第一篇证明离线RL中使用TPMs的可能性的论文,即使NP-hard
第一篇证明离线RL中使用TPMs的可能性的论文,即使NP-hard

Expressive Modeling Is Insufficient for Offline RL: A Tractable Inference Perspective https://arxiv.org/abs/2311.00094
表达建模对于离线强化学习来说是不够的:易于处理的推理视角



摘要
一种流行的离线强化学习(RL)任务范式是首先将离线轨迹拟合到序列模型中,然后提示模型执行能够产生高期望回报的动作。尽管普遍认为更具表现力的序列模型意味着更好的性能,但本文强调了可处理性的重要性,即准确且高效地回答各种概率查询的能力同样重要。具体而言,由于离线数据收集策略和环境动态的基本随机性,需要进行高度非平凡的条件/约束生成来引发有益的动作。虽然可以近似地解决此类查询,但我们观察到这种粗略估计显著削弱了表现力强大的序列模型带来的好处。为了解决这个问题,本文提出了Trifle(用于离线RL的可处理推理),利用现代可处理概率模型(TPMs)来弥合评估优秀序列模型和高期望回报之间的差距。从实验上看,Trifle在9个Gym-MuJoCo基准测试中实现了最先进的得分,超过了强基线。此外,由于其可处理性,在随机环境和安全RL任务(例如,带有动作约束)中,Trifle在最小算法修改的情况下明显优于先前的方法。
1 简介
最近深度生成模型的进展为使用序列建模技术(称为RvS方法)解决离线强化学习(RL)任务打开了可能性(Levine等人,2020)。具体而言,我们首先将离线数据集中提供的轨迹拟合到一个序列模型中。在评估过程中,模型被要求在当前状态下采样具有高期望回报的动作。利用现代深度生成模型,如GPTs(Brown等人,2020)和扩散模型(Ho等人,2020),RvS算法在各种离散/连续控制问题上显著提高了性能(Ajay等人,2022;Chen等人,2021)。
尽管其吸引人的简单性,但仍不清楚仅仅通过表达建模是否保证了RvS算法的良好性能,如果是这样,在什么类型的环境中。也许令人惊讶的是,本文发现了许多RvS算法的常见失败并不是由建模问题引起的。相反,在训练期间,虽然有用的信息被编码到模型中,但在评估期间,模型无法引发这种知识。具体而言,这个问题体现在两个方面:(i)无法准确估计状态的预期回报以及在给定近乎完美的学习转移动态和奖励函数时要执行的相应动作序列的预期回报;(ii)即使离线数据集中存在准确的回报估计,并且模型已经学会了这些估计值,但在评估过程中仍可能无法采样到有回报的动作。在这种评估时性能的核心问题是,需要进行高度非平凡的条件/约束生成来刺激高回报的动作(Paster等人,2022;Brandfonbrener等人,2022)。
Specifically, this issue is reflected in two aspects: (i) inability to accurately estimate the expected return of a state and a corresponding action sequence to be executed given near-perfect learned transition dynamics and reward functions; (ii) even when accurate return estimates exist in the offline dataset and are learned