PeLK:101 x 101 的超大卷积网络,同参数量下反超 ViT | CVPR 2024
原创PeLK:101 x 101 的超大卷积网络,同参数量下反超 ViT | CVPR 2024
原创
最近,有一些大型内核卷积网络的研究,但考虑到卷积的平方复杂度,扩大内核会带来大量的参数,继而引发严重的优化问题。受人类视觉的启发,论文提出了外围卷积,通过参数共享将卷积的复杂性从 $O(K^{2})$ 降低到 $O(\mathrm{log} K)$,有效减少 90% 以上的参数数量并设法将内核尺寸扩大到极限。在此基础上,论文提出了参数高效的大型内核网络(
PeLK),将CNN的内核大小扩展到前所未有的$101\times 101$,性能的也在持续提升。来源:晓飞的算法工程笔记 公众号
论文: PeLK: Parameter-efficient Large Kernel ConvNets with Peripheral Convolution

Introduction
? ViT的强大性能归因于其巨大的感受野,在自注意力机制的帮助下可以从大的空间范围捕获上下文信息并建模远程依赖关系。受此启发,CNN的最新进展表明,当配备大内核(例如 $31\times31$ )时,纯CNN架构在各种视觉任务上的表现可以与最先进的ViT相当甚至更好。
? 虽然大核卷积网络表现出强大的性能和吸引人的效率,但其相对于核大小 $K$ 的平方复杂度 ${O}(K^{2})$ 会带来大量的参数。例如,$31\times31$ 内核的参数比 $3\times3$ 内核的参数大 100 倍以上。为了解决这一问题:
RepLKNet将大内核重参数化为并行的 $5\times 5$ 内核,从而弥补优化问题。SLaK妥协地使用条带卷积将复杂度降低为线性,并扩展到 $51\,\times\,51$(即 $51\times 5$ 和 $5\times 51$)。
? 然而,这对于下游任务的分辨率来说仍然是有限的交互范围(例如ADE20K上的 $2048\times 512$)。此外,条带卷积缺乏密集卷积的范围感知,可能会破坏模型的空间感知能力。
? 论文先在统一的现代框架(即SLaK)下对卷积形式进行了全面的剖析,验证了密集网格卷积在不同内核大小下均优于条带卷积的猜想。这种现象不仅适用于分类任务,而且适用于下游任务,这表明密集卷积相对于条带形式的本质优势。然而,大密集卷积的平方复杂度导致参数激增阻碍其进一步缩放,是个亟需解决的问题。
