推荐一家还不错的互联网中厂。

携程 Java 后端面经(详细)
多久开始学Java的?
我是从大一下学期开始学习 Java 的,当时已经学完了 C语言,但苦于 C语言没有很好的应用方向,就开始学习 Java 了,因为我了解到,绝大多数的互联网公司后端服务都是用 Java 开发的,另外就是学习资料也非常丰富,就业岗位和薪资待遇都比较理想。
于是就想着一边学,一边实战,后来就有了技术派这个社区系统。
这样我就可以作为创作者把自己在学习 Java 过程中的经验心得通过文章/教程的形式发布出来,同时读者还可以通过评论、点赞、收藏的形式和我进行互动。
后面我又接触到了 Spring Boot、MyBatis-Plus、MySQL、Redis、ElasticSearch、MongoDB、Docker、RabbitMQ 等一些 Java 技术栈,让我的编程能力也有了很大的提升。
ConcurrentHashMap 怎么保证线程安全?1.7 与 1.8 的差别
ConcurrentHashMap 在 JDK 7 时采用的是分段锁机制(Segment Locking),整个 Map 被分为若干段,每个段都可以独立地加锁。因此,不同的线程可以同时操作不同的段,从而实现并发访问。
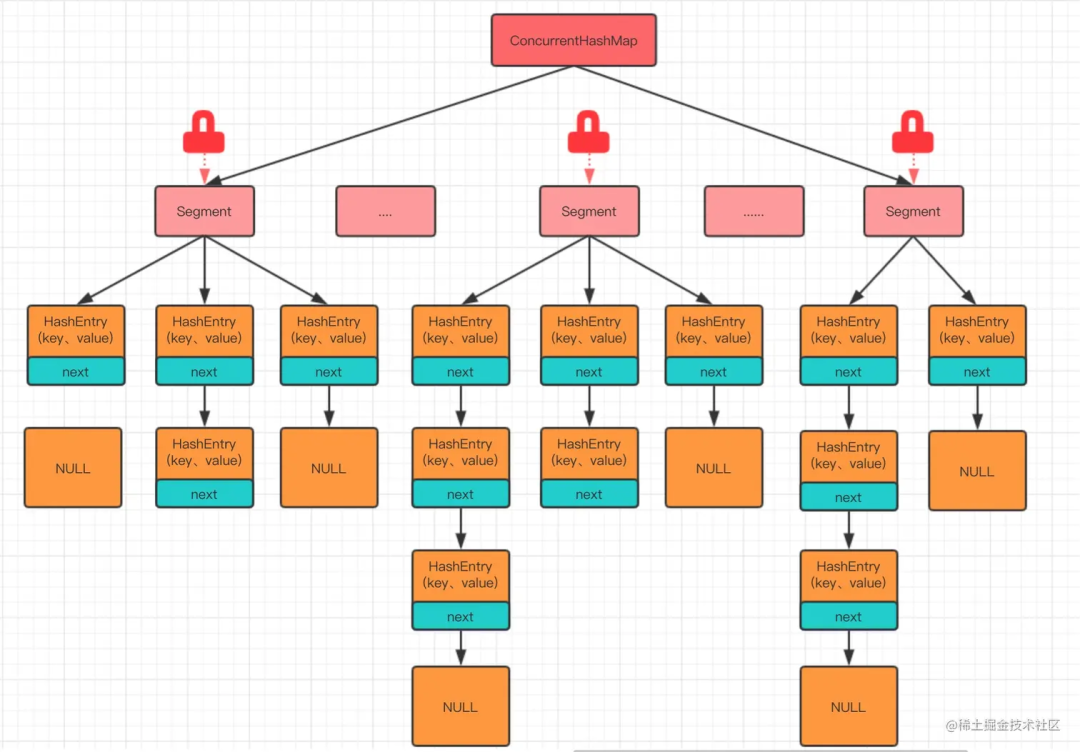
初念初恋:JDK 7 ConcurrentHashMap
在 JDK 8 及以上版本中,ConcurrentHashMap 的实现进行了优化,不再使用分段锁,而是使用了一种更加精细化的锁——桶锁,以及 CAS 无锁算法。每个桶(Node 数组的每个元素)都可以独立地加锁,从而实现更高级别的并发访问。
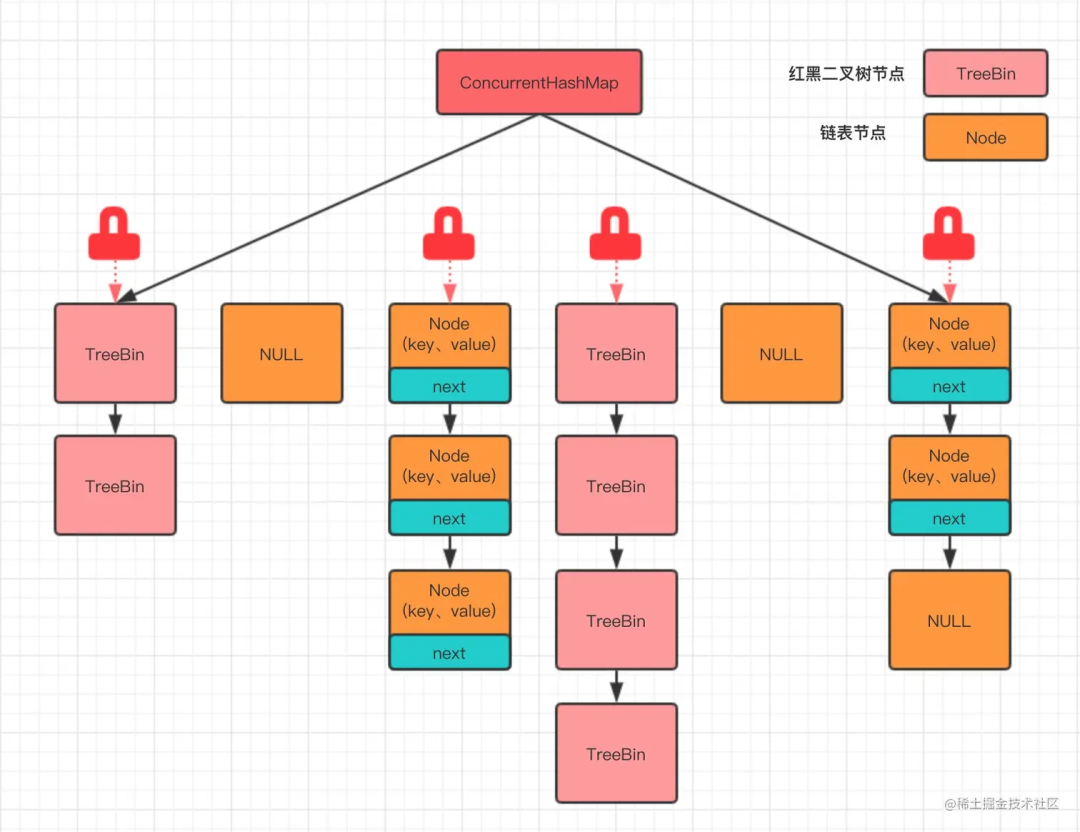
初念初恋:JDK 8 ConcurrentHashMap
同时,对于读操作,通常不需要加锁,可以直接读取,因为 ConcurrentHashMap 内部使用了 volatile 变量来保证内存可见性。