by the model, it could still fail to sample rewarding actions during evaluation.1At the heart of such inferior evaluation-time performance is the fact that highly non-trivial conditional/constrained generation is required to stimulate high-return actions
因此,除了表现力之外,能够有效且准确地回答各种查询(例如,计算期望累积回报),即可处理性,在RvS方法中发挥着同样重要的作用。
鉴于缺乏可处理性是RvS算法表现不佳的一个重要原因,本文研究了是否可以从使用可处理概率模型(TPMs)(Poon&Domingos,2011; Choi等人,2020; Kisa等人,2014)中获得实际的好处,这些模型通过设计支持对某些查询的精确和高效计算?我们通过展示我们可以利用一类支持计算任意边缘概率的TPMs,从而显著减轻RvS方法在推理时间的次优性来肯定地回答这个问题。所提出的算法Trifle(离线RL的可处理推理Tractable Inference for Offline RL)具有三个主要贡献:
1. 强调可处理模型在离线RL中的重要作用。这是第一篇论文,证明了在复杂的离线RL任务中使用TPMs的可能性。Trifle的优越经验性能表明,表达性建模并不是决定RvS算法性能的唯一因素,并激发了开发更好的推理感知RvS方法的动力。
2. 具有竞争力的实证性能。与强大的离线RL基线(包括RvS、模仿学习和离线时差算法)相比,Trifle在9个Gym-MuJoCo基准测试中获得了最先进的得分。
3. 对随机环境和安全RL任务的泛化能力。Trifle可以扩展到处理随机环境以及具有最少算法修改的安全RL任务。具体来说,我们在随机出租车环境和动作空间受限的MuJoCo环境中评估了Trifle,并展示了其优于所有基线的性能。
2 预赛
在强化学习(RL)中,代理与未知环境在离散的时间步中进行交互,以最大化其累积奖励。环境由马尔可夫决策过程(MDP)?S,A,R,P,d0?定义,其中S是状态空间,A是动作空间,R:S×A→R是奖励函数,P:S×A→S是转移动态,d0是初始状态分布。我们的目标是学习一个策略π(a|s),最大化期望回报
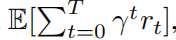
,其中γ ∈ (0, 1]是折扣因子,T是最大步数。
离线RL(Levine等人,2020)旨在解决我们无法自由与环境交互的RL问题。相反,我们收到一组使用未知策略收集的轨迹数据集。离线RL的一个有效学习范式是将其视为序列建模问题(称为通过序列建模或RvS方法的RL)(Janner等人,2021; Chen等人,2021; Emmons等人,2021)。具体来说,我们首先在数据集上学习一个序列模型,然后在过去的状态和未来高回报的条件下采样动作。由于模型通常不会编码整个轨迹,因此对于每个状态-动作对,还包括了估计值或未来回报(RTG)(即未来奖励总和的蒙特卡洛估计),使模型能够估计任何时间步的回报。
