0921-7.1.9-bucket布局和从HDFS拷贝数据到Ozone
0921-7.1.9-bucket布局和从HDFS拷贝数据到Ozone

Fayson
发布于 2024-04-30 19:48:56
发布于 2024-04-30 19:48:56
1 Bucket布局
Ozone支持多种bucket布局
- ? FILE_SYSTEM_OPTIMIZED (FSO):
- ? 包含文件和目录的分层文件系统命名空间。
- ? 支持原子重命名/删除操作。
- ? 建议使用 Hadoop 文件系统兼容接口而不是 s3 接口。
- ? 支持回收站
- ? OBJECT_STORE (OBS):
- ? 扁平键值(flat key-value)命名空间,如S3。
- ? 建议与S3接口一起使用。
- ? LEGACY
- ? 旧版本中创建的bucket
- ? 默认行为与 Hadoop 文件系统兼容。
1.在一个volume下创建一个FSO布局的bucket:
ozone sh bucket create /vol1/fso-bucket --layout FILE_SYSTEM_OPTIMIZED
ozone sh bucket info /vol1/fso-bucket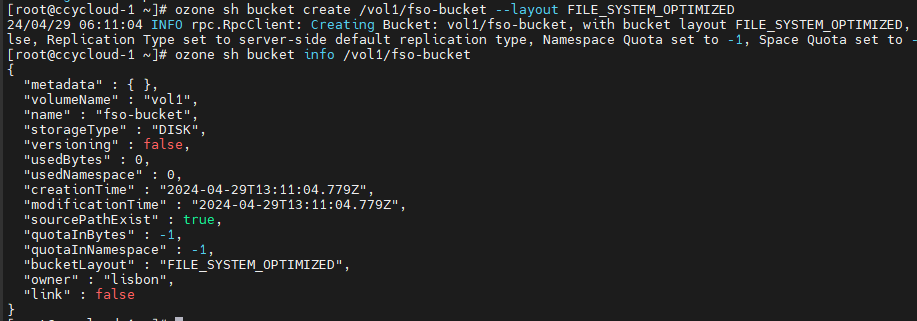
2.创建一个OBS布局的bucket:
ozone sh bucket create /vol1/obs-bucket --layout OBJECT_STORE
ozone sh bucket info /vol1/obs-bucket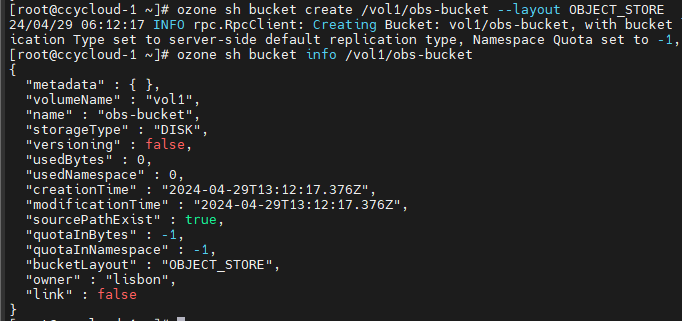
2 将文件从HDFS拷贝到Ozone
1.上传文件到HDFS
wget -qO - https://www.fueleconomy.gov/feg/epadata/vehicles.csv | hdfs dfs -copyFromLocal - /tmp/vehicles.csv
2.将文件拷贝到Ozone
ozone fs -mkdir -p ofs://ozone1/hive/warehouse/cp/vehicles ### Creates an FSO bucket by default
ozone fs -cp hdfs:///tmp/vehicles.csv ofs://ozone1/hive/warehouse/cp/vehicles
3.在Ozone中列出文件
ozone fs -ls ofs://ozone1/hive/warehouse/cp/vehicles
4.使用ozone fs -cp命令复制文件的速度非常慢,因为只有一个客户端会在系统之间下载和上传文件。为了提升性能,需要让集群通过多个服务器并行地将文件直接从源移动到目标。
5.所以我们可以使用hadoop distcp命令复制文件,它会向YARN提交一个MapReduce程序来运行拷贝作业,默认情况下该作业会使用多个服务器来运行复制作业,默认使用4个container。这比使用ozone cp命令要更加高效,distcp是并行拷贝文件的强大工具,它提供了许多用于同步和自动复制数据的选项,即使通信出现错误也不会丢失任何文件。
ozone fs -mkdir -p ofs://ozone1/hive/warehouse/distcp/vehicles
hadoop distcp -m 2 -skipcrccheck hdfs:///tmp/vehicles.csv ofs://ozone1/hive/warehouse/distcp/vehicles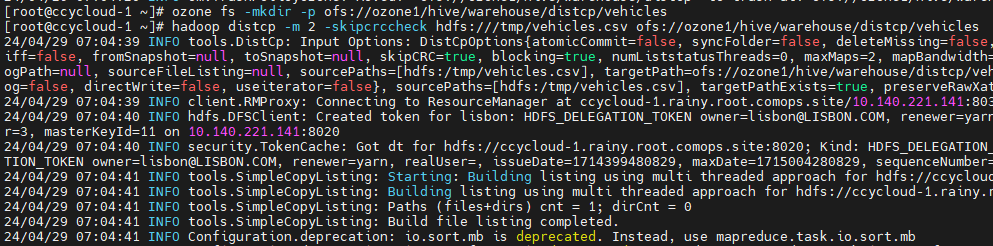
6.列出Ozone中的文件
ozone fs -ls ofs://ozone1/hive/warehouse/distcp/vehicles
注意:HDFS 和Ozone的checksum不兼容,校验需要单独执行。Cloudera内部有一个Spark工具FileSizeValidator,可以比较源文件系统和目标文件系统中文件的 md5 checksum。
本文参与?腾讯云自媒体分享计划,分享自微信公众号。
原始发表:2024-04-30,如有侵权请联系?cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录