? 与卷积或自注意力的密集计算不同,人类视觉拥有更高效的视觉处理机制,称为周边视觉。具体来说,人类视觉根据到注视中心的距离将整个视野分为中心区域和周边区域,并且中心区域的感光细胞数量是周边区域的100倍以上。这样的生理结构赋予了人类视觉具有模糊感知的特点:中心区域感知力强,看得很清楚,能识别形状和颜色;而在外围区域,视野变得模糊,分辨率降低,只能识别抽象的视觉特征,例如运动和高级上下文。这种机制使人类能够仅通过一小部分视野($<5 \%$)即可感知重要细节,同时最大限度地减少剩余部分($>95\%$)中不必要的信息,从而促进人脑的高效视觉处理。
? 受人类视觉的启发,论文提出一种新颖的外围卷积,将卷积的参数复杂度从 $O(K^{2})$ 降低到 $O(\mathrm{log} K)$,同时保持密集的计算形式。外围卷积由三种设计组成:
- 聚焦和模糊机制。在卷积核的中心区域保留细粒度的独立参数,在外围区域则使用大范围的共享参数。
- 呈指数级增加的共享粒度。共享网格以指数级增长的方式增长,这比固定粒度更有效。
- 内核级位置嵌入。引入内核级位置嵌入,以优雅且廉价的方式解决因大范围的外围共享而导致的细节模糊问题。
? 基于外围卷积,论文提出了参数高效的纯CNN大型内核网络(PeLK),其有效感受野(ERF)与参数量呈指数增长。在精心设计的参数共享机制的帮助下,PeLK以非常小的参数成本扩展了内核大小,实现了极大的密集内核(例如 $51\times 51$,$101\times 101$),并具有持续的改进。PeLK在各种视觉任务中实现了最先进的性能,在配备极大的内核尺寸时展示了纯CNN架构的潜力。
? PeLK被证明能够覆盖比之前的大型内核模型更大的ERF区域,这是其强大的性能所在。更有趣的是,论文的实验分析和消融实验表明,外围卷积的最佳设计原理与人类视觉具有惊人的相似性,这表明受生物学启发的机制可以成为设计强大的现代网络的有希望的候选者。
Dense Outperforms Stripe Consistently
? 论文通过SLaK和RepLKNet研究密集网格卷积是否比条纹卷积更好,先在ImageNet训练得到预训练模型,然后将预训练模型作为UperNet的主干网络在ADE20K上进行训练和对比。