可处理概率模型(TPMs)是一类生成模型,设计用于高效且准确地回答各种概率查询(Poon&Domingos,2011; Choi等,2020; Rahman等,2014)。TPM的一个示例类别是隐马尔可夫模型(HMMs)(Rabiner&Juang,1986),它支持边缘概率的线性时间(相对于模型大小和输入大小)计算等。最近的进展已经大大推动了现代TPMs的表达能力(Liu等人,2022; 2023; Correia等人,2023),在自然图像和文本数据集上与强变分自动编码器(Vahdat&Kautz,2020)和扩散模型(Kingma等人,2021)等强基线相比具有竞争力的似然性。本文利用了这些进展,并探讨了TPMs在离线RL任务中带来的好处。
3 离线强化学习中的可处理性很重要
实际的RvS方法主要分为两个阶段 - 训练和评估。在训练阶段,采用序列模型学习长度为T的轨迹的联合分布:
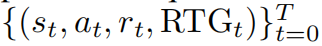
。在评估阶段,对于每个时间步t,模型的任务是发现一个动作序列
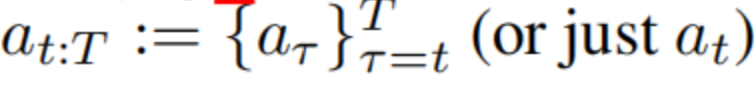
,该序列具有高期望回报以及在先前策略p(at:T |st)下具有高概率,以防止生成超出分布的动作。


以上定义自然揭示了RvS方法中的两个关键挑战:(i)训练时优化:我们能多好地拟合离线轨迹,以及(ii)推断时优化:是否可以从方程(1)中无偏且高效地抽样动作。虽然已经取得了大量突破,以改善训练时的优化(Ajay等人,2022年;陈等人,2021年;詹纳等人,2021年),但推断时的优化仍然不清楚。我们将以下两种一般情况中的现有RvS方法表现不佳归因于推断时性能的次优。我们将这种失败归因于这些模型受限于回答特定查询类别(例如,自回归模型只能计算下一个标记概率),并在以下部分探讨可计算概率模型在离线RL任务中的潜力。
情景#1 首先考虑标记的RTG属于(接近)最优策略的情况。在这种情况下,方程(1)可以简化为p(at|st,E[Vt]≥v)(选择Vt:= RTGt),因为一步最优性意味着多步最优性。实际上,尽管RTGs是次优的,但预测的值通常与代理实际获得的回报很好地匹配。以轨迹变换器(TT)(Janner等人,2021年)为例,图1(左侧)展示了其预测回报(x轴)与六个MuJoCo(Todorov等人,2012年)基准上实际累积回报(y轴)之间的强正相关性,表明模型已学习了大多数动作的“好处”。在这种情况下,RvS算法的性能主要取决于其推断时的优化,即它们是否能够高效地抽样具有高预测回报的动作。具体地,令at为RvS算法在状态st处采取的动作,
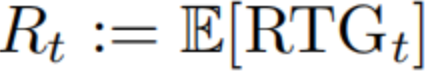
是相应的估计期望值。我们将推断时优化的代理定义为状态条件值分布
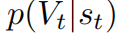
中Rt的分位值。分位值越高,RvS算法抽样高估回报的动作就越频繁。
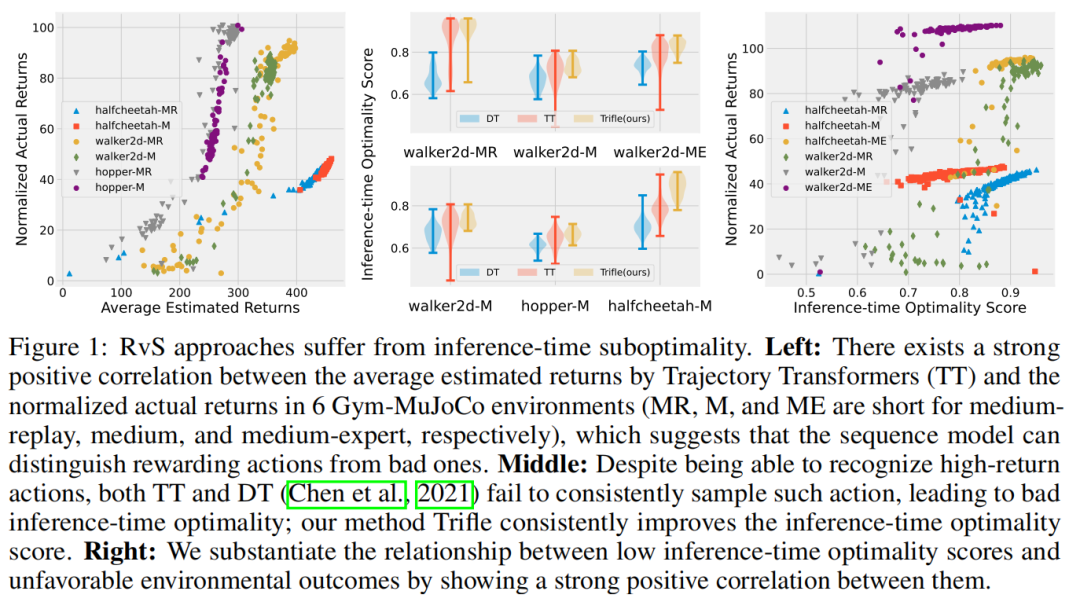
图1:RvS方法在推断时间子优化方面存在问题。左图:在6个Gym-MuJoCo环境中,轨迹变换器(TT)的平均预估回报与标准化实际回报之间存在强烈的正相关性(MR、M和ME分别代表中等重播、中等和中等专家),这表明序列模型能够区分有回报的动作和糟糕的动作。中间图:尽管能够识别高回报动作,但TT和DT(Chen等,2021)都未能一致地采样到这样的动作,导致推断时间优化性不佳;我们的方法Trifle持续改善了推断时间优化分数。右图:我们通过展示它们之间的强正相关性,证实了推断时间优化分数低与环境结果不利之间的关系。
