提示工程(prompt engineering):技术分类与提示词调优看这篇就够了
提示工程(prompt engineering):技术分类与提示词调优看这篇就够了

前言
在人工智能盛起的当下,出现了一个新兴的行业——提示工程(prompt engineering)。提示词,简言之,就是我们和AI说的话。在人机交互模式下,一个好的提示词,往往能产生事半功倍的效果。文本领域,好的提示词往往能超越RAG/Agent所能发挥的能力;图片对应的视觉领域,好的提示词往往能产生更好地图片/视觉效果。
在山行AI的视频号上有两个关于提示词的视频很好地说明了这一点,感兴趣的小伙伴不妨一观(顺便帮忙点个关注??-_-??,很分感谢~):
PS:可能看了本文之后,你对于提示词的理解就能超过别人很多啦~
01如何训练提示词模型来生成爆款文案
02翻译时如何用好提示词来告别机翻感
提示工程:技术分类与提示调优
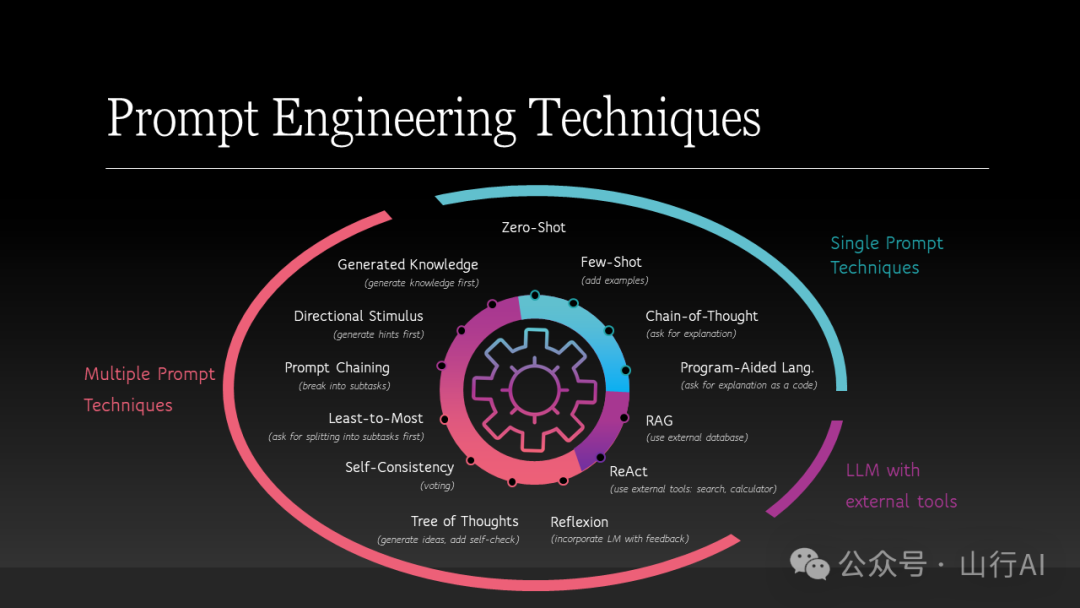
作为一个新兴的研究领域,提示工程(prompt engineering)缺乏明确的技术分类。当你浏览不同的文章和网站讨论这些技术时,你会发现它们各不相同且缺乏结构。由于这种混乱,从业者往往只坚持使用最简单的方法。在这篇文章中,我提出了一个对提示工程技术的概览和清晰的分类,这将帮助你把握它们的概念并在你的应用程序中有效使用它们。此外,我还将讨论将提示工程作为一个涉及提示调整(prompt tuning)和评估的数据科学过程。

尽管许多研究者付出了努力,大型语言模型仍然面临一些问题。它们的主要陷阱有:
?引用资源。 大型语言模型(LLMs)可以生成看似非常可信并引用外部资源的内容,但重要的是要记住,它们不能引用资源,它们既没有访问互联网的权限,?偏见。 LLMs在它们的回应中可能表现出偏见,常常生成刻板印象或有偏见的内容,?幻觉。 当LLMs被问到它们不知道答案的问题时,有时可以“幻觉”或生成虚假信息,?数学和常识问题。 尽管它们有先进的能力,LLMs常常在解决即使是最简单的数学或常识问题时遇到困难,?提示劫持。LLMs可以被用户操纵或“黑客攻击”,以忽略开发者的指令并生成特定内容。
大多数的提示工程技术解决了两个问题:幻觉和解决数学及常识任务。有特定的技术旨在减轻提示劫持,但这是一个单独讨论的话题。
常见规则
在讨论具体技术之前,让我们谈谈提示的常见规则,这将帮助你写出清晰和具体的指令:
1.准确地说明要做什么(写作、总结、提取信息),2.避免说明不要做什么,而是说明要做什么,3.具体一点:不要说“用几句话”,而是说“用2-3句话”,4.添加标签或分隔符来构造提示,5.如果需要,要求结构化输出(JSON、HTML),6.要求模型验证是否满足条件(例如,“如果你不知道答案,就说‘没有信息’”),7.要求模型先解释然后再提供答案(否则模型可能试图为错误的答案辩解)。
分类
目前的大多数技术可以分为三组:
?单一提示技术 旨在优化对一个提示的响应,?接下来是结合几个提示的技术。它们的共同理念是多次查询模型(或多个模型)以解决任务,?最后,有一组方法将大型语言模型与外部工具结合使用。
单一提示技术

哪些技术旨在通过单个提示解决你的任务?
