ICCV 2023 | ImitatorЃКИіадЛЏгявєЧ§ЖЏЕФ 3D ШЫСГЖЏЛ
ICCV 2023 | ImitatorЃКИіадЛЏгявєЧ§ЖЏЕФ 3D ШЫСГЖЏЛ

РДдДЃКICCV 2023 ТлЮФЬтФПЃКImitator: Personalized Speech-driven 3D Facial Animation ТлЮФСДНгЃКhttps://arxiv.org/abs/2301.00023 ТлЮФзїепЃКBalamurugan Thambiraja ЕШШЫ ФкШнећРэ: СжзкхА БОЮФЬсГіСЫвЛжжгУгкИіадЛЏгявєЧ§ЖЏ 3D ШЫСГЖЏЛЕФЗНЗЈ ImitatorЃЌИУЗНЗЈПЩвдДгМђЖЬЕФЪфШыЪгЦЕжабЇЯАЬиЖЈЩэЗнЕФЯИНкЃЌВЂЩњГЩгыФПБъШЫЮяЕФЫЕЛАЗчИёКЭУцВПЬижЪЯрЦЅХфЕФШЫСГБэЧщЃЌВЂЮЊЫЋДНИЈвєЃЈ'm','b','p'ЃЉЬсЙЉзМШЗЕФДНБеКЯЁЃДѓСПЪЕбщБэУї Imitator ДгЪфШывєЦЕжаЩњГЩСЫИЛгаБэЧщЕФШЫСГЖЏЛЃЌУїЯдЬсИпСЫПкаЭЭЌВНадФмЃЌВЂБЃСєСЫШЫЮяЕФЫЕЛАЗчИёЁЃ
в§бд

ЭМ 1ЃКImitator ЪЧвЛжжгУгкИіадЛЏгявєЧ§ЖЏ 3D ШЫСГЖЏЛЕФаТЗНЗЈЁЃИјЖЈвєЦЕађСаКЭИіадЛЏЗчИёЧЖШызїЮЊЪфШыЃЌЮвУЧЩњГЩЬиЖЈШЫЮяЕФдЫЖЏађСаЃЌВЂЮЊЫЋДНИЈвєЃЈ'm','b','p'ЃЉЬсЙЉзМШЗЕФДНБеКЯЁЃжїЬхЕФЗчИёЧЖШыПЩвдДгвЛИіМђЖЬВЮПМЪгЦЕЃЈ5 УыЃЉжаМЦЫуЕУЕНЁЃ