我们评估了决策变换器(DT)(Chen等人,2021年)和轨迹变换器(TT)(Janner等人,2021年)这两种广泛使用的RvS算法在各种环境和来自Gym-MuJoCo基准套件(Fu等人,2020年)的离线数据集上的推断时优化情况。令人惊讶的是,如图1(中)所示,大多数设置的推断时优化平均值仅约为0.7(最大可能值为1.0)。而这些推断时优化得分低的运行得到的环境回报也较低(图1(右))。
情景#2 当标记的RTGs是次优的时候(例如,它们来自随机策略),实现推断时的优化变得更加困难。在这种情况下,即使估计动作序列的未来期望回报也变得非常棘手,特别是当环境的转移动态是随机的时候。具体来说,要评估状态-动作对(st,at),由于RTGt没有信息,我们需要求助于多步估计
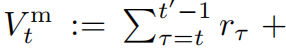

,其中动作at:t′是共同选择的,以最大化期望回报。以自回归模型为例。由于变量按照顺序排列...,我们需要在计算Vtm中的奖励和RTG之前显式抽样st+1:t′。当转移动态是随机的时候,估计
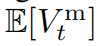
可能会因为中间状态的随机性随时间累积而产生高方差。
正如我们将在第6.2节中说明的那样,与具有接近确定性转移动态的环境相比(例如,图1(左)),使用难以处理的序列模型估计随机环境中的期望回报是困难的,而Trifle能够通过其消除中间状态并以闭合形式计算E[Vtm]来显着缓解这个问题。
4 利用易于处理的模型
前面的部分表明,除了建模之外,推断时次优性是导致RvS方法表现不佳的另一个关键因素。鉴于这样的观察,一个自然的后续问题是更可处理的模型如何改善离线RL任务的评估时间性能?虽然有不同类型的可处理性(即,计算不同类型的查询的能力),但本文重点研究准确计算任意边际/条件概率的附加好处。这在学习和推断之间取得了适当的平衡,因为我们可以训练这样一个可处理但富有表现力的模型,这要归功于TPM社区最近的发展。请注意,除了提出一种竞争性的RvS算法外,我们还旨在强调在离线RL任务中使用更可处理的模型的必要性和好处,并鼓励未来在推断感知的RvS方法和更好的TPM方面的发展。作为对第3节确定的两种失败情景的直接回应,接下来,我们首先展示了即使标记的RTGs是(近似)最优时,可处理性也如何提供帮助(第4.1节)。然后我们转向更一般的情况,即我们需要使用多步返回估计来解释标记的RTGs中的偏差(第4.2节)。
4.1 从单步案例来看......
考虑 RTG 最佳的情况。回想一下第 3 节,我们的目标是从

中采样动作。先前的工作使用两种典型的方法从该分布中进行近似采样。第一种方法直接训练模型来生成返回条件动作:p(at|st, RTGt)(Chen 等人,2021)。然而,由于给定状态-动作对的 RTG 是随机的, 从这种 RTG 条件策略中采样可能会导致获得高回报的概率较小的动作,但预期回报较低(Paster 等人,2022 年;Brandfonbrener 等人,2022)。
另一种方法利用序列模型准确估计状态-动作对的预期回报(
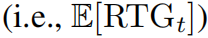
的能力(Janner et al., 2021)。具体来说,我们首先从先验分布p(at|st)中采样,然后拒绝预期回报较低的动作。这种基于拒绝采样的方法通常在动作空间较小(可以枚举所有动作)或数据集包含许多高回报轨迹(拒绝率较低)的情况下效果良好。然而,在实践中,动作可能是多维的,数据集通常包含许多低回报轨迹,从而使推断时优化得分较低(参见图1)。
在审查了现有方法的优缺点之后,我们面临一个问题,即一个可计算的模型是否能够改善采样的动作(在这种单步情况下)。我们对此的回答是积极和消极的混合结果:即使在
