VILA:引领视觉语言模型新纪元的先锋

VILA是一个由Nvidia和MIT联合开发的视觉语言模型,它融合了计算机视觉和自然语言处理两大领域的技术,旨在实现更加智能和自然的图像理解和语言交互。借助Nvidia强大的硬件支持,VILA在性能和效率上都达到了新的高度。
VILA的核心在于其能够联合处理视觉和语言信息的能力。传统的图像处理或自然语言处理模型往往只能处理单一模态的信息,而VILA则能够将图像和语言信息进行有效融合。这种跨模态的处理能力使得VILA能够更深入地理解图像内容,并根据语言指令做出相应的响应。
VILA核心特性
VILA不仅在图像问答基准测试中取得了显著的性能提升,更在视频问答基准测试中展现了其强大的多图像推理能力和上下文学习能力。此外,VILA还针对推理速度进行了优化,使其在保持高精度的同时,实现了高效的推理性能。
全面的预训练流程
VILA的预训练流程深入研究了视觉语言预训练过程,通过解冻大型语言模型(LLM)并融入视觉输入,实现了对图像和文本两种模态的联合建模。同时,VILA还利用交错图像文本数据,有效维护了文本单一模态的能力,从而实现了对视觉语言任务的全面支持。
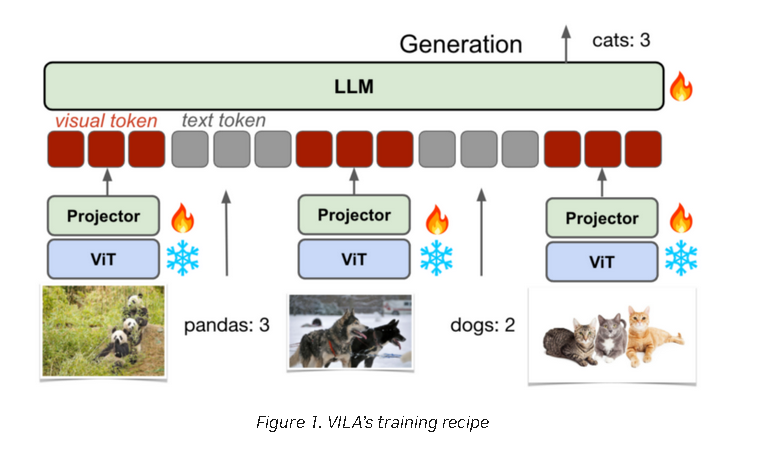
高效的指令调优方法
在指令调优阶段,VILA采用了联合监督微调(Joint SFT)的方法,通过同时加入文本指令数据和视觉指令数据,不仅有效缓解了仅使用视觉指令数据导致的文本能力退化问题,还进一步提升了模型在视觉语言任务上的表现。
强大的多模态处理方法
VILA能够处理任意数量的交错图像文本输入,支持多图像推理和视频理解。通过高效的训练和优化,VILA在处理复杂视觉语言任务时展现出了强大的性能,包括理解多图像逻辑、进行上下文学习和提供零次/少次学习能力等。
优化推理速度
为了提高推理效率,VILA采用了多种优化技术。其中,利用4位算术加权平均量化(AWQ)技术,VILA在保持高精度的同时,显著提高了推理速度。这使得VILA能够在NVIDIA RTX 4090和Jetson Orin等平台上实现实时推理,为边缘设备上的应用提供了强有力的支持。
VILA的性能表现
VILA在多个视觉语言基准测试中均取得了显著的性能提升。无论是图像问答任务(如VQA-v2、GQA等),还是视频问答任务,VILA都展现出了强大的多图像推理能力和在上下文学习能力。此外,VILA还能够处理复杂的视觉输入(如多图像、视频帧等),并生成详细且准确的描述,进一步拓宽了其应用场景。
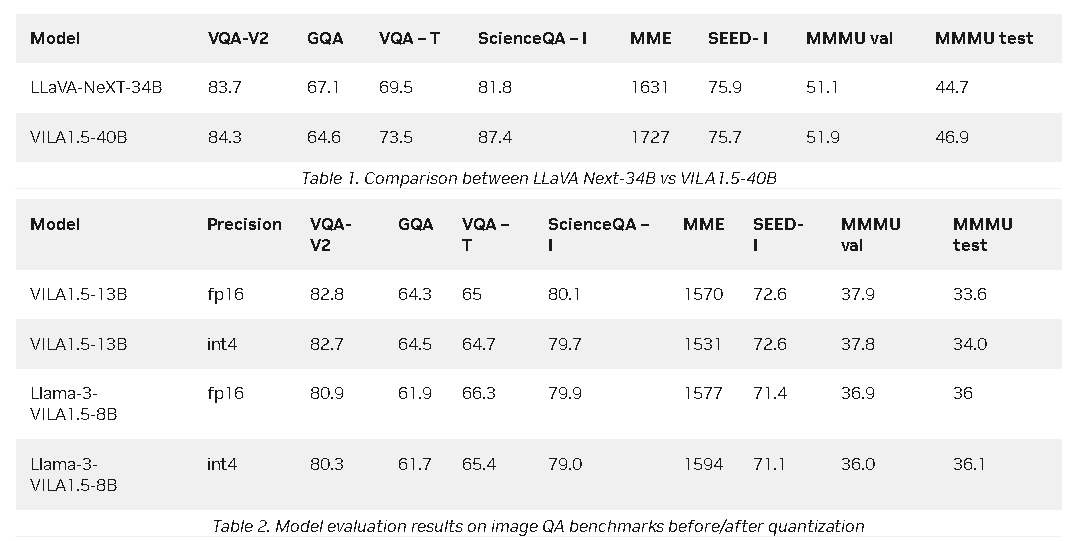