гявєЧ§ЖЏЕФ 3D ШЫСГЖЏЛвбОЕУЕНСЫЙуЗКЕФЬНЫїЁЃФПЧАзюЯШНјЕФЗНЗЈЖдФПБъШЫЮяЕФУцВПЭиЦЫНјаааЮБфвдЭЌВНЪфШывєЦЕЃЌЕЋУЛгаПМТЧЬиЖЈЩэЗнЕФЫЕЛАЗчИёКЭУцВПЬижЪЃЌДгЖјЕМжТСЫВЛецЪЕЁЂВЛзМШЗЕФзьДНдЫЖЏЁЃЮЊСЫНтОіетвЛЮЪЬтЃЌЮвУЧЬсГіСЫвЛжжгявєЧ§ЖЏЕФШЫСГБэЧщКЯГЩЗНЗЈ ImitatorЃЌИУЗНЗЈПЩвдДгМђЖЬЕФЪфШыЪгЦЕжабЇЯАЬиЖЈЩэЗнЕФЯИНкЃЌВЂЩњГЩгыФПБъШЫЮяЕФЫЕЛАЗчИёКЭУцВПЬижЪЯрЦЅХфЕФШЫСГБэЧщЁЃОпЬхЖјбдЃЌЮвУЧдквЛИіДѓаЭШЫСГБэЧщЪ§ОнМЏЩЯбЕСЗСЫвЛИіЗчИёЮоЙиЕФ TransformerЃЌзїЮЊвєЦЕЧ§ЖЏЕФШЫСГБэЧщЯШбщЃЌНјЖјИљОнМђЖЬЕФВЮПМЪгЦЕЃЌРћгУЯШбщРДгХЛЏЬиЖЈЩэЗнЕФЫЕЛАЗчИёЁЃЮЊСЫбЕСЗЯШбщЃЌЮвУЧв§ШыСЫвЛжжЛљгкМьВтЕФЫЋДНИЈвєЫ№ЪЇКЏЪ§ЃЌвдШЗБЃКЯРэЕФДНБеКЯЃЌДгЖјЬсИпЩњГЩБэЧщЕФецЪЕадЁЃЭЈЙ§ГфЗжЕФЪЕбщКЭгУЛЇбаОПЃЌЮвУЧеЙЪОСЫ Imitator НЋПкаЭЭЌВНЬсИпСЫ 49%ЃЌВЂДгЪфШывєЦЕжаЩњГЩСЫИЛгаБэЧщЕФШЫСГЖЏЛЃЌЭЌЪББЃСєСЫШЫЮяЕФЫЕЛАЗчИёЁЃБОЮФЕФжївЊЙБЯззмНсШчЯТЃК
- ЮвУЧЬсГіСЫвЛжжЧсСПМЖЫЕЛАЗчИёЪЪгІЗНЗЈЃЌЭЈЙ§ЗжРыЭЈгУЪгЫиЩњГЩКЭЬиЖЈЩэЗнНтТыЃЌДгМђЖЬЕФВЮПМЪгЦЕжагааЇЪЪгІаТШЫЮяЕФЫЕЛАЗчИёЁЃ
- ЮвУЧв§ШыСЫвЛжжаТЕФДНВПНгДЅЫ№ЪЇЃЌЛљгкЫЋДНИЈвєЃЈ'm','b','p'ЃЉЕФЩњРэбЇвРОнИФЩЦСЫзьДНЕФБеКЯЁЃ
ЗНЗЈ
ФЃаЭМмЙЙ
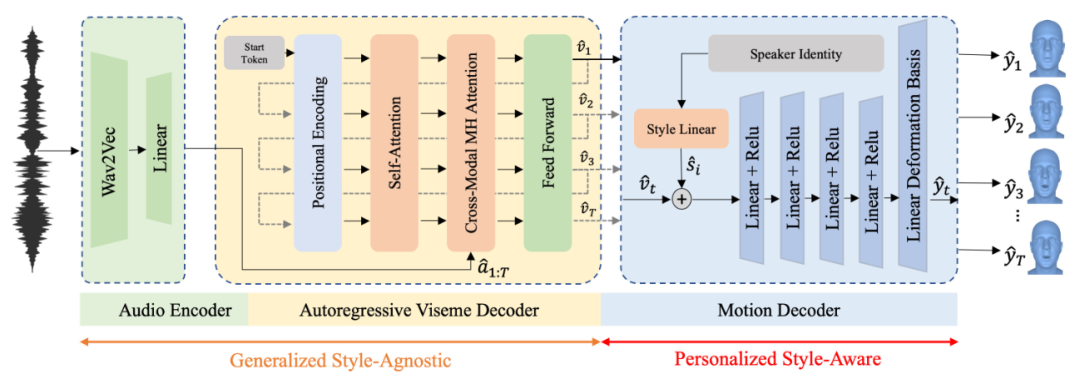
