Int4:Lucene中的标量量化更进一步
原创Int4:Lucene中的标量量化更进一步
原创
在Lucene中引入Int4量化
在我们之前的博客中,我们详细介绍了Lucene中标量量化的实现。我们还探讨了两种特定的量化优化。现在,我们来探讨这个问题:在Lucene中,int4 量化是如何工作的,以及它是如何对齐的?
存储和评分量化向量
Lucene将所有向量存储在一个平面文件中,使得可以根据某个序号检索每个向量。你可以在我们的之前的标量量化博客中阅读这方面的简要概述。
现在,int4为我们提供了比之前更多的压缩选项。它将量化空间减少到只有16个可能的值(0到15)。为了更紧凑的存储,Lucene使用一些简单的位移操作将这些较小的值打包到一个字节中,这可能在已有的int8的4倍空间节省的基础上,再节省2倍的空间。总的来说,存储带有位压缩的int4比float32小8倍。
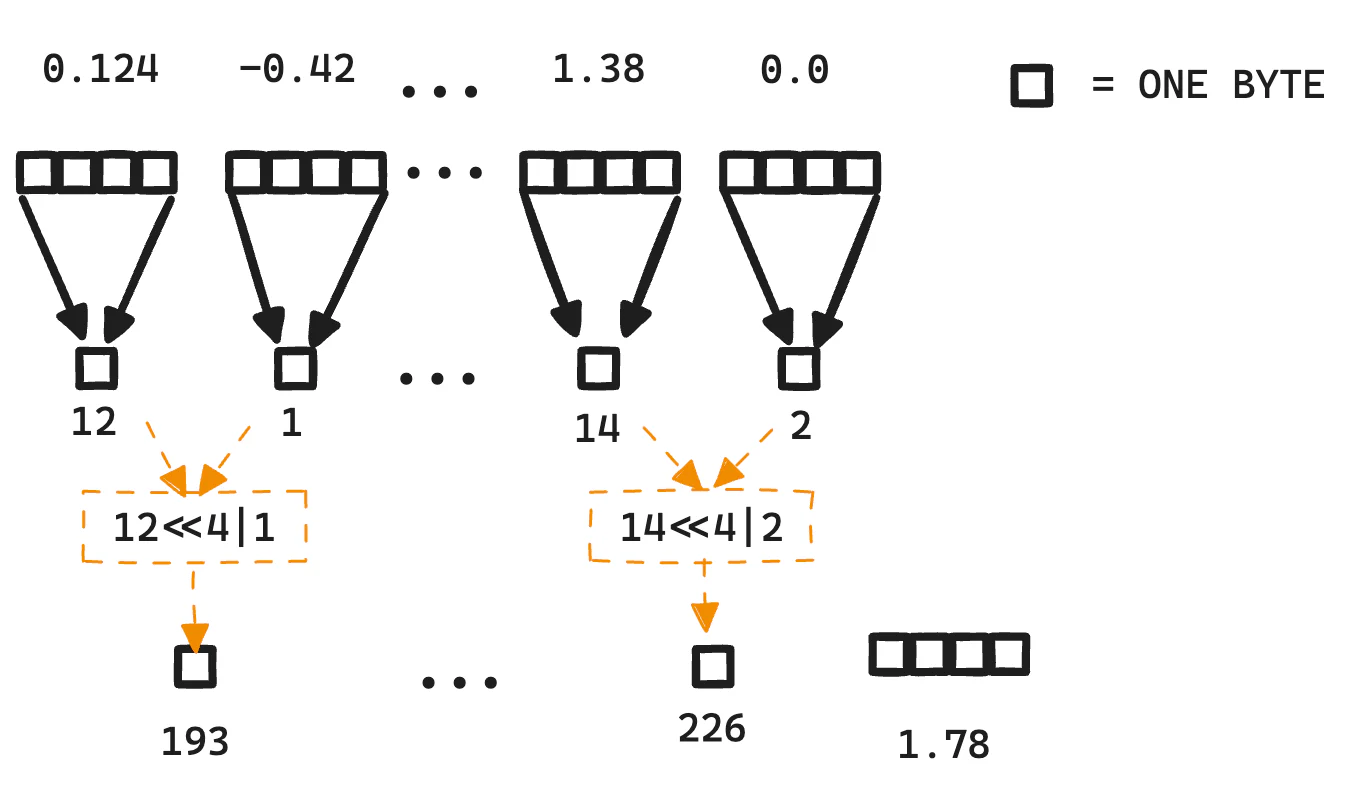
图1:这展示了int4所需的字节减少,当压缩时,相比float32可以减少8倍的大小。
int4在评分延迟方面也有一些优点。由于已知这些值在0-15之间,我们可以准确地知道何时需要考虑值溢出,并优化点积计算。一个点积的最大值是15*15=225,这可以放入一个字节中。ARM处理器(如我的macbook)的SIMD指令长度为128位(16字节)。