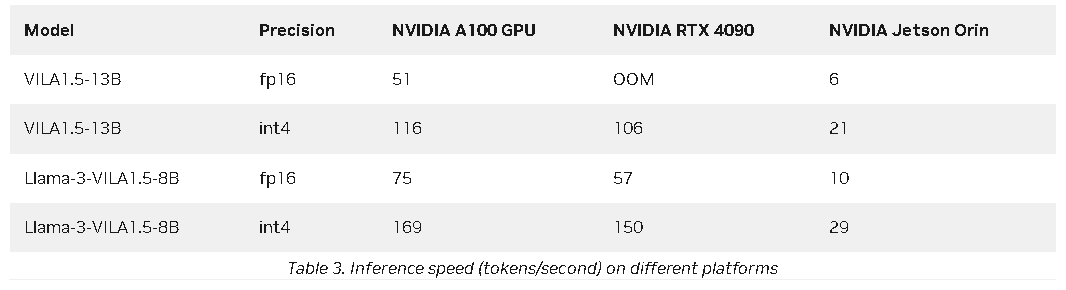
VILA在AI领域的应用
VILA,作为一种先进的视觉语言模型,在AI领域展现出了广泛的应用前景。其融合了计算机视觉与自然语言处理的技术,使得机器能够更深入地理解图像内容,并根据自然语言指令做出相应的响应。以下是VILA在AI领域的几个主要应用:
- 图像检索与理解
传统的图像检索主要基于关键词,但很多时候用户可能难以用准确的关键词来描述自己想找的图像。VILA能够理解自然语言描述,并根据这些描述来检索相关的图像,大大提高了图像检索的准确性和用户体验。
- 视觉问答系统
VILA可以用于构建视觉问答系统,这类系统能够回答关于图像内容的问题。例如,用户可以询问一张图片中某个物体的颜色、位置或与其他物体的关系等问题,VILA能够理解这些问题并提供准确的答案。
- 图像生成与编辑
结合生成对抗网络(GANs)或其他图像生成技术,VILA可以指导图像生成过程,根据用户的自然语言描述来生成符合要求的图像。此外,它还可以用于图像编辑,如根据用户描述对图像进行特定的修改或增强。
- 自动字幕与解说
在视频处理中,VILA可以自动生成与视频内容相匹配的文字描述,为视频添加字幕或解说词,这对于无障碍视频制作、视频内容摘要等场景非常有用。
- 机器人导航与交互
在机器人应用中,VILA可以帮助机器人更好地理解环境信息,并根据自然语言指令进行导航。此外,它还可以增强机器人与人之间的交互能力,使机器人能够更自然地理解和回应人类语言。
- 情感分析与推荐系统
通过分析图像和语言信息,VILA可以洞察用户的情感和偏好,从而为个性化推荐系统提供有力支持。这种技术在电商、社交媒体和广告推荐等领域具有广阔的应用前景。
- 辅助设计与创作
在设计和创作领域,设计师和艺术家可以借助VILA来寻找灵感或生成初步的设计草图。例如,通过输入“设计一个现代风格的客厅”,VILA可以生成符合这一描述的客厅设计图像或建议。
- 多模态数据分析
在大数据分析中,VILA能够处理包含图像、文本等多种模态的数据,从而提供更全面的数据分析和洞察。这对于市场调研、社交媒体分析等领域非常有价值。
总的来说,VILA在AI领域的应用广泛且多样,它不仅提高了机器理解和处理视觉与语言信息的能力,还为各种实际应用场景提供了强大的技术支持。
总结
VILA作为视觉语言模型领域的佼佼者,凭借其全面的预训练策略、高效的指令调优方法和优化的部署方案,不仅为视觉语言模型的研究提供了新的思路和方法,也为推动人工智能技术在多模态信息处理领域的应用做出了重要贡献。未来,随着技术的不断进步和应用场景的不断扩展,我们有理由相信VILA将继续引领视觉语言模型的新发展。