?零次学习(Zero-Shot),?少次学习(Few-Shot),?思维链(Chain of Thought),?程序辅助语言(Program Aided Language)。
我们来逐一研究它们。
零次提示(Zero-Shot Prompting)
这是最简单的技术,使用自然语言指令。

单次学习。示例来自 promptingguide.ai[1]
少次提示(Few-Shot Prompting)
大型语言模型(LLMs)在单次学习方面表现非常出色,但它们仍可能在复杂的任务上失败。少次学习的理念是向模型演示带有正确答案的类似任务(Brown et al. (2020)[2])。

少次学习。示例来自 promptingguide.ai[3]
在 Min et al. (2022)[4] 的论文中,研究表明在一系列分类和多选任务中,示范中标签的不正确几乎不会影响性能。相反,确保示范提供标签空间的少数几个示例、输入测试的分布以及序列的整体格式是至关重要的。
思维链提示(Chain of Thought Prompting, CoT)
思维链提示通过中间推理步骤实现复杂的推理能力。这项技术的目标是使模型迭代并对每一步进行推理。

零次学习、少次学习和思维链提示技术。示例来自 Kojima et al. (2022)[5]。
思维链提示可以与零次学习或少次学习一起使用。零次思维链提示的概念是建议模型一步一步地思考,以得出解决方案。这种方法的作者(Kojima et al. (2022)[6])展示了零次思维链提示在算术、符号和其他逻辑推理任务上的性能显著超过了零次学习的大型语言模型(LLM)的表现。
如果你选择少次思维链提示,你必须确保有包含解释的多样化示例(Wei et al. (2022)[7])。这种方法在算术、常识和符号推理任务上具有惊人的实证增益。
程序辅助的语言模型(Program-Aided Language Models, PAL)
程序辅助的语言模型是一种扩展思维链提示的方法,通过将解释扩展为带有代码的自然语言(Gao et al. (2022)[8])。

程序辅助语言提示。示例来自 Gao et al. (2022)[9]。
这一技术可以使用 LangChain PALChain[10] 类来实施。
多重提示技术
下一组提示基于结合一个或几个模型的提示的不同策略:
1.投票。这个想法是通过投票得到正确答案。技术:自我一致性。2.分而治之。这组提示基于将复杂任务分解为几个提示。技术:方向刺激、生成知识、提示链、表格链和由少到多的提示。3.自我评估。这种方法建议在框架中加入检查输出是否符合指示的步骤。技术:反思、思维树。
自我一致性(Self Consistency, SC)
自我一致性基于这样的直觉:“一个复杂的推理问题通常有多种不同的思考方式,导致其唯一正确的答案”(Wang et al. (2022)[11])。