ЭМ 2ЃКЮвУЧЕФМмЙЙвдвєЦЕзїЮЊЪфШыВЂгЩ Wav2Vec 2.0 БрТыЁЃвєЦЕЧЖШыЫЭШывЛИіздЛиЙщЪгЫиНтТыЦїЩњГЩдЫЖЏЬиеїЁЃЗчИёЪЪгІдЫЖЏНтТыЦїНЋетаЉдЫЖЏЬиеїгГЩфЕНЬиЖЈЩэЗнЕФШЫСГБэЧщЃЌМДЯрЖдФЃАхЭјИёЕФЖЅЕуЮЛвЦЁЃ
вєЦЕБрТыЦї
ЮвУЧЪЙгУЭЈгУгявєФЃаЭРДЖдЪфШывєЦЕНјааБрТыЁЃОпЬхЖјбдЃЌЮвУЧВЩгУ Wav2Vec 2.0ЁЃзюГѕЕФ Wav2Vec Лљгк CNN МмЙЙЃЌжМдкЩњГЩгавтвхЕФШЫРргявєЧБдкБэЪОЁЃЫќвдздМрЖНКЭАыМрЖНЕФЗНЪННјаабЕСЗЃЌЭЈЙ§ЖдБШЫ№ЪЇРДдЄВтЕБЧАЪфШыгявєжЎКѓЕФжЕЃЌДгЖјЪЙФЃаЭФмЙЛДгДѓСПЮДБъМЧЕФЪ§ОнжаНјаабЇЯАЁЃWav2Vec 2.0 ЭЈЙ§СПЛЏЧБдкБэЪОКЭМЏГЩЛљгк Transformer МмЙЙРДЭиеЙСЫетвЛЯыЗЈЁЃЮвУЧЭЈЙ§ЯпадВхжЕЖд Wav2Vec 2.0 ЪфГіНјаажиВЩбљЃЌвдЦЅХфдЫЖЏЕФВЩбљЦЕТЪЃЌДгЖјЕУЕН
жЁЕФЩЯЯТЮФБэЪО
ЁЃ
здЛиЙщЪгЫиНтТыЦї
ЪгЫиНтТыЦї
вдвєЦЕађСаЕФЩЯЯТЮФБэЪОзїЮЊЪфШыЃЌвдздЛиЙщЕФЗНЪНЩњГЩЗчИёЮоЙиЕФЪгЫиЬиеї
ЁЃетаЉЪгЫиЬиеїУшЪіСЫдкИјЖЈЩЯЯТЮФвєЦЕКЭЯШЧАЕФЪгЫиЬиеїЯТЕФДНВПаЮБфЁЃЮвУЧЪЙгУОЕф Transformer МмЙЙзїЮЊЪгЫиНтТыЦїЃЌЫќбЇЯАДгвєЦЕЬиеї
ЕНЩэЗнЮоЙиЕФЪгЫиЬиеї
ЕФгГЩфЁЃздЛиЙщЪгЫиБрТыЦїЖЈвхЮЊЃК
ЦфжаЃЌ