对于写操作,ConcurrentHashMap 使用 CAS 操作来实现无锁的更新,这是一种乐观锁的实现,因为它假设没有冲突发生,在实际更新数据时才检查是否有其他线程在尝试修改数据,如果有,采用悲观的锁策略,如 synchronized 代码块来保证数据的一致性。
讲一讲你对线程池的理解,并讲一讲使用的场景
线程池,简单来说,就是一个管理线程的池子。
三分恶面渣逆袭:管理线程的池子
①、频繁地创建和销毁线程会消耗系统资源,线程池能够复用已创建的线程。
②、提高响应速度,当任务到达时,任务可以不需要等待线程创建就立即执行。
③、线程池支持定时执行、周期性执行、单线程执行和并发数控制等功能。
为了最大程度利用 CPU 的多核性能,并行运算的能力是不可获取的,通过线程池来管理线程是一个非常基础的操作。
①、快速响应用户请求
当用户发起一个实时请求,服务器需要快速响应,此时如果每次请求都直接创建一个线程,那么线程的创建和销毁会消耗大量的系统资源。
使用线程池,可以预先创建一定数量的线程,当用户请求到来时,直接从线程池中获取一个空闲线程,执行用户请求,执行完毕后,线程不销毁,而是继续保留在线程池中,等待下一个请求。
注意:这种场景下需要调高 corePoolSize 和 maxPoolSize,尽可能多创建线程,避免使用队列去缓存任务。
比如说,在技术派实战项目中,当用户请求首页时,就使用了线程池去加载首页的热门文章、置顶文章、侧边栏、用户登录信息等。
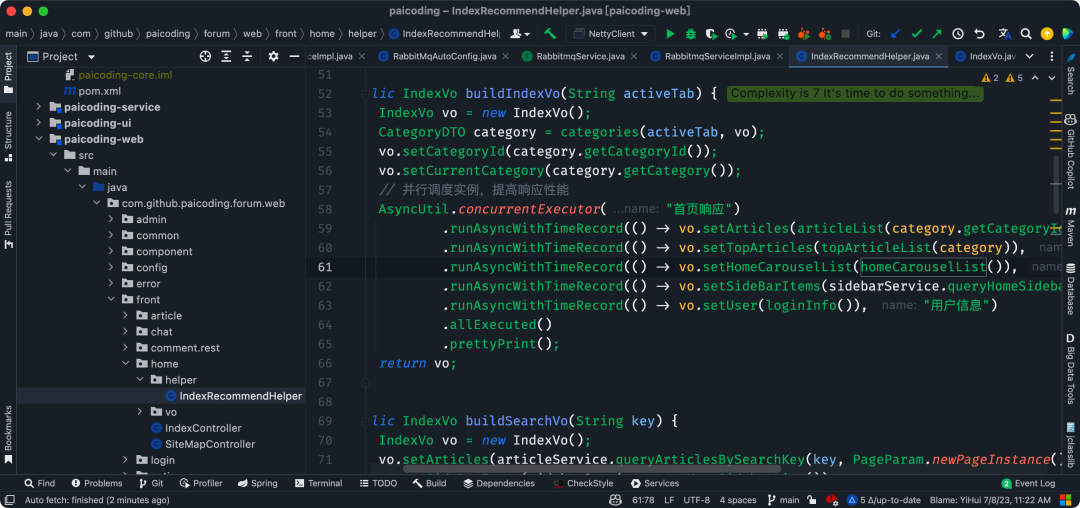
技术派源码截图
我们封装了一个异步类 AsyncUtil,内部的静态类 CompletableFutureBridge 是通过 CompletableFuture 实现的,其中的 runAsyncWithTimeRecord() 方法就是使用线程池去执行任务的。
public CompletableFutureBridge runAsyncWithTimeRecord(Runnable run, String name) {
