分享最新10篇大模型论文,涉及应用、多模态、推理增强、剪枝等热点话题!
分享最新10篇大模型论文,涉及应用、多模态、推理增强、剪枝等热点话题!

引言
好久没有给大家梳理文章了,今天分享8篇有关大模型(LLMs)的最新研究进展,其中涉及涉及大模型推理、应用、方法论、多模态、剪枝等热门研究方向。全部论文获取方式,后台回复:20240414
混合推理方法
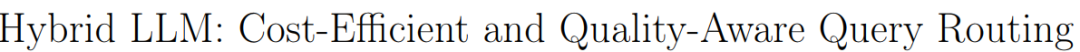
大模型在自然语言处理任务中表现出色,但是需要昂贵的云服务进行部署。而部署在成本较低的设备上的小模型,在响应质量上却不如大模型。作者考虑能否训练一个判别器,看这个Query是使用大模型回答好呢,还是用小模型回答好,将简单的Query路由到小模型上面,复杂的路由到大模型上面,从而节约计算成本。
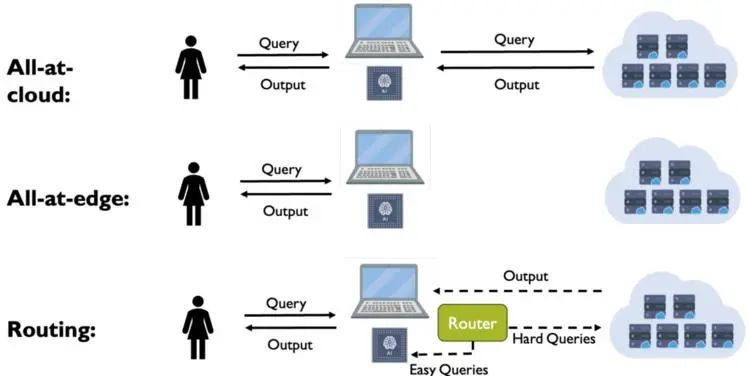
为此作者提出了一种混合推理方法,旨在结合大模型(LLMs)和小模型的优势,其核心是使用一个路由器,根据预测的查询难度和期望的质量水平来分配Query至不同的模型上面。
优质Token选择
传统的语言模型预训练方法,对每个Token都是采用下一个Token的预测损失,然而对于预训练模型来说,并非所有Token都是同等重要。
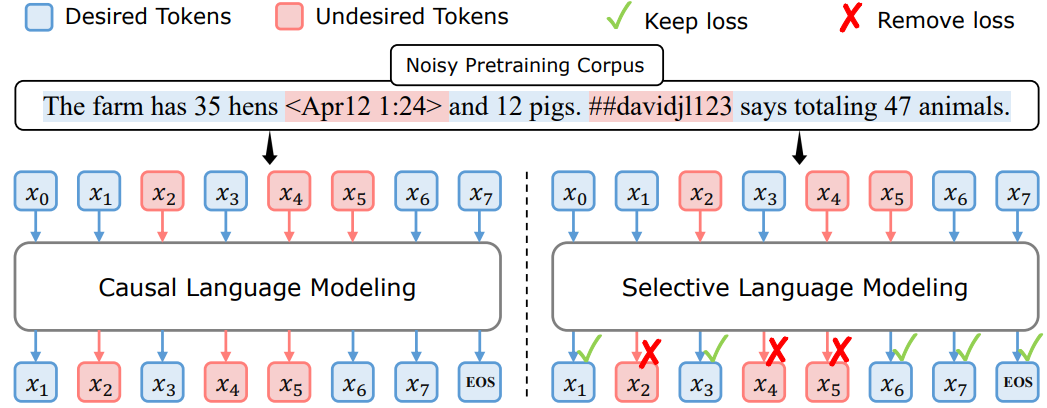
为此,本文作者进行了深入的分析,将Token进行分类,并提出了一种新型的语言模型训练方法:选择性语言建模法(SLM),实验结果表明:SLM方法不仅提高了模型性能还提高了训练效率,在数学任务上,使用SLM方法预训练的模型在少量样本准确率上比传统方法提高了多达30%;在通用任务上,SLM方法也实现了平均6.8%的性能提升。
Think-and-Execute框架
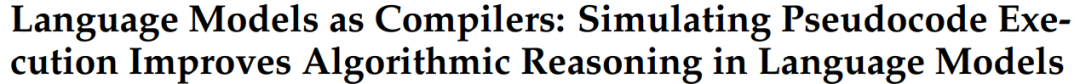
算法推理能力是指理解问题背后的复杂逻辑并将其分解为一系列推理步骤的能力。为了提升大模型复杂推理能力,本文作者提出了Think-and-Execute框架。
