WanJuan-CC数据集:为大型语言模型训练提供高质量Webtext资源
WanJuan-CC数据集:为大型语言模型训练提供高质量Webtext资源

Datawhale干货
作者:虹桥北北
如何在参差不齐的海量网页数据中提炼高质量内容?如何保证模型训练数据的质量和安全性,如何构建高效的处理策略?上海人工智能实验室的这篇论文提供了一种不错的参考方案。
众多大语言模型成果表明,基于大规模数据预训练,即使在无需标注数据微调的情况下,也能在各类NLP任务中展现出优异的性能。
根据大模型的训练过程中,最优模型参数量、训练数据量和总计算开销之间所存在的 规模定律(Scaling Law) 来看,要训练出更强大的模型,需要更多的模型参数量和更大的预训练数据。有研究显示,训练一个拥有175B参数量的语言模型大约需要3.7TTokens的高质量预训练数据。然而,传统的从特定数据源收集并进行定制清洗的数据方案已经无法满足这种规模的数据需求,这对预训练数据集的构建工作提出了新的挑战。
为此,上海人工智能实验室OpenDataLab团队设计了一套针对CommonCrawl网页数据的处理流程,包括数据提取、启发式规则过滤、模糊去重、内容安全过滤以及数据质量过滤等多个步骤,可实现高效生产 内容安全 与 高质量数据 两大核心目标。
通过这一流程,他们从CommonCrawl中高效获取了一个1.0T Tokens的高质量英文网络文本数据集——WanJuan-CC。结果显示,与各类开源英文CC语料在PerspectiveAPI不同维度的评估上,WanJuan-CC都表现出更高的安全性。此外,通过在4个验证集上的困惑度(PPL)和6个下游任务的准确率,也展示了WanJuan-CC的实用性。
WanJuan-CC在各种验证集上的PPL表现出竞争力,特别是在要求更高语言流畅性的tiny-storys等数据集上。通过与同类型数据集进行1B模型训练对比,使用验证数据集的困惑度(perplexity)和下游任务的准确率作为评估指标,实验证明,WanJuan-CC显著提升了英文文本补全和通用英文能力任务的性能。

论文链接:https://arxiv.org/abs/2402.19282
数据集下载链接:https://opendatalab.com/OpenDataLab/WanJuanCC
根据论文显示,日前作者从WanJuan-CC中抽取了100B Tokens的开源数据,为其他大型模型的训练提供了宝贵的数据资源,节省了数据成本。与此同时,他们也在数据集中加入了包含数据质量的统计信息,并发布了一篇详细介绍数据处理方法的相关论文,以便开发者可以根据自身需求选择恰当的数据和处理策略。这为大模型的数据处理提供了实用的参考方案。

1. 背景知识
CommonCrawl(CC)作为一个开放的互联网网页的超大规模数据库,收录自2008年以来的历史公开数据,是目前主流大模型预训练数据的重要来源,但由于其原始数据规模庞大、格式复杂、存在大量低质量数据以及可能含有色情、毒性、个人隐私等不安全内容,在数据抽取、清洗过滤、质量提升和价值观对齐等方面存在诸多挑战。
以往的公开数据集中,有些直接使用了CommonCrawl数据库,或者采用了基于CommonCrawl的OSCAR数据集,例如RefinedWeb、Redpajama以及Dolma等。从数据集大小、CC dumps数量,以及数据集的安全性、个人隐私保护和数据质量筛选方法等多个维度来看,WanJuan-CC与其他基于CommonCrawl处理的数据集相比,具有以下特点:
- 与RefinedWeb是唯二覆盖了超过90个CC dumps的数据;
- 除了常用的基于关键词和URL的屏蔽之外,还使用了基于模型的方法来排除含有毒性(toxic)和色情(prongraphy)内容的数据,并利用正则表达式来遮蔽个人隐私信息(PII);
- 特别采用了基于模型的质量筛选方法,筛选出了相对高质量的数据;
- 是唯一一个能够完全覆盖毒性、色情和个人隐私三个方面的内容安全措施的公开数据集。
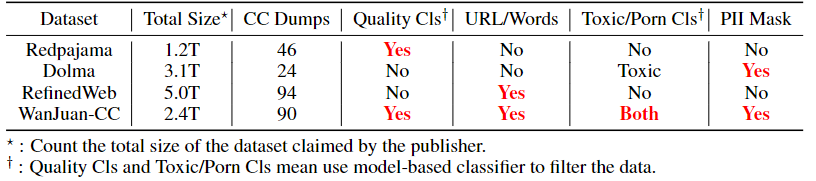
WanJuan-CC与开源英文CC语料多维度对比
2. 高性能分布式数据处理框架
OpenDataLab团队搭建的数据处理流程如图所示。

