双塔模型的瓶颈究竟在哪?

作者 | Maple小七 整理 | NewBeeNLP
开放域问答系统的泛化性和鲁棒性一直是一个业界难题,其中位于最顶层的稠密检索模型(Dense Retriever)常常被诟病其OOD泛化能力不如传统的BM25算法。
今天分享一篇来自Google的工作,其实稠密检索模型的泛化能力并不是天生就差,它只是需要更强大的编码器和更多更好的训练数据而已。
- Large Dual Encoders Are Generalizable Retrievers
- https://arxiv.org/abs/2112.07899

自BEIR基准数据集提出以来,稠密检索模型的域外泛化能力得到了广泛的关注。目前学术界的一种普遍的看法是,稠密检索模型的性能瓶颈主要在于query和doc仅靠单个稠密向量的点积做交互,而单个向量的表示能力是有限的,很难依靠简单的点积来捕捉query和doc的语义相关性,因此极大地限制了模型的泛化能力,导致模型的域外泛化性能不如传统的BM25。
为了克服query和doc的交互瓶颈,一种普遍的做法是构建多向量表示模型,从而引入轻量级的交互算子,比如ColBERT、ME-BERT、Poly-encoder、COIL等。但这些模型通常会带来更大的查询时延和更大的存储开销。
但是,单向量表示模型的性能瓶颈真的完全在于简单的点积交互吗?「如果我们固定表示向量的维度,增大编码模型的尺寸,模型性能是不是也会像大规模预训练模型那样服从Scaling Law呢?」
为了回答这个问题,作者在固定稠密向量维度(
