面向超万卡集群的新型智算技术白皮书
面向超万卡集群的新型智算技术白皮书

摘要
自ChatGPT发布以来,科技界掀起了一场大模型的竞争热潮。数据成为新生产要素,算力成为新基础能源,大模型则成为新生产工具,各行各业从“+AI”向“AI+”的转变已势不可挡。随着模型参数量从千亿迈向万亿,模型能力更加泛化,大模型对底层算力的诉求进一步升级,万卡集群成为这一轮大模型基建军备竞赛的标配。
万卡集群将有助于压缩大模型训练时间,实现模型能力的快速迭代,并及时对市场趋势作出应对。然而,如何在万卡集群中实现高效的训练,并长期保持训练过程的稳定性,是将大模型训练扩展到数万张GPU卡上所要面临的双重挑战。本白皮书提出超万卡集群的核心设计原则,并在计算、存储、网络、平台及机房配套等多个领域提出关键问题和解决方案。
1、背景与挑战
自ChatGPT面世以来,大模型步入了迅猛发展期,AI技术的发展带动产业大规模升级的同时,也带来了对巨量算力和能源的需求。大模型对底层算力、空间、水电能源产生极大消耗,对新一代智算设施的设计要求也日益严苛。新型智算中心相关技术将继续被推向新的高度。无论是通信运营商、头部互联网企业、大型AI研发企业还是AI初创企业,都在通过自建或使用万卡集群加速其在人工智能领域的技术突破和产业创新。随着万卡集群建设的不断深入,我们预见这一趋势将为整个智算产业的发展带来深远影响。
当前,万卡集群的建设仍处于起步阶段,主要依赖英伟达GPU及配套设备实现。英伟达作为全球领先的GPU供应商,其产品在大模型训练上有较大优势。得益于政策加持和应用驱动,国产AI芯片在这两年取得长足进步,但在整体性能和生态构建方面仍存在一定差距。构建一个基于国产生态体系、技术领先的万卡集群仍在极致算力使用效率、海量数据处理、超大规模互联、高能耗高密度机房设计等方面面临诸多挑战。
2、设计原则与总体架构
在大算力结合大数据生成大模型的发展路径下,万卡集群的搭建不是简简单单的算力堆叠,要让数万张GPU卡像一台“超级计算机”一样高效运转。超万卡集群的总体设计应遵循坚持打造极致集群算力、坚持构建协同调优系统、坚持实现长稳可靠训练、坚持提供灵活算力供给、坚持推进绿色低碳发展五大设计原则。
万卡集群的总体架构由四层一域构成(如图1),四层分别是机房配套、基础设施、智算平台和应用使能,一域是智算运营和运维域。
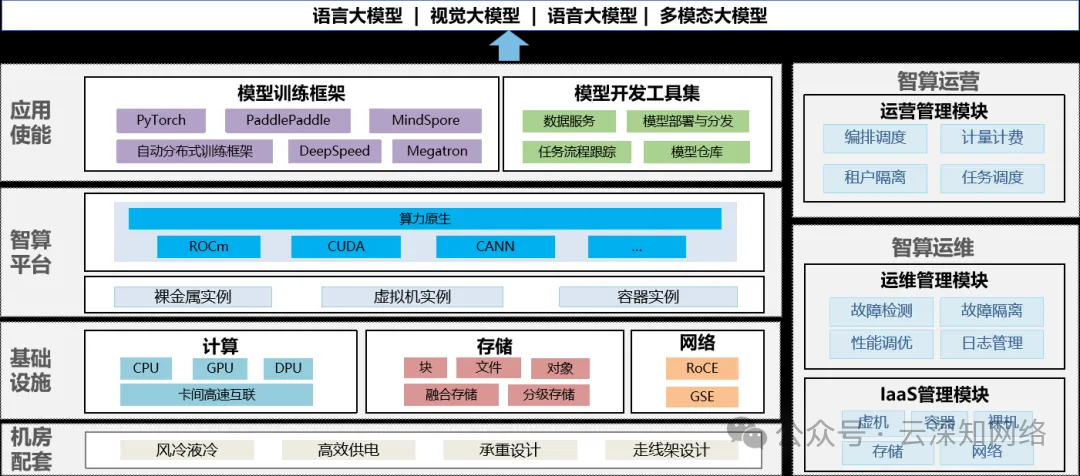
面向超万卡集群的新型智算总体架构设计
3、关键技术
集群高能效计算技术:随着大模型从千亿参数的自然语言模型向万亿参数的多模态模型升级演进,万卡集群亟需全面提升底层计算能力。具体而言,包括增强单芯片能力、提升超节点计算能力、基于DPU(Data Processing Unit)实现多计算能力融合以及追求极致算力能效比。这些系统性的提升将共同支持更大规模的模型训练和推理任务,满足迅速增长的业务需求。
高性能融合存储技术:为了实现存储空间高效利用、数据高效流动,并支持智算集群大规模扩展,万卡集群应采用多协议融合和自动分级存储技术,提升智算数据处理效率,助力万卡集群支撑千亿乃至万亿大模型训练。
大规模机间高可靠网络技术:万卡集群网络包括参数面网络、数据面网络、业务面网络、管理面网络。业务面网络、管理面网络一般采用传统的TCP方式部署,参数面网络用于计算节点之间参数交换,要求具备高带宽无损能力。数据面网络用于计算节点访问存储节点,也有高带宽无损网络的诉求。万卡集群对参数面网络要求最高,主要体现在四个方面:大规模,零丢包,高吞吐,高可靠。