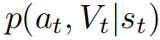
遵循简单的朴素贝叶斯分布的情况下,计算
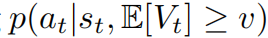
是NP-难的,但我们可以设计一个近似算法,在实践中以高概率采样高回报的动作。我们先从消极的结果开始。

4.2 ...多步情况

5 TPMS 的实际实施
前一节已经展示了如何有效地从期望值条件下的策略(式1)中进行采样。基于这个采样算法,本节进一步介绍了提出的算法Trifle(用于离线RL的可计算推断)。Trifle的高层次思想是从
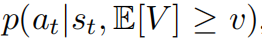
中获取良好的动作(序列)候选,并使用beam search进一步确定最有益的动作。直观地说,根据式(1)的定义,候选动作既有回报又在离线数据集中具有相对较高的可能性,这确保了动作在离线数据分布内,并在beam search期间防止过于自信的估计。
Beam search维护着一组N(不完整的)序列,每个序列从一个空序列开始。为了方便演示,我们假设当前时间步为0。在每个时间步t,beam search将每个N个动作序列复制成
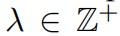
个副本,并将一个动作at附加到每个序列中。具体来说,对于每个部分动作序列a<t,我们根据
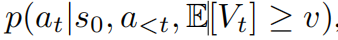
采样一个动作,其中Vt可以是单步或多步估计,具体取决于任务。现在,我们总共有λ·N个轨迹,下一步是评估它们的期望回报,可以使用TPM精确计算(参见第4.2节)。保留N个最佳动作序列并继续下一个时间步骤。重复这个过程H个时间步后,我们返回最佳的动作序列。序列中的第一个动作用于与环境交互。
另一个设计选择是阈值v的取值。虽然在整个训练过程中使用固定的高回报是常见的做法,但我们遵循Ding等人(2023)的做法,采用自适应阈值。具体来说,在状态st处,我们选择v为p(Vt|st)的?-分位值,该值是使用TPM计算的。
采用的TPM的详细信息 : 本文使用概率电路(PCs)(Choi等,2020)作为Trifle有效性的示例TPM。PCs可以在与其大小成正比的时间内计算任何边际或条件概率。我们使用一种称为HCLT(Liu&Van den Broeck,2021)的先进PC结构,并使用潜变量蒸馏技术(Liu等,2022)优化其参数。有关额外的训练/推断细节,请参见附录B。
6 实验
本节逐步探讨了Trifle是否能够在不同情境下缓解推断时间子优化问题。首先,在标记的预期回报目标(RTG)是良好的性能指标(即单步情况)的情况下,我们研究了Trifle是否能够一致地采样更具回报性的动作(第6.1节)。接下来,我们在高度随机的环境中进一步挑战了Trifle,因为现有的RvS算法由于未能考虑到环境的随机性而导致灾难性失败(第6.2节)。最后,我们展示了Trifle可以直接应用于安全RL任务(具有动作约束),通过有效地对满足约束的条件进行调整(第6.3节)。总的来说,本节突显了TPMs在离线RL任务中的潜力。
6.1 与现有技术的比较
正如在第3节和图1中所示,尽管Gym-MuJoCo(Fu等,2020)基准测试中的标记的RTGs足以反映实际的环境回报,但现有的RvS算法由于其庞大且多维的动作空间而未能有效采样这些动作。图1(中)展示了Trifle实现了更好的推断时间优化性。本节进一步检查更高的推断时间优化分数是否会导致更好的性能表现。
