S3-FIFO
S3-FIFO

S3-FIFO
БОЮФзїЮЊЯТвЛЦЊЛКДцЮФеТЕФдЄБИжЊЪЖЁЃ
БГОА
ЛљгкLRUКЭFIFOЕФЧ§ж№
FIFOКЭLRUЖМЪЧОЕфЕФЛКДцЧ§ж№ЫуЗЈЃЌдкЙ§ШЅМИЪЎФъжавВГіЯжСЫКмЖрзЗЧѓИќИпаЇТЪЕФЧ§ж№ЫуЗЈЃЌШчARC, 2Q, LIRS, TinyLFUЁЃДЋЭГЙлЕуШЯЮЊЃЌЛљгкLRUЕФЛКГхЮДУќжаТЪвЊЕЭгкЛљгкFIFOЕФЫуЗЈЃЌШчCLOCKЃЌетРрИпМЖЫуЗЈЭЈГЃЖМЪЧЛљгкLRUЕФЁЃЕЋЛљгкLRUЕФЫуЗЈДцдк3ИіЮЪЬтЃК1)УПИіЖдЯѓашвЊСНИіжИеыЃЌЖдгкАќКЌаЁЖдЯѓЕФИКдиЛсВњЩњДѓСПДцДЂПЊЯњЃЛ2)гЩгкдкЛКДцУќжаЪБашвЊЪЙгУЫјРДНЋЧыЧѓЕФЖдЯѓЗХЕНЖгСаЪзВПЃЌвђДЫЮоЗЈЪЕЯжРЉеЙЃЛ3)гЩгкЪЧЫцЛњаДЃЌЩСДцВЛгбКУЁЃ
ПЩРЉеЙЕФживЊад
гЩгкКмЖрЯжДњCPUЖМАќКЌЖрИіКЫЃЌвђДЫЛКДцЕФРЉеЙадвтЮЖзХЫќЕФЭЬЭТСППЩвдЫцCPUКЫЪ§ЕФдіМгЖјдіМгЁЃРэЯыЧщПіЯТЃЌвЛИіЛКДцЕФЭЬЭТСПКЭCPUКЫЪ§ГЪЯпадЙиЯЕЁЃЕЋдкЛљгкLRUЕФЫуЗЈжаЃЌЖСШЁВйзїашвЊМгЫјВХФмИќаТдЊЪ§ОнЃЌвђДЫЮоЗЈЭъШЋРћгУCPUЕФМЦЫуФмСІЁЃ
FIFOЕФгХЪЦ
ПЩвдЪЙгУring bufferРДЪЕЯжFIFOЃЌЮоашЮЊУПИіЖдЯѓЗжХфжИЯђдЊЪ§ОнЕФжИеыЃЌвВЮоашдкУПДЮЛКДцУќжаЪБаоИФЖдЯѓЕФЮЛжУЃЌвђДЫВЛДцдкПЩРЉеЙЦПОБЁЃСэЭтFIFOАДееЯШНјЯШГіЕФЫГађРДЧ§ж№ЖдЯѓЃЌвђДЫЪЧвЛжжЩСДцгбКУЕФЗУЮЪФЃЪНЃЌПЩвдМѕаЁЩСДцаДШывдМАЩСДцЫ№КФЁЃЕЋFIFOдкаЇТЪЩЯТфКѓгкLRUКЭвЛаЉЯШНјЕФЧ§ж№ЫуЗЈЁЃ
one-hit wonders ratio
Ъѕгя"one-hit-wonder ratio"жИдквЛИіађСа(sequences)жаЃЌжЛБЛЧыЧѓвЛДЮЕФЖдЯѓЫљеМЕФБШР§ЃЌЭЈГЃгУгкCDNжа(ЦфДцдкНЯДѓЕФone-hit-wonder ratio)ЁЃЫфШЛone-hit-wonder ratioЛсвђЮЊЛКДцИКдиЕФРраЭЖјгаЫљБфЛЏЃЌЕЋЮвУЧЗЂЯждНЖЬЕФЧыЧѓађСа(shorter request sequencesЃЌМДНЯЩйЕФЖдЯѓ)ЕФone-hit-wonder ratioдНИп
етРяЕФЧыЧѓађСаПЩвдПДзіЪЧвЛИіЧыЧѓбљБО

ЩЯУцЪОР§жаЃЌдкађСаГЄЖШЮЊ17ЃЌАќКЌ5ИіЖдЯѓЕФГЁОАжаЃЌга1ИіЖдЯѓ(E)НіБЛЗУЮЪСЫвЛДЮЃЌЦфone-hit-wonder ratioЮЊ20%ЃЛЖјдкађСаГЄЖШЮЊ7(1st~7st)ЕФГЁОАжаЃЌга2ИіЖдЯѓ(CЃЌD)НіБЛЗУЮЪСЫвЛДЮЃЌЦфone-hit-wonder ratioЮЊ50%ЃЛРрЫЦЕидкађСаГЄЖШЮЊ4(1st~4st)ЕФГЁОАжаЃЌЦфone-hit-wonder ratioЮЊ67%.
