统一元数据:元模型定义、元数据采集
原创
背景
元数据管理可分为如下5个流程步骤:元模型定义、元数据采集、元数据加工、元数据存储、元数据应用。其中,元模型定义是整个元数据管理的前提和规范,用于定义可管理的元数据范式。元数据采集是元数据来源的重要途径,提供可管理的元数据原料,而如何进行可扩展且高效的元数据采集也是元数据管理的难点之一。本文将主要针对元模型定义、元数据采集两个模块进行详细说明。

元模型定义
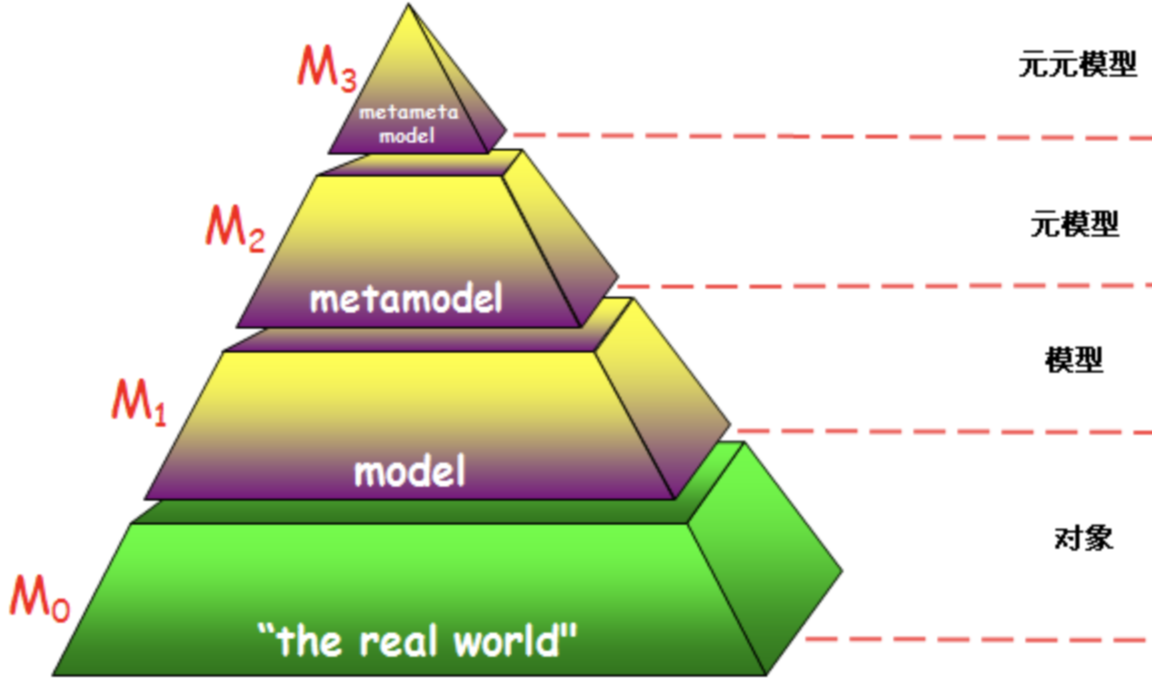
元模型是元数据标准的M2层,是对元数据M1层的抽象。更多详情可参考《数据资产管理体系与标准》。
例如:一个Hive库表user.student,字段有id, name, age,各层级对应的样例数据是:
- M0:对象层(数据层),可对应student记录,例如,{id=1, name='zhangsan', age=18}
- M1:模型层,即元数据,是针对M0数据层的抽象,定义的schema信息(库表定义):{db=user, table=student, columns={id:int, name:string, age: int}}。基于元数据定义数据范式
- M2:元模型层,是针对M1模型层的抽象,例如,Hive元模型可理解为Hive Metastore的相关表定义
- M3:元元模型层
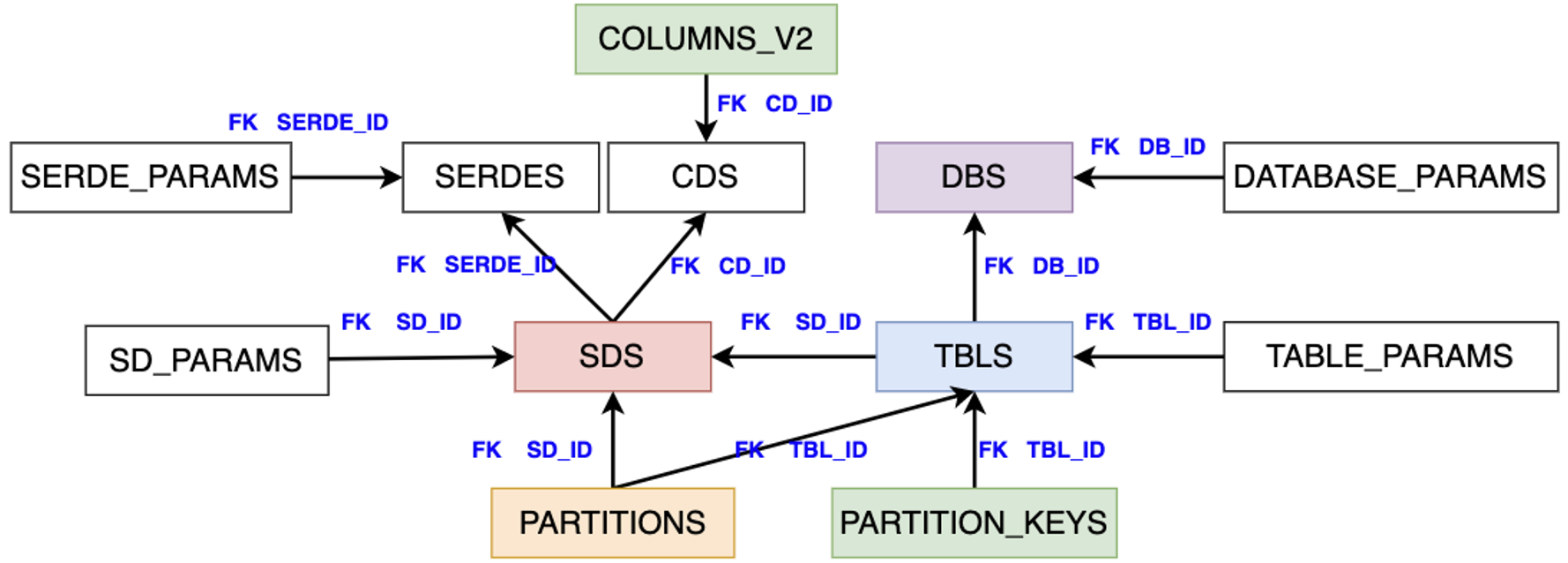