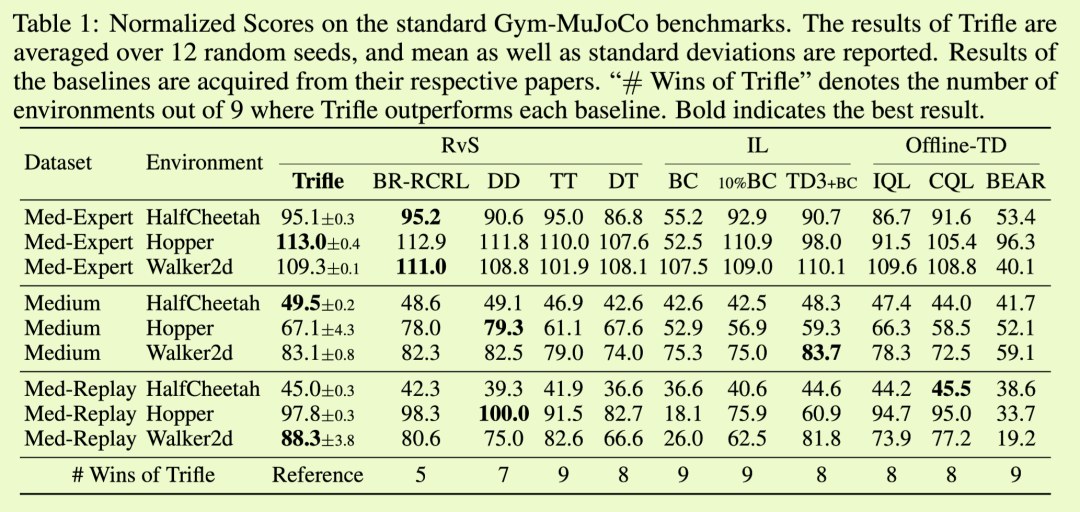
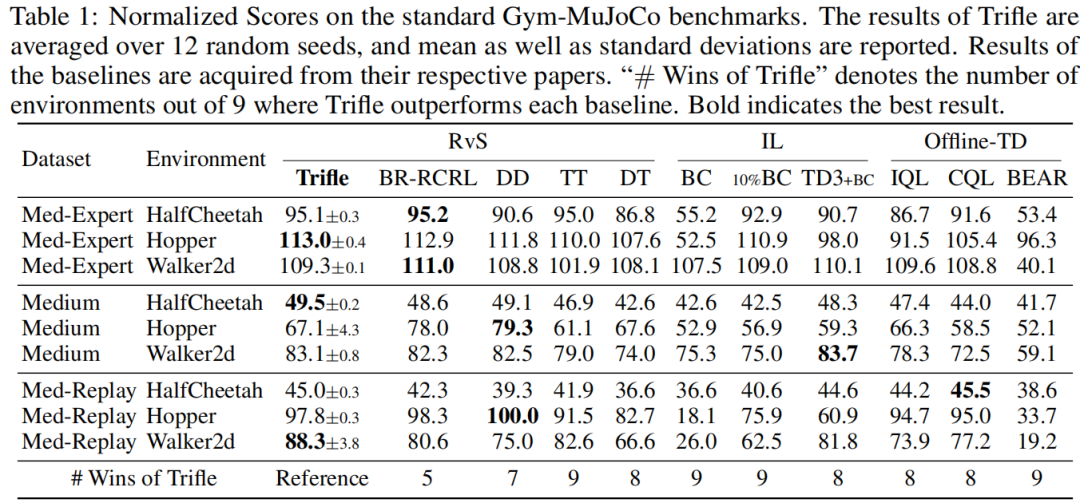
环境设置 Gym-MuJoCo基准套件在3个运动环境(HalfCheetah、Hopper、Walker2D)中收集轨迹,并为每个环境构建了3个数据集(Medium-Expert、Medium、Medium-Replay),从而产生了3×3=9个任务。对于每个环境,数据集之间的主要区别在于其轨迹的质量。具体而言,“Medium”数据集记录了从Soft Actor-Critic(SAC)(Haarnoja等,2018)代理收集的100万步。“Medium-Replay”数据集包含了在SAC代理的训练过程中记录在重放缓冲区中的所有样本。“Medium-Expert”数据集混合了100万步的专家演示和部分训练过的SAC策略或随机策略生成的100万步。结果经过归一化处理,以确保经过良好训练的SAC模型得分为100,随机策略得分为0。
基线 我们将Trifle与三类主要的离线RL方法进行比较:(i)RvS方法,包括轨迹变换器(TT)(Janner等,2021)、决策变换器(DT)(Chen等,2021)、决策扩散器(DD)(Ajay等,2022)和贝叶斯参数化RCRL(BR-RCRL)(Ding等,2023);(ii)离线TD学习方法(Offline-TD),包括IQL(Kostrikov等,2021)、CQL(Kumar等,2020)和BEAR(Kumar等,2019a);(iii)不明确编码奖励或值信息的模仿学习方法(IL)。具体而言,我们考虑了行为克隆(BC)(Pomerleau,1988)及其变体10% BC,后者仅使用10%的具有最高回报的轨迹,以及用于比较的TD3+BC(Fujimoto等,2019)。
由于标记的RTGs足够信息丰富,可以反映出行动的“优良性”,我们通过采用单步价值估计
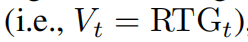
来实现Trifle,用于行动评估步骤和行动采样步骤,如第5节所述。有关更多算法细节,请参阅附录C.1。
实证洞见 结果如表1所示。首先,Trifle在Med-Replay数据集中取得了最先进的成绩,尤其在比另外两种类型的数据集包含更多次优轨迹的情况下表现良好。接下来,与每个单独的基线相比,Trifle在9个基准测试中的5到9个中取得了更好的结果。为了进一步研究TPM带来的好处,我们将Trifle与TT进行比较,因为在此设置中,它们的主要算法差异在于对行动进行采样时使用了改进的提议分布(式2)。我们可以看到,Trifle在所有环境中都比TT表现出更大的优势,表明Trifle能够从高维动作空间中稳健地采样出更好的行动。
表1:在标准Gym-MuJoCo基准测试上的标准化得分。Trifle的结果是基于12个随机种子的平均值,并报告了均值以及标准差。基线的结果来自于它们各自的论文。“Trifle胜出次数”表示Trifle在9个环境中超越每个基线的次数。粗体表示最佳结果。
6.2 随机环境:改进的健身房-出租车环境
本节进一步在具有高度次优轨迹和离线数据集中的标记RTGs的随机环境中挑战Trifle。正如在第3节中展示的那样,在这种情况下,由于转换动态的随机性,甚至很难获得准确的价值估计。第4.2节展示了Trifle在次优标记RTGs和随机环境下更可靠地估计和采样动作序列的潜力。本节通过比较以下四种算法来检验这一观点:(i) 采用Vt = RTGt的Trifle(称为单步Trifle或s-Trifle);(ii) 配备