ЩњВњжаЕФone-hit wonders ratio
ФЧУДдкЪЕМЪЩњВњжаЕФБэЯжЪЧЗёКЭЩЯУцЪОР§жавЛжТЃПЯТЭМеЙЪОСЫЖдРДздMSRЕФвЛИіПщЛКДц(hm_0) traceКЭРДздTwitterЕФвЛИіkey-value ЛКДцЕФtraceНсЙћЁЃXжсБэЪОЖдЯѓдкtraceжаЕФБШТЪ(ЗжБ№ЪЙгУЯпад(зѓЭМ)КЭЖдЪ§БэЪО(гвЭМ))ЁЃ
ПЩвдПДЕНЭъећtraceЕФone-hit-wonder ratio(зѓЭМXжсЮЊ1.00ЕФЕу)ЗжБ№ЮЊ13%(Twitter)КЭ38%(MSR)ЃЌЖјАќКЌ10%ЖдЯѓЕФЫцЛњзгађСаЕФone-hit-wonder ratio(гвЭМXжсЮЊ10-1ЕФЕу)ЗжБ№ЮЊ26%(Twitter)КЭ75%(MSR)ЁЃ
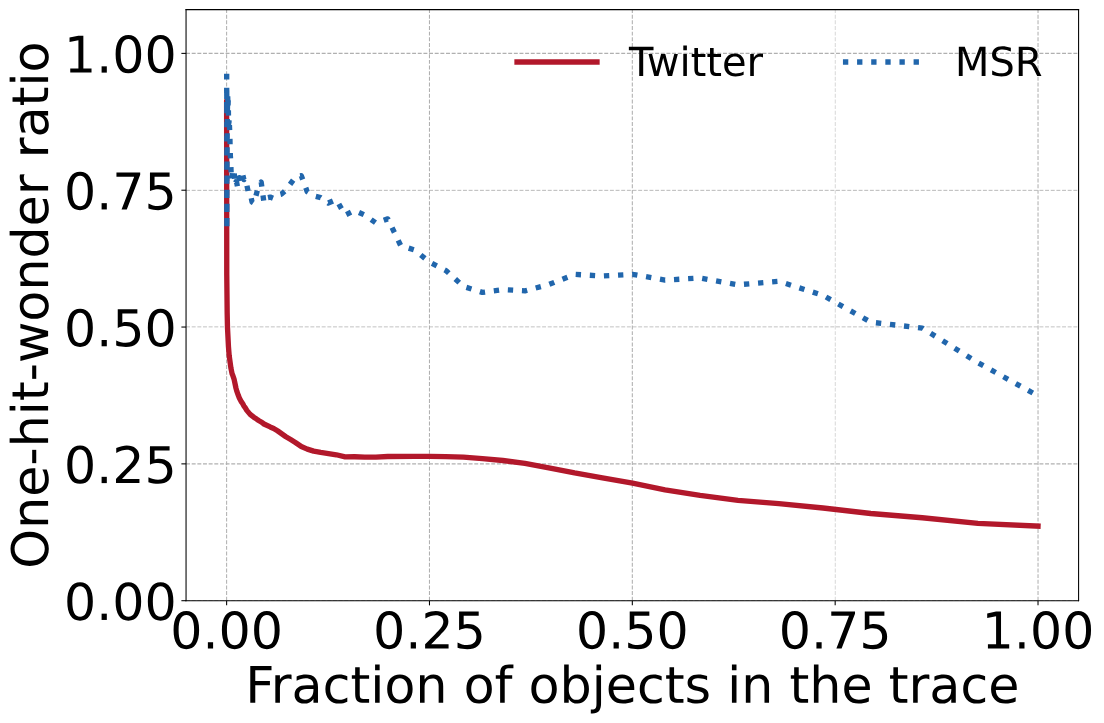