)不变的条件下,采用不同尺寸的T5-encoder(base、large、3B、11B)训练稠密检索模型。实验结果表明,「稠密检索模型的瓶颈并不完全在于单个向量的表示能力不足,编码器的能力也会在很大程度上影响模型的泛化能力。」
本文提出的GTR模型(Generalizable T5-based dense Retriever)在BEIR基准上大幅超越了当前所有的稀疏/稠密检索模型,取得了SOTA结果。

Generalizable T5 Retriever
接下来简要地介绍GTR模型的训练过程,给定训练数据集
,我们首先用共享参数的T5-encoder分别对
和
编码,然后使用平均池化获取向量表示,并计算批内负采样的交叉熵损失:
其中
为余弦相似度,
为softmax的温度系数。当有额外的困难负样本
可用时,我们可以将其加入到分母部分:
另外,我们还可以计算反向损失:
最终求得的损失为双向损失
。本文采用的参数设置为
,
。
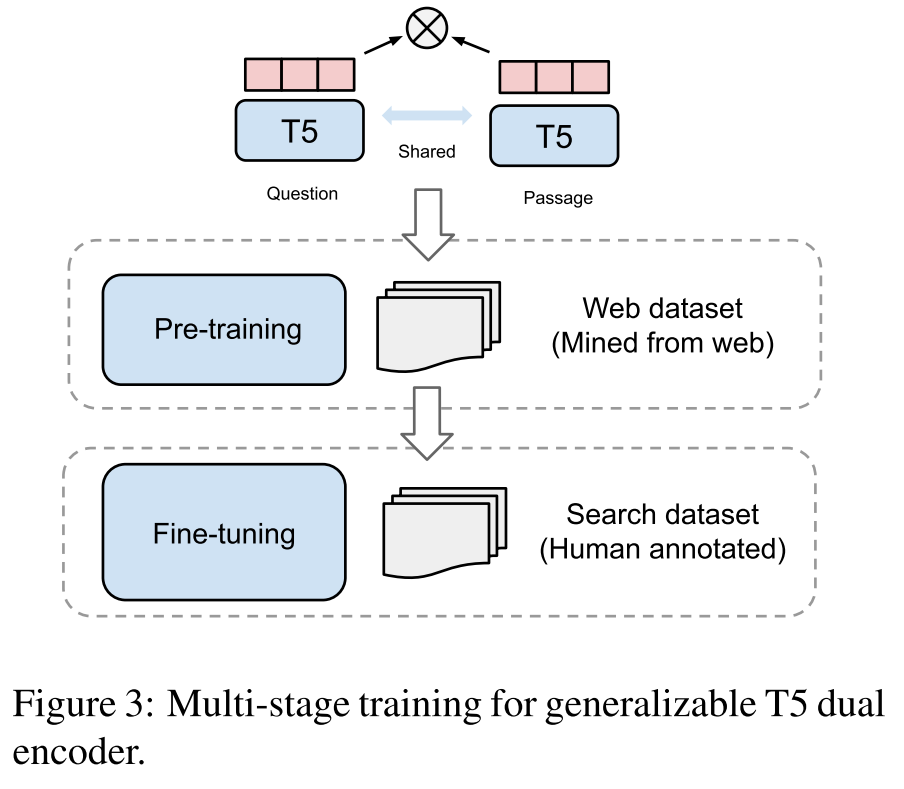
另外,为了有效地利用大模型的容量优势,训练出泛化性能更好的模型,作者还设计了一个预训练+微调的训练策略。
如上图所示,在预训练阶段,作者从Reddit、Stack-Overflow等网站爬取了20亿个社区问答对数据来为模型提供丰富的语义相关信息,这部分数据通常易于收集,但噪声很大,因此在微调阶段,模型将在人工标注的检索数据集(MS-MARCO)上进一步学习更好的语义匹配模式,这样就得到了作者提出的GTR模型。
Results
