CVPR 2024 | LORS算法:低秩残差结构用于参数高效网络堆叠,参数少、成本低、内存小
CVPR 2024 | LORS算法:低秩残差结构用于参数高效网络堆叠,参数少、成本低、内存小

关注公众号,发现CV技术之美
本文主要介绍 CVPR2024 录用文章LORS: Low-rank Residual Structure for Parameter-Efficient Network Stacking的主要工作。深度神经网络主要采用堆叠大量相似模块的设计范式。尽管这是一种有效的方式,但与此同时带来了参数量的显著增长,这给实际应用带来了挑战。本文算法LORS允许堆叠模块共享大多数参数,每个模块只需要少量参数就可以匹配甚至超过原始完全不同参数的方法,这显著减少了参数量。
- 论文链接:https://arxiv.org/abs/2403.04303
- 源码链接:https://github.com/li-jl16/LORS
背景
在大语言模型上已经验证了堆叠在增强模型方面很强大。本文关注的问题:如何在减少所需参数量同时享受堆叠好处?注意到堆叠解码器具有相同结构和相似功能,这表明它们参数之间应该有一些共性。然后由于它们输入输出有不同分布,因此它们参数也必须有独特的方面。一个自然的想法是:可以用共享的参数表示共享的方面,同时允许每个堆叠的模块只保留捕捉独特特性参数。
基于以上观察,本文将堆叠模块的参数分解为两部分:表示共性的共享模块和捕捉特定特征的私有模块。共享模块可用于所有模块,并由它们联合训练,而私有模块中参数在每个模块中单独拥有。为了实现这个目标,本文受到LoRA模块启发提出了低秩残差结构模块(Low-rank Residual Structure,LORS)。LORS本质是将唯一参数添加到共享参数中,就像残差连接将残差信息添加到特征中一样。虽然LORA最初是为微调设计的,但本文算法从头开始对参数进行类似LoRA操作。
方法
LoRA简介
低秩适应(Low-rank Adaption,LoRA)核心思想是引入一个能够不住哦特定任务知识的低秩参数矩阵,同时保持原始的预训练参数固定。
数学上,给定预训练参数矩阵
,LoRA模块使用一个低秩矩阵
和一个投影矩阵
适应矩阵
,且满足
。适应参数矩阵可以描述为:
其中
捕捉特定任务知识。
LoRA 主要优势是可以显著减少需要微调的参数,因此减少了计算成本并降低了内存需要。在一些应用例子,即使r个位数值也可以将模型微调到期望的状态。
基于查询的检测器简介
与依赖锚框或滑动窗口的传统检测器不同,基于查询的模型利用一组可学习查询与图像特征图进行交互。这种交互可以通过注意力操作形式化:
可学习查询
用于预测目标类别和包围框,
和
源于编码的图像特征。
AdaMixer解码器简介
AdaMixer是一种基于查询的检测器。主要设计包括自适应通道混合(Adaptive Channel Mixing,ACM)和自适应空间混合(Adaptive Spatial Mixing,ASM),这显著增强了其性能。
给定采样特征
,其中
,
是采样组数量。才阿姨那个特征通过称为组采样的操作获得。该操作将特征空间通道
划分为
组,并对每一组执行采样。之后ACM使用通过目标查询适应的权重在通道维度转换特征
,增强其通道语义。