Hive Metastore 的元模型定义如下所示,一个库表即代表一个元模型,其中有颜色的库表是核心元模型:
- DBS:DB库定义
- TBLS:Table表定义,外键关联库DB_ID、关联物理存储SD_ID
- SDS:Table表物理存储相关,外键关联序列化SERDE_ID、关联字段存储CD_ID
- COLUMNS_V2:表字段定义
- PARTITION_KEYS:表分区字段定义,外键关联表:TBL_ID
- PARTITIONS:表分区列表详情,外键关联表:TBL_ID
元模型的抽象可以为元数据管理带来灵活性,但会引入系统复杂性和高维护成本。因此元模型并不是越灵活越好,在元模型设计时,需考虑使用场景决策元模型的管理。为满足使用场景和兼容系统简易性,我们限制元模型自定义管理,只抽象了两种固定的元模型:
- Hive数据模型:支持元数据在线数据目录功能,对外提供与Hive Metastore一致的能力,可基于Thrift接口对接计算引擎调用
- 通用数据模型:支持关系型数据源的数据治理,如MySQL、PG、Oracle等元数据管理;
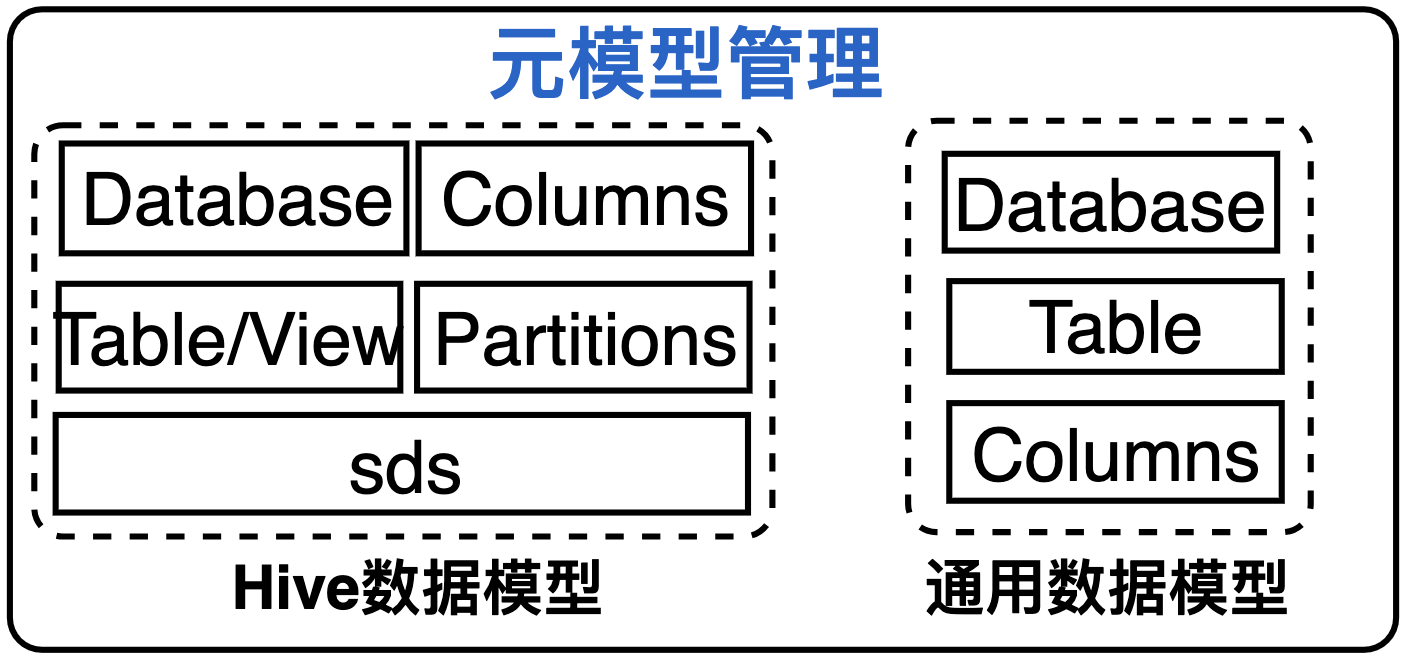
备注:如果需考虑文件元数据等场景,需要对元模型扩展。对于复杂元模型的定义、元元模型管理可参考Apache Altas类型系统的实现,更多详情可参考《业界元数据管理:方案设计概览》
元数据采集
系统架构
元数据采集是获取元数据的重要途径之一,通过对不同调度任务的封装,元数据采集可分为两种类型:
