如何利用IPIDEA代理IP优化数据采集效率?

一、 前言
?? 在全球化与信息化交织的当代社会,数据已成为驱动商业智慧与技术革新的核心引擎。网络,作为信息汇聚与交流的枢纽,不仅是人们获取知识的窗口,更是商业活动与技术创新的广阔舞台。在这个信息繁荣的时代,Python网络爬虫成为采集、分析大数据的重要工具,但实际操作中却常遇挑战。
?? 这里简单介绍一下,什么是网络爬虫:网络爬虫是一种自动化程序,能够遍历互联网上的不同网页,并提取其中的信息,这些信息可以是文本、图像、视频等各种形式的数据。我们可按需提取所需要的各种数据,以供后续分析和应用。
??然而,网络环境复杂,信息来源丰富但分散,导致网络爬虫的效率大打折扣。即使爬虫技术本身已经相当成熟,但面对海量的信息和复杂的网络环境,仍然难以保证高效的数据采集。
??代理IP技术,作为一种可行的解决方案,可以更加灵活地进行数据爬取,避免被网站识别为异常访问,从而提高数据采集的速度和稳定性,为商业决策和技术创新提供有力的数据支持。
??本人也测试过很多的代理IP品牌,有一款用下来体验很不错的品牌——IPIDEA
二、 IPIDEA介绍
?? IPIDEA在一众提供海外代理IP的品牌中,名气还是挺大的,主要确实很好用。
??IPIDEA很多优点,比如覆盖的国家多、提供真实的住宅IP、连接很稳定、支持大量并发、有专门的技术团队提供支持等。在这我就简单讲解几点,就不一一完全列举出来了。
??1. 全球覆盖: IPIDEA 在全球各地部署了服务器,我们可以根据需要选择不同地区的代理 IP,实现全球范围的公开访问和爬虫需求。目前覆盖了包括美国、英国、加拿大、印度、韩国等热门国家在内的220多个国家和地区,提供超9000万IP数量。

??2. 多种代理方案:IPIDEA目前为提供了5种解决方案:
??动态住宅、 静态住宅、 独享数据中心、 动态长效ISP、 动态数据中心。一般网络爬虫主要使用到的是“动态住宅”,它能实现公开数据爬虫率大于99.9%。
??动态住宅代理:与静态代理IP有所不同。静态代理IP在连接后一直保持不变,而动态住宅代理IP则会在一段时间内动态变化,可进行类真人的网络爬虫。
??如果我一个师兄使用了IPIDEA动态住宅代理,那IP地址可能会每隔一段时间就会轮换,比如每隔几分钟、几小时或者每请求一次换一下,这可以更好地隐私保护,提高爬虫的效率。

?下面代码演示如何实现动态住宅代理IP的自动轮换:
import requests
from bs4 import BeautifulSoup
import random
import time
# 定义代理IP列表
proxy_list = [
{'ip': 'YOUR_PROXY_IP_1', 'port': 'YOUR_PROXY_PORT_1'},
{'ip': 'YOUR_PROXY_IP_2', 'port': 'YOUR_PROXY_PORT_2'},
# 添加更多代理IP...
]