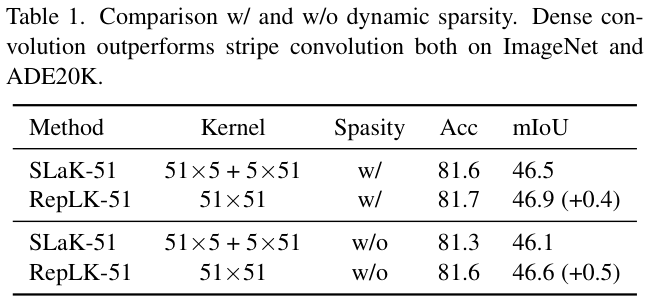
? SLaK通过两个步骤将内核扩大到 $51\times 51$:1) 将大内核分解为两个并行的矩形内核;2)使用动态稀疏性并扩大网络宽度。为了彻底分析卷积形式的效果,论文进行了带稀疏性和不带稀疏性的实验。默认情况下,像SLaK和RepLKNet所采取的方法,重参数化 $5\times 5$ 卷积来缓解优化问题。表 1 的结果表明,无论动态稀疏性如何,密集网格卷积都超过了条带卷积。
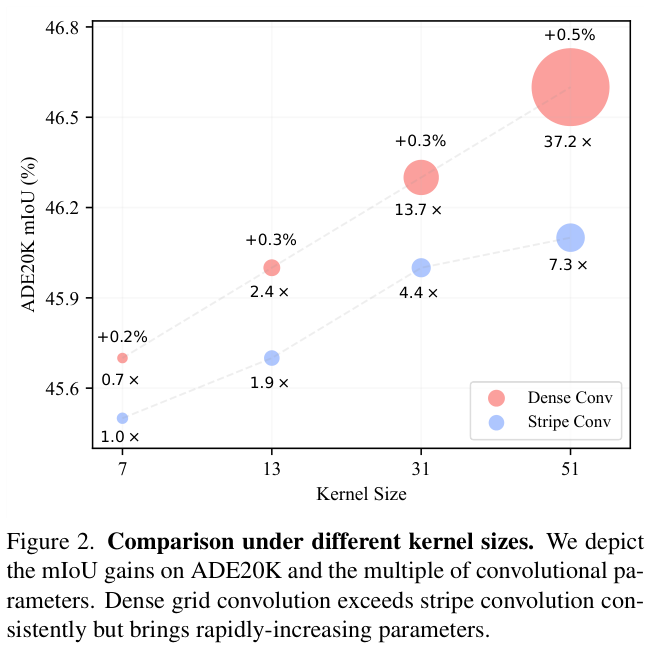
? 论文进一步探索不同内核大小下的卷积形式(即 $K \times K$ 与 $K\times N$),将SLaK的条带卷积的短边固定为 5 作为默认设置($N=5$),然后逐渐将 $K$ 从 51 减少到 7。期间不使用动态稀疏性,方便对卷积形式进行纯粹的对比。如图 2 所示,密集网格卷积在多个内核尺寸下始终优于条带卷积,并且增益随着内核尺寸的增加而增加,这表明密集网格大内核卷积的本质优势。
? 但是,密集网格卷积的平方复杂度会导致参数量激增。如图 2 所示,条带卷积的内核从 7 放大到 51 只会带来 $7.3\times$ 参数,而密集卷积则为 $53.1\times$。考虑到人类的周边视觉中外围区域只有少量的感光细胞,论文认为密集参数对于外围区域的相互作用不是必需的。受此启发,论文寻求通过引入周边视觉机制来降低参数复杂度,同时保留密集计算以保持密集卷积的强大性能。
Parameter-efficient Large Kernel Network
Peripheral Convolution
? 标准的2D卷积核由4D向量组成:$w \in \mathbb{R}^{c\mathrm{in}\times c{\mathrm{out}}\times\mathrm{k}\times\mathrm{k}}$,其中 $c{\mathrm{in}}$ 为输入通道数,$c{\mathrm{out}}$ 为输出通道数,$\mathrm{k}$ 为空间核维度。论文通过空间参数共享来将 $w$ 参数化为更小的内核 $w{\theta} \in \mathbb{R}^{C\mathrm{in}\times c_{\mathrm{out}}\times\mathrm{k}^{\prime}\times\mathrm{k}^{\prime}}$,其中 $0<\mathrm{k}^{\prime}\le\mathrm{k}$。