return runAsyncWithTimeRecord(run, name, executorService);
}
其中线程池的初始化中,corePoolSize 为 CPU 核心数的两倍,因为技术派中的大多数任务都是 IO 密集型的,maxPoolSize 设置为 50,是一个比较理想的值,尤其是在本地环境中;阻塞队列为 SynchronousQueue,这意味着任务被创建后直接提交给等待的线程处理,而不是放入队列中。
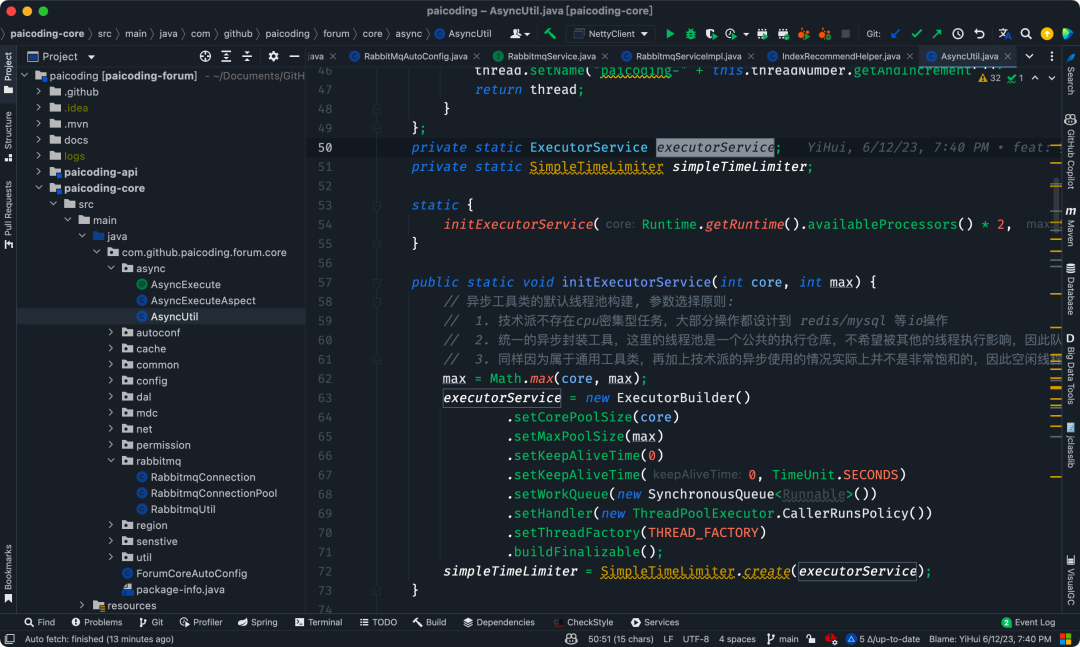
技术派源码:AsyncUtil
②、快速处理批量任务
这种场景也需要处理大量的任务,但可能不需要立即响应,这时候就应该设置队列去缓冲任务,corePoolSize 不需要设置得太高,避免线程上下文切换引起的频繁切换问题。
单例模式,如何线程安全
单例模式(Singleton Pattern)是一种创建型设计模式,它确保一个类只有一个实例,并提供一个全局访问点来获取该实例。单例模式主要用于控制对某些共享资源的访问,例如配置管理器、连接池、线程池、日志对象等。
refactoringguru.cn:单例模式
懒汉式单例(Lazy Initialization)在实际使用时才创建实例,“确实懒”(?)。这种实现方式需要考虑线程安全问题,因此一般会带上 synchronized 关键字。
public class Singleton {
private static Singleton instance;
private Singleton() {}
public static synchronized Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
双重检查锁定(Double-Checked Locking)结合了懒汉式的延迟加载和线程安全,同时又减少了同步的开销,主要是用 synchronized 同步代码块来替代同步方法。