# 定义目标网站列表
target_urls = [
'https://www.amazon.com/',
'https://support.reddithelp.com/',
# .......
]
# 随机选择一个代理IP
def get_random_proxy():
return random.choice(proxy_list)
# 发送带代理的请求
def send_request(url, proxy):
try:
response = requests.get(url, proxies=proxy)
if response.status_code == 200:
return response.text
else:
print("请求失败 状态码:", response.status_code)
return None
except requests.exceptions.RequestException as e:
print("发生异常:", e)
return None
# 解析页面内容
def parse_content(html):
soup = BeautifulSoup(html, 'html.parser')
# 根据需要提取相关数据例如,找到页面中的链接、文本内容等
return soup
# 主程序
def main():
for url in target_urls:
# 随机选择一个代理IP
proxy = get_random_proxy()
proxy_url = f"http://{proxy['ip']}:{proxy['port']}"
proxies = {'http': proxy_url, 'https': proxy_url}
# 发送带代理的请求
html_content = send_request(url, proxies)
if html_content:
# 解析页面内容
parsed_content = parse_content(html_content)
# 在这里可以根据需求处理解析后的内容
print(f"从 {url} 获取到的内容:", parsed_content)
#注意这里要休眠一段时间,防止对目标网站造成过大负荷
time.sleep(random.randint(1, 5))
if __name__ == "__main__":
main()??此代码主要通过随机选择代理IP来发送请求,可以有效地提高数据采集效率和保护隐私安全。
??此外还有其他优势:
??3. 稳定可靠: IPIDEA 具有较高的稳定性和可用性,大家可以放心地使用代理 IP 进行数据采集等操作,减少因代理服务器不稳定而导致的中断和失败。
??4. 灵活性: 大家可以根据自己的需求选择不同类型的代理服务,包括 HTTP、HTTPS、SOCKS 等不同协议的代理,以及不同地区、不同类型的代理方案,满足用户的个性化需求。
??假设我一个师兄,他现在在美国,他可以根据自己的需求随意将IP定位到德国、印度、日本等国家,此外他还可以定时轮转、随机更换或者根据请求量动态更换。通过设置他自己定义的请求头信息,以真实用户身份访问,降低被识别为异常访问的风险。IPIDEA这种灵活性使用户能够访问心里所想任何地区的公开内容或服务,同时确保链接的稳定性和安全性,简直不要太爽了。

??5. 提高数据采集效率: IPIDEA海外代理可以帮助分布式部署数据采集任务,实现多IP并发访问公开数据,提高网络爬虫的效率和速度,从而获取多样化的数据资源,为数据分析和挖掘提供更广泛的信息基础。
??6. 保护隐私安全: 使用海外代理可以保护用户的真实IP地址,提高个人隐私安全,减少被跟踪和定位的风险。
??我的师兄又来啦,假设他在日常生活中,面对一些不可抗力因素,比如自然灾害等,他能够借助IPIDEA海外代理IP,快速访问各地的新闻网站和社交媒体平台。这样,他就能及时获取到原本无法访问的内容,掌握实时的事件报道和信息,更好地了解世界动态。
??再比如,我的师兄在一些流媒体平台或网站上想浏览一些东西(安全起见,懂得都懂)他又想看又不想暴露自己的真实IP地址和位置信息…额,通过使用海外代理IP,他可以保护自己的真实IP地址,避免被网站或服务追踪或识别。
??– 以下是测试代理IP是否连接成功的代码示例:
import requests
# 定义获取代理IP的地址
p_ip = 'YOUR_PROXY_IP'
#定义获取代理IP的端口
p_port = 'YOUR_PROXY_PORT'
# 构建完整的代理地址
p_url = f'http://{p_ip}:{p_port}'
# 定义访问目标网址
target_url = 'https://www.amazon.com/USA/s?k=USA&page=2'
# 设置代理
proxies = {
'http': p_url,
'https': p_url,
}
# 发送带代理的请求
try:
response = requests.get(target_url, proxies=proxies)
# 检查响应状态码
if response.status_code == 200:
print("代理IP测试成功!")
else:
print("代理IP测试失败,状态码:", response.status_code)
except requests.exceptions.RequestException as e:
print("发生异常:", e)
# 代码会发送一个带有代理的HTTP请求到target_url的网站,然后检查响应状态码以确定代理是否有效。??7. 响应迅速:IPIDEA代理服务器能够快速响应并转发请求,以便我们能够快速高效的获取数据。以下是我测试的结果展示:
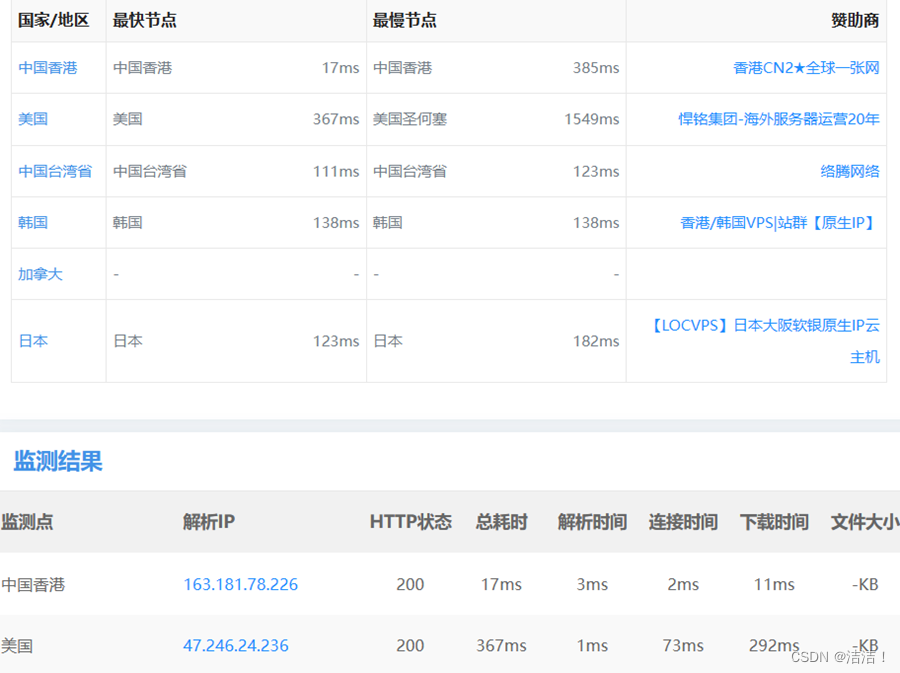
??可以看到香港地区速度很快,只有17ms延迟。延迟越低,表示请求速度越快,数据获取过程中的速度也随之提升。这显示了IPIDEA在数据获取方面的强大能力。
??综上所述,上面描述的IPIDEA 代理有很多优点,它适用于各种海外代理IP需求,包括数据采集、SEO优化、市场调查等。那废话就不多说了,咱们一起体验一下吧!
