只要过期时间一到,过期的 key 就会被删除了。
除此之外,还有两种方式应对删除缓存失败的情况。
消息队列方案
我们可以引入消息队列,将第二个操作(删除缓存)要操作的数据加入到消息队列,由消费者来操作数据。
- 如果应用删除缓存失败,可以从消息队列中重新读取数据,然后再次删除缓存,这个就是重试机制。当然,如果重试超过的一定次数,还是没有成功,我们就需要向业务层发送报错信息了。
- 如果删除缓存成功,就要把数据从消息队列中移除,避免重复操作,否则就继续重试。
举个例子,来说明重试机制的过程。
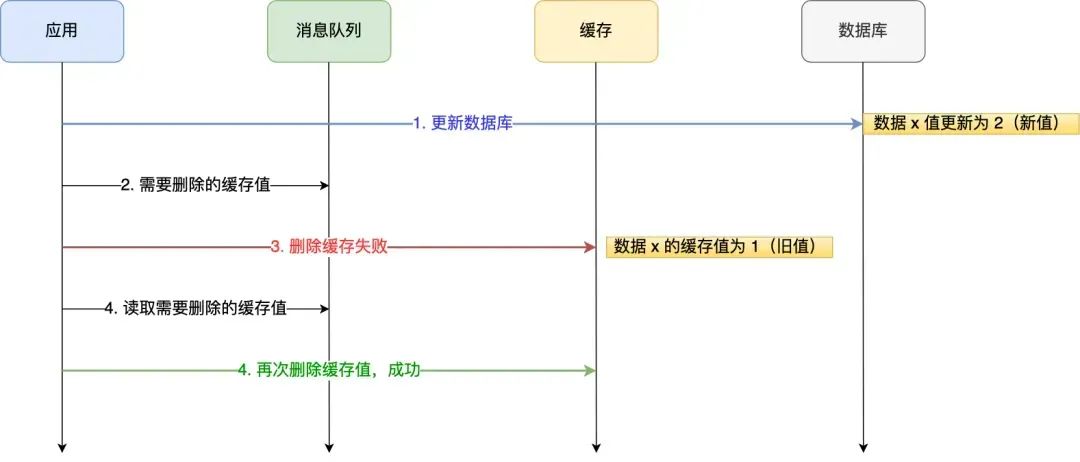
Canal+MQ
订阅 MySQL binlog,再操作缓存「先更新数据库,再删缓存」的策略的第一步是更新数据库,那么更新数据库成功,就会产生一条变更日志,记录在 binlog 里。
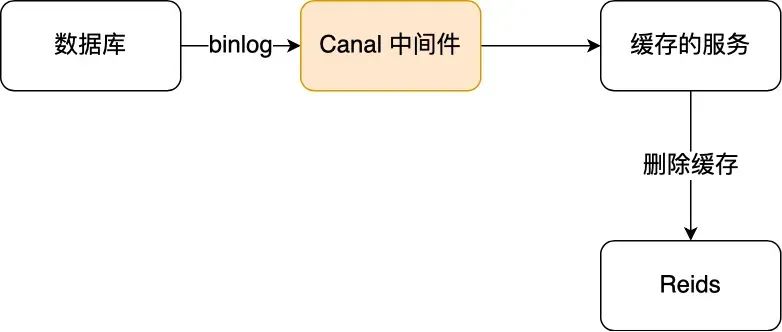
于是我们就可以通过订阅 binlog 日志,拿到具体要操作的数据,然后再执行缓存删除,阿里巴巴开源的 Canal 中间件就是基于这个实现的。
Canal 模拟 MySQL 主从复制的交互协议,把自己伪装成一个 MySQL 的从节点,向 MySQL 主节点发送 dump 请求,MySQL 收到请求后,就会开始推送 Binlog 给 Canal,Canal 解析 Binlog 字节流之后,转换为便于读取的结构化数据,供下游程序订阅使用。
下图是 Canal 的工作原理:
所以,如果要想保证「先更新数据库,再删缓存」策略第二个操作能执行成功,我们可以使用「消息队列来重试缓存的删除」,或者「订阅 MySQL binlog 再操作缓存」,这两种方法有一个共同的特点,都是采用异步操作缓存。
缓存穿透是什么,怎么解决?