这意味着对于一个Java short,我们可以分配8个值来填充通道。对于1024维度,每个通道最终会累积总共1024/8=128个乘法,最大值为225。结果最大和28800很好地适应了Java的short值的限制,我们可以一次迭代更多的值。下面是这对于ARM来说看起来的简化代码。
// snip preamble handling vectors longer than 1024
// 8 lanes of 2 bytes
ShortVector acc = ShortVector.zero(ShortVector.SPECIES_128);
for (int i = 0; i < length; i += ByteVector.SPECIES_64.length()) {
// Get 8 bytes from vector a
ByteVector va8 = ByteVector.fromArray(ByteVector.SPECIES_64, a, i);
// Get 8 bytes from vector b
ByteVector vb8 = ByteVector.fromArray(ByteVector.SPECIES_64, b, i);
// Multiply together, potentially saturating signed byte with a max of 225
ByteVector prod8 = va8.mul(vb8);
// Now convert the product to accumulate into the short
ShortVector prod16 = prod8.convertShape(B2S, ShortVector.SPECIES_128, 0).reinterpretAsShorts();
// Ensure to handle potential byte saturation
acc = acc.add(prod16.and((short) 0xFF));
}
// snip, tail handling计算误差修正
对于误差修正计算和其推导的更详细解释,请参见标量点积的误差修正。
下面是一个简短的总结,很幸运(或者说很高兴),它没有复杂的数学公式。
对于每个存储的量化向量,我们额外跟踪一个量化误差修正。在标量量化101博客中,提到了一个特定的常数:
?×???8?×???α×int_8_i×min
这个常数是基础代数推导出的一个简单常数。然而,我们现在在存储的浮点数中包含了与四舍五入损失相关的额外信息。
∑?=0????1((?????)??′×?)?′×?i=0∑dim?1((i?_min)?i′×α)_i′×α
