分享一份抓取某东商品名称、价格和评论数的代码

大家好,我是皮皮。
一、前言
前几天在Python白银交流群【邮递员】问了一个Python网络爬虫的问题,提问截图如下:
代码如下:
import requests
from lxml import etree
import json
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36 Edg/104.0.1293.70"
}
###根据商品id获取评论数
def commentcount(product_id):
url = 'https://club.jd.com/comment/productCommentSummaries.action?referenceIds=' + str(
product_id) + '&callback=jQuery5774279&_=1661908123160'
res = requests.get(url, headers=headers)
res.encoding = 'gbk'
text = (res.text).replace('jQuery5774279(', '').replace(");", "")
text = json.loads(text)
comment_count = text['CommentsCount'][0]['CommentCountStr']
print(comment_count)
comment_count = comment_count.replace('+', '')
###对“万”进行操作
if '万' in text:
comment_count = comment_count.replace('万', '')
comment_count = str(int(comment_count) * 10000)
return comment_count
commentcount('13865278250')
###获取每一页的商品数据
def getlist():
url = 'https://search.jd.com/search?keyword=%E7%94%B5%E8%84%91%E7%AC%94%E8%AE%B0%E6%9C%AC&suggest=1'
res = requests.get(url, headers=headers)
res.encoding = 'utf-8'
text = res.text
selector = etree.HTML(text)
list = selector.xpath('//*[@id="J_goodsList"]/ul/li')
for i in list:
title = i.xpath('.//div[@class="p-name p-name-type-2"]/a/em/text()')[0]
price = i.xpath('.//div[@class="p-price"]/strong/i/text()')[0]
product_id = i.xpath('.//div[@class="p-commit"]/strong/a/@id')[0].replace("j_comment_", "")
comment_count = commentcount(product_id)
print(title)
print(price)
print(comment_count)
print(list)
getlist()
二、实现过程
这里【瑜亮老师】给他指出了问题,如下图所示:

只需要改一个字母就可以了。
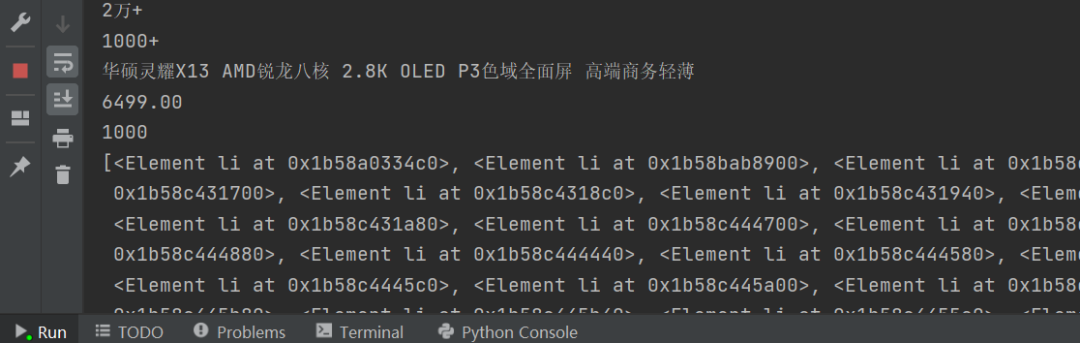
运行结果正常:
后来【甯同学】也给了一个代码,还可以自动存储到Excel中去,代码如下所示:
import requests
import openpyxl
from lxml import etree
import json
import pandas as pd
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36 Edg/104.0.1293.70"
}
outwb = openpyxl.Workbook()
outws = outwb.create_sheet(index=0)
outws.append(['行号', '标题', '价格', '评论数'])
# 根据商品id获取评论数
def commentcount(product_id):
url = 'https://club.jd.com/comment/productCommentSummaries.action?referenceIds=' + str(product_id)
res = requests.get(url, headers=headers)
res.encoding = 'gbk'
text = res.text
text = json.loads(text)
comment_count = text['CommentsCount'][0].get('CommentCountStr')
comment_count = comment_count.replace('+', '').replace('万', '')
comment_count = str(int(comment_count) * 10000)
return comment_count
commentcount('13865278250')
# 获取每一页的商品数据
def getlist():
number = 0
for page in range(1, 10, 2):
print(f'正在抓取第{page}页...')
url = f'https://search.jd.com/search?keyword=%E7%94%B5%E8%84%91%E7%AC%94%E8%AE%B0%E6%9C%AC&suggest=1&page={page}'
res = requests.get(url, headers=headers)
res.encoding = 'utf-8'
text = res.text
selector = etree.HTML(text)
list = selector.xpath('//*[@id="J_goodsList"]/ul/li')
print(f'这一页一共有{len(list)}条数据')
for i in list:
number += 1
title = i.xpath('.//div[@class="p-name p-name-type-2"]/a/em/text()')[0].strip()
price = i.xpath('.//div[@class="p-price"]/strong/i/text()')[0]
product_id = i.xpath('.//div[@class="p-commit"]/strong/a/@id')[0].replace("J_comment_", "")
comment_count = commentcount(product_id)
info_list = [number, title, float(price), comment_count]
print(info_list)
outws.append(info_list)
if __name__ == '__main__':
getlist()
outwb.save("京东商品.xlsx")
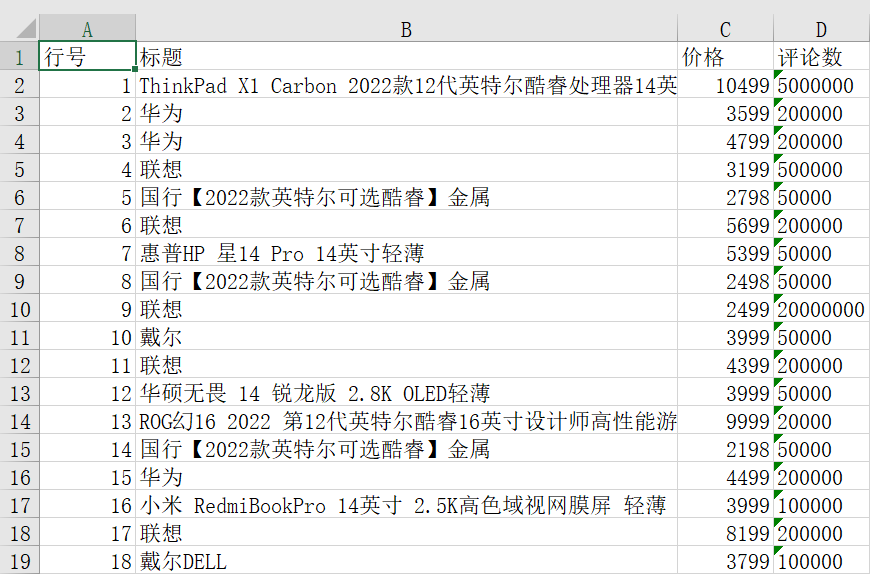
代码运行之后,在本地可以得到结果,如下如所示:
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python网络爬虫的问题,实现了某东商品信息的网络爬虫抓取,文中针对该问题给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【邮递员】提问,感谢【甯同学】、【瑜亮老师】给出的思路和代码解析,感谢【dcpeng】、【冫马讠成】、【此类生物】等人参与学习交流。
本文参与?腾讯云自媒体分享计划,分享自微信公众号。
原始发表:2024-04-20,如有侵权请联系?cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录