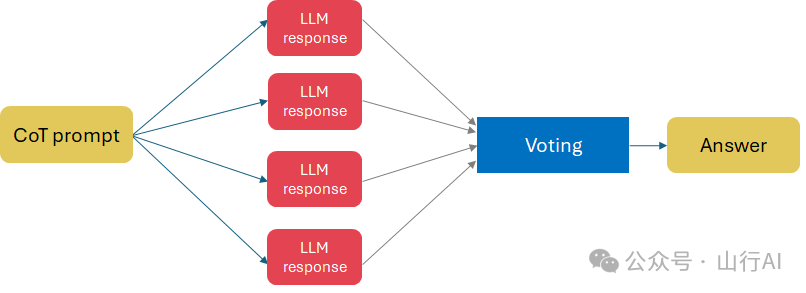
它多次提出相同的思维链提示,从而生成一组多样化的推理路径,然后通过应用投票选择最一致的答案。
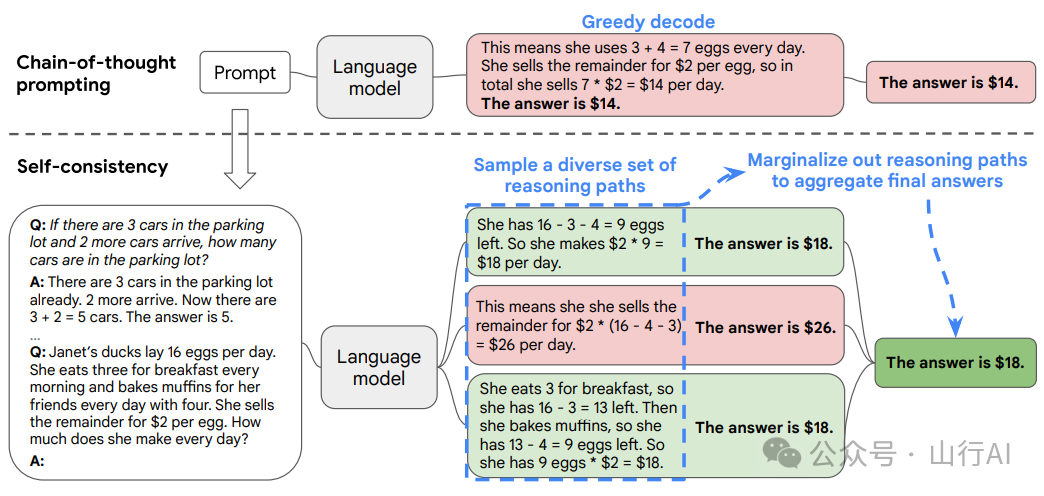
自我一致性提示技术示例,源自Wang et al. (2022)[12]
在Wang et al. (2022)[13]的研究中,应用自我一致性技术对算术和常识任务的提升,在常见基准测试中为4%–18%。
定向刺激提示(DSP)
结合提示的下一个概念是“分而治之”。在DSP中,我们有两个步骤:生成刺激(例如,关键词)并使用它们来提高响应的质量。
定向刺激提示在Li et al. (2023)[14]提出,用于摘要生成、对话响应生成和思维链推理任务。它包含两个模型:
?训练一个小型可调策略语言模型(LM)来生成刺激(提示),?使用一个黑盒冻结的大型语言模型(LM)根据问题和上一步的刺激生成摘要。
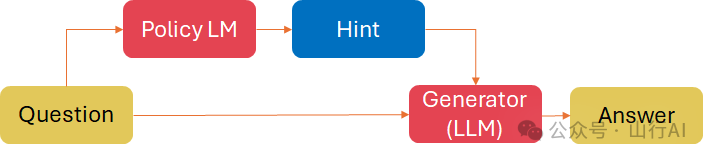
策略模型可以通过使用标记数据的监督式微调和基于大型语言模型(LLM)输出的离线或在线奖励进行强化学习来进行优化,例如:
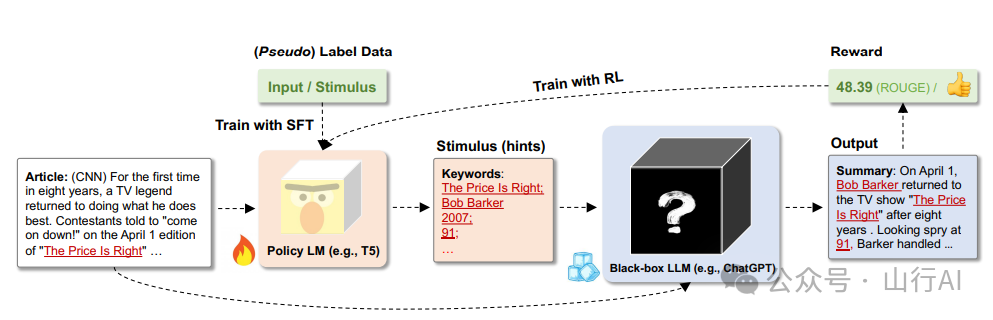
DSP框架 Li et al. (2023)[15] 我们学习一个小型的可调策略模型来生成定向刺激(在这种情况下是关键词),它为大型语言模型(LLM)提供了针对特定输入的指导,以达到预期的目标。
生成知识提示(GK)
在“分而治之”概念下的下一个提示技术是在 Liu et al. (2022)[16] 提出的生成知识。其思想是先使用一个单独的提示来生成知识,然后利用这些知识来获得更好的响应。
生成知识提示包括两个阶段:
?知识生成:使用少量样本演示从语言模型中生成与问题相关的知识陈述,?知识整合:使用第二个语言模型与每个知识陈述一起进行预测,然后选择最高置信度的预测。
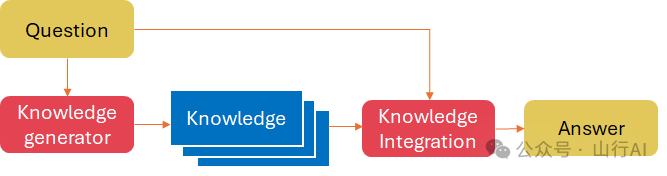
这种方法不需要对知识整合的特定任务的监督,也不需要访问结构化的知识库,但它提高了大型、最先进模型在常识推理任务上的性能。

来自 Liu et al. (2022)[17] 的知识生成小样本提示示例,用于QASC
提示链接
提示链接是一种简单而强大的技术,你应该将任务分解为子问题,并依次用这些子问题提示模型。
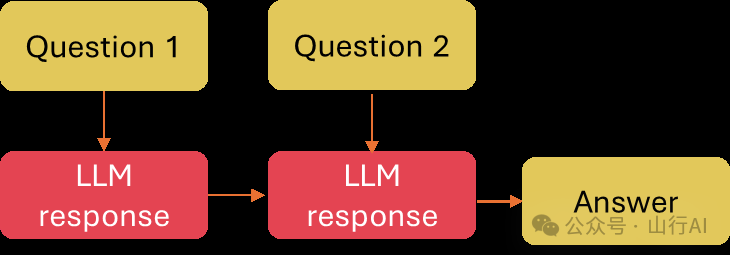
提示链接对于完成一个大型语言模型(LLM)可能难以应对的复杂任务非常有用,特别是当这些任务伴随着非常详细的提示时。它还有助于提高大型语言模型应用的透明度,增强可控性和可靠性。
提示链接示例来自 txt.cohere.com[18]