? 首先,定义共享网格 $S=s{0},s{1},\ldots,s_{\mathbf{k^{\prime}-1}}$,其中 $\sum_{i=0}^{k^{\prime} -1} s_i=k$。根据 $S$,将 $k\times k$ 位置划分为 $k^{\prime}\times k^{\prime}$区域:
$$
\begin{array}{c}
{{\mathrm{for~}a,b=0,1,\ldots,k^{\prime}-1,}}
\
{{Z{a,b}={(x,y)|\sum{i=0}^{a-1}s{i}<\sum{i=0}^{a}s{i},\sum{j=0}^{b-1}s{j}\le y<\sum{j=0}^{b}s_{j}}}}
\end{array}
\quad\quad(1)
$$
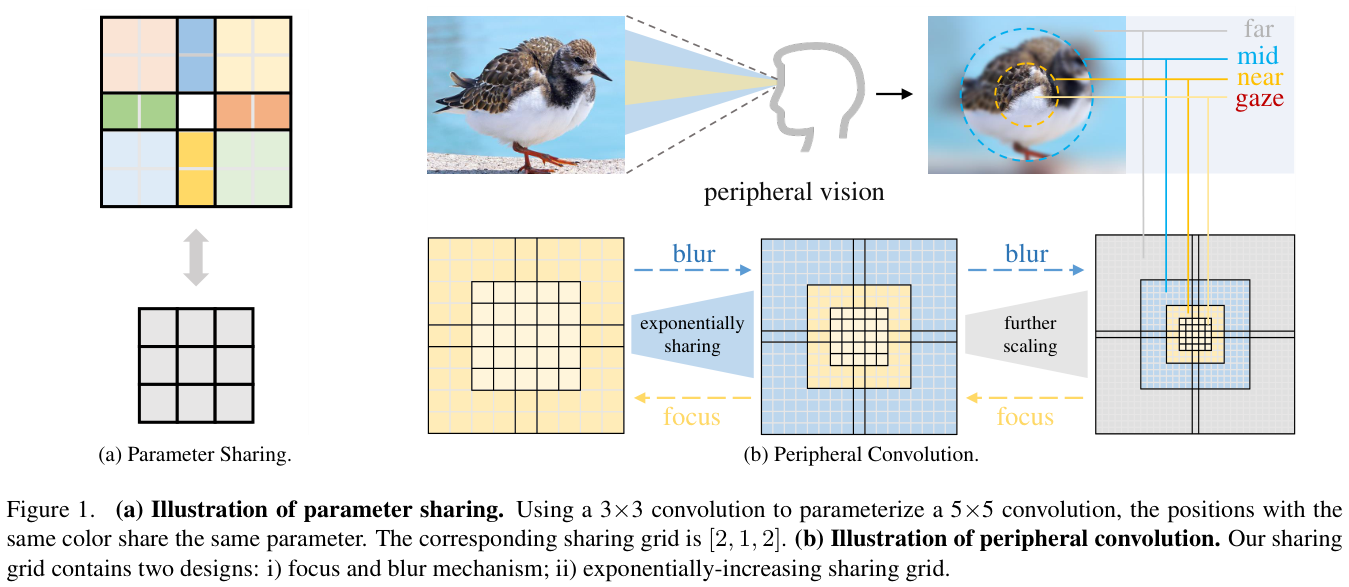
? 为了简洁起见,规定 $\sum{i=0}^{-1}s{i}=0$。对于任意位置 $(x,y)\in Z{a,b}$,设置 $w(x,y)=w\theta(a,b)$。这样就可以利用一个小核来参数化一个大核,实现空间上的参数共享,如图 1a 所示。
? 接下来进行下一步升级,将共享网格重新表示为轴对称形式:$S = \bar{s}{?r}, \bar{s}{?r+1},\cdots,\bar{s}{-1},\bar{s}{0},\bar{s}{1},\cdots,\bar{s}{r-1},\bar{s}_{r}$,其中 $r=\frac{{k}^{\prime}-1}{2}$,为 $w_{\theta}$ 的核半径。
? 类似于人类的周边视觉,共享网格主要由两个核心设计组成:
- 聚焦和模糊机制。如图 1b 所示,将细粒度参数保留在卷积核的中心区域,其对应共享网格设置为 1 (即不共享)。对于外围区域,利用大范围参数共享来探索外围视觉的空间冗余。
- 呈指数级增加的共享粒度。受人类视觉的启发,论文设计了以指数级的方式增长的共享网格。这种设计可以优雅地将卷积的参数复杂度从 $O(K^{2})$ 降低到 $O(\log K)$,从而可以进一步扩大密集卷积的内核大小。具体来说,共享网格 $S$ 的构造如下:
$$
\bar{s}_{i}
=
\begin{cases}{{{1},}}&{{\mathrm{if}\ \ \vert i\vert\le\ r{c}}}\ {{{m}^{(\vert i\vert-r{c})},}}&{{\mathrm{if}\ \ r_{c}\lt\vert i\vert\le\ r}}\end{cases}
\quad\quad(2)
$$
? 其中 $r_{c}$ 是中心细粒度区域的半径,$m$ 是指数增长的基数,默认设置为 2。
Kernel-wise Positional Embedding
? 尽管外围卷积能够有效地减少密集卷积的参数,但大范围的参数共享可能导致外围区域的局部细节模糊。尤其当内核大小以外围卷积的形式放大到 50 以上甚至 100 以上时,这种现象会进一步放大,单个参数需要处理 $8\times8$ 甚至 $16\times16$ 外围区域。
? 为了解决这个问题,论文提出了基于内核的位置嵌入。给定一组输入特征 $X$,通过权值为 $w \in \mathbb{R}^{c{in}\times c{out}\times k\times k}$ 的卷积来处理这些特征。使用trunc normal来初始化位置嵌入 $h \in \mathbb{R}^{c_{in}\times k\times k}$。
? 输出位置 $(x,y)$ 处的卷积计算为:
$$
Y(x,y)=\sum{i=-r{\mathrm{w}}}^{r{\mathrm{w}}}\sum{j=-r{\mathrm{w}}}^{r{\mathrm{w}}}\mathrm{w}(i,j)\cdot\left(X(x+i,y+j)+\mathrm{h}(i,j)\right)
\quad\quad(3)
$$
? 其中 $Y$ 是输出,$r{w}$ 是内核 $w$ 的半径,设置为 $r{w}=\frac{k-1}{2}$。
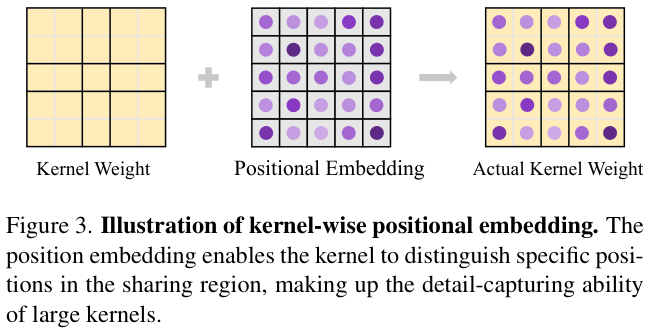
? 如图 3 所示,通过引入位置嵌入,可以区分共享区域中的特定位置,从而弥补共享带来的局部细节模糊的问题。实际上,这可以被视为向输入特征添加相对位置信息的偏置。值得注意的是,同一个阶段中的所有内核共享相同的位置嵌入 $h$,因此 $h$ 带来的额外参数可以忽略不计。这种设计以一种廉价而优雅的方式解决了由于共享权重而导致的位置不敏感问题,特别是对于非常大的内核。
