精调模型,获得自己的翻译姬
原创精调模型,获得自己的翻译姬
原创
用户1322359
发布于 2024-04-29 11:17:16
发布于 2024-04-29 11:17:16
- 随着大模型技术的发展,个人/业务获取自己专属的翻译模型,精调专属词汇已经变的越来越容易,本文旨在记录精调并使用模型步骤以及遇到的坑
- 模型选型
选取了一个专门用作翻译的小模型:MarianMT
https://huggingface.co/docs/transformers/main/en/model_doc/marian
由于本次只需要中译英,所以这种小模型已经够了
https://huggingface.co/Helsinki-NLP/opus-mt-zh-en
- 使用模型
from transformers import MarianMTModel, MarianTokenizer
tokenizer = MarianTokenizer.from_pretrained("Helsinki-NLP/opus-mt-zh-en")
model = MarianMTModel.from_pretrained(Helsinki-NLP/opus-mt-zh-en")
text="你好"
input_ids = tokenizer(text, return_tensors="pt",padding=True)
outputs = model.generate(**input_ids)
translated_text_from_text = tokenizer.decode(outputs[0],skip_special_tokens=True)
print(translated_text_from_text)首次执行时会下载模型到本地,此时模型还是未经过精调过的
- 精调模型
- 确认transforms版本:
https://huggingface.co/Helsinki-NLP/opus-mt-zh-en/blob/main/config.json - git clone 对应版本的transforms
git clone --depth 1 --branch v4.22.0 https://github.com/huggingface/transformers.git
- 安装transforms
pip install -e .
python setup.py install- 修改精调配置
修改文件
examples/legacy/seq2seq/train_distil_marian_enro.sh
export WANDB_PROJECT=distil-marian
export BS=64
export GAS=1
#export m=/mnt/models/models/opus-mt-zh-en #如果不是重新开始精调,而是接着精调,修改这个模型位置
export m=Helsinki-NLP/opus-mt-zh-en
export MAX_LEN=128
export MAX_TGT_LEN=128
export DATA_DIR=./test_data/zh_eng # 这是用于精调的数据位置
torchrun finetune_trainer.py \
--tokenizer_name $m --model_name_or_path $m \
--data_dir $DATA_DIR \
--output_dir opus-mt-zh-en --overwrite_output_dir \
--learning_rate=3e-4 \
--warmup_steps 500 --sortish_sampler \
--fp16 \
--gradient_accumulation_steps=$GAS \
--per_device_train_batch_size=$BS --per_device_eval_batch_size=$BS \
--freeze_encoder --freeze_embeds \
--num_train_epochs=3 \
--save_steps 3000 --eval_steps 3000 \
--max_source_length $MAX_LEN --max_target_length $MAX_LEN \
--val_max_target_length $MAX_TGT_LEN --test_max_target_length $MAX_TGT_LEN \
--do_train --do_eval --do_predict \
--evaluation_strategy steps \
--predict_with_generate --logging_first_step \
--task translation --label_smoothing_factor 0.1 \
"$@"- 准备数据
由于我把数据放到了./test_data/zh_eng中,需要保证这个目录下有6个文件夹
test.source、test.target、train.source、train.target、val.source、val.target
数据格式很简单,一行source对应一行targert,官方wmt_en_ro文件里面也有示例
- 修改源码
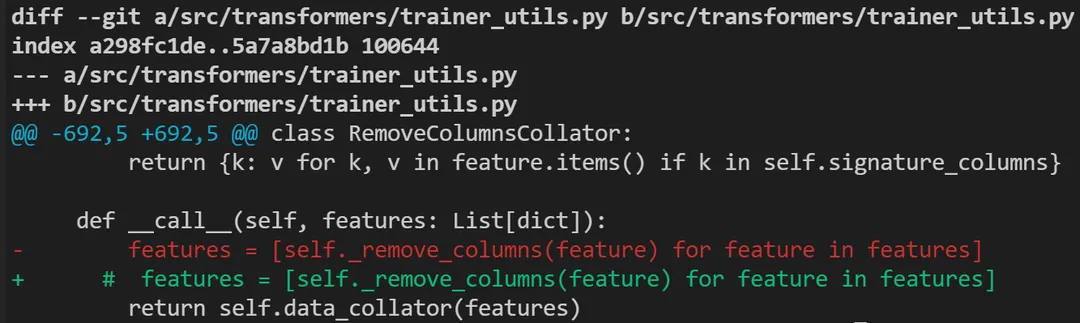
注释掉这行代码,不然精调无法进行,会被挡住
- 进行精调
bash train_distil_marian_enro.sh
精调结束后由于指定的输出目录是
--output_dir opus-mt-zh-en
所以会在同级目录下生成一个模型
- 使用精调后的模型
from transformers import MarianMTModel, MarianTokenizer
model_path = "训练后的模型位置"
tokenizer = MarianTokenizer.from_pretrained(model_path)
model = MarianMTModel.from_pretrained(model_path)
text="你好"
input_ids = tokenizer(text, return_tensors="pt",padding=True)
outputs = model.generate(**input_ids)
translated_text_from_text = tokenizer.decode(outputs[0],skip_special_tokens=True)
print(translated_text_from_text)想要快速验证精调效果可以一开始给训练数据时都给相同的,快速训练完成之后验证下
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读