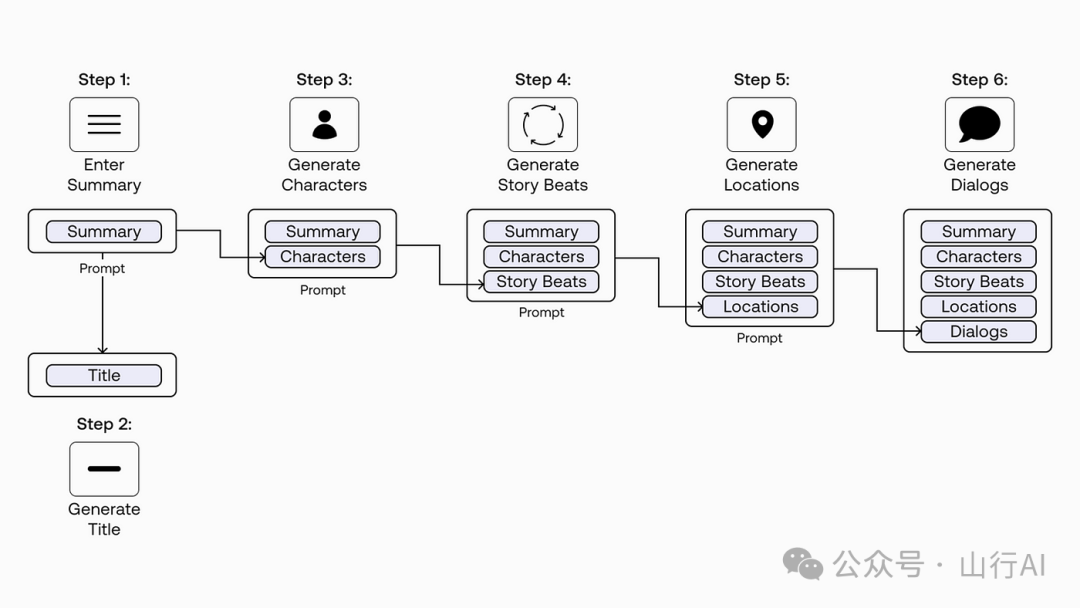
从简到繁的提示
从简到繁的提示方法更进了一步,增加了一个步骤,即模型需要决定如何将你的任务分解成子问题。
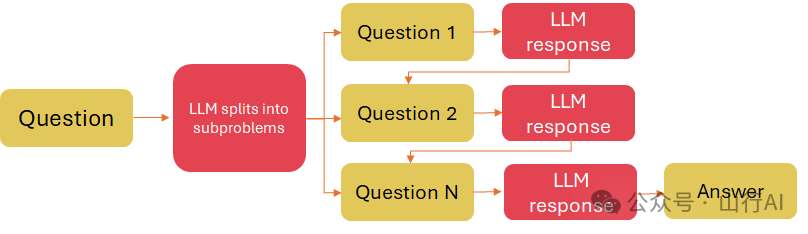
Zhou et al. (2022)[19] 中的实验结果揭示,从简到繁的提示方法在与符号操作、组合泛化和数学推理相关的任务上表现良好。
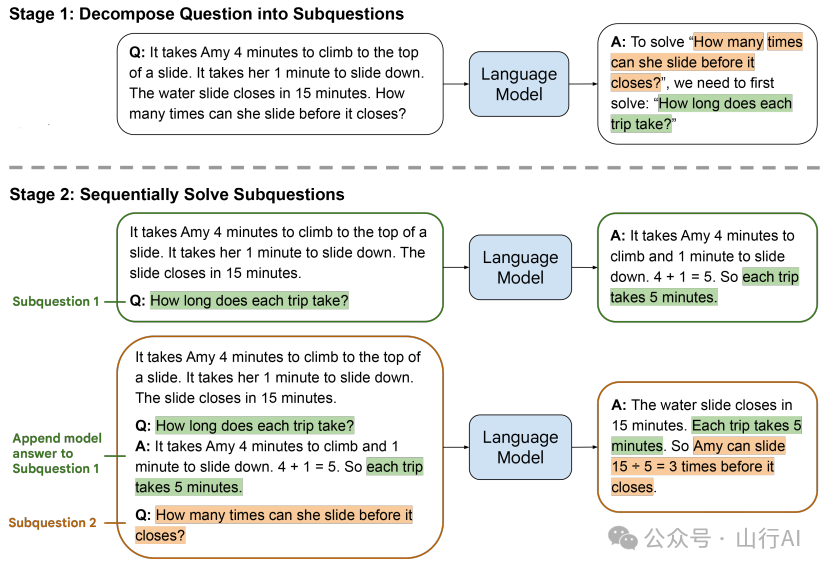
Zhou et al. (2022)[20] 中的从简到繁提示的例子
连锁表格提示
在最近的研究 (Wang et al. (2024)[21]) 中提出了一种新方法,其中表格数据被明确用作推理链中的中间思考的代理。
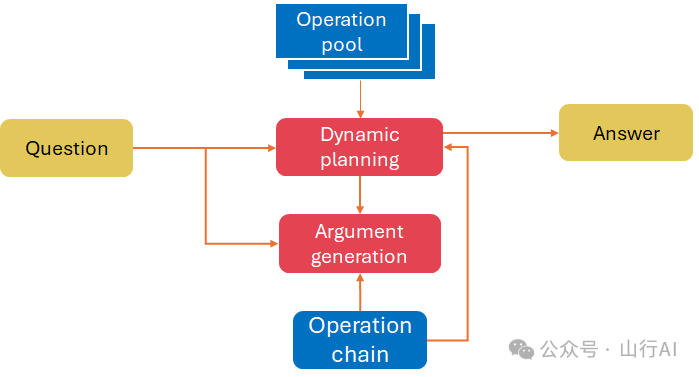
该算法包括两个步骤的循环:
1.动态规划,在此过程中,大型语言模型(LLM)根据输入查询和以前操作的历史(操作链)从操作池中抽取下一个操作,2.参数生成,涉及使用大型语言模型(LLM)为上一步骤选定的操作生成参数(例如新的列名),并应用编程语言来执行操作并创建相应的中间表格。
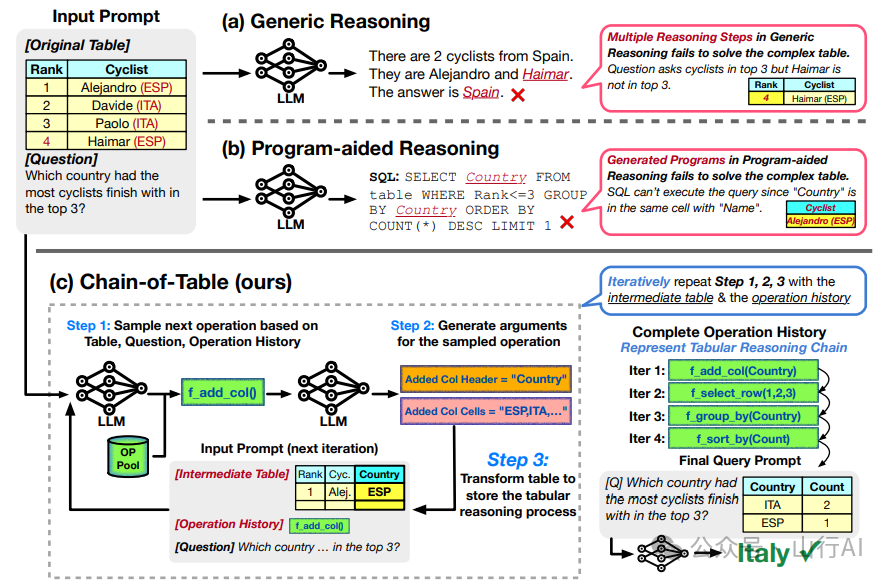
来自Wang et al. (2024)[22]的连锁思考提示的示例和比较。
接下来的两种方法实现了自检(Self-Check)的概念 —— 框架中有一个步骤来检查解决方案。连锁表格(Cgain-of-Table)实现的示例可以在此链接[23]找到。
思维树(Tree of Thoughts,ToT)
思维树在连锁思考方法的基础上进行泛化,允许模型探索多个推理步骤并自我评估选择。
要实现ToT技术,我们必须决定四个问题:
1.如何将中间过程分解为思考步骤,2.如何从每个状态生成潜在的思考点,3.如何启发式地评估状态(使用状态评估提示),4.使用什么搜索算法(Yao et al. (2023)[24])。
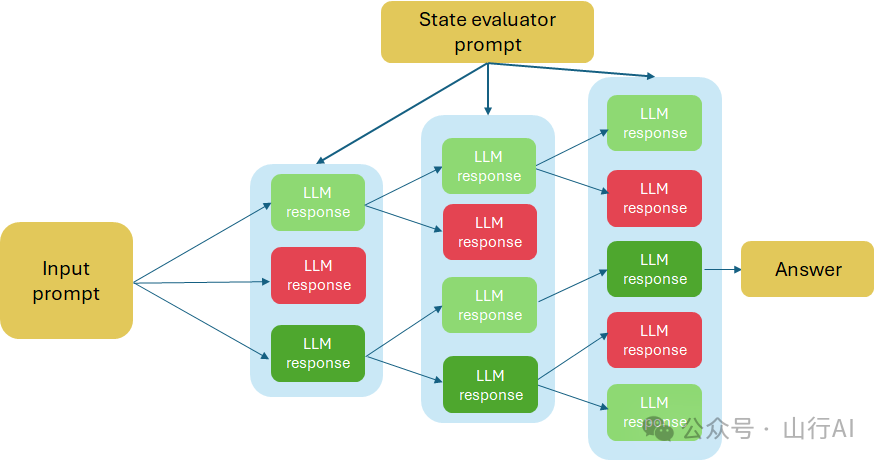
输入提示 必须包括解决问题的中间步骤的描述,以及抽取的思考点或关于生成它们的指令。状态评估提示 必须提供关于选择哪些提示进行下一步的指令。
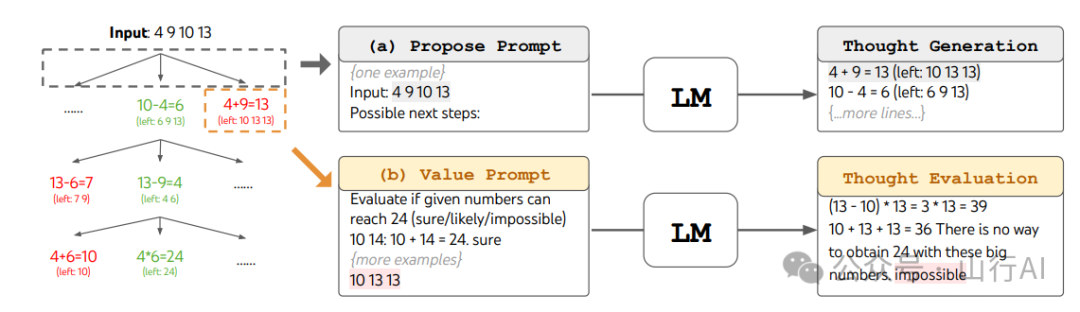
【思维树在24点游戏中的例子】摘自Yao et al. (2023)[25]
Yao et al. (2023)[26]的实验显示,对于需要复杂规划或搜索的任务,思维树技术(ToT)非常成功。LangChain 实现了思维树技术,在 langchain_experimental.tot.base.ToTChain 类[27]中有所体现。
反思