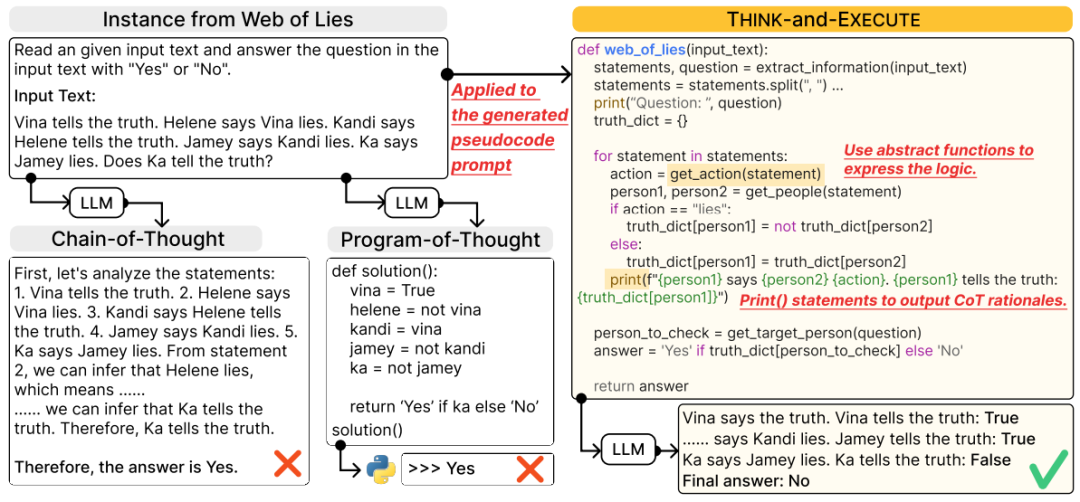
具体来说,它将语言模型的推理过程分解为Think、Execute两个步骤,其中 (1)在Think步骤中,作者发现了一个在所有实例之间共享的任务级逻辑,用于解决给定的任务,然后用伪代码表达该逻辑;(2)在Execute步骤中,作者进一步针对每个实例定制生成的伪代码并模拟代码的执行。实验证明,该方法能够更好地改进了 LM 的推理。
aiXcoder-7B
北大发布最强开源代码大模型:aiXcoder-7B,可商用。

aiXcoder 7B 代码大模型,不仅在代码生成和补全任务中大幅领先同量级甚至超越 15B、34B 参数量级的代码大模型;还凭借其在个性化训练、私有化部署、定制化开发方面的独有优势,成为最适合企业应用、最能满足个性化开发需求的代码大模型。aiXcoder 7B 的全部模型参数和推理代码均已开源,可以通过 GitHub、Hugging Face、Gitee 和 GitLink 等平台访问。
交互培训框架
在人类的社交活动中,为了更有效地在工作和生活中与他人沟通,需要一定的社交技能,比如解决冲突。然而,社交技能的练习环境对于大多数人来说通常是遥不可及的。特别是由专家训练这些技能时,往往耗时、投入高且可用性有限。现有的练习和反馈机制很大程度上依赖专家监督,使训练难以扩展。此外,经过专业培训的教练也缺乏,而大多数可以提供定制化反馈的教练无法帮助大量有需要的人。
斯坦福研究人员提出了APAM交互培训框架,其利用 LLM 通过现实实践和量身定制的反馈进行社交技能训练!其实这好像是斯坦福发表的第二篇有关提高沟通技巧的培训框架,另外一篇是提升沟通技巧!斯坦福&微软 | 提出交互培训框架:IMBUE,准确率比GPT-4高出25%,两个可以参考学习。
中文为中心的模型

当前,绝大多数大模型(LLMs)基本上都是以英文语料库训练得到的,然后经过SFT来匹配不同的语种。然而你,本文作者挑战以英语为中心的主流模型训练范式,考虑以中文为基础的预训练模型是否可以激活对其它语言的能力。以中文为中心的方法如果成功,可能会显著推动语言技术的民主化,为创造反映全球语言多样性的包容性模型提供洞见。