的Trifle(称为多步Trifle或m-Trifle);(iii) 轨迹变换器(TT);(iv) 决策变换器(DT)。在这四种算法中,s-Trifle和DT不计算“更准确”的多步值,而TT通过蒙特卡罗样本逼近值。因此,我们期望它们的相对性能为DT ≈ s-Trifle < TT < m-Trifle。
环境设置 我们创建了Gym-Taxi环境的随机变体(Dietterich,2000)。如图3a所示,出租车位于一个包含乘客和目的地的网格世界中。出租车的任务是首先导航到乘客的位置并接他们,然后将他们送到目的地。每一步都有6个离散动作可用:(i)4个导航动作(北,南,东,西),(ii)接乘客,(iii)放下乘客。每当代理尝试执行导航动作时,它有0.3的概率朝一个随机选择的意外方向移动。在每个情节的开始,出租车、乘客和目的地都会随机初始化在25个、5个和4个位置之一。奖励函数定义如下:(i)每个动作扣除1分;(ii)成功交付乘客额外加20分;(iii)撞到墙壁扣除4分;(iv)撞到边界扣除5分;(v)非法执行接乘客或放下乘客动作扣除10分(例如,在乘客不在出租车上时执行放下乘客)。

图3:随机出租车环境的结果。所有报告的数字均是在1000次试验中平均得出的。#惩罚表示在一个情节内执行非法动作收到惩罚的平均次数,P(失败)表示未能将乘客送到目的地的概率。
遵循Gym-MuJoCo基准,我们通过在上述环境中运行Q-learning代理(Watkins&Dayan,1992)并记录成功将乘客送到目的地的前1000个轨迹来收集离线轨迹。
实证见解 我们首先检查了s-Trifle、m-Trifle和TT的估计回报的准确性。由于DT并未明确估计动作序列的值,因此排除了它。图2说明了这三种方法的预测回报与真实回报之间的相关性。首先,s-Trifle表现最差,因为它仅使用不准确的RTGt来近似真实回报。接下来,由于其能够精确计算多步值估计,m-Trifle优于TT,后者通过蒙特卡洛样本来近似多步值。
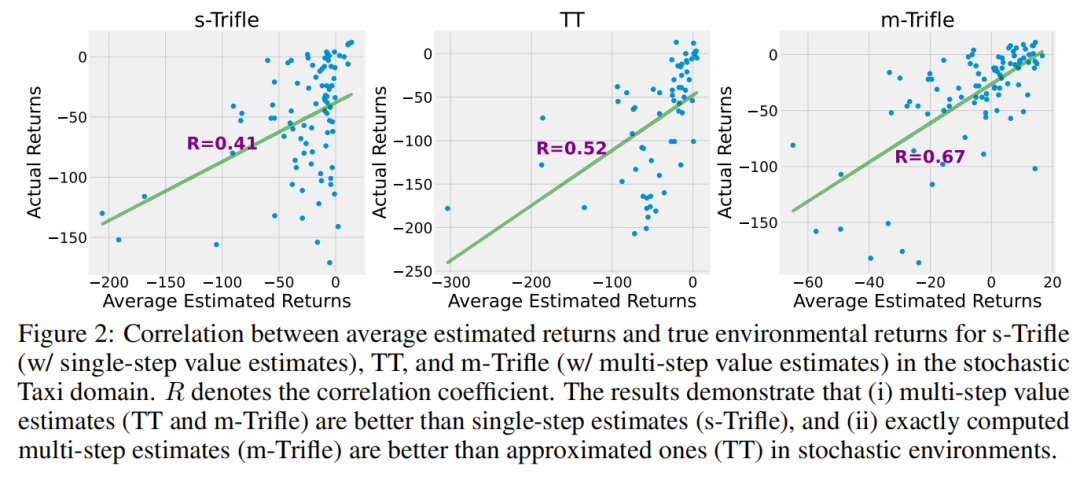
图2:在随机出租车环境中,s-Trifle(使用单步值估计)、TT和m-Trifle(使用多步值估计)的平均估计回报与真实环境回报之间的相关性。R代表相关系数。结果表明,(i)多步值估计(TT和m-Trifle)优于单步估计(s-Trifle),以及(ii)在随机环境中,精确计算的多步估计(m-Trifle)优于近似估计(TT)。
我们继续评估它们在随机Taxi环境中的性能。除了情节回报外,我们采用两个指标来更好地评估采用的方法:(i)#penalty:在一个情节内执行非法动作的平均次数;(ii)P(failure):在300步内未能将乘客运送到目的地的概率。如图3b所示,这四种算法的相对性能为DT < TT < s-Trifle < m-Trifle,这与预期结果基本一致。唯一的“令人惊讶”的结果是s-Trifle相对于TT的优越性能。这种行为的一个合理解释是,尽管TT可以更好地估计给定的动作,但其较差的性能是由于其无法有效地采样有益的动作所致。
6.3 动作空间受限的 GYM-MUJOCO 变体
本节展示了由于TPM能够计算条件概率,Trifle可以轻松地扩展到安全RL任务中。具体来说,除了实现高预期回报外,安全RL任务还需要满足对动作或未来状态的额外约束。因此,我们将约束定义为c,我们的目标是从
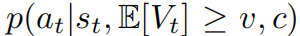