ЪЧПЩбЇЯАЕФВЮЪ§ЁЃЮвУЧЪЙгУЦ№ЪМ token РДжИЪОађСаЕФПЊЭЗЃЌгЩгкађСаГЄЖШ
ЪЧгЩЪфШывєЦЕГЄЖШИјЖЈЕФЃЌЙЪВЛЪЙгУжежЙ tokenЁЃЮвУЧЭЈЙ§дкЪгЫиЬиеїжаМгШые§ЯвБрТыЪБМф
РДНЋЪБМфаХЯЂзЂШыађСажаЃК
ИјЖЈЮЛжУБрТыЪфШыађСа
ЃЌЮвУЧЪЙгУЖрЭЗздзЂвтСІИљОнЪфШыЕФЯрЙиадМгШЈЩњГЩЩЯЯТЮФБэЪОЁЃетаЉЩЯЯТЮФБэЪОКЭвєЦЕЬиеї
зїЮЊПчФЃЬЌЖрЭЗзЂвтСІПщЕФЪфШыЁЃзюКѓвЛИіЧАРЁВуНЋвєЦЕ-дЫЖЏзЂвтСІВуЕФЪфГігГЩфЕНЪгЫиЧЖШы
ЁЃ
дЫЖЏНтТыЦї
ЮвУЧЕФФПБъЪЧДгЗчИёЮоЙиЕФЪгЫиЬиеї
КЭЬиЖЈЩэЗнЕФЗчИёЧЖШы
ЩњГЩЬиЖЈЩэЗнЕФ 3D ШЫСГЖЏЛ
ЁЃЮвУЧЕФдЫЖЏНтТыЦїАќКЌСНИіВПЗжЃЌвЛИіЗчИёЧЖШыВуКЭвЛИідЫЖЏКЯГЩПщЁЃЮвУЧЮЊбЕСЗМЏЩшжУСЫЩэЗнЕФЖРШШБрТыЁЃЗчИёЧЖШыВуНЋЩэЗнаХЯЂзїЮЊЪфШыЩњГЩБрТыСЫЬиЖЈЩэЗндЫЖЏЕФЗчИёЧЖШы
ЁЃИУЗчИёЧЖШыБЛЬэМгЕНЪгЫиЬиеї
жаВЂЫЭШыдЫЖЏКЯГЩПщЁЃдЫЖЏКЯГЩПщгЩЗЧЯпадВузщГЩЃЌНЋЗчИёИажЊЕФЪгЫиЬиеїгГЩфЕНгЩЯпадаЮБфЛљЖЈвхЕФдЫЖЏПеМфжаЁЃдкбЕСЗЙ§ГЬжаЃЌаЮБфЛљДгЪ§ОнМЏжаЕФЫљгаЩэЗнбЇЯАЕУЕНЃЌВЂПЩЭЈЙ§ЮЂЕїЪЪгУгкбЕСЗЩэЗнЭтЕФЗчИёЁЃзюжеЭјИёЪфГі
гЩЙРМЦЕФЖЅЕуЯрЖдЮЛвЦгыжїЬхЕФФЃАхЭјИёЯрМгЕУЕНЁЃ
бЕСЗ
