掌握时间序列特征工程:常用特征总结与 Feature-engine 的应用
掌握时间序列特征工程:常用特征总结与 Feature-engine 的应用

时间序列数据的特征工程是一种技术,用于从时间序列数据中提取信息或构造特征,这些特征可用于提高机器学习模型的性能。以下是一些常见的时间序列特征工程技术:
- 滚动统计量:计算时间窗口内的统计量,如平均值、中位数、标准偏差、最小值和最大值。这些统计量可以捕捉到时间序列在不同时间段的行为变化。
- 滞后特征:创建时间序列的过去值作为新的特征,以揭示序列的自相关性质。例如,可以使用前一天(滞后1)或前一周(滞后7)的数据作为预测当前值的特征。
- 差分和季节差分:计算时间序列的一阶差分(即当前值与前一个值的差)或季节性差分(如当前值与前一年同一天的值的差)来帮助去除趋势和季节性影响。
- 变换:应用变换如对数变换、平方根变换等,可以帮助稳定时间序列的方差,使其更适合某些统计模型。
- 时间戳信息:提取时间戳的特定部分,如小时、周天、月份等,用于捕捉周期性模式。
- 傅里叶变换:通过傅里叶变换将时间序列转换为频域表示,提取周期性特征。
- 波动性度量:对于金融时间序列,可以计算历史波动性或返回序列的标准偏差等度量。
- 窗口函数:使用滑动窗口操作,如滑动平均或指数平滑,以平滑时间序列并减少噪声。

本文将通过使用feature-engine来简化这些特征的提取,首先我们看看数据。
# Importing the Data and Cleaning them
import pandas as pd
import matplotlib.pyplot as plt
filename = 'AirQualityUCI.csv'
# load the data
data = pd.read_csv(
filename, sep=';', parse_dates=[['Date', 'Time']]
).iloc[:, :-2] # drops last 2 columns, not real variables
# drop missing values
data.dropna(inplace=True)
new_var_names = [
'Date_Time',
'CO_true',
'CO_sensor',
'NMHC_true',
'C6H6_true',
'NMHC_sensor',
'NOX_true',
'NOX_sensor',
'NO2_true',
'NO2_sensor',
'O3_sensor',
'T',
'RH',
'AH',
]
data.columns = new_var_names
predictors = data.columns[1:]
for var in predictors:
if data[var].dtype =='O':
data[var] = data[var].str.replace(',', '.')
data[var] = pd.to_numeric(data[var])
data['Date_Time'] = data['Date_Time'].str.replace('.', ':', regex=False)
data['Date_Time'] = pd.to_datetime(data['Date_Time'],dayfirst=True)
data.sort_index(inplace=True)
data.to_csv('AirQualityUCI_Cleaned.csv', index=False)然后我们安装feature-engine
pip install feature-enginefeature-engine 是一个 Python 库,专门设计用于特征工程。该库提供了许多方便的特征处理方法,可以简化数据预处理的流程,增强机器学习模型的性能。下面是一些 feature-engine 主要提供的功能:
- 缺失数据处理:
- 提供了多种填充缺失值的策略,如使用均值、中位数、众数或指定的常数来填充。
- 提供添加缺失数据指示器的功能,这可以帮助模型识别数据缺失的模式。
- 分类变量编码:
- 支持多种编码策略,如独热编码、序数编码、计数编码、目标编码(Mean encoding)、权重风险比编码等。
- 连续变量变换:
- 提供了对数变换、倒数变换、平方根变换等多种数学变换,帮助处理偏态数据。
- 包括离散化连续变量的功能,如等距离散化、等频离散化或使用决策树分箱等。
- 特征缩放:
- 包括最常见的缩放方法,如最大最小缩放(Min-Max Scaling)、标准缩放(Standard Scaling)和均值正规化。
- 特征选择:
- 提供基于各种统计检验和模型性能的特征选择方法,例如基于相关系数、卡方检验、递归特征消除等。
- 特征组合:
- 支持创建特征的交互项,如两个变量的乘积或其他复合关系。
下面我们来演示feature-engine如何应用在时间序列的数据上。
import numpy as np
import pandas as pd
from feature_engine.creation import CyclicalFeatures
from feature_engine.datetime import DatetimeFeatures
from feature_engine.imputation import DropMissingData
from feature_engine.selection import DropFeatures
from feature_engine.timeseries.forecasting import LagFeatures, WindowFeatures
from sklearn.pipeline import Pipeline我们还将从Sklearn导入Pipeline,它可以帮助我们执行特征工程,然后载入数据,排序,然后做简单的数据清理
def load_data():
# Data lives here.
filename = "AirQualityUCI_Cleaned.csv"
# Load data: only the time variable and CO.
data = pd.read_csv(
filename,
usecols=["Date_Time", "CO_sensor", "RH"],
parse_dates=["Date_Time"],
index_col=["Date_Time"],
)
# Sanity: sort index.
data.sort_index(inplace=True)
# Reduce data span.
data = data.loc["2004-04-01":"2005-04-30"]
# Remove outliers
data = data.loc[(data["CO_sensor"] >= 0) & (data["RH"] >= 0)]