public class Singleton {
private static volatile Singleton instance;
private Singleton() {}
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
当 instance 创建后,再次调用 getInstance 方法时,不会进入同步代码块,从而提高了性能。
在 instance 前加上 volatile 关键字,可以防止指令重排,因为 instance = new Singleton() 并不是一个原子操作,可能会被重排序,导致其他线程获取到未初始化完成的实例。
使用枚举(Enum)实现单例是最简单的方式,不仅不需要考虑线程同步问题,还能防止反射攻击和序列化问题。
public enum Singleton {
INSTANCE;
// 可以添加实例方法
}
有哪些垃圾回收器,选一个讲一下垃圾回收的流程
就目前来说,JVM 的垃圾收集器主要分为两大类:分代收集器和分区收集器,分代收集器的代表是 CMS,分区收集器的代表是 G1 和 ZGC。
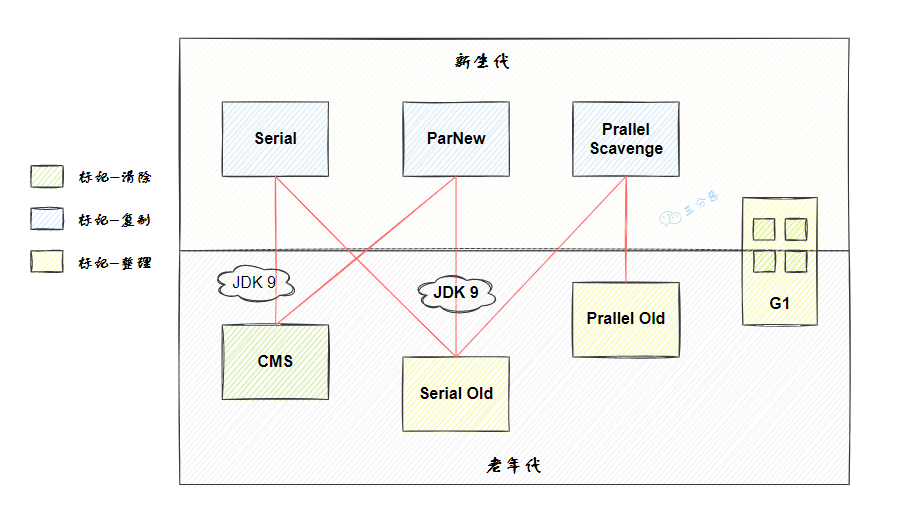
三分恶面渣逆袭:HotSpot虚拟机垃圾收集器
说说 CMS 收集器?
以获取最短回收停顿时间为目标,采用“标记-清除”算法,分 4 大步进行垃圾收集,其中初始标记和重新标记会 STW,JDK 1.5 时引入,JDK9 被标记弃用,JDK14 被移除。
小潘:CMS
说说 Garbage First 收集器?
G1(Garbage-First Garbage Collector)在 JDK 1.7 时引入,在 JDK 9 时取代 CMS 成为了默认的垃圾收集器。G1 有五个属性:分代、增量、并行、标记整理、STW。
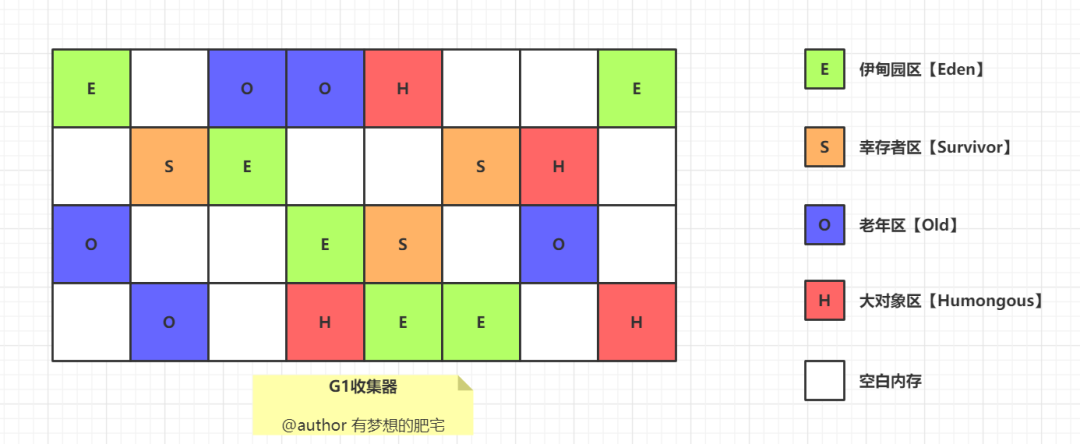
有梦想的肥宅:G1
说说 ZGC 收集器?