反思是一个通过语言反馈加强语言代理的框架。反思代理通过对任务反馈信号进行口头反思,然后在情节记忆缓冲区中保持自己的反思文本,以在后续试验中促进更好的决策(Shinn et al. (2023)[28])。
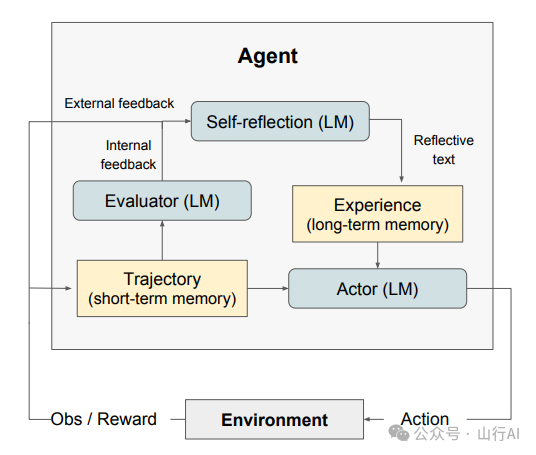
来自 Shinn et al. (2023)[29] 的反思框架图解
反思框架由三个不同的模型组成:
?执行者(Actor):一个基于状态观察生成文本和行动的大型语言模型(使用CoT和ReAct技术),?评估者(Evaluator):一个对执行者产生的输出进行评分的大型语言模型,?自我反思(Self-Reflection):一个生成口头强化提示以协助执行者自我提升的大型语言模型。

来自 Shinn et al. (2023)[30] 的不同任务中的反思示例
反思在需要顺序决策、编程、语言推理的任务中表现良好。
请通过此链接[31]查看实现。
结合外部工具的大型语言模型框架
在本节中,我将介绍两种方法 —— 检索增强生成和ReAct。
检索增强生成(Retrieval-Augmented Generation, RAG)
RAG将信息检索组件与文本生成模型结合起来:
?检索。在检索步骤中,系统通常使用向量搜索寻找可能回答问题的相关文档,?生成。接下来,将相关文档作为上下文连同初始问题传递给一个大型语言模型(Lewis et al. (2021)[32])。
在大多数情况下,使用RAG-序列方法,意味着我们检索k篇文档,并使用它们生成回答用户查询的所有输出标记。
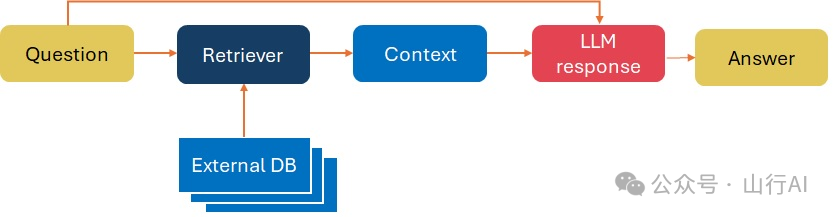
在RAG中,语言模型可以进行微调,但实际上这种做法很少见,因为预训练的大型语言模型已经足够好,可以直接使用,而自行进行微调成本过高。此外,RAG中的内部知识可以以高效的方式修改,而无需重新训练整个模型。
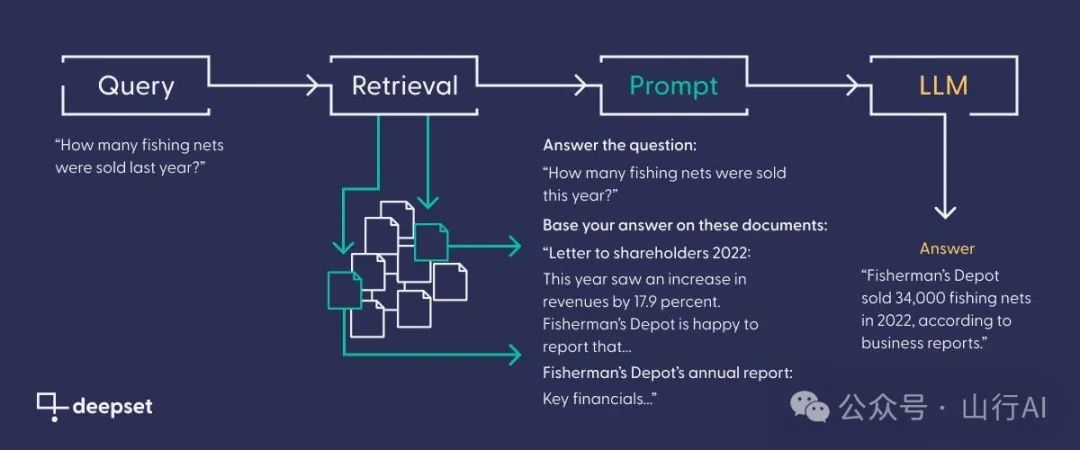
RAG生成的响应更具事实性、具体性和多样性,有助于提高事实验证的结果。
ReAct
Yao等人(2022)[33] 提出了一个名为ReAct的框架,其中大型语言模型被用来以交错的方式生成推理迹象和任务特定的行动:推理迹象帮助模型引导、跟踪和更新行动计划,以及处理异常,而行动则使其能够与外部来源(如知识库或环境)接口并收集额外信息。
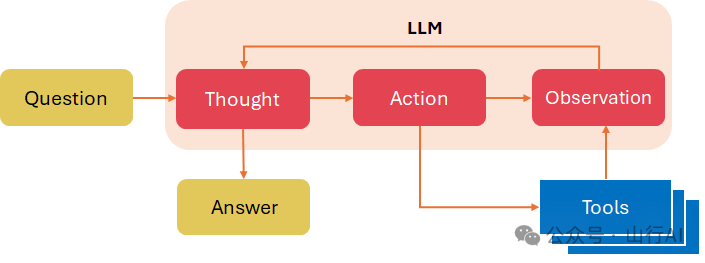
ReAct框架可以选择一个可用的工具(例如搜索引擎、计算器、SQL代理),应用它并分析结果以决定下一步行动。
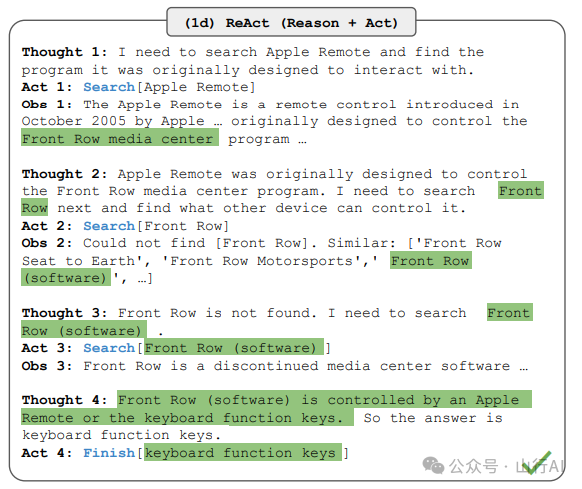
ReAct案例(引自Yao等人(2022年)[34])