ASM模块目标是通过在空间维度应用自适应变换使目标查询具有对采样特征空间结构的适应能力。
ACM和ASM对于每个采样组训练独立的参数,最终输出形状为
扁平化后通过线性函数
变换到
维度并加回目标查询。
ACM、ASM和输出线性变换
有相较于解码器其他操作显著更多的参数。本文将它们作为目标组件验证本文算法的有效性。
LORS形式化描述
LORS计算划分为两个类型:自适应和静态。
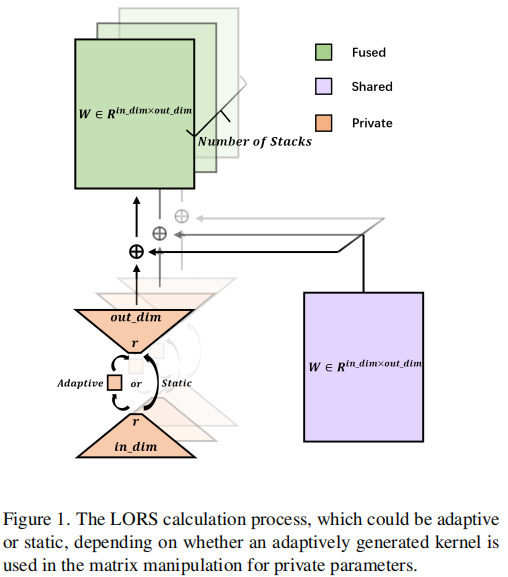
静态低秩残差结构(Static Low Rank Residual Structure,LORS^T^)
假设有N个有相同架构的堆叠层模块,
是属于第i层的参数矩阵。此时满足:
。
其中
是属于第i层的特定层参数,计算可以描述为:
。
其中
。
表示用于计算
的参数组数量。
自适应低秩残差结构(Adaptive Low Rank Residual Structure,LORS^A^)
定义
是第i对叠层的自适应生成参数,计算过程表示:
。跨层分享参数
和特定层参数
基于
计算:
其中
。
LORS在AdaMixer解码器应用
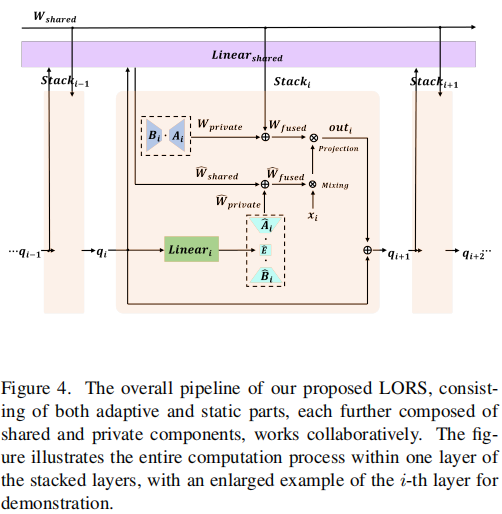
本文将LORS应用到属于AdaMixer解码器每个ACM、ASM和
。
对于每组的采样点,LORS^A^用于减少ACM中
参数(从
到
)与ASM中
参数(从
到
)。LORS^T^最小化
中参数(从
到
)。
因此
、
和
参数数量为
,
,
。本文实验默认采样策略包含两组,每组64个点,变量设置为
。在以ResNet-50为backbone的AdaMixer模型上,这三个组件共同占了总参数大部分,而它们也是增强模型性能主要驱动因素。
实验
训练超参数设置
模型训练12或36周期,12周期训练的第8和第11阶段的学习率下降了10倍,36周期训练的第24和第33阶段的学习率下降了10倍。对于LORS^A^低秩值设置为
,LORS^T^低秩值设置为
。LORS^A^参数组的数量设置为
,应用于AdaMixer解码器的ACM和ASM,
设置为
。本文将特征通道分为2组,每组64个采样点,而不是AdaMixer的默认的4组,每组32个采样点,旨在增加LORS的参数可压缩空间。
初始化策略
- LORS^T^:对于静态LORS的
和
采用Kaiming初始化,对于每个
零初始化。
- LORS^A^:对于自适应LORS,对于形成每个
的线性变换权重采用kaiming初始化,每个
和
采用相同初始化。对于形成每个
的线性变换权重采用零初始化。
主要实验结果
表2给出了使用LORS与没有LORS在1x训练方案与COCO数据集上的实验性能比较。比较指标包括参数数量、GFLOPs和各种尺度的AP。当AdaMixer与LORS组合时观察到显著的参数数量减少。例如当使用12周期和100查询时,AdaMixer+LORS使用仅仅35M解码器参数和60M总参数训练性能与对应110M和135M的AdaMixer相当。
表3显示了AdaMixer + LORS方法在不同backbone和查询数的3×训练方案下的显著性能。可以观察到,所提出的方法在所有backbone、查询数和评估指标上始终优于普通的AdaMixer。这个结果让我们有些惊讶,因为LORS使模型在训练和推理过程中使用明显更少的参数。