ЮвУЧЪЙгУздЛиЙщбЕСЗЗНАИдк VOCAset Ъ§ОнМЏЩЯбЕСЗЮвУЧЕФФЃаЭЃЌЖЈвхШчЯТЫ№ЪЇЃК
ЦфжаЃЌ
ЖЈвхЖЅЕуЕФжиНЈЫ№ЪЇЃЌ
ЖЈвхЫйЖШЫ№ЪЇЃЌ
КтСПДНВПНгДЅЁЃШЈжиЗжБ№ЮЊ
ЃЌ
ЃЌ
ЁЃ
жиНЈЫ№ЪЇ
жиНЈЫ№ЪЇ
ЮЊЃК
ЦфжаЃЌ
ЮЊЪБМф
ађСаЫїв§
ЕФецжЕЭјИёЃЌ
ЮЊдЄВтжЕЁЃ
ЫйЖШЫ№ЪЇ
ЮвУЧЕФдЫЖЏНтТыЦїНЋЖРСЂЕФЪгЫиЬиеїзїЮЊЪфШыРДЩњГЩШЫСГБэЧщЁЃЮЊСЫЬсИпдЄВтжаЕФЪБМфвЛжТадЃЌЮвУЧв§ШыСЫЫйЖШЫ№ЪЇ
ЃК
ДНВПНгДЅЫ№ЪЇ
ЪЙгУ
НјаабЕСЗЛсв§ЕМФЃаЭбЇЯАЦНОљЕФШЫСГБэЧщЃЌДгЖјЕМжТВЛзМШЗЕФзьДНБеКЯЁЃЮЊДЫЃЌЮвУЧв§ШыСЫвЛжжаТЕФЫЋДНИЈвєЃЈ'm','b','p'ЃЉДНВПНгДЅЫ№ЪЇЁЃОпЬхЖјбдЃЌЮвУЧздЖЏБъзЂСЫ VOCAset жаетаЉИЈвєЕФГіЯжДЮЪ§ЃЌЖЈвхСЫвдЯТДНВПЫ№ЪЇЃК
ЦфжаЃЌ
ИљОнЫЋДНИЈвєЕФБъзЂЃЌЖддЄВтНјааИпЫЙМгШЈЁЃОпЬхЖјбдЃЌЖдгкОпгаДЫРрИЈвєЕФжЁЃЌ
дк
жаШЁжЕЃЌЗёдђЮЊ
ЁЃ
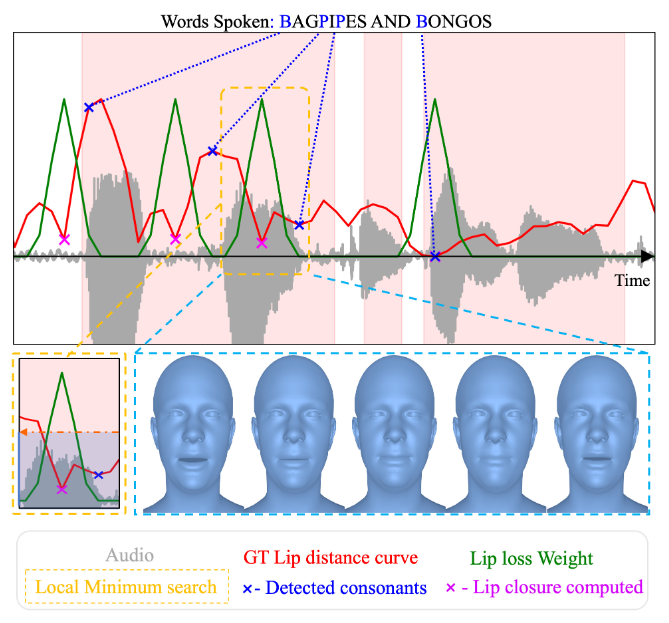
ЭМ 3ЃКдк VOCAset ађСажаздЖЏБъзЂЫЋДНИЈвєЃЈ'm','b','p'ЃЉМАЦфЯргІЕФДНВПБеКЯЁЃЮвУЧЪЙгУ Torch Audio РДЖдЦыЮФБОКЭвєЦЕЁЃЮЊСЫМьВтЪЕМЪЕФДНВПБеКЯЃЌЮвУЧдкМьВтЕНЕФИЈвєжЎЧАЕФДАПкжаЫбЫїДНВПОрРыЧњЯпЃЈКьЩЋЃЉЩЯЕФОжВПзюаЁжЕЁЃДНВПЫ№ЪЇШЈжиЩшжУЮЊИпЫЙКЏЪ§ЕФЙЬЖЈжЕЁЃ
ЗчИёЪЪгІ