通过与简单的Wikipedia API交互,ReAct解决了在连贯思维推理中普遍存在的幻觉和错误传播问题,并生成了类似人类解决任务的轨迹,这些轨迹比没有推理痕迹的基线模型更易于解释(Yao等人(2022年)[35])。
查看Langchain工具实现的ReAct案例[36]。
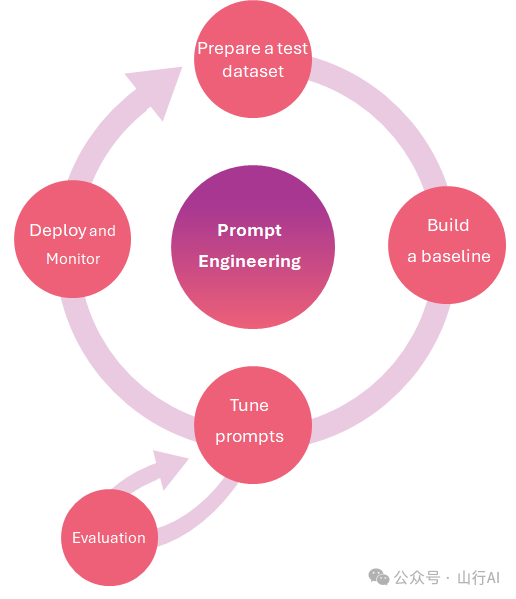
提示调整和评估
选择提示工程技术在很大程度上取决于您的LLM的应用和可用资源。如果您曾经尝试过提示,您知道大型语言模型对人类生成的提示中最微小的变化非常敏感,这些提示往往是次优的且通常具有主观性。
无论您选择哪种提示技术,如果您正在构建一个应用程序,将提示工程视为一个数据科学过程是非常重要的。这意味着创建一个测试集,选择指标,调整提示,并评估其对测试集的影响。
测试提示的指标在很大程度上将取决于应用程序,但以下是一些指南(来自数据科学峰会2023[37]):
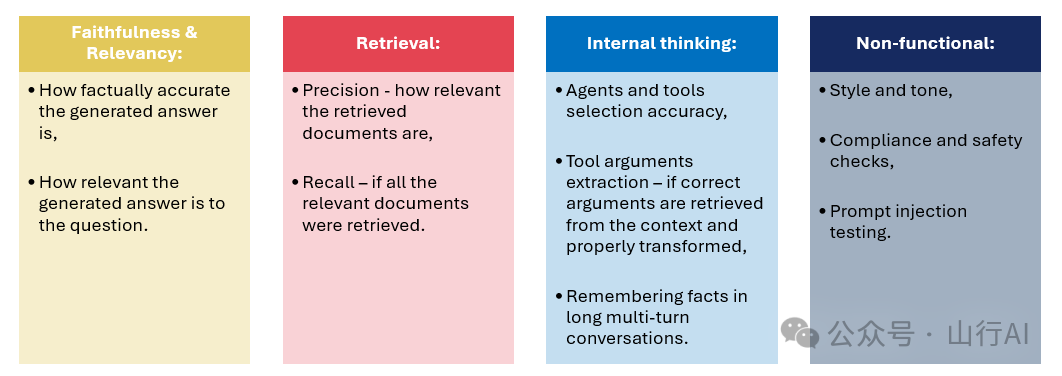
测试提示的指标(摘自数据科学峰会2023[38])
1.忠实度和相关性:?生成答案的事实准确性如何,?生成答案与问题的相关性如何。2.检索 — 主要用于RAG和ReAct管道,但也可以应用于生成的知识及方向性刺激提示:?精确度 — 检索到的文档的相关性有多高,?召回率 — 是否检索到了所有相关文档。3.内部思考:?代理和工具选择的准确性 — 用于ReAct,?工具参数提取 — 是否从上下文中正确检索到参数,并进行了恰当的转换 — 用于ReAct,?在长轮对话中记住事实 — 用于ReAct,?正确的逻辑步骤 — 用于ReAct和思维链提示。4.非功能性:?答案的风格和语调,?缺乏偏见,?合规和安全检查,?提示注入测试。
根据您的用例,选择指标并跟踪提示更改对测试集的影响,确保任何更改不会降低响应的质量。
总结
我不敢说已经涵盖了所有现有技术 — 它们太多了,不久的将来有人可能会出版一本完整的教科书。但如果你读到这里,你会注意到所有技术的概念都相当普遍且直观。我可以将所有写好提示的规则总结为一个简短的清单:
1.清晰而准确,以便模型不必猜测你的意图,2.使用分隔符或标签增加结构,3.通过展示示例和添加解释来帮助模型,4.要求模型迭代思考,解释其解决方案,5.如果提示复杂,考虑将其分解为子任务,6.尝试多次询问相同的提示,7.考虑增加模型自检的步骤,8.如有需要,将您的LLM与外部工具结合使用,9.将提示调整视为一个迭代且需要评估的数据科学过程。
就是这样!感谢您阅读到这里,祝您提示愉快!
声明
本文由山行翻译整理自:https://medium.com/@kate.ruksha/prompt-engineering-classification-of-techniques-and-prompt-tuning-6d4247b9b64c,如果对您有帮助,请帮忙点赞、关注、收藏,谢谢~
