数据分享|R语言分析上海空气质量指数数据:kmean聚类、层次聚类、时间序列分析:arima模型、指数平滑法|附代码数据
原创数据分享|R语言分析上海空气质量指数数据:kmean聚类、层次聚类、时间序列分析:arima模型、指数平滑法|附代码数据
原创
全文链接:http://tecdat.cn/?p=30131
最近我们被客户要求撰写关于上海空气质量指数的研究报告。本文向大家介绍R语言对上海PM2.5等空气质量数据 间的相关分析和预测分析,主要内容包括其使用实例,具有一定的参考价值,需要的朋友可以参考一下
相关分析(correlation analysis)是研究现象之间是否存在某种依存关系,并对具体有依存关系的现象探讨其相关方向以及相关程度,是研究随机变量之间的相关关系的一种统计方法。分类:
·?????? 线性相关分析:研究两个变量间线性关系的程度,用相关系数r来描述。常用的三种计算方式有Pearson相关系数、Spearman和Kendall相关系数。
·?????? 偏相关分析:当两个变量同时与第三个变量相关时,将第三个变量的影响剔除,只分析另外两个变量之间相关程度的过程。如控制年龄和工作经验的影响,估计工资收入与受教育水平之间的相关关系。
在变量较多的复杂情况下,变量之间的偏相关系数比简单相关系数更加适合于刻画变量之间的相关性。
PM2.5细颗粒物指环境空气中空气动力学当量直径小于等于2.5微米的颗粒物。它能较长时间悬浮于空气中,其在空气中含量浓度越高,就代表空气污染越严重。与较粗的大气颗粒物相比,PM2.5粒径小,面积大,活性强,易附带有毒、有害物质(例如,重金属、微生物等),且在大气中的停留时间长、输送距离远,因而对人体健康和大气环境质量的影响更大。
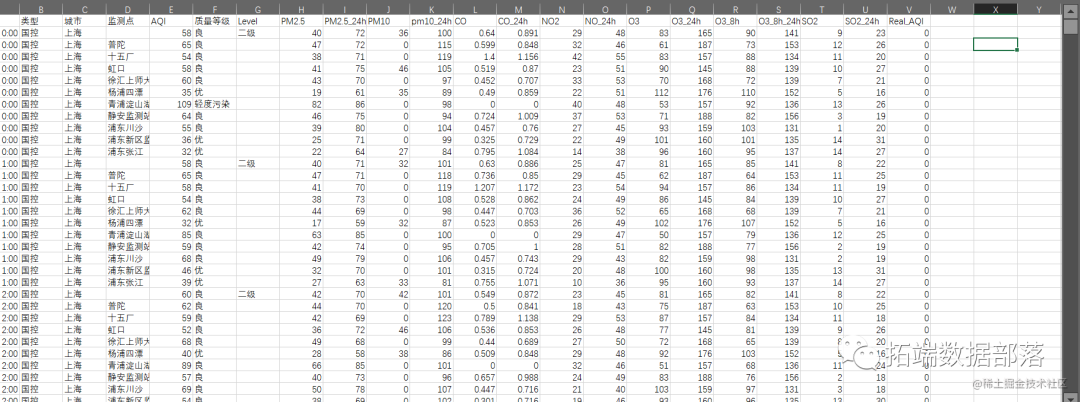
pydat2=read.csv("上海市_05.csv",header=T)
pydat3=read.csv("上海市_06.csv",header=T)
?
head(pydat)
head(pydat2)
?
attach(pydat)
?