高容错高效能平台技术:智算平台的性能通常不能随着算力线性增长,而是会出现耗损,因此大模型训练还需要高效的算力调度来发挥算力平台的效能。而这不仅需要依赖算法、框架的优化,还需要借助高效的算力调度平台,根据算力集群的硬件特点和计算负载特性实现最优化的算力调度,来保障集群可靠性和计算效率。针对以上问题,业界多以断点续训、并行计算优化、智能运维等作为切入点,构建高容错高效能智算平台。
新型智算中心机房设计:面向高密度高能耗智能算力发展,对于部署超万卡集群的新型智算中心来说,需要在确保智能计算设备安全、稳定、可靠地运行的前提下,具备高效制冷、弹性扩展、敏捷部署、绿色低碳等特征,并实现智能化运维管理。
4、未来展望
随着数据规模的持续扩大、集群能力的不断增强以及大模型应用的日益丰富,对新型智算底座的升级提出了更高的要求。面对未来,我们呼吁在超节点、跨集群训练、软件框架等领域实现技术突破,以强化智算基础设施能力。与此同时持续探索存算一体、光子芯片等先进技术领域与智算中心的结合,为下一次信息变革奠定基础。
参考文献
[1] Kaplan J , Mccandlish S , Henighan T ,et al.Scaling Laws for Neural Language Models[J]. 2020.DOI:10.48550/arXiv.2001.08361.
[2] Shazeer N , Mirhoseini A , Maziarz K ,et al.Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer[J]. 2017.DOI:10.48550/arXiv.1701.06538.
[3] Touvron H, Martin L, Stone K, et al. Llama 2: Open foundation and fine-tuned chat models[J]. arXiv preprint arXiv:2307.09288, 2023.
[4] 中国移动NICC新型智算中心技术体系白皮书,中国移动,2023
[5] Jiang Z, Lin H, Zhong Y, et al. MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs[J]. arXiv preprint arXiv:2402.15627, 2024.
[6] B. Kim et al., "The Breakthrough Memory Solutions for Improved Performance on LLM Inference," in IEEE Micro, doi: 10.1109/MM.2024.3375352.
[7] 全调度以太网技术架构白皮书,中国移动研究院
[8] Shoeybi M, Patwary M, Puri R, et al. Megatron-lm: Training multi-billion parameter language models using model parallelism[J]. arXiv preprint arXiv:1909.08053, 2019.
[9] Rasley J, Rajbhandari S, Ruwase O, et al. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters[C]//Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020: 3505-3506.