ZGC 是 JDK 11 时引入的一款低延迟的垃圾收集器,它的目标是在不超过 10ms 的停顿时间内,为堆大小达到 16TB 的应用提供一种高吞吐量的垃圾收集器。
ZGC 的两个关键技术:指针染色和读屏障,不仅应用在并发转移阶段,还应用在并发标记阶段:将对象设置为已标记,传统的垃圾回收器需要进行一次内存访问,并将对象存活信息放在对象头中;而在 ZGC 中,只需要设置指针地址的第 42-45 位即可,并且因为是寄存器访问,所以速度比访问内存更快。
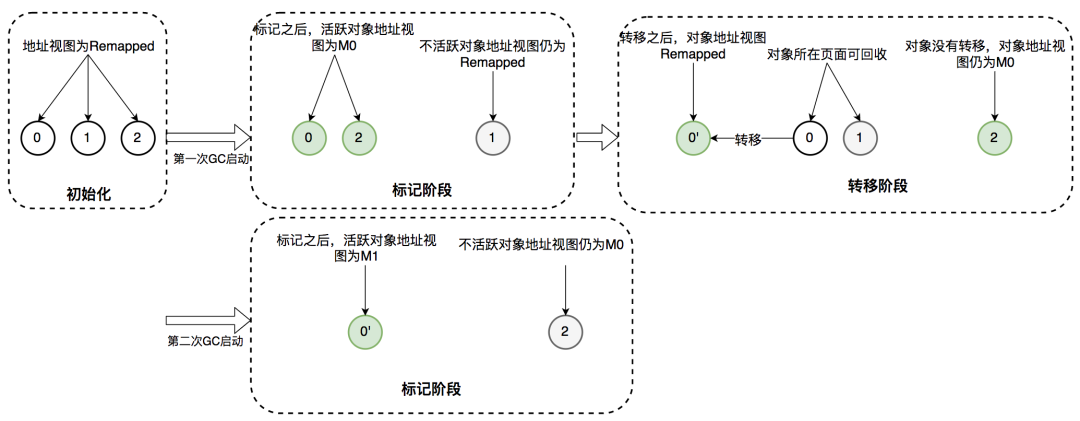
得物技术
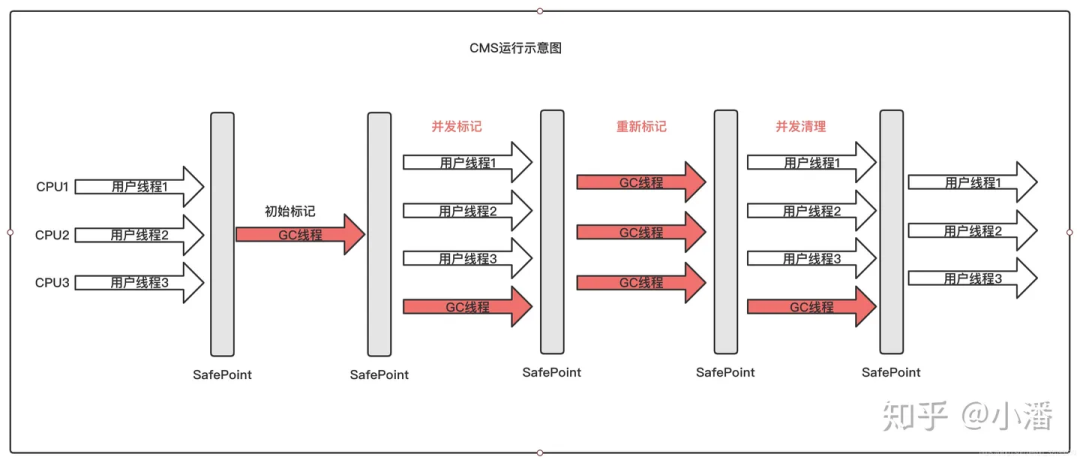
那我就以 CMS 为例来说说垃圾回收的流程吧
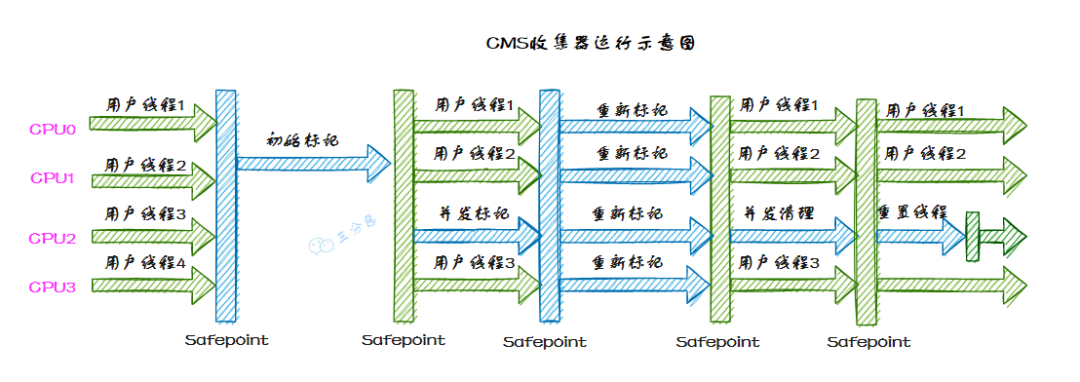
三分恶面渣逆袭:Concurrent Mark Sweep收集器运行示意图
CMS(Concurrent Mark Sweep)分 4 大步进行垃圾收集:
- 初始标记(Initial Mark):标记所有从 GC Roots 直接可达的对象,这个阶段需要 STW,但速度很快。
- 并发标记(Concurrent Mark):从初始标记的对象出发,遍历所有对象,标记所有可达的对象。这个阶段是并发进行的,STW。
- 重新标记(Remark):完成剩余的标记工作,包括处理并发阶段遗留下来的少量变动,这个阶段通常需要短暂的 STW 停顿。
- 并发清除(Concurrent Sweep):清除未被标记的对象,回收它们占用的内存空间。
讲一讲 MySQL 的索引,如何优化SQL?