ЩњВњtracesжаЕФone-hit-wonder ratioЁЃЭъећtraceЕФone-hit-wonder ratioЮЊ13%КЭ38%ЃЌПЩвдПДЕНЃЌађСадНЖЬЃЌone-hit-wonder ratioдНИп
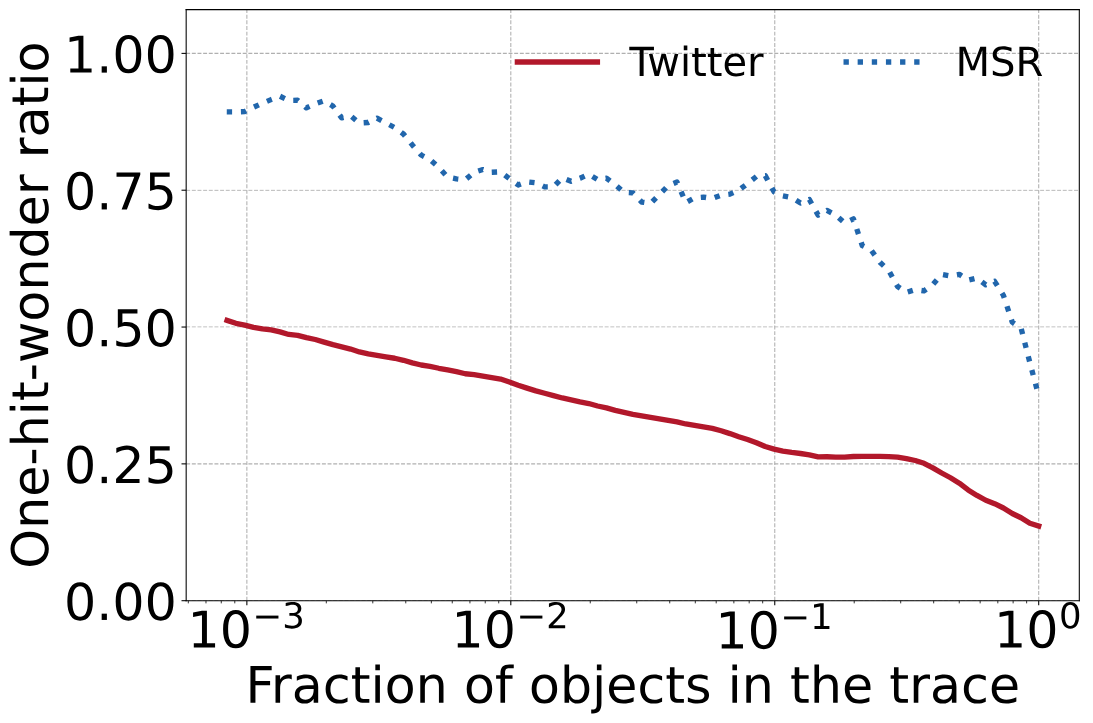
ЮвУЧНјвЛВНЗжЮіСЫвЛИіАќКЌ6594ЬѕtraceЕФДѓаЭЛКДцtraceМЏКЯЃЌВЂдкЯфЯпЭМжаЛцжЦСЫвЛДЮУќжаБШР§ЕФЗжВМЁЃЭъећtraceЕФone-hit-wonder ratioЕФжаЮЛЪ§ЮЊ26%ЃЌАќКЌ50% traceађСаЕФone-hit-wonder ratioЕФжаЮЛЪ§ЮЊ38%ЁЃДЫЭтЃЌАќКЌ10%КЭ1% traceађСаЕФone-hit-wonder ratioЕФжаЮЛЪ§ЗжБ№ЮЊ72%КЭ78%ЁЃ
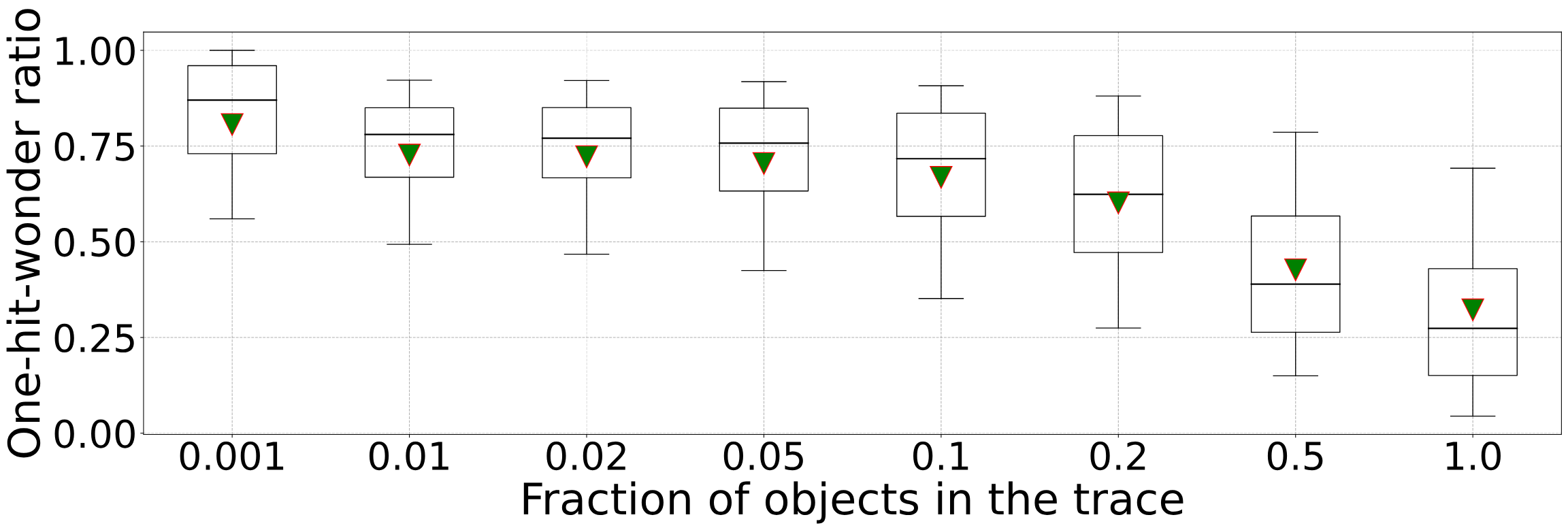
one-hit-wonder ratioЕФгАЯь