ИјЖЈвЛИіаТжїЬхЕФЖЬЪгЦЕЃЌЮвУЧЪЙгУ MICA зЗзйШЫСГ
ЁЃЛљгкИУВЮПМЪ§ОнЃЌЮвУЧЪзЯШгХЛЏЫЕЛАепЕФЗчИёЧЖШы
ЃЌШЛКѓРћгУ
КЭ
Ы№ЪЇСЊКЯИФНјЯпадаЮБфЛљЁЃдкЮвУЧЕФЪЕбщжаЃЌЮвУЧЗЂЯжетжжСННзЖЮЪЪгІЖдгкЗКЛЏЕНаТЕФвєЦЕЪфШыжСЙиживЊЃЌвђЮЊЫќжигУСЫдЫЖЏНтТыЦїЕФдЄбЕСЗаХЯЂЁЃзїЮЊЗчИёЧЖШыЕФГѕЪМЛЏЃЌЮвУЧЪЙгУбЕСЗМЏжаЕФвЛжжЫЕЛАЗчИёЁЃЮвУЧдЄМЦЫуСЫвЛДЮЫљгаЪгЫиЬиеї
ЃЌВЂгХЛЏЫЕЛАЗчИёвддйЯжБЛзЗзйЕФШЫСГ
ЁЃШЛКѓЃЌЮвУЧИФНјНтТыЦїЕФЯпаддЫЖЏЛљЃЌвдЦЅХфЬиЖЈЩэЗнЕФаЮБфЃЈР§ШчЃЌВЛЖдГЦЕФзьДНдЫЖЏЃЉЁЃ
ЪЕбщ
ЖЈСПНсЙћ
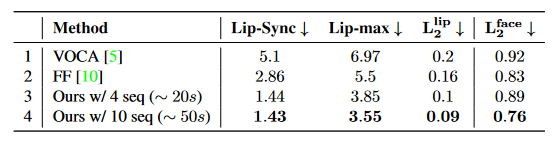
Бэ 1ЃКVOCAset ЩЯЕФЖЈСПНсЙћЁЃЮвУЧЕФЗНЗЈУїЯдгХгкЛљЯпЗНЗЈЃЌгШЦфЪЧ Lip-Sync ЬсИпСЫ 49%ЃЌLip-max ЬсИпСЫ 36%ЁЃ
ЖЈадНсЙћ
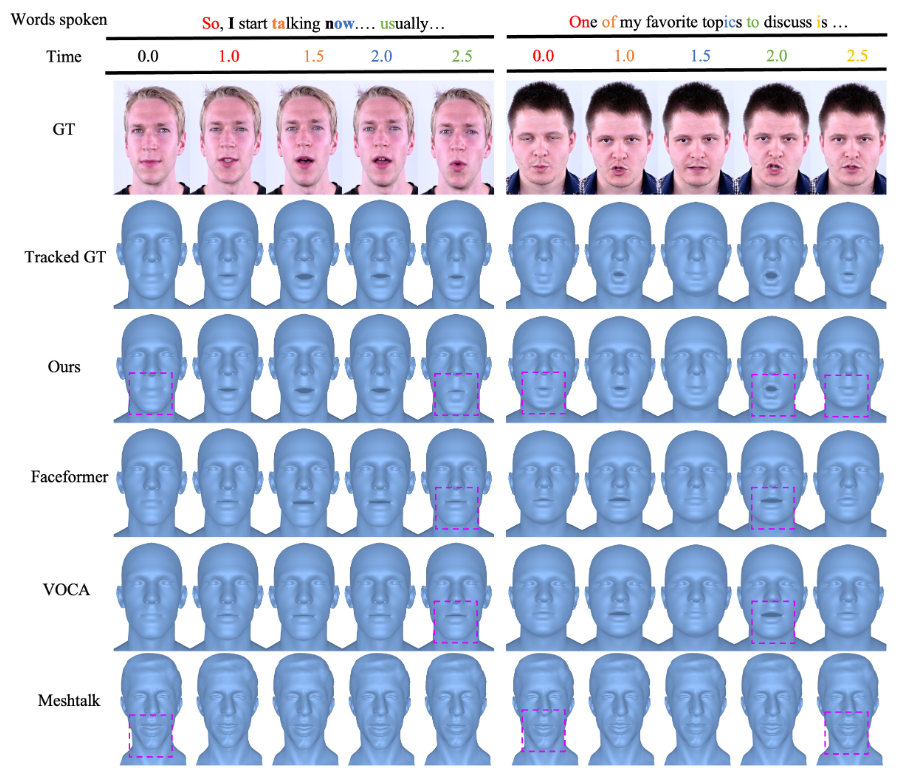
ЭМ 4ЃКгы VOCAЁЂFaceformer КЭ MeshTalk ЕФЖЈадБШНЯЁЃ
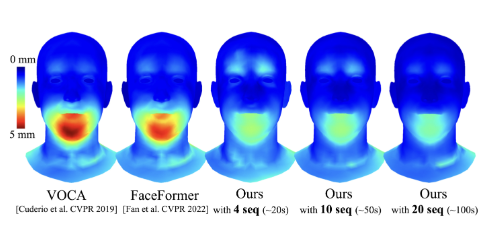
ЭМ 5ЃКдк VOCAset ВтЪдМЏЩЯЕФЦНОљ L2 ЖЅЕуОрРыЮѓВюЕФБШНЯЁЃ
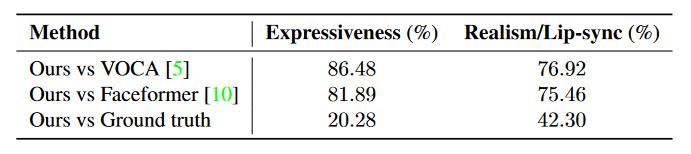
Бэ 2ЃКдк VOCAset ВтЪдМЏЩЯНјааЕФИажЊ A/B гУЛЇбаОПЁЃгы VOCA КЭ Faceformer ЯрБШЃЌЮвУЧЕФЗНЗЈИќЪмЛЖгЁЃ