MySQL 的索引可以显著提高查询的性能,可以从三个不同的维度对索引进行分类(功能、数据结构、存储位置):
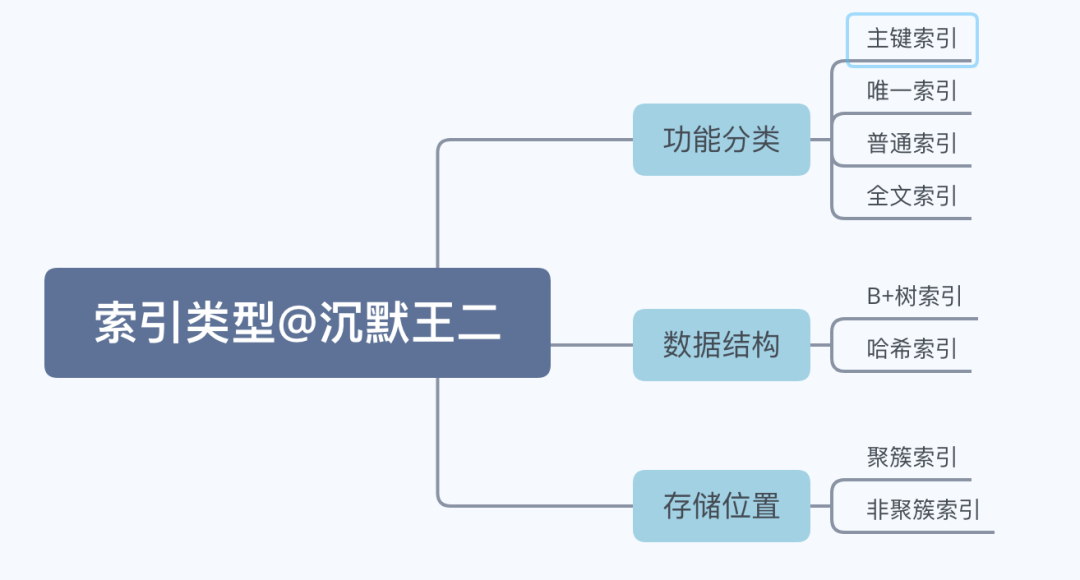
我这里就从数据结构上来讲一讲吧
①、B+树索引:最常见的索引类型,一种将索引值按照一定的算法,存入一个树形的数据结构中(二叉树),每次查询都从树的根节点开始,一次遍历叶子节点,找到对应的值。查询效率是 O(logN)。
也是 InnoDB 存储引擎的默认索引类型。
B+ 树是 B 树的升级版,B+ 树中的非叶子节点都不存储数据,只存储索引。叶子节点中存储了所有的数据,并且构成了一个从小到大的有序双向链表,使得在完成一次树的遍历定位到范围查询的起点后,可以直接通过叶子节点间的指针顺序访问整个查询范围内的所有记录,而无需对树进行多次遍历。这在处理大范围的查询时特别高效。
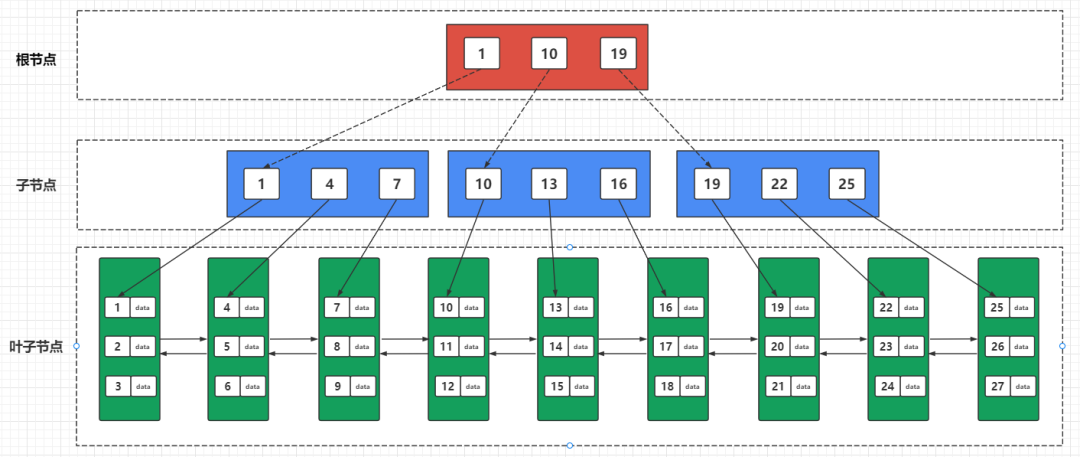
一颗剽悍的种子:B+树的结构
因为 B+ 树是 InnoDB 的默认索引类型,所以创建 B+ 树的时候不需要指定索引类型。
CREATE TABLE example_btree (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255),
INDEX name_index (name)
) ENGINE=InnoDB;
②、Hash 索引:基于哈希表的索引,查询效率可以达到 O(1),但是只适合 = 和 in 查询,不适合范围查询。
Hash 索引在原理上和 Java 中的 HashMap 类似,当发生哈希冲突的时候也是通过拉链法来解决。
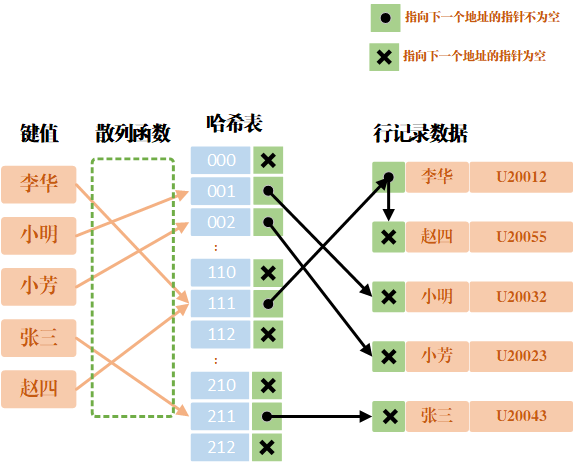
业余码农:哈希索引
可以通过下面的语句创建哈希索引:
CREATE TABLE example_hash (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255),
UNIQUE HASH (name)
) ENGINE=MEMORY;