ЮвУЧдкЗжЮіжаЪЙгУЕФtraceДѓВПЗжЪЧЮЊЦквЛжмЃЌЩйВПЗжЪЧЮЊЦквЛИідТЕФЁЃгЩгкЛКДцДѓаЁЭЈГЃдЖаЁгкtraceЕФеМгУПеМф(traceжаЕФЖдЯѓЪ§СП/зжНкЪ§)ЃЌвђДЫдкЖЬађСаГЁОАЯТОЭПЩФмЛсЗЂЩњЛКДцЧ§ж№ЁЃЮвУЧЙлВьЗЂЯжЃЌЕБЛКДцДѓаЁЮЊtraceПеМфЕФ10%ЪБЃЌДѓдМга72%ЕФЖдЯѓдкЧ§ж№жЎЧАВЛЛсБЛдйДЮЪЙгУЁЃ
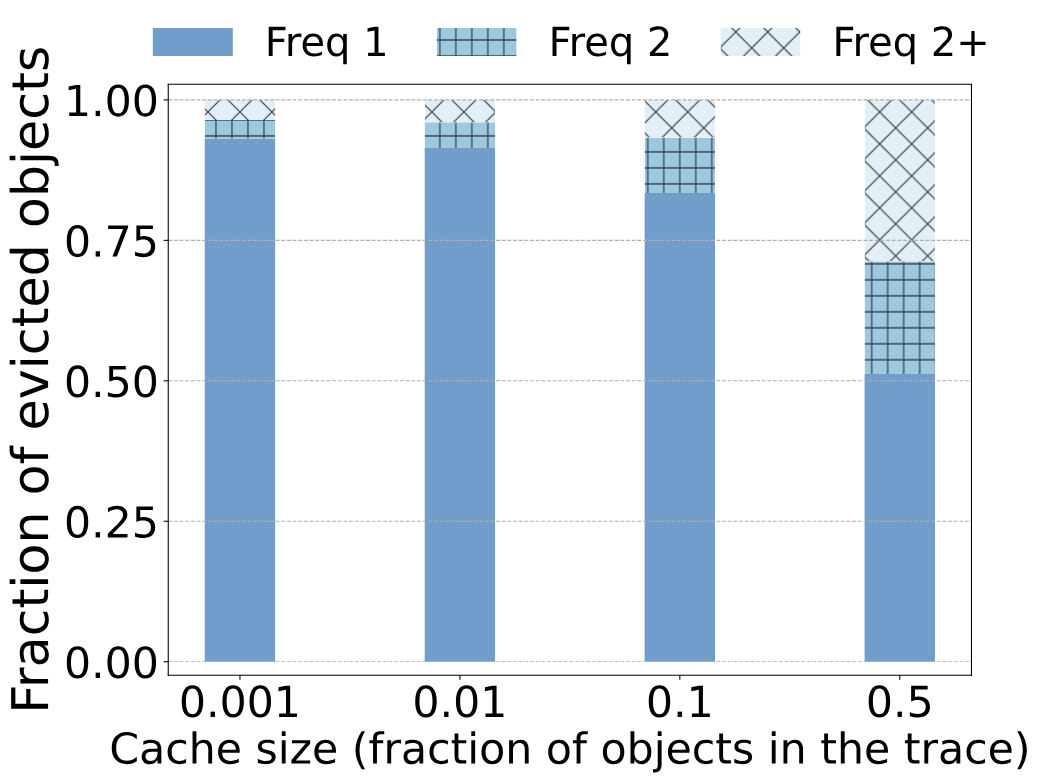
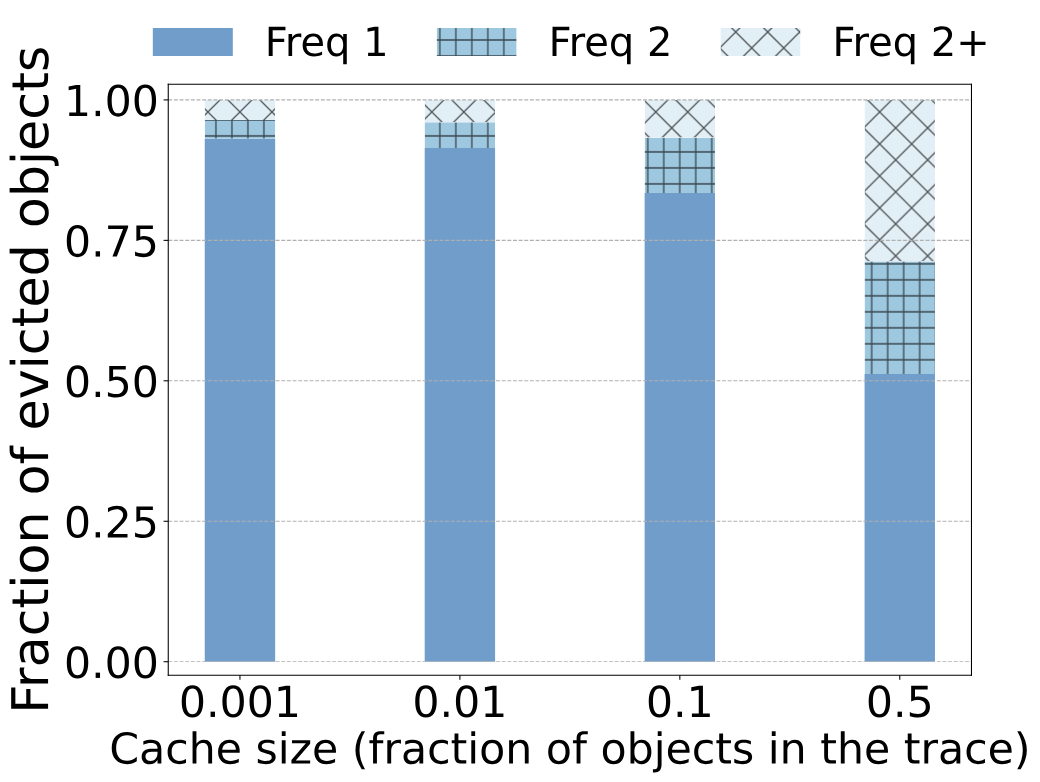
ЮвУЧгУЛКДцЗТецНјвЛВНжЄЪЕСЫЙлВтНсЙћЁЃЩЯЭМеЙЪОСЫЧ§ж№ЖдЯѓЕФЦЕТЪЁЃЮвУЧЕФtraceЗжЮіБэУїЃЌдкTwitterЕФtraceжаЃЌЕБађСаЮЊtraceПеМфЕФ10%ЪБЃЌone-hit-wonder