WanJuan-CC数据处理工作流
有以下5个核心步骤:
- 从CommonCrawl的WARC格式数据中提取文本,得到"原始数据"(Rawdata)。
- 通过启发式规则对原始数据进行过滤,生成"清洗数据"(Cleandata)。
- 利用基于LSH的去重方法对清洗数据进行处理,得到"无重复数据"(Dedupdata)。
- 使用基于关键词和域名列表的过滤方法,以及基于Bert的有害内容分类器和淫秽内容分类器对无重复数据进行过滤,产生"安全数据"(Safedata)。
- 采用基于Bert的广告分类器和流畅性分类器对安全数据进行进一步过滤,得到"高质量数据"(High-Qualitydata)。
详细每一步的具体实现可见论文:https://arxiv.org/abs/2402.19282
3. WanJuan-CC数据处理结果
3.1 文档留存率
在CommonCrawl中抽取了约1,300亿份原始数据文档,基于高性能数据处理工作流得到了9.71TB(35.8亿个文档)安全数据,并根据质量排序精选出4.45TB(17.8亿个文档)最高质量的数据作为WanJuan-CC数据集,占原始数据的1.38%。
如下图所示的是WanJuan-CC处理中,以处理的文档数(即CommonCrawl的网页数)为维度统计的每个阶段相对上一阶段的去除率,以及相对初始网页数的保留率。
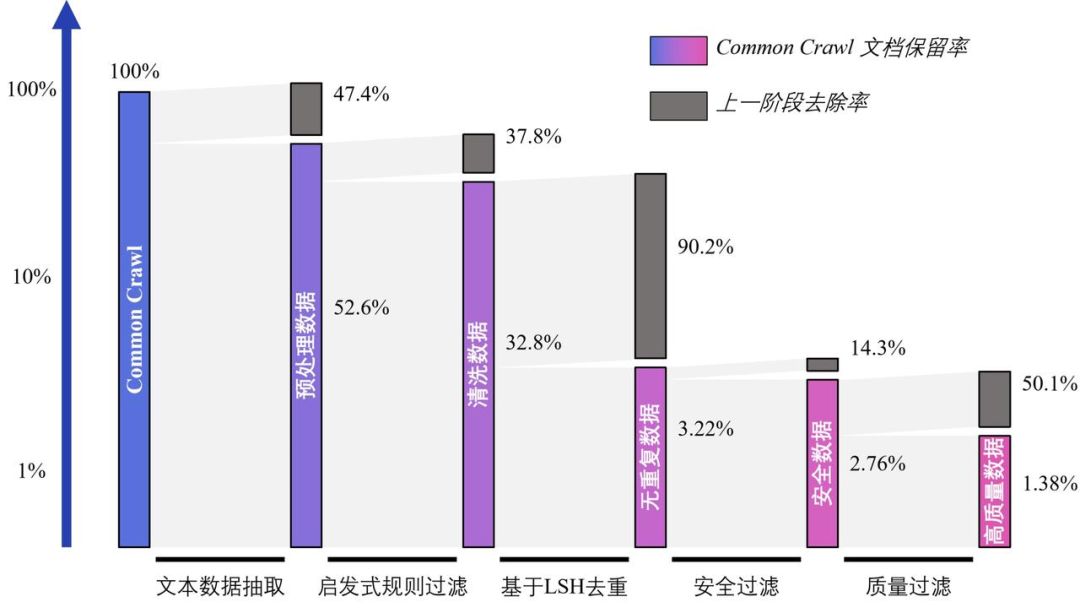
各清洗阶段的文档保留率和去除率(注意:使用的是对数坐标轴)
3.2 不同指标的分布
参考了Redpajama-v2中的一些数据质量指标对WanJuan-CC进行了统计。统计了数据集的文档长度,行数,token长度,非字母字符占比,唯一词占比,平均词长,句子数,停用词占比,符号占词比。每个指标的分布如下图所示:

WanJuan-CC上各指标百分比统计图。为了绘制出分布的主要区域,部分指标的统计范围被截断由于存在长尾分布。
3.3 数据毒性检测
对Wanjuan-CC、Redpajama和RefinedWeb数据集分别抽样100K条数据,使用PerspectiveAPI对7个安全维度进行评分,并根据得分绘制不安全性分布曲线,通过计算曲线下面积作为不安全性的度量指标。由下表结果可看出,Wanjuan-CC在各个维度上的不安全性最低,表明其具有更高的安全性。
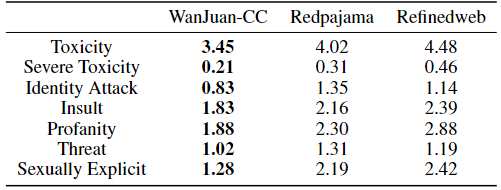
WanJuan-CC与开源英文CC语料安全性对比
3.4 模型评测结果
为了进一步验证数据的质量,作者使用相同的自回归decoder-onlyTransformer模型,分别使用WanJuan-CC和RefinedWeb从零开始训练。分别在1B参数和3B参数的水平上进行了实验,其中1B模型使用了100Btokens而3B模型使用了200Btokens。
对于1B模型采用计算验证数据集上平均PPL作为评价指标。这是由于小参数量模型很难观测到下游任务的指标变化,因此采用使用验证集的ppl指标会更容易度量小模型的训练效果。作者使用了来自Pile的三个子集pile-books3,pile-openwebtext2,pile-wikipedia-en,以及来自Tiny-stroys的tiny-storys共四个验证集。
实验结果如下表所示,WanJuan-CC在pile-books3,pile-openwebtext2以及pile-wikipedia-en上的ppl都比RefinedWeb略低,而在tiny-storys上的ppl则比RefinedWeb显著低。表明WanJuan-CC的数据质量略优于RefinedWeb,尤其在tiny-storys这种对语言流畅性要求较高的验证集上效果更加明显。

不同验证集上WanJuan-CC与Refinedweb模型的困惑度
而对于较大参数量的模型,下游任务的准确率可以更好地反映数据的质量。作者选择了三大类下游任务:英文文本补全(LAMBADA,StoryCloze),英文通用能力(SuperGLUE),英文常识问答(HellaSwag,PIQA,WinoGrande)共六个下游任务任务进行评测。
实验结果如表所示。实验结果表明WanJuan-CC在英文文本补全和英文通用能力上有明显提升,而在英文常识问答中HellaSwag有下降,PIQA上有轻微下降,WinoGrande上明显提升。综合来看,WanJuan-CC在下游任务上的表现优于RefinedWeb。

WanJuan-CC与Refinedweb模型在不同下游任务上的准确性
WanJuan-CC作为书生·浦语2.0(InternLM2)大模型的关键语料,其文本质量和高信息密度所带来的效果也经过了模型的有效验证,在仅使用约60%的训练数据即可达到使用第二代数据训练1Ttokens的性能表现,大幅提升模型训练效率,并在相同语料规模上取得了更好的模型性能提升。

WanJuan-CC所使用的数据处理技术可大幅提升数据质量和模型训练效率
4. 总结
总结来说,WanJuan-CC为大规模语言模型训练领域做出了重要贡献。它为研究人员和实践者提供了一个安全、高质量、开源的数据集。未来的工作可以集中在进一步优化数据处理流水线以提高数据质量和安全性,并探索该数据集在更多样化的自然语言处理任务中的应用。