其中?i是每个浮点向量维度,?′i′是标量量化的浮点值,而?=???????(1<<????)?1α=(1<<bits)?1m_ax?mi_n。
这有两个后果。第一个是直观的,因为这意味着对于一个给定的量化桶集,我们在考虑了量化的损失后,会稍微精确一些。第二个后果有点微妙。这现在意味着我们有一个受到量化分桶影响的误差修正度量。这意味着它可以被优化。
找到最佳分桶
进行标量量化的简单和朴素的方法可以让你走得很远。通常,你选择一个置信区间,从中计算向量值的允许极限。Lucene和因此Elasticsearch的默认值是1?1/(??????????+1)1?1/(dimensions+1)。图2显示了一_些采样CohereV_3嵌入上的置信区间。图3显示了相同的向量,但是使用那个静态设置的置信区间进行标量量化。
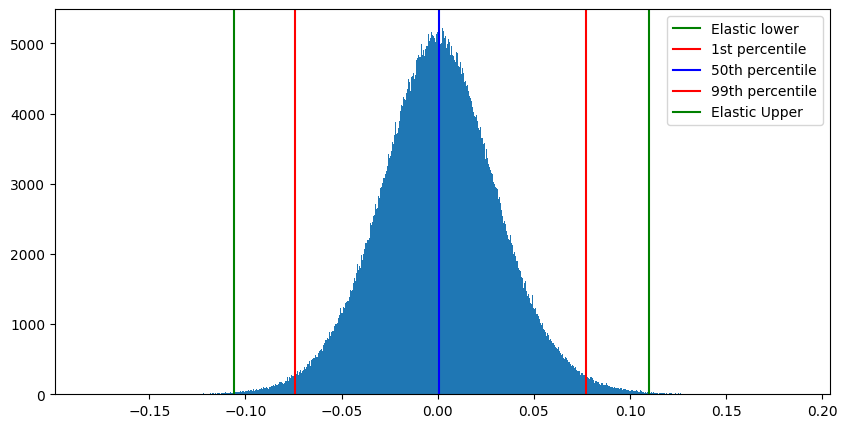
图2:CohereV3维度值的样本。
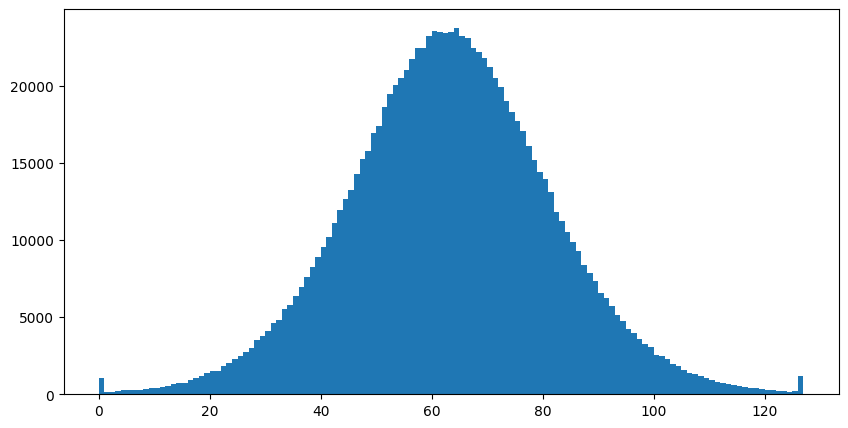
图3:CohereV3维度值量化为int7值。那些在末尾的尖峰是什么?那是在量化过程中截断极值的结果。
但是,我们把一些好的优化放在了地板上。如果我们可以调整置信区间来移动桶,使得更重要的维度值具有更高的保真度,那该如何呢?为了优化,Lucene做了以下操作:
- 从数据集中采样大约1,000个向量,并计算它们的真实最近的10个邻居。