注意,我们这里创建的是 MEMORY 存储引擎,InnoDB 并不提供直接创建哈希索引的选项,因为 B+ 树索引能够很好地支持范围查询和等值查询,满足了大多数数据库操作的需要。
我在进行 SQL 优化的时候,主要通过以下几个方面进行优化:
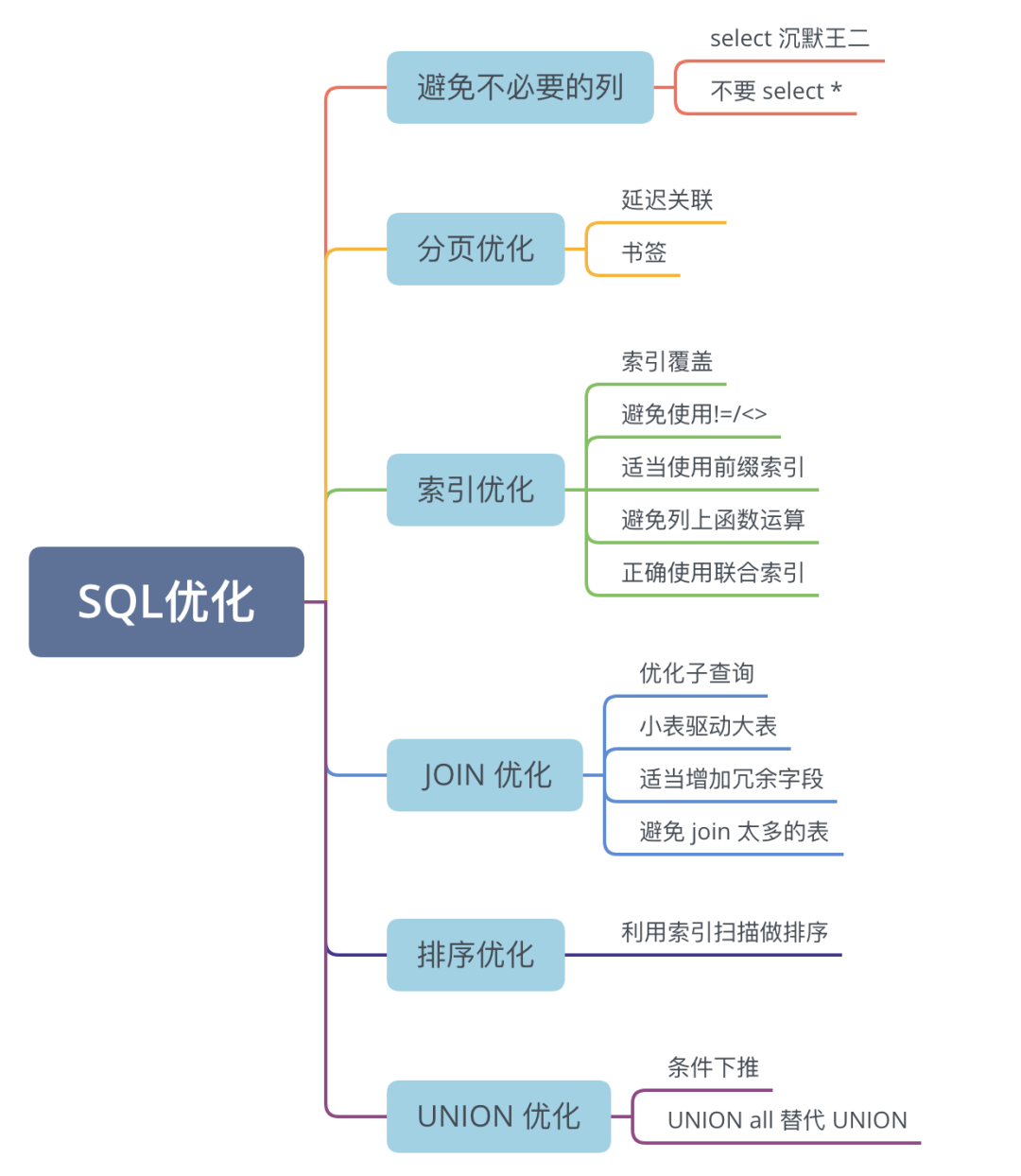
沉默王二:SQL 优化
就拿索引优化为例吧。
正确地使用索引可以显著减少 SQL 的查询时间,通常可以从索引覆盖、避免使用 != 或者 <> 操作符、适当使用前缀索引、避免列上函数运算、正确使用联合索引等方面进行优化。
①、利用覆盖索引
使用非主键索引查询数据时需要回表,但如果索引的叶节点中已经包含要查询的字段,那就不会再回表查询了,这就叫覆盖索引。
举个例子,现在要从 test 表中查询 city 为上海的 name 字段。
select name from test where city='上海'
如果仅在 city 字段上添加索引,那么这条查询语句会先通过索引找到 city 为上海的行,然后再回表查询 name 字段,这就是回表查询。
为了避免回表查询,可以在 city 和 name 字段上建立联合索引,这样查询结果就可以直接从索引中获取。
alter table test add index index1(city,name);
②、避免使用 != 或者 <> 操作符
!= 或者 <> 操作符会导致 MySQL 无法使用索引,从而导致全表扫描。
例如,可以把column<>'aaa',改成column>'aaa' or column<'aaa',就可以使用索引了。
优化策略就是尽可能使用 =、>、<、BETWEEN等操作符,它们能够更好地利用索引。
③、适当使用前缀索引
适当使用前缀索引可以降低索引的空间占用,提高索引的查询效率。
比如,邮箱的后缀一般都是固定的@xxx.com,那么类似这种后面几位为固定值的字段就非常适合定义为前缀索引:
alter table test add index index2(email(6));
需要注意的是,MySQL 无法利用前缀索引做 order by 和 group by 操作。
④、避免列上使用函数
在 where 子句中直接对列使用函数会导致索引失效,因为数据库需要对每行的列应用函数后再进行比较,无法直接利用索引。