ratioЮЊ26%ЃЌЖјЗТецеЙЪОСЫРрЫЦЕФНсЙћЃКБЛLRUж№ГіЕФЖдЯѓжага26%дкВхШыЛКДц(ДѓаЁЮЊtraceЕФ10%)КѓУЛгаБЛЧыЧѓЁЃРрЫЦЕиЃЌдкMSRЕФtraceжаЃЌЕБађСаГЄЖШЮЊtraceЕФ10%ЪБЃЌone-hit-wonder ratioЮЊ75%ЃЌЖјЗТецжаБЛLRUЧ§ж№ЕФЖдЯѓжаЕФ82%УЛгаБЛдйДЮЪЙгУЁЃ
КмУїЯдЃЌЛКДцгІИУЙ§ТЫЕєетаЉone-hit wondersЃЌвђЮЊЫќУЧеМгУСЫПеМфЃЌШДУЛгаДјРДКУДІЁЃ
S3-FIFOЃКвЛИіНіЪЙгУFIFOЖгСаЕФЧ§ж№ЫуЗЈ
ЪмЩЯУцЙлВтНсЙћЕФЦєЗЂЃЌЮвУЧЩшМЦСЫвЛИіаТЕФЛКДцЧ§ж№ЫуЗЈЃЌГЦЮЊS3-FIFOЃКМђЕЅЁЂЪЙгУШ§ИіОВЬЌFIFOЖгСаЕФПЩРЉеЙЛКДц(Simple, Scalable caching with three Static FIFO queues)ЁЃ