三、体验步骤
- 首先登录官网,可以看到新用户可以免费领取17.5G流量,用来测试IP质量足够了,想领取的点击此处专属链接领取哦~
- 点击–【获取代理】–【API获取】–右边绿色的【生成链接】
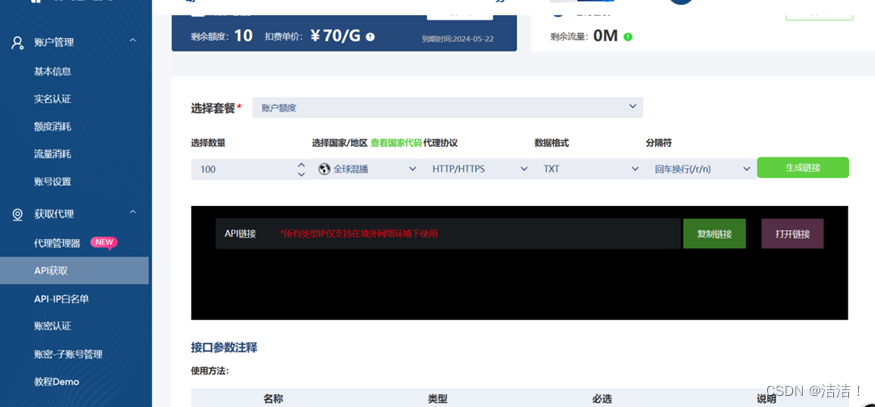
- 可以看到如下界面: ?? 如果点击【确定】可直接将本机IP添加到白名单,如果是其他电脑使用代理IP,就点【其他白名单】进行添加(注意:这里需要把ip添加到白名单才能正常使用哦)
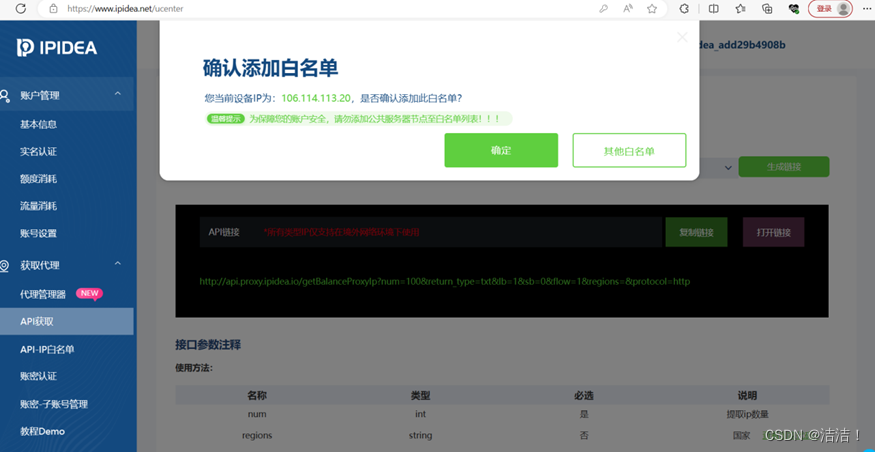
- 把IP添加到白名单之后,点击【复制链接】,然后直接到浏览器中请求,就可看到新的ip和对应的端口

- 然后我们就可以做一些Python爬虫相关的应用啦!(当然它能做的事情还有很多哟)
四、实战训练
我将运用Python爬虫技术,提取全球最大电商平台amazon上的商品信息和价格。
??注意下面代码我省略了自己的账户和密码:
import requests
import json
from re import findall
class IPIDEAProxy:
def __init__(self):
self.user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0'
self.headers = {
'User-Agent': self.user_agent
}
self.login_url = "https://api.ipidea.net/g/api/account/accountLogin"
self.get_user_info_url = "https://api.ipidea.net/g/api/user/getUserInfo"
self.get_new_ips_url = "https://api.ipidea.net/g/api/tiqu/new_get_ips"
self.add_white_url = "https://api.ipidea.net/g/api/white/add"
# 登录IPIDEA
def login(self, account, password):
body = {
"account": account,
"password": password
}
response = requests.post(self.login_url, headers=self.headers, data=body)
json_object = json.loads(response.text)
session_id = json_object.get("ret_data", {}).get("session_id")
return session_id
# 获取新的IP地址
def get_new_ips(self, session_id):
if not session_id:
return None, None
self.headers["Session-Id"] = session_id
body = {
"num": 1,
"type": 1,
"tiqu_type": "balance",
"protocol": 1,
"line_break": 1,
}
response = requests.post(self.get_new_ips_url, headers=self.headers, data=body)
json_object = json.loads(response.text)
links = json_object.get("ret_data", {})
for _, link in links.items():
response = requests.get(link)
ip_info = response.text.split(":")
if len(ip_info) == 2:
proxie_ip = ip_info[0]
proxie_port = ip_info[1].strip()
return proxie_ip, proxie_port
else:
data = json.loads(response.text)
if data.get("success") == "false":
request_ip = data.get("request_ip")
if request_ip:
if self.add_white(request_ip):