作者在BEIR基准上测试了GTR模型的零样本域外泛化能力,其中BEIR包含了来自9个领域的18个信息检索任务。实验结果表明,尽管query和doc仅依靠点积交互,但增大编码器的尺寸依旧能够较大幅度地提升稠密检索模型的域内和域外泛化能力,超越了之前所有的稀疏和稠密检索模型。

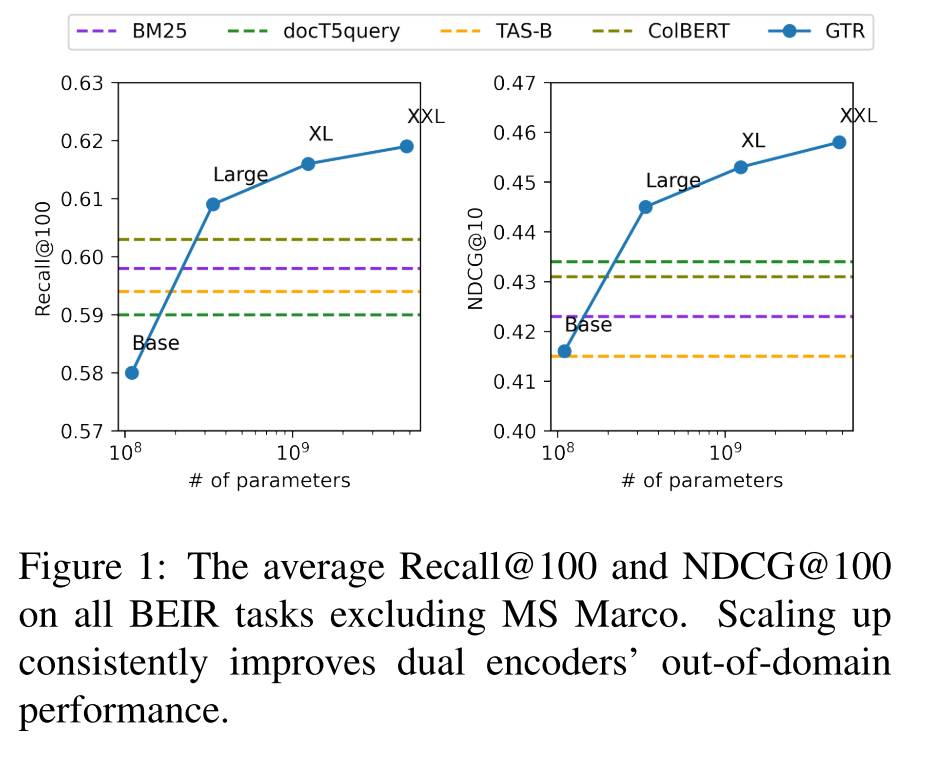
Data efficiency for large retrievers
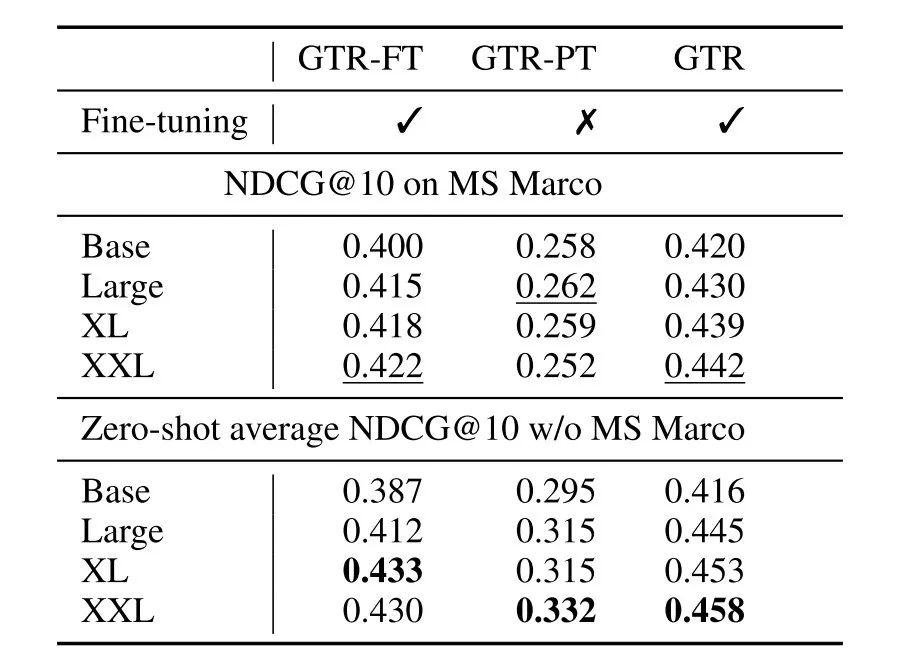
稠密检索模型的训练通常是data-hungry的,因此样本效率也是一个重要的研究方向。而作者发现使用大模型除了能提指标,同时也提升了样本效率。作者尝试仅使用10%的训练数据来微调模型,并对比了不进行预训练的模型(GTR-FT)和进行预训练的模型(GTR),结果如下表所示。
神奇的是,「虽然仅使用10%的训练数据会导致模型的域内泛化能力下降,但却提升了模型的域外泛化能力」,这表明预训练能够同时提升模型的域内和域外泛化能力,也表明MS MARCO的数据分布并不能代表通用领域(general domain)的分布,使用全量的MS MARCO数据训练模型会导致模型对MS MARCO的数据分布产生轻微的过拟合。

Ablation Study and Analysis
接下来,作者也对模型大小和训练策略进行了消融实验,结果如下表所示。一方面,随着模型的增大,除了GTR-PT(仅预训练)以外,其余模型的性能都变得越来越好;另一方面,微调对模型的域外泛化能力也有较大的影响,如果没有在MS MARCO数据集上微调,模型在BEIR基准上的NDCG@10会差10个点,说明高质量的人工标注数据依旧是很必要的。