- 计算一组候选的上和下分位数。这组分位数是通过使用两个不同的置信区间来计算的:1?1/(??????????+1)1?1/(dimensions+1)和1?(??????????/10)/(??????????+1)1?(dimensions/10)/(dimensions+1)。这些区间在极端情况下是相反的。例如,具有1024维度的向量将在置信区间0.999_02和0.9_0009之间搜索分位数候选者。
- 对这两个置信区间之间存在的分位数的子集进行网格搜索。网格搜索找到的分位数是量化得分误差与先前计算的真实10个最近邻的决定系数最大化的。
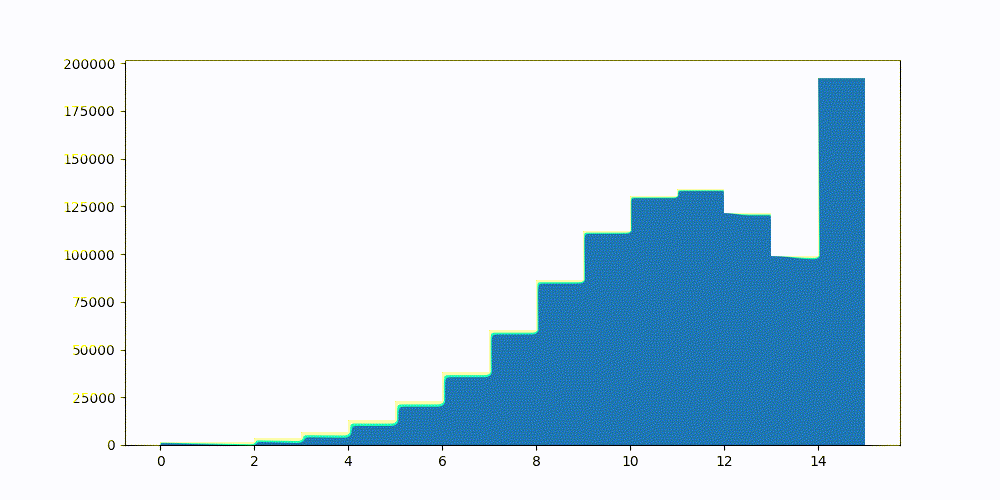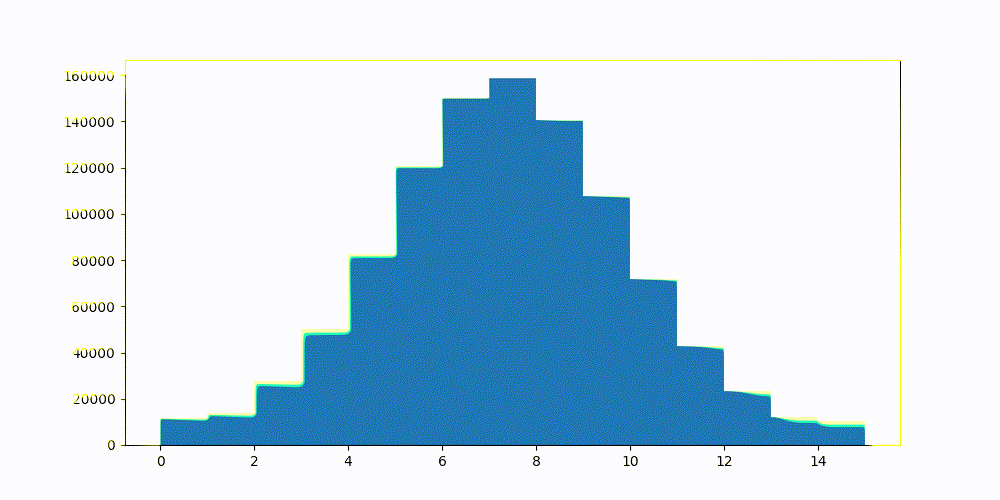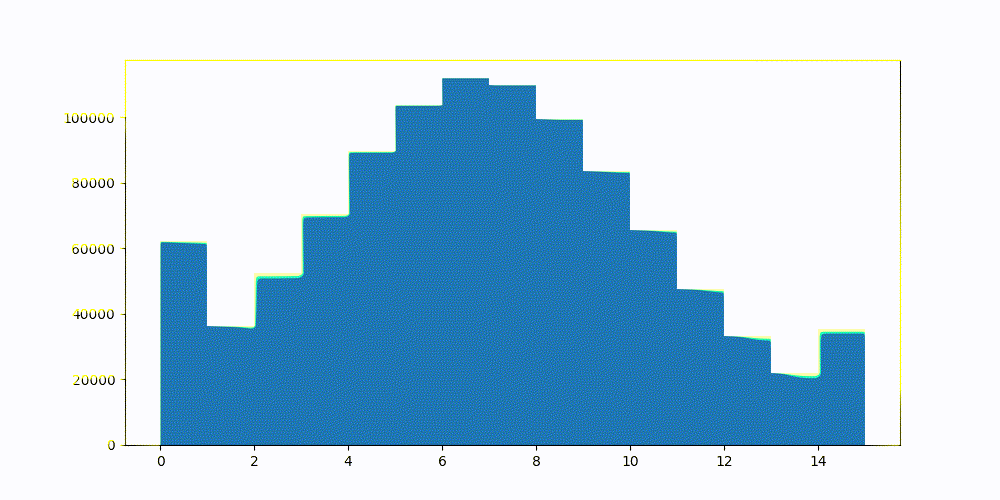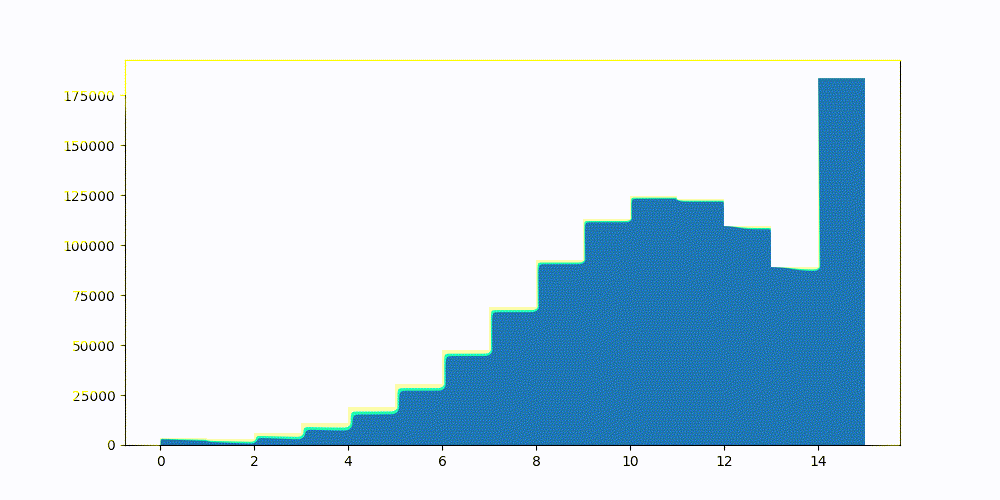
图3:Lucene搜索置信区间空间,并测试int4量化的各种桶。
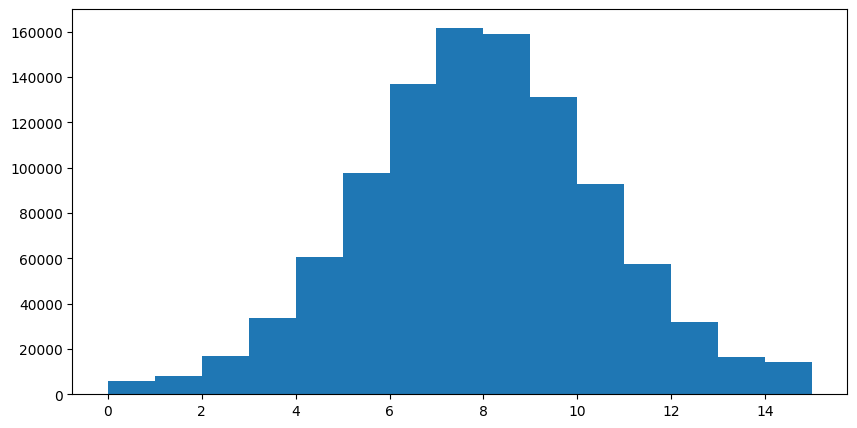
图4:这是为CohereV3样本集找到的最佳int4量化桶。
对于优化过程和此优化背后的数学的更完整解释,请参见优化截断间隔。
量化的速度与大小