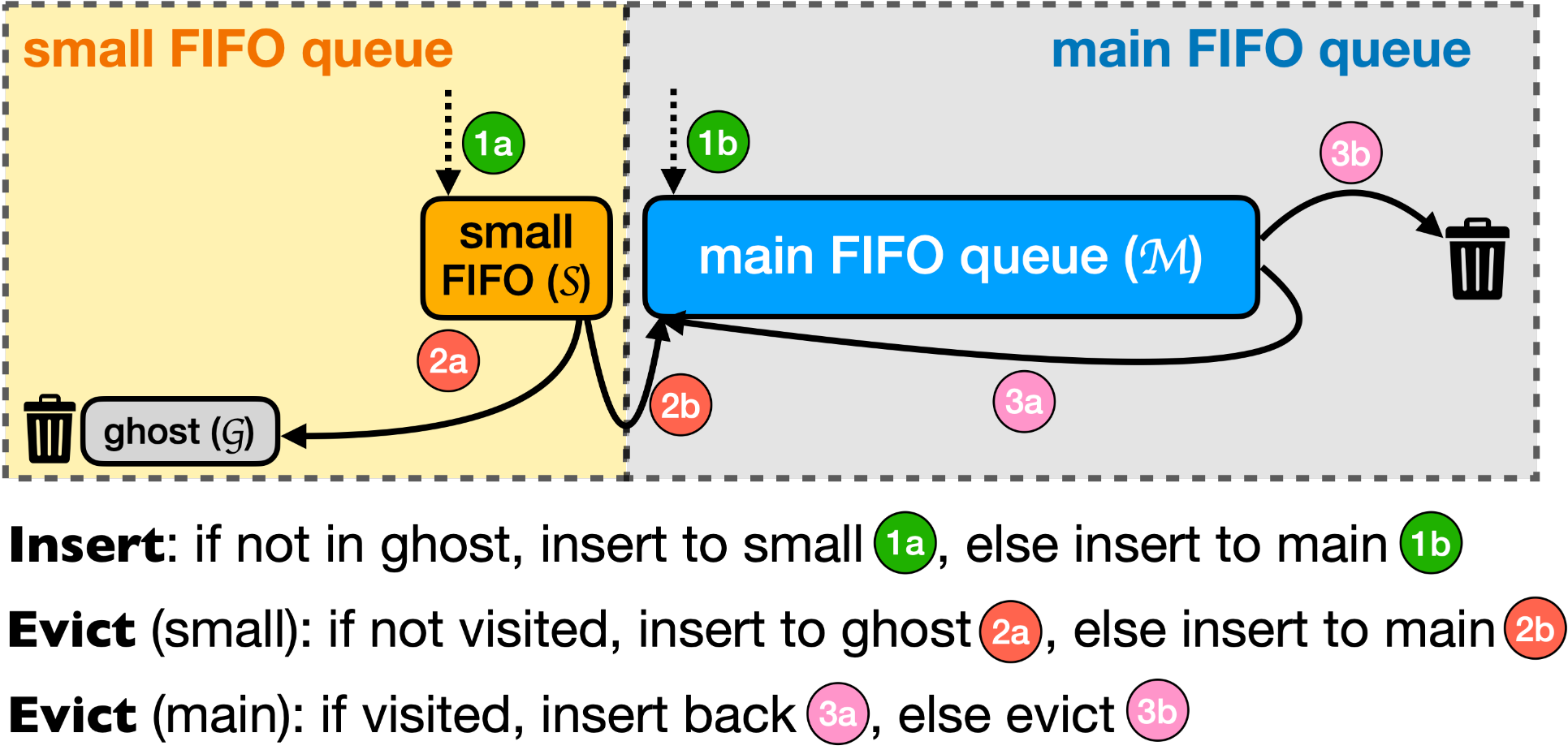
S3-FIFOЪЙгУ3ИіFIFOЖгСаЃКвЛИіsmall FIFOЖгСа(S)ЃЌвЛИіmain FIFOЖгСа(M)ЃЌвЛИіghost FIFOЖгСа(G)ЁЃЮвУЧНЋSЩшжУЮЊ10%ЕФЛКДцПеМф(ЪЕбщЕУГі)ЁЃMЮЊ90%ЕФЛКДцПеМфЃЌЖјGЕФДѓаЁКЭMЯрЭЌЁЃзЂвтЃЌЕБдкghostЖгСажаЗЂЯжЧыЧѓЕФЪ§ОнЪБЃЌДЫЪБВЂВЛЫуЛКДцУќжаЃЌдвђЪЧghostЖгСаВЂВЛБЃДцЪ§ОнЁЃ
- ЛКДцЖСЃКS3-FIFOжаЃЌУПИіЖдЯѓЪЙгУСНИіbits(
freq)РДИњзйЖдЯѓЗУЮЪзДЬЌЃЌЩЯЯоЮЊ3ЃЌЛКДцУќжаЪБздЖЏМг1ЁЃ - ЛКДцаДЃКЕБВхШывЛИіЖдЯѓЪБЃЌШчЙћ