select name from test where date_format(create_time,'%Y-%m-%d')='2021-01-01';
可以改成:
select name from test where create_time>='2021-01-01 00:00:00' and create_time<'2021-01-02 00:00:00';
通过日期的范围查询,而不是在列上使用函数,可以利用 create_time 上的索引。
⑤、正确使用联合索引
正确地使用联合索引可以极大地提高查询性能,联合索引的创建应遵循最左前缀原则,即索引的顺序应根据列在查询中的使用频率和重要性来安排。
select * from messages where sender_id=1 and receiver_id=2 and is_read=0;
那就可以为 sender_id、receiver_id 和 is_read 这三个字段创建联合索引,但是要注意索引的顺序,应该按照查询中的字段顺序来创建索引。
alter table messages add index index3(sender_id,receiver_id,is_read);
Spring IoC 的设计模式,AOP 的设计模式
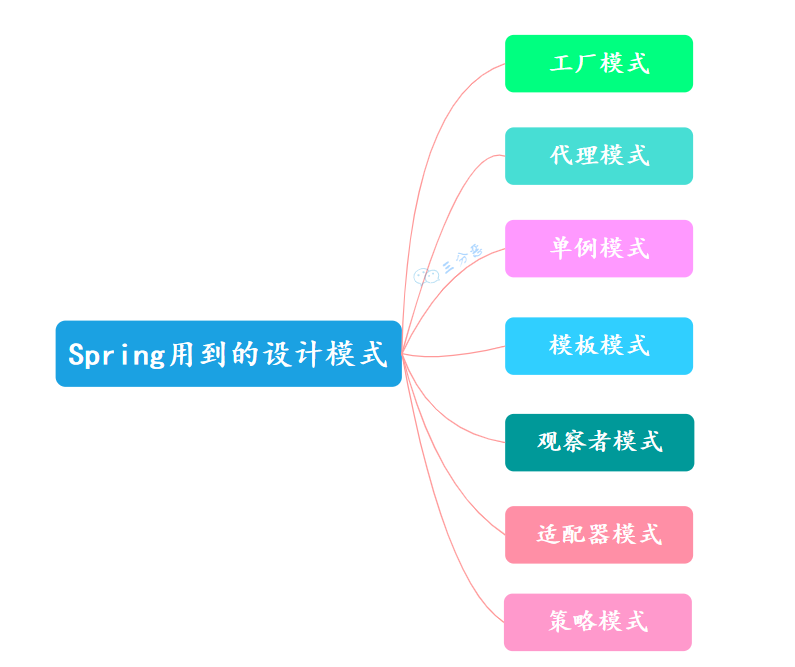
三分恶面渣逆袭:Spring中用到的设计模式
Spring 框架中用了蛮多设计模式的:
①、工厂模式:IoC 容器本身可以看作是一个巨大的工厂,负责创建和管理 Bean 的生命周期和依赖关系。
像 BeanFactory 和 ApplicationContext 接口都提供了工厂模式的实现,负责实例化、配置和组装 Bean。
②、代理模式:AOP 的实现就是基于代理模式的,如果配置了事务管理,Spring 会使用代理模式创建一个连接数据库的代理对象,来进行事务管理。
参考链接
- 三分恶的面渣逆袭:https://javabetter.cn/sidebar/sanfene/nixi.html
- 二哥的 Java 进阶之路:https://javabetter.cn