当发生缓存雪崩或击穿时,数据库中还是保存了应用要访问的数据,一旦缓存恢复相对应的数据,就可以减轻数据库的压力,而缓存穿透就不一样了。
当用户访问的数据,既不在缓存中,也不在数据库中,导致请求在访问缓存时,发现缓存缺失,再去访问数据库时,发现数据库中也没有要访问的数据,没办法构建缓存数据,来服务后续的请求。那么当有大量这样的请求到来时,数据库的压力骤增,这就是缓存穿透的问题。
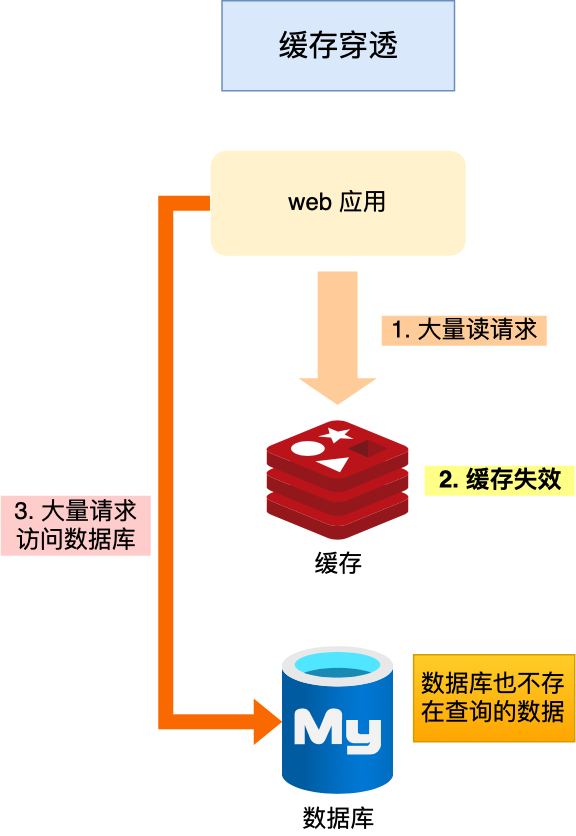
缓存穿透的发生一般有这两种情况:
- 业务误操作,缓存中的数据和数据库中的数据都被误删除了,所以导致缓存和数据库中都没有数据;
- 黑客恶意攻击,故意大量访问某些读取不存在数据的业务;
应对缓存穿透的方案,常见的方案有三种。
- 第一种方案,非法请求的限制;
- 第二种方案,缓存空值或者默认值;
- 第三种方案,使用布隆过滤器快速判断数据是否存在,避免通过查询数据库来判断数据是否存在;
第一种方案,非法请求的限制
当有大量恶意请求访问不存在的数据的时候,也会发生缓存穿透,因此在 API 入口处我们要判断求请求参数是否合理,请求参数是否含有非法值、请求字段是否存在,如果判断出是恶意请求就直接返回错误,避免进一步访问缓存和数据库。
第二种方案,缓存空值或者默认值
当我们线上业务发现缓存穿透的现象时,可以针对查询的数据,在缓存中设置一个空值或者默认值,这样后续请求就可以从缓存中读取到空值或者默认值,返回给应用,而不会继续查询数据库。
第三种方案,使用布隆过滤器快速判断数据是否存在,避免通过查询数据库来判断数据是否存在.
我们可以在写入数据库数据时,使用布隆过滤器做个标记,然后在用户请求到来时,业务线程确认缓存失效后,可以通过查询布隆过滤器快速判断数据是否存在,如果不存在,就不用通过查询数据库来判断数据是否存在。
即使发生了缓存穿透,大量请求只会查询 Redis 和布隆过滤器,而不会查询数据库,保证了数据库能正常运行,Redis 自身也是支持布隆过滤器的。
那问题来了,布隆过滤器是如何工作的呢?接下来,我介绍下。
布隆过滤器由「初始值都为 0 的位图数组」和「 N 个哈希函数」两部分组成。当我们在写入数据库数据时,在布隆过滤器里做个标记,这样下次查询数据是否在数据库时,只需要查询布隆过滤器,如果查询到数据没有被标记,说明不在数据库中。
布隆过滤器会通过 3 个操作完成标记:
- 第一步,使用 N 个哈希函数分别对数据做哈希计算,得到 N 个哈希值;
- 第二步,将第一步得到的 N 个哈希值对位图数组的长度取模,得到每个哈希值在位图数组的对应位置。
- 第三步,将每个哈希值在位图数组的对应位置的值设置为 1;
举个例子,假设有一个位图数组长度为 8,哈希函数 3 个的布隆过滤器。
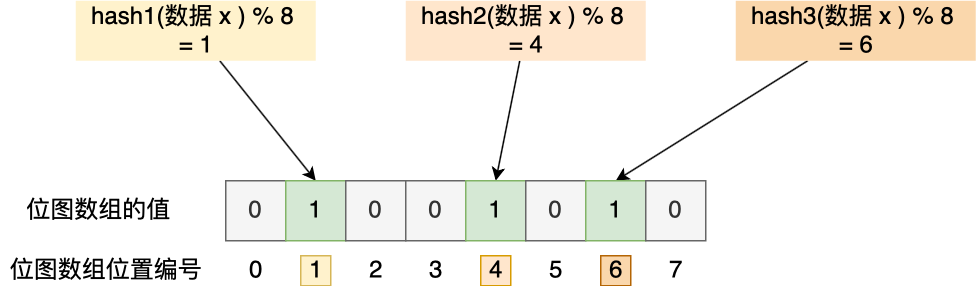
在数据库写入数据 x 后,把数据 x 标记在布隆过滤器时,数据 x 会被 3 个哈希函数分别计算出 3 个哈希值,然后在对这 3 个哈希值对 8 取模,假设取模的结果为 1、4、6,然后把位图数组的第 1、4、6 位置的值设置为 1。当应用要查询数据 x 是否数据库时,通过布隆过滤器只要查到位图数组的第 1、4、6 位置的值是否全为 1,只要有一个为 0,就认为数据 x 不在数据库中。
布隆过滤器由于是基于哈希函数实现查找的,高效查找的同时存在哈希冲突的可能性,比如数据 x 和数据 y 可能都落在第 1、4、6 位置,而事实上,可能数据库中并不存在数据 y,存在误判的情况。
所以,查询布隆过滤器说数据存在,并不一定证明数据库中存在这个数据,但是查询到数据不存在,数据库中一定就不存在这个数据。