return data
# Load data.
data = load_data()提取数据时间特征
首先我们从datetime字段中提取日期时间特征。
datetime_features= DatetimeFeatures( variables='index',
features_to_extract=['month',
'week',
'day_of_week',
'day_of_month',
'hour',
'weekend'])
data=datetime_features.fit_transform(data)
滞后特征提取
lag_features= LagFeatures(variables=['CO_sensor','RH'],
freq=['1H','24H'],
missing_values='ignore')
data= lag_features.fit_transform(data)
data.head(26)在上面的代码中,我们将滞后频率设置为1小时和24小时,代码将为上面定义的每个变量创建2个单独的特征。
# Seeing all the Lag Features alone
data[[features for features in data.columns if 'lag' in features]]
基于窗口的特性
window_features= WindowFeatures(variables=['CO_sensor','RH'],
window='3H', # This will window the last 3 hours
freq='1H', # Do this for every hour
missing_values='ignore')
data=window_features.fit_transform(data)创建一个3小时移动平均值的窗口特征。由于上面没有定义汇总函数,所以默认情况下取平均值作为窗口函数。
# Seeing all the Window Features alone
data[[features for features in data.columns if 'window' in features]]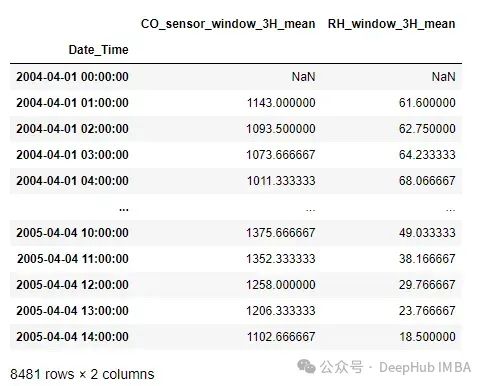
周期性特征
周期性特征将保持任何其他日期字段的连续性。
cyclic_features= CyclicalFeatures(variables=['month','hour'],
drop_original=False)
data= cyclic_features.fit_transform(data)
# Seeing all the Periodic Features alone
data[[features for features in data.columns if 'month' in features or 'hour' in features]]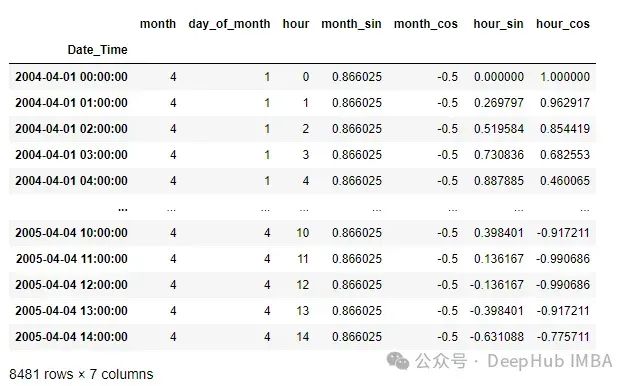
清理特征
在创建某些特性时,将会得到一些nan值。我们需要移除它们。
imputer=DropMissingData()
data=imputer.fit_transform(data)我们还可以删除不需要的特征
drop_features=DropFeatures(features_to_drop=['CO_sensor','RH'])
data=drop_features.fit_transform(data)因为我们已经从这些原始特征中提取了其他的高级特征。所以保留它们模型会学习两次或三次相同的信息,从而导致过拟合。
创建管道
data = load_data()这将加载已清理的原始数据,然后我们创建一个特征处理的完整流程
pipe= Pipeline([
('datetime_features',datetime_features),
('lag_features',lag_features),
('window_features',window_features),
('cyclic_features',cyclic_features),
('dropnan',imputer),
('drop_dataleak_features',drop_features)
])
data=pipe.fit_transform(data)上面代码将创建所有特征,删除nan,然后同时删除原始特征。
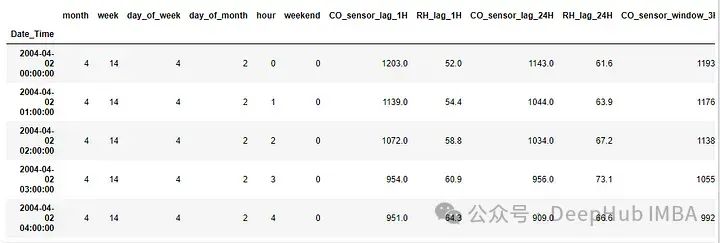
总结
时间序列数据的分析对于许多领域如金融、气象和销售预测至关重要。本文首先总结了常用的时间序列特征,例如滚动统计量、滞后特征、季节差分等,这些特征有助于揭示数据的底层模式和趋势。接着,文章深入探讨了如何利用 feature-engine 库来简化这些特征的工程过程。feature-engine 是一个强大的 Python 库,提供了一系列工具和技术,用于高效地处理和转换数据,从而提高机器学习模型的性能。通过集成滚动窗口统计、自动填充缺失值、编码分类变量等功能,feature-engine 不仅优化了数据预处理流程,还使得特征工程更加直观和易于管理。
本文的数据下载地址:
https://archive.ics.uci.edu/dataset/360/air+quality
作者:Harish Siva Subramanian