response = requests.get(link)
ip_info = response.text.split(":")
if len(ip_info) == 2:
proxie_ip = ip_info[0]
proxie_port = ip_info[1]
return proxie_ip, proxie_port
return None, None
# 将IP地址添加到白名单
def add_white(self, request_ip):
body = {
"ip": request_ip,
"remark": "Generated by script"
}
response = requests.post(self.add_white_url, headers=self.headers, data=body)
data = json.loads(response.text)
if data.get("msg") == "success":
return True
return False
# 返回代理IP
def get_proxies(self, ip, port):
proxies = {
'http': f'http://{ip}:{port}',
'https': f'http://{ip}:{port}',
}
return proxies
class Amazon:
def __init__(self):
self.proxy_manager = IPIDEAProxy()
self.ama_url = " https://www.amazon.com/USA/s?k=USA&page=2 "
self.cookies = 'your_cookie_here'
# 获取amazon网站商品页面内容
def get_ama_page(self, proxies):
headers = {
'User-Agent': self.proxy_manager.user_agent,
'Cookie': self.cookies
}
response = requests.request("GET", self. ama_url, headers=headers, proxies=proxies)
return response.text
# 解析amazon网站商品页面,提取商品信息和价格
def parse_ama_page(self, page_content):
image_pattern = r'data-lazy-img="//(.+?)"'
price_pattern = r'<span class="J_%s">(.*?)</span>'
goods_names = findall(image_pattern, page_content)
prices = findall(price_pattern % 'price', page_content)
return goods_names, prices
# 获取amazon商品信息和价格
def get_ama_goods_info(self):
session_id = self.proxy_manager.login(your_account, your_passwd)
proxy_ip, proxy_port = self.proxy_manager.get_new_ips(session_id)
if proxy_ip and proxy_port:
proxies = self.proxy_manager.get_proxies(proxy_ip, proxy_port)
page_content = self.get_ama_page(proxies)
goods_names, prices = self.parse_ama_page(page_content)
for goods_name, price in zip(goods_names, prices):
print(goods_name, price)
else:
print("Failed to get proxies.") 五、结语
??代理IP就像网络爬虫的隐身衣,不仅能保护真实身份,避免被攻击或追踪,还能轻松获取市场公开数据。
??IPIDEA作为专业的海外代理IP服务平台,为开发者提供了实现全球化数据采集和访问,解决了工作中不少棘手的麻烦问题。期待IPIDEA未来继续努力,为用户提供更全面、更优质的使用体验。