GжаУЛгаИУЖдЯѓЃЌдђВхШыSЁЃЕБSТњЪБЃЌЮЛгкSЮВВПЕФЖдЯѓвЊУДЛсБЛзЊвЦЕНM(ЗУЮЪЗЧ0)ЃЌвЊУДБЛзЊвЦЕНG(ЗУЮЪЮЊ0)ЃЌВЂдкзЊвЦжЎКѓЧхГ§ЗУЮЪБъМЧ(freq) ЕБGТњЪБЃЌЫќЛсАДееFIFOЫГађЧ§ж№ЖдЯѓЁЃMЪЙгУвЛИіРрЫЦ FIFO-ReinsertionЕФЫуЗЈЃЌЕЋЭЌЪБЪЙгУСНИіbitsРДИњзйЗУЮЪаХЯЂЁЃжСЩйЖдЯѓЕФfreqДѓгк0ЃЌЛсБЛжиаТВхШыMЪзВПЃЌВЂНЋfreqМѕ1(freq-1)

ЬэМгЖдЯѓЕФбнЪОШчЯТЃК
БОЮФЗжЯэзд зїепИіШЫеОЕу/ВЉПЭ?ЧАЭљВщПД
ШчгаЧжШЈЃЌЧыСЊЯЕ cloudcommunity@tencent.com ЩОГ§ЁЃ
БОЮФВЮгы?ЬкбЖдЦздУНЬхЗжЯэМЦЛЎ? ЃЌЛЖгШШАЎаДзїЕФФувЛЦ№ВЮгыЃЁ