References
[1] promptingguide.ai: https://www.promptingguide.ai/techniques/fewshot
[2] Brown et al. (2020): https://arxiv.org/abs/2005.14165
[3] promptingguide.ai: https://www.promptingguide.ai/techniques/fewshot
[4] Min et al. (2022): https://arxiv.org/abs/2202.12837
[5] Kojima et al. (2022): https://arxiv.org/abs/2205.11916
[6] Kojima et al. (2022): https://arxiv.org/abs/2205.11916
[7] Wei et al. (2022): https://arxiv.org/abs/2201.11903
[8] Gao et al. (2022): https://arxiv.org/abs/2211.10435
[9] Gao et al. (2022): https://arxiv.org/abs/2211.10435
[10] LangChain PALChain: https://api.python.langchain.com/en/latest/pal_chain/langchain_experimental.pal_chain.base.PALChain.html
[11] Wang et al. (2022): https://arxiv.org/abs/2203.11171
[12] Wang et al. (2022): https://arxiv.org/abs/2203.11171
[13] Wang et al. (2022): https://arxiv.org/abs/2203.11171
[14] Li et al. (2023): https://arxiv.org/abs/2302.11520
[15] Li et al. (2023): https://arxiv.org/abs/2302.11520
[16] Liu et al. (2022): https://arxiv.org/pdf/2110.08387.pdf
[17] Liu et al. (2022): https://arxiv.org/pdf/2110.08387.pdf
[18] txt.cohere.com: https://txt.cohere.com/chaining-prompts/
[19] Zhou et al. (2022): https://arxiv.org/pdf/2205.10625.pdf