作者在从头开始训练中文大模型,在训练过程中「主要纳入中文文本数据」,最终作者得到了一个2B规模的中文Tiny LLM(CT-LLM)。结果表明,该模型在中文任务上表现出色,且通过SFT也能很好的支持英文。
谷歌Gecko
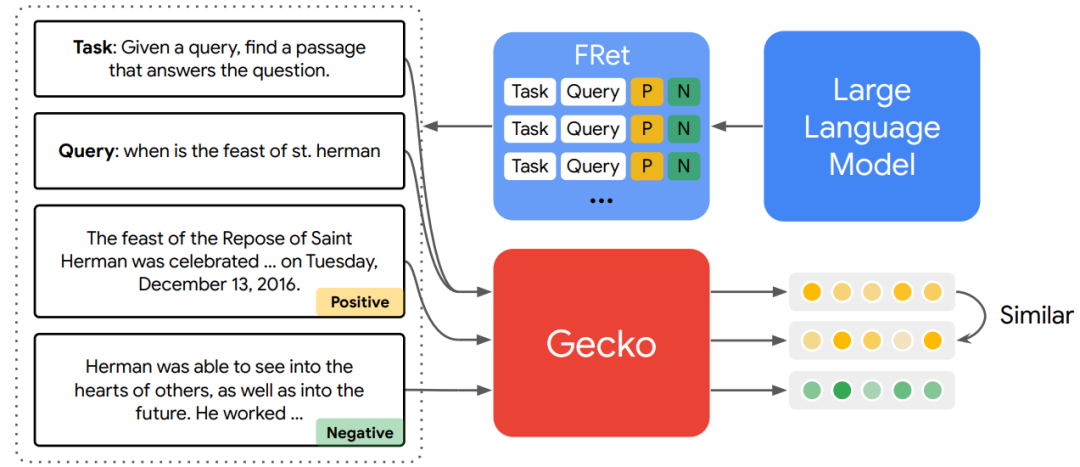
谷歌 DeepMind 的研究者提出了 Gecko,这是一种从 LLM 中蒸馏出来的多功能文本嵌入模型,其在 LLM 生成的合成数据集 FRet 上进行训练,并由 LLM 提供支持。通过将 LLM 的知识进行提炼,然后融入到检索器中,Gecko 实现了强大的检索性能。
在大规模文本嵌入基准(MTEB,Massive Text Embedding Benchmark)上,具有 256 个嵌入维度的 Gecko 优于具有 768 个嵌入尺寸的现有模型。具有 768 个嵌入维度的 Gecko 的平均得分为 66.31,在与 7 倍大的模型和 5 倍高维嵌入进行比较时,取得了相竞争的结果。
Infini-attention

对于人工智能(AI)来说,内存资源是神经网络模型进行高效计算的必要条件。然而,由于Transformers 中的注意力机制在内存占用和计算时间上都表现出二次复杂度,所以基于Transformer的大模型就更加依赖内存资源。
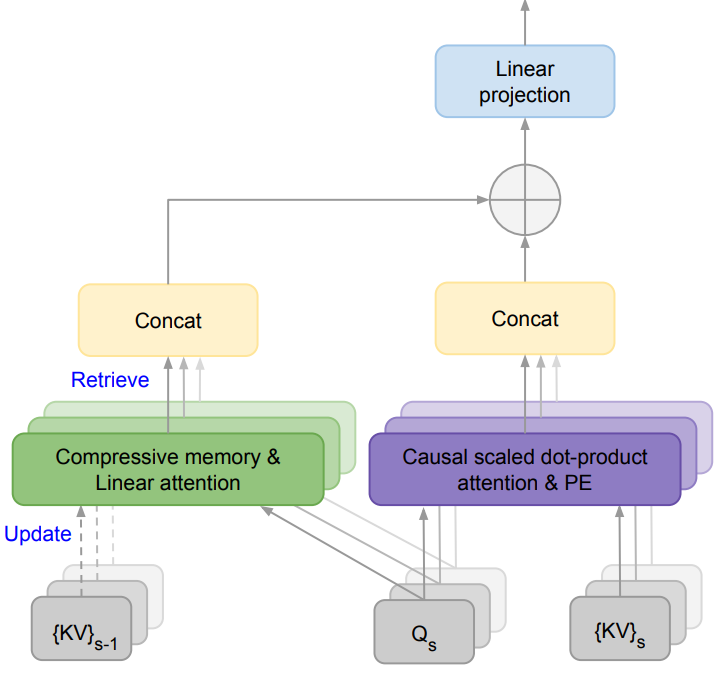
为解决大模型(LLMs)在处理超长输入序列时遇到的内存限制问题,本文作者提出了一种新型架构:Infini-Transformer,它可以在有限内存条件下,让基于Transformer的大语言模型(LLMs)高效处理无限长的输入序列。实验结果表明:Infini-Transformer在长上下文语言建模任务上超越了基线模型,内存最高可节约114倍。
大模型剪枝
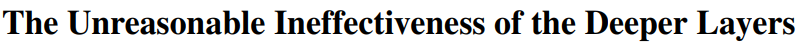
作者对大模型层剪枝策略进行了研究,发现删除模型层不超过一半,性能效果都不会有很大程度的下降。具体要删除哪些层块呢?