Partial Peripheral Convolution
? 大型内核卷积网络已被证明具有高度通道冗余性,非常适合进行稀疏化。外围卷积使得论文能够设计具有更强空间感知能力的大型密集卷积,因此可以进一步优化大卷积的通道冗余。
? 论文引入了一种Inception风格的设计,其中只有特征图的部分通道将通过卷积进行处理。整体设计遵循一个简单的理念:更多的恒等映射来优化通道冗余。具体来说,对于输入 $X$,沿着通道维度将其分为两组,
$$
\begin{align}
X{\mathrm{conv}},X{\mathrm{id}} &= \mathrm{Split}(X) \notag
\
&= X{:,:,:g},X{:,:,g:} \notag
\end{align}
\quad\quad(4)
$$
? 其中 $g$ 是卷积分支的通道数,默认设置为 $\frac{3}{8}C_{in}$。然后将分割后的输入分别输入外围卷积和恒等映射:
$$
\begin{align}
X^{\prime}{\mathrm{conv}} &= \mathrm{Periphera\ Conv}(X{\mathrm{conv}}) \notag
\
X^{\prime}{\mathrm{id}} &= X{\mathrm{id}} \notag
\end{align}
\quad\quad(5)
$$
? 最后,将两个分支的输出连接起来以恢复原始形状:
$$
X^{\prime}=\mathrm{Concat}(X^{\prime}{\mathrm{conv}},X^{\prime}{\mathrm{id}}).
\quad\quad(6)
$$
? 这种设计可以看作是Inception类型结构的特例,如Inception、Shufflenet和InceptionNeXt。他们在并行分支中使用不同的运算符,而论文采用更简单的设计:仅外围卷积和恒等映射。这种设计非常适合具有极大内核的外围卷积,可显著减少FLOP而不会产生降低性能。
Architecture Specification
? 基于上述设计和观察,论文设计了参数高效的大型内核网络(PeLK)的架构,按照ConvNeXt和SLaK来构建多种尺寸的模型:
- 采用了 4 阶段的框架。
- stem 包含一个 $4\times 4$ 内核和 4 步幅的卷积层。
- 对于
tiny和small/base大小的模型,各阶段的块数量是分别为 $3,3,9,3$ 和 $3,3,27,3$。 - 不同阶段的内核大小默认为 $51,49,47,13$。对于
PeLK-101,内核大小放大至 $101,69,67,13$。 - 默认情况下,保持中心 $5\times 5$ 区域作为细粒度。对于
PeLK-101,中心区域则放大到 $7\times 7$。 - 遵循
SLaK的设计,使用动态稀疏性来增强模型容量,所有超参数设置相同($1.3\times$ 网络宽度,40% 稀疏度)。
Experiments
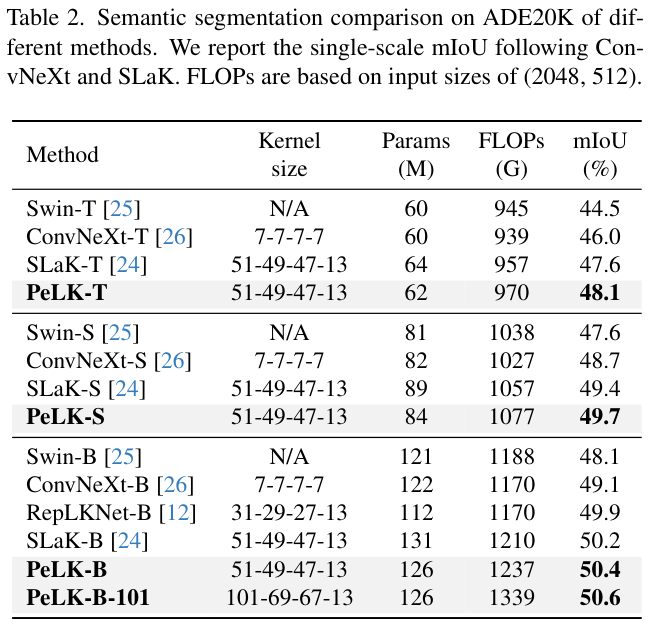
? 对于语义分割,在ADE20K上评估PeLK作为主干网络的效果。
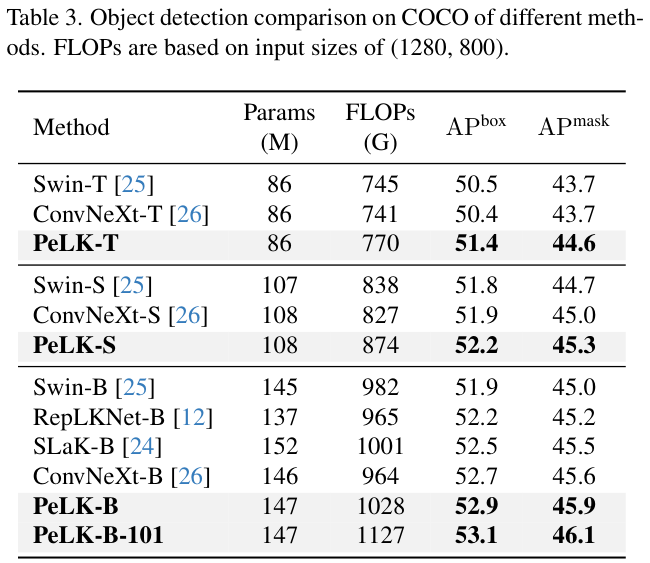
? 对于目标检测/分割,在MS-COCO上使用Cascade Mask R-CNN进行实验。
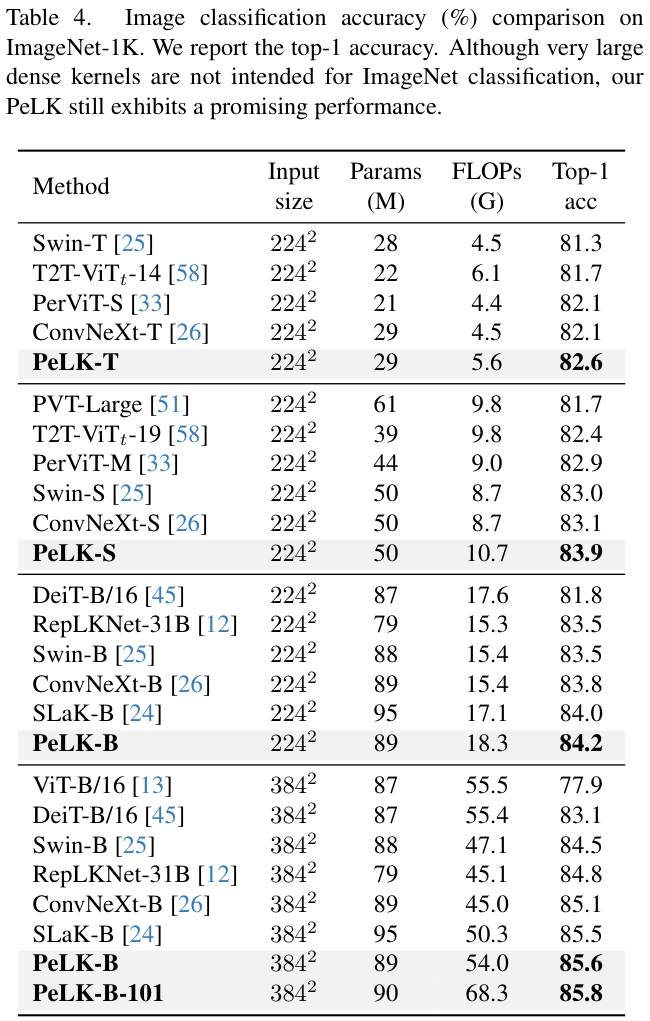
? 对于图像分类,在ImageNet-1K上进行对比。

? 表 5 展示不同共享粒度的性能对比。由于网格是轴对称的,表格中仅表示半个网格。
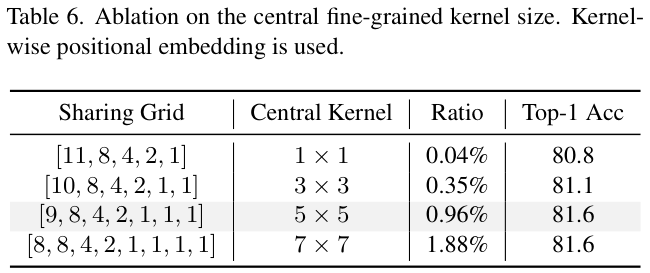
? 表 6 展示了不同中心细粒度内核大小的性能对比。
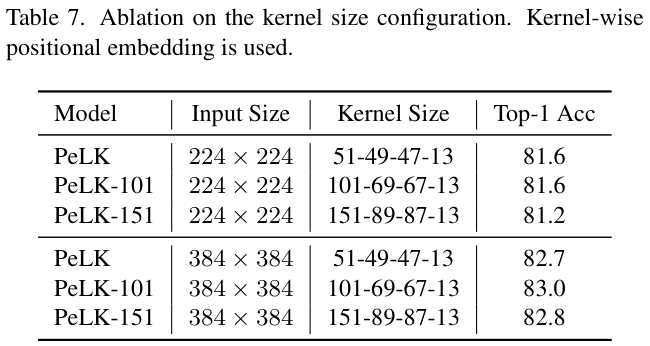
? 表 7 展示了不同内核大小配置的性能对比。

? 图 4 展示不同模型最后一层对输入图片的感受野对比。

? 图 5 中对语义分割中使用的PeLK-T架构的FLOP进行详细的分类。

? 表 8 中比较了推理吞吐量。
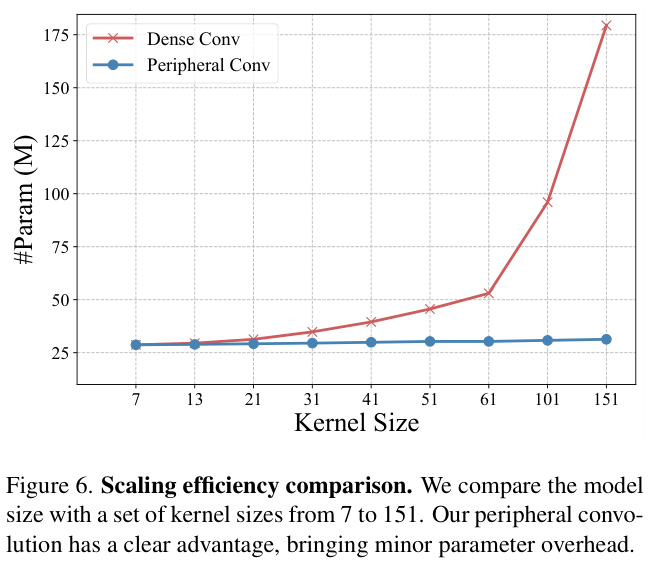
? 图 6 展示了内核缩放对模型参数量的影响。
如果本文对你有帮助,麻烦点个赞或在看呗~?developer/article/2411882/undefined更多内容请关注 微信公众号【晓飞的算法工程笔记】
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。