正如我之前提到的,int4在性能和空间之间提供了一个有趣的权衡。为了让这一点更加明确,这里有一些CohereV3 500k向量的内存需求。
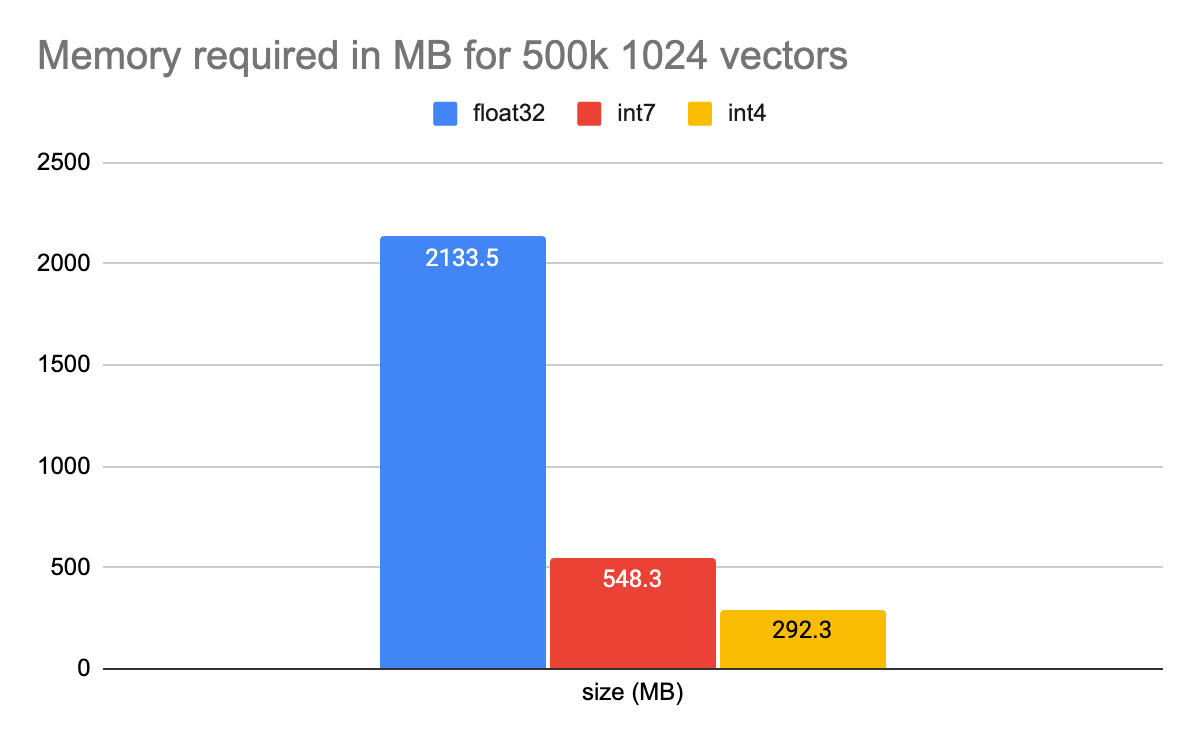
图5:CohereV3 500k向量的内存需求。
当然,我们在常规的标量量化中看到了典型的4倍减少,但然后int4额外的2倍减少。将所需内存从2GB降低到不到300MB。记住,这是在启用压缩的情况下。在搜索时解压缩和压缩字节确实有一些开销。对于每个字节向量,我们必须在进行int4比较之前对它们进行解压缩。因此,当这在Elasticsearch中引入时,我们希望给用户选择压缩与否的能力。对于一些用户来说,更便宜的内存需求实在太好了,无法放过,对于其他人来说,他们关注的是速度。Int4给了你调整设置以适应你的用例的机会。
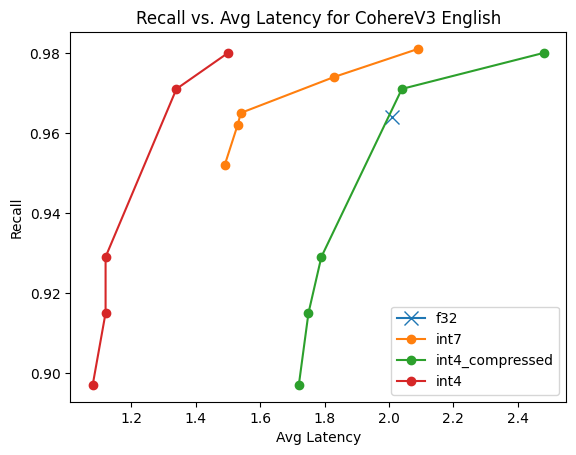
图6:CohereV3 500k向量的速度比较。
结束了吗?
在过去的两篇大而技术性的博客文章中,我们讨论了优化的数学和直觉,以及它们为Lucene带来了什么。这是一个漫长的旅程,我们还远未结束。请期待这些功能在未来的Elasticsearch版本中的出现!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。