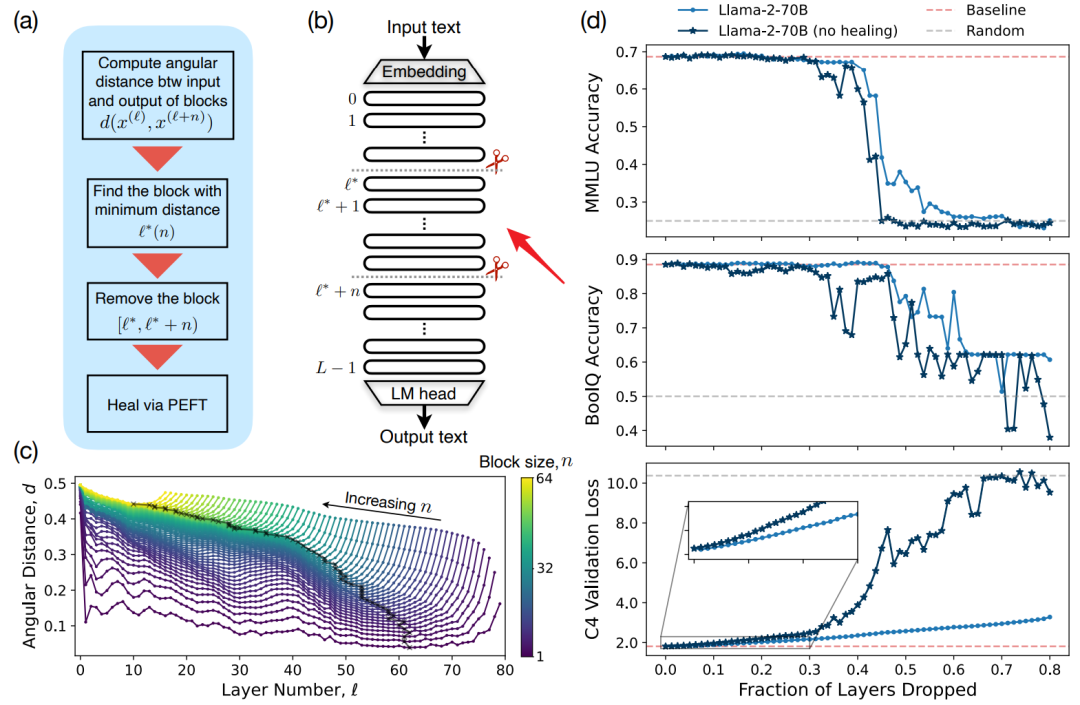
本文作者考虑层之间的相似性来确定要修剪的最佳层块,同时为了修补剪枝带来的损伤,作者又使用参数高效微调 (PEFT) 方法QLoRA进行微调。一顿操作下,模型即减少了参数,又提高了模型推理效率。
VLM

虽然说VLM 取得了巨大进步,但与 GPT-4 和 Gemini 等高级模型相比差距还是很大。本文作者认为主要原因是高分辨率视觉标记不够、vision推理数据质量不高。
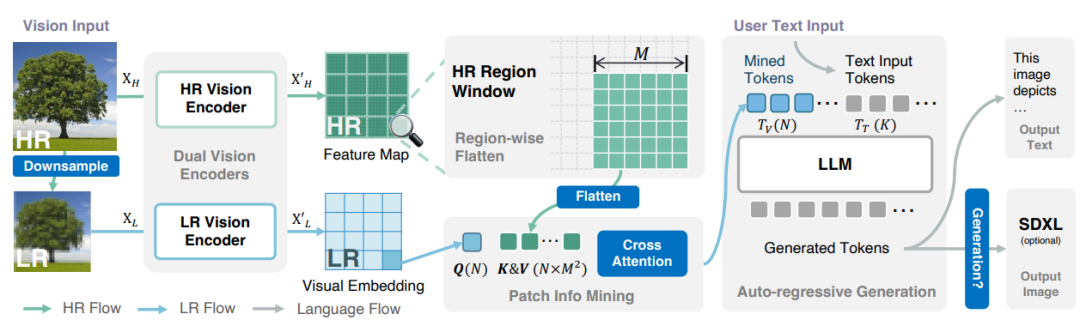
为此作者利用额外的视觉编码器进行高分辨率细化,构建了一个高质量的数据集。构建了一个Mini-Gemini 架构,支持一系列从 2B 到 34B 的密集和 MoE 大型语言模型 (LLM)。在零样本测试集上超过了私有模型。