另外作者也对比了模型分别在MS MARCO和在Natural Questions上微调的表现。如下表所示,由于NQ数据集只包含了Wikipedia的文档,且数据量级更小,因此训练出来的模型域外泛化性能更差,这也表明训练数据的通用性也是很重要的。

Document length vs model capacity
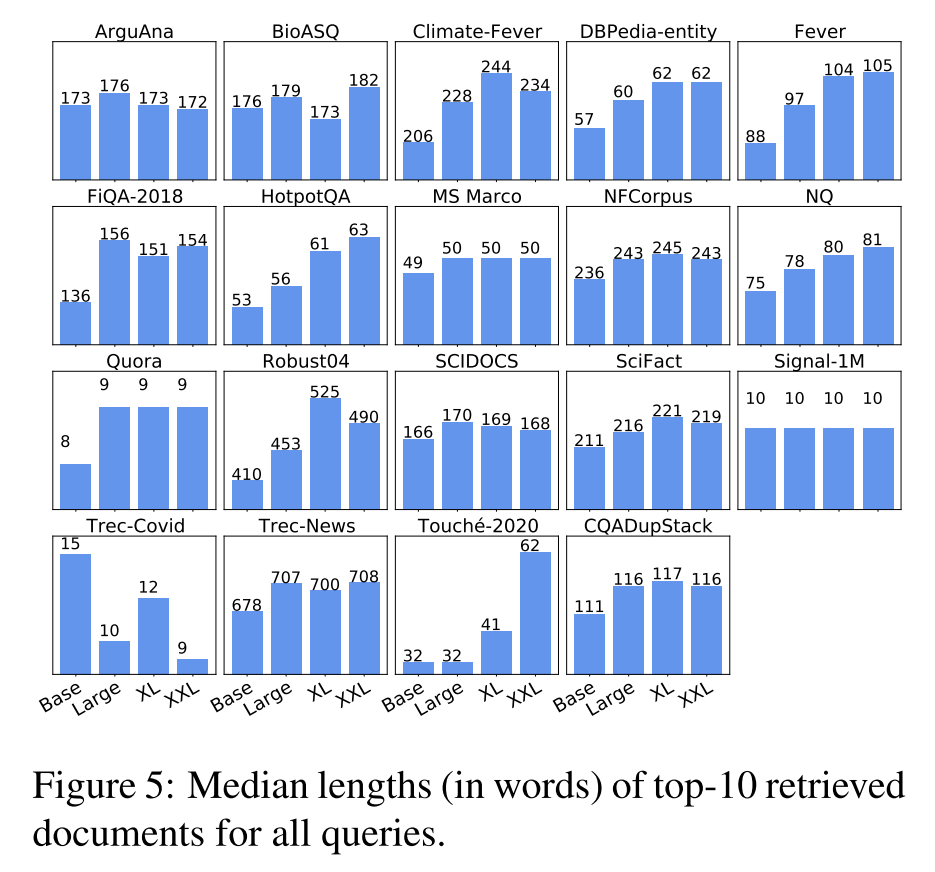
BEIR原文指出,使用余弦相似度度量训练的模型会偏向于检索出短文档,而使用点积相似度训练的模型会偏向于检索出长文档,作者想要验证当模型尺寸变大之后,这一论点是否还成立,因此作者在BEIR基准上计算了召回Top-10文档的平均长度,如下图所示。
可以看到,当模型尺寸变大时,某些数据集的平均召回长度会变长,尤其是在Touche-2020这个测试集上,GTR-XXL的平均召回长度几乎是GTR-Base的两倍,而该数据集整个语料库的平均文档长度更接近于GTR-XXL的平均召回长度,因此当模型尺寸变大之后,模型能够生成更优质的文档编码,上面提到的长度偏差问题也许就没那么严重了。
Discussion
谷歌的这篇论文再一次指出了当前NLP领域反复出现的一个主题:虽然深度学习是一项很棒的技术,但它也许永远无法解决域外泛化/组合泛化/因果推理问题,而目前唯一有效的办法似乎只有遵循Scaling Law,每当我们将模型/数据扩大十倍以上,上述问题均能得到明显的缓解。本篇论文的结论也一样,更多的数据和更大的模型总能产生更好的结果,修改模型结构或损失函数只能算是锦上添花的trick。