- 元数据推断:通过读取并解析存储系统的数据文件,自动识别和推断该数据文件对应的Schema信息;
- 元数据Crawler:主要通过PULL方式主动定时的周期性拉取元数据信息;同时也支持引擎以Hook的方式,通过固定的消息格式PUSH上报元数据信息。根据不同的底层数据源引擎,主要分为两种类型:(1). 对于传统关系型数据库(如MySQL等),使用通用的JDBC连接方式,定义各数据源类型的元数据采集SQL语句,从底层引擎的元数据内置系统库表爬取所需元数据信息;(2). 对于其他大数据组件元数据(如Hive、HBase等),元数据可能不支持JDBC连接方式获取,我们会根据其数据源特点进行自定义扩展实现。
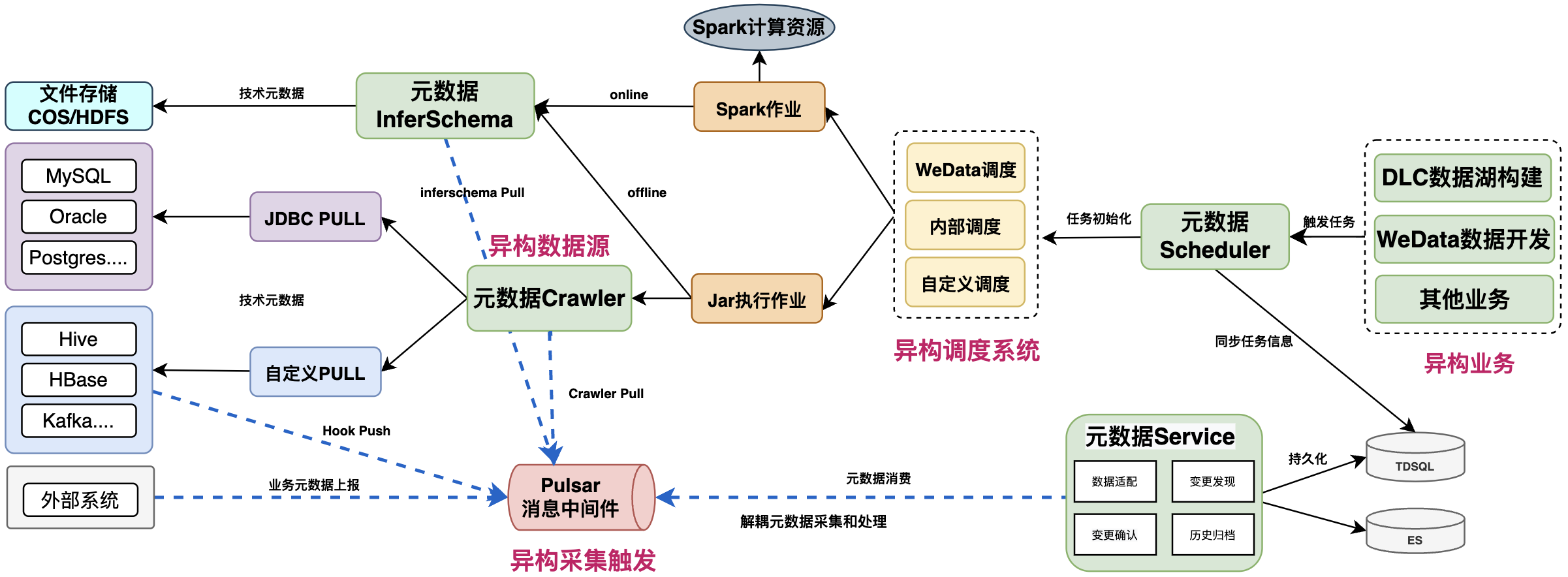
元数据采集系统的整体架构如图所示,为保证扩展和通用性,具备多维度的异构适配:
- 异构业务:允许多样化的业务对接,触发元数据采集任务,如支持DLC数据湖计算、WeData数据开发治理系统;
- 异构调度系统:支持多样化的采集任务调度,包括内置调度、自定义调度、WeData调度;
- 异构数据源:
- 支持多类型的JDBC数据源,PULL方式调用JDBC连接获取元数据信息
- 对于非JDBC数据源,如HBase、Hive等,支持自定义PULL方式,获取元数据信息;
- 对于特殊组件,如Hive,可实现组件Hook,基于PUSH主动上报