中采样动作,这可以通过在候选动作采样过程中额外条件化c来实现。
环境设置在MuJoCo环境中,at的每个维度表示在时间步t对铰接关节的某个转子施加的扭矩。我们考虑动作空间约束采用“施加在脚部转子上的扭矩值 ≤ A”的形式,其中A = 0.5是一个阈值,适用于三个MuJoCo环境:Halfcheetah、Hopper和Walker2d。请注意,Halfcheetah和Walker2d中有多个脚关节,因此约束应用于多个动作维度。对于所有设置,我们采用了介绍中的“Medium-Expert”离线数据集。
实证见解在这些受动作约束的任务中的关键挑战是需要考虑在采样某个动作变量的值时应用到其他动作维度的约束。例如,自回归模型在采样ait时不能考虑添加到变量ai+1t的约束。因此,尽管强制执行动作约束很简单,但同时保证良好性能仍然很困难。如表2所示,由于其能够精确地对动作约束进行条件化,Trifle在所有三个环境中明显优于TT。

表2:动作空间受限的Gym-MuJoCo变体的归一化得分。Trifle和TT的结果均基于12个随机种子的平均值,报告了均值和标准差。
7 相关工作及结论
在离线RL任务中,我们的目标是利用由未知策略收集的数据集,从而推导出一个改进的策略,而无需与环境进一步交互。在这种范式下,我们希望能够超越简单的模仿学习,并将行为策略的良好部分拼接起来。为了追求这样的能力,许多最近的工作将离线RL任务框架为条件建模问题,以生成具有高期望回报的动作(Chen等人,2021; Ajay等人,2022; Ding等人,2023)或其代理,如即时奖励(Kumar等人,2019b; Schmidhuber,2019; Srivastava等人,2019)。这一领域的最新进展可以归功于现代序列模型的强大表现力,因为通过准确拟合过去的经验,我们可以获得两种可能意味着高期望回报的信息:(i)环境的转换动态,这是以模型为基础进行规划的必要条件(Chua等人,2018);(ii)合理的策略先验,比随机策略更合理,可以改进(Janner等人,2021)。
虽然先前关于基于模型的RL(MBRL)的工作也利用了环境转换动态和奖励函数的模型(Kaiser等人,2019; Heess等人,2015; Amos等人,2021),但上述RvS方法更侧重于直接建模动作和其最终表现之间的相关性。具体来说,MBRL方法仅关注使用环境模型进行规划。尽管从理论上讲,MBRL很有吸引力,但需要重型机械来解决滚动过程中累积误差(Jafferjee等人,2020; Talvitie,2017)和分布之外问题(Zhao等人,2021; Rigter等人,2022)等问题。所有这些问题都给推断端增加了重大负担,这使得MBRL算法在实践中不太吸引人。相比之下,虽然RvS算法可以通过直接学习动作和它们的回报之间的相关性来减轻推断时间的负担,但标记的回报的次优性可能会显著降低其性能。解决此问题的一个潜在方法是将RvS算法与可以校正标记回报/RTG中错误的时序差异学习方法相结合(Zheng等人,2022; Yamagata等人,2023)。
除了旨在减轻由次优标记的RTGs引起的问题外,我们的工作采用了一种完全不同的方法——通过利用TPMs来减轻推断时间的计算负担(例如,通过有效地计算多步估计)。具体来说,我们确定了由序列模型的不可计算性引起的两个主要问题:一个涉及估计期望回报,另一个涉及有条件地采样动作。我们表明,借助于能够高效计算更多查询的能力,我们可以部分解决所识别的这两个问题。总之,这项工作提供了有关可计算模型对RvS算法潜在好处的积极证据,并鼓励开发更多关注推断的RvS方法。