[20] Zhou et al. (2022): https://arxiv.org/pdf/2205.10625.pdf
[21] Wang et al. (2024): https://arxiv.org/pdf/2401.04398.pdf
[22] Wang et al. (2024): https://arxiv.org/pdf/2401.04398.pdf
[23] 此链接: https://github.com/run-llama/llama-hub/blob/main/llama_hub/llama_packs/tables/chain_of_table/chain_of_table.ipynb
[24] Yao et al. (2023): https://arxiv.org/abs/2305.10601
[25] Yao et al. (2023): https://arxiv.org/abs/2305.10601
[26] Yao et al. (2023): https://arxiv.org/abs/2305.10601
[27] langchain_experimental.tot.base.ToTChain 类: https://api.python.langchain.com/en/latest/tot/langchain_experimental.tot.base.ToTChain.html
[28] Shinn et al. (2023): https://arxiv.org/pdf/2303.11366.pdf
[29] Shinn et al. (2023): https://arxiv.org/pdf/2303.11366.pdf
[30] Shinn et al. (2023): https://arxiv.org/pdf/2303.11366.pdf
[31] 此链接: https://github.com/noahshinn/reflexion
[32] Lewis et al. (2021): https://arxiv.org/pdf/2005.11401.pdf
[33] Yao等人(2022): https://arxiv.org/abs/2210.03629
[34] Yao等人(2022年): https://arxiv.org/abs/2210.03629
[35] Yao等人(2022年): https://arxiv.org/abs/2210.03629
[36] ReAct案例: https://python.langchain.com/docs/modules/agents/agent_types/react/
[37] 数据科学峰会2023: http://dssconf.pl/
[38] 数据科学峰会2023: http://dssconf.pl/