- 业务元数据支持PUSH主动上报
- 异构采集触发:基于消息中间件,解耦元数据的采集过程和处理过程;
元数据推断
元数据推断(InferSchema):也称为元数据发现,主要在数据湖场景使用,用于schema推断。对于已存储的数据文件,识别文件信息,自动发现并加载Schema元数据,便于用户一键迁移的数据湖分析场景,如DLC数据湖计算。
元数据推断通过读取并解析存储系统(HDFS、COS等)的数据文件,自动识别和推断该数据文件对应的Schema信息(字段及字段属性),主要考虑因素如下:
- 访问权限保证
- 支持的文件类型和压缩方式:
- 文件类型:文本文件(包括Log、TXT等)、CSV、Json、Parquet、ORC、AVRO;
- 压缩方式:非压缩,gz压缩,snappy压缩
- 超大文件读取识别的性能问题
最简单的实现可直接复用spark inferSchema能力,对于特定业务需求再进行对应改造:
val people = spark.read.format("csv")
.option("sep", ";")
.option("inferSchema", "true")
.option("header", "true")
.load("cos://examples/src/main/resources/people.csv")
val schema = people.schema;元数据Crawler
元数据Crawler,即为通用的元数据采集,一般有两种采集方式:PULL、PUSH,为减少对数据源的侵入性,建议优先采用PULL方式。
- PULL主动采集:元数据管理系统定时周期性采集,采集周期应支持设定,以适配数据源差异化的更新频率;
- PUSH被动采集:由人工发起或外部系统通过API主动上报,人工发起时,可以采用手动上传元数据文件或主动启动采集任务的方式来完成。
社区开源组件的采集实现方式整理如下:
组件 | 方式 | 实现 |
|---|---|---|
Apache Atlas | PUSH | 自定义Hive Hook上报Kafka,需适配不同Hive版本 |
Lyft Amundsen | PULL | Python采集脚本,连接HMS的元数据库 |
Linkedin Datahub | PULL | Python ORM框架是SQLAlchemy |
Schemacrawler | PULL | JDBC适配器获取不同JDBC数据源的元数据(仅支持JDBC数据源) |
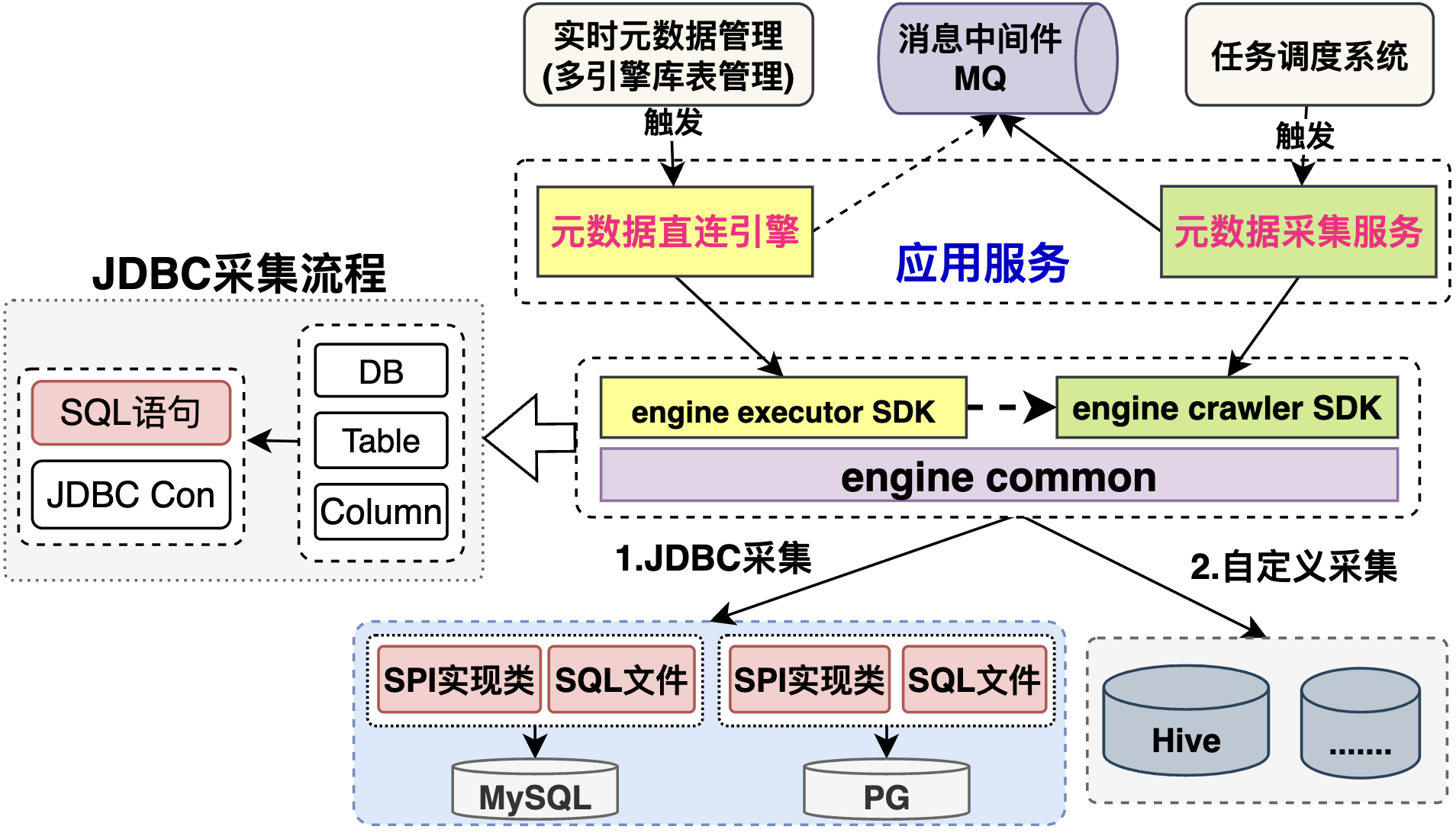
元数据Crawler实现逻辑:定义采集对外提供的接口定义,其实现主要分为JDBC采集、非JDBC采集两类。
- JDBC采集:主要基于JdbcCrawler实现,其中:JdbcConnectorRegistry负责各类数据源注册实现,JdbcRetriever负责JDBC各类元数据采集实现,JdbcCrawlerOptions维护对应JDBC采集配置参数,分为:SPI模板,JDBC Metadata两类