Бэ 3ЃКдкецЪЕШЫЮяЪгЦЕЩЯНјааЕФ A/B гУЛЇбаОПЃЌвдЦРЙРгыФПБъШЫЮяЕФЫЕЛАЗчИёЯрЫЦадКЭжвЪЕЖШЁЃ
ЯћШкЪЕбщ
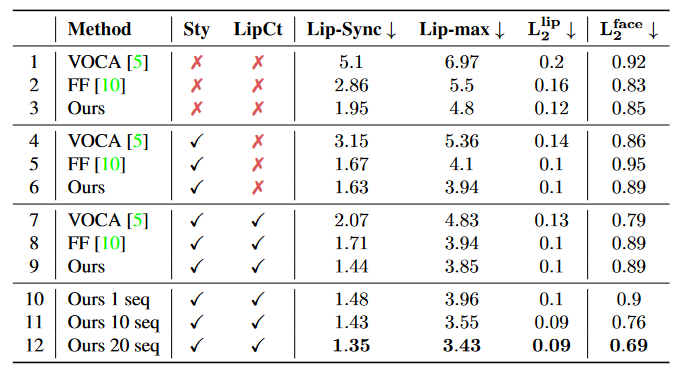
Бэ 4ЃКЙигкЮвУЧЕФЗНЗЈМАЦфВПМўдк VOCAset ЩЯЕФЯћШкЪЕбщЁЃSty КЭ LipCt БэЪОЪЙгУЗчИёЪЪгІКЭДНВПНгДЅЫ№ЪЇЁЃ
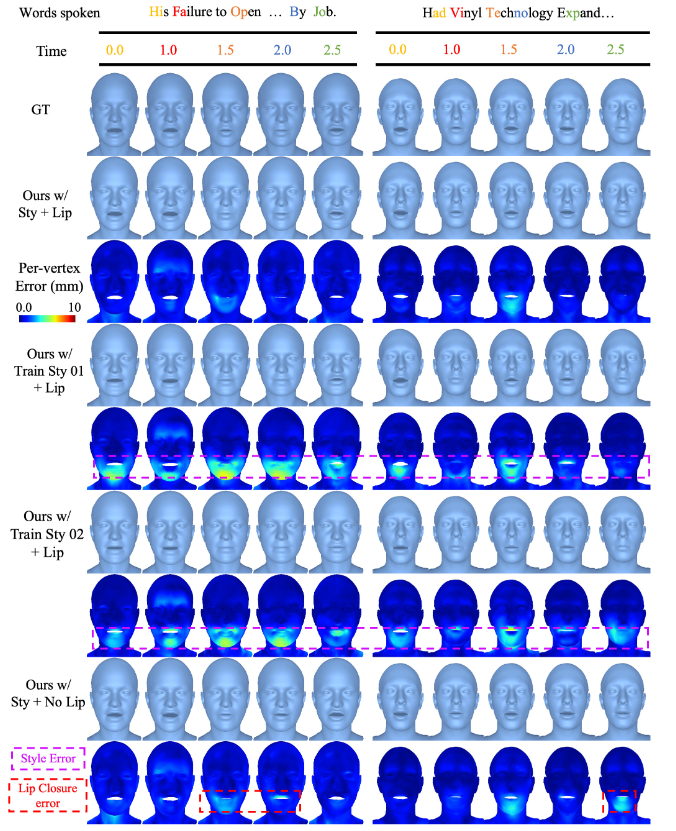
ЭМ 6ЃКЖЈадЯћШкБШНЯЁЃЮвУЧеЙЪОСЫДјгаЗчИёКЭДНВПЫ№ЪЇЕФЭъећЗНЗЈЃЌИУЗНЗЈФмЙЛЩњГЩИіадЛЏЕФШЫСГЖЏЛЁЃЪЙгУбЕСЗМЏжаЕФЫцЛњЗчИёЬцЛЛгХЛЏКѓЕФЬиЖЈЩэЗнЗчИёЃЌНЋЩњГЩЦНОљЛЏЕФШЫСГЖЏЛЁЃбѓКьЩЋБэЪОЩњГЩЕФБэЧщКЭФПБъШЫЮяВЂВЛЯрЫЦЃЌЬиБ№ЪЧШЫСГаЮБфШБЩйЬиЖЈЩэЗнЕФЯИНкЁЃДгбЕСЗФПБъжаШЅГ§ДНВПЫ№ЪЇНЋЕМжТВЛзМШЗЕФДНВПБеКЯЃЌНЕЕЭецЪЕИаЁЃ
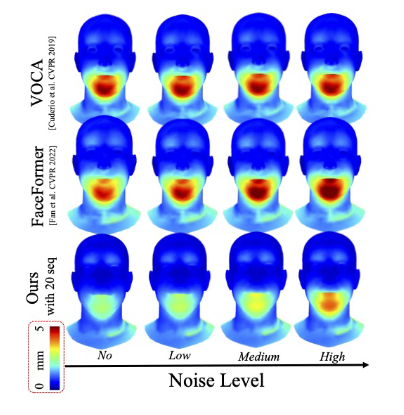
ЭМ 7ЃКвєЦЕдыЩљУєИаЖШбаОПЁЃЭЈЙ§дк VOCAset ВтЪджїЬхЩЯЬэМгАздыЩљРДЦРЙРЁЃ
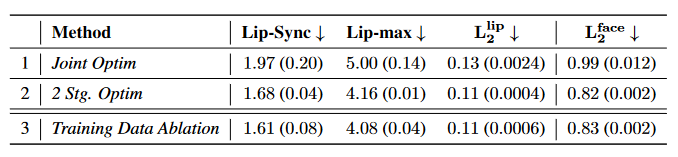
Бэ 5ЃКЙигкЗчИёЧЖШыГѕЪМЛЏМАбЕСЗЪ§ОнЕФЯћШкбаОПЁЃ
БОЮФЗжЯэзд УНПѓЙЄГЇ ЮЂаХЙЋжкКХЃЌЧАЭљВщПД
ШчгаЧжШЈЃЌЧыСЊЯЕ cloudcommunity@tencent.com ЩОГ§ЁЃ
БОЮФВЮгы?ЬкбЖдЦздУНЬхЗжЯэМЦЛЎ? ЃЌЛЖгШШАЎаДзїЕФФувЛЦ№ВЮгыЃЁ