- SPI模板:基于InformationSchemaViews 定义引擎SQL语句;
- JDBC Metadata:基于 connection.getMetaData() 获取;
- 自定义采集:数据源引擎无JDBC连接,根据引擎自定义实现;
特别的,元数据Crawler的底层实现逻辑除了支持离线采集外,也可提供即时的数据目录功能。如图所示,可分别设计两个服务:
- 元数据直连引擎:即时执行,获取当前的元数据库表信息,主要用于实时查找或者执行引擎使用;
- 元数据采集服务:离线定时调度,采集元数据,主要用于数据治理场景;
总结
本文提供了元模型定义、元数据采集的一些思路和设计方向。在实践中,由于统一元数据管理与具体业务场景密切相关,该架构方案虽然无法直接套用,但也可以作为方案设计时的考量因素。
- 元模型定义并不是越灵活越好,越灵活则元数据管理越复杂和越晦涩难懂。元模型定义尽量与具体业务贴近,满足业务需求即可,无需预留更多的扩展性;
- 为减少数据源组件的侵入性改造,建议优先以PULL方式实现元数据采集;
- 元数据采集量级较大时,建议使用消息中间件解耦,元数据采集和元数据加工处理的流程,避免元数据服务压力过大;
- 元数据采集任务管理,如果存在异构调度系统,在元数据层可抽象出任务的定义,以适配不同的调度系统;
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。