plot(pydat[,c(8:10)],
???? col=质量等级)#画出变量相关图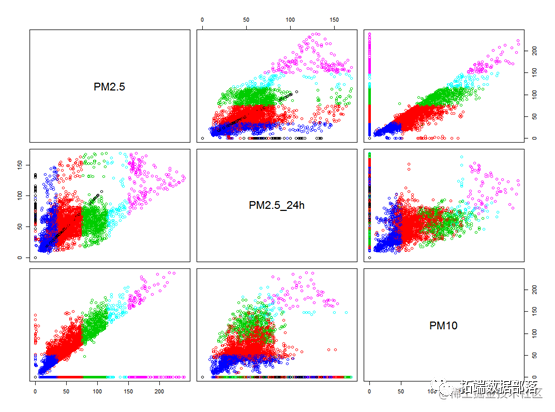
???? col=质量等级)#画出变量相关图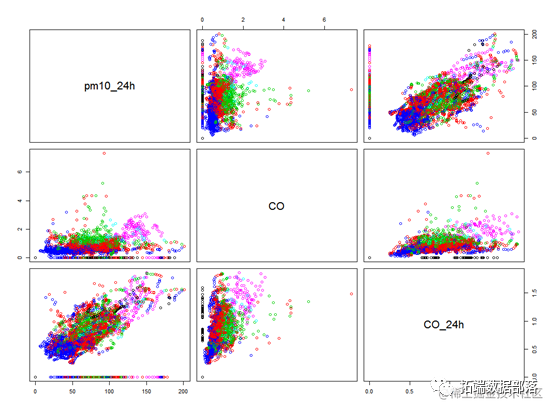
???? col=质量等级)#画出变量相关图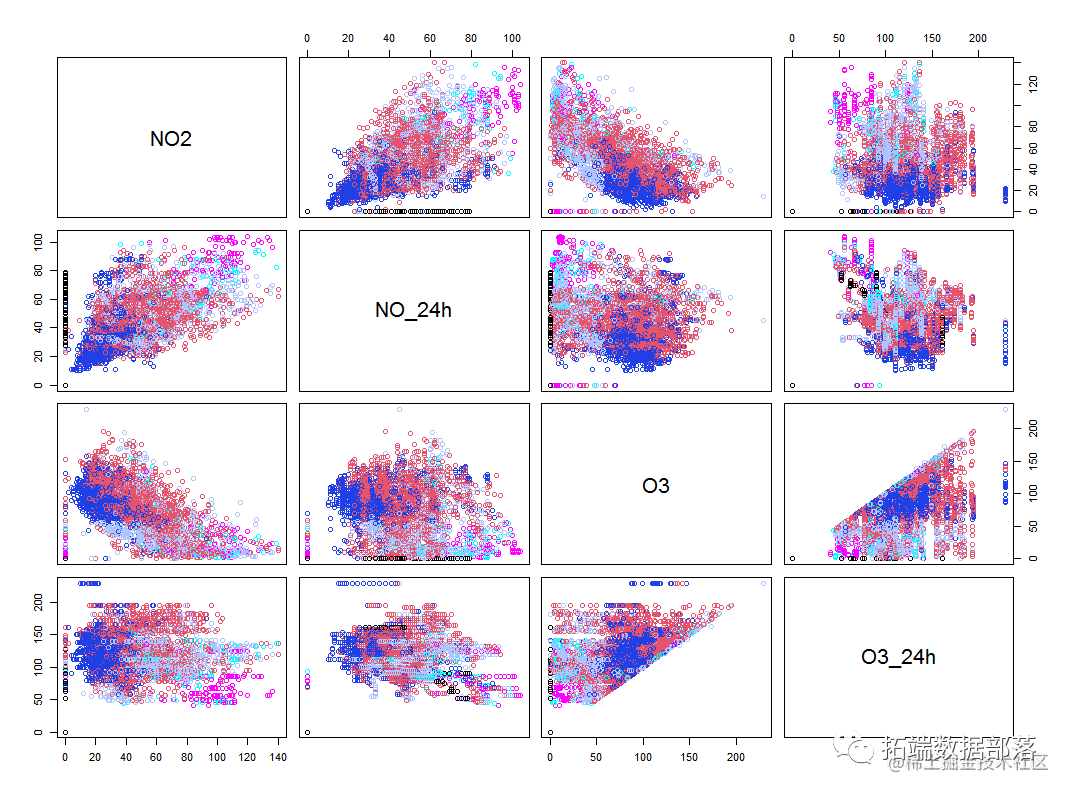
上面的图中不同颜色代表不同的空气质量地区,从所有变量的两两关系散点图来看,可以看到pm2.5和pm10的关系图可以比较好的区分出不同空气质量的地区。并且他们之间存在正相关关系。
对数据进行聚类
plot(hc1,
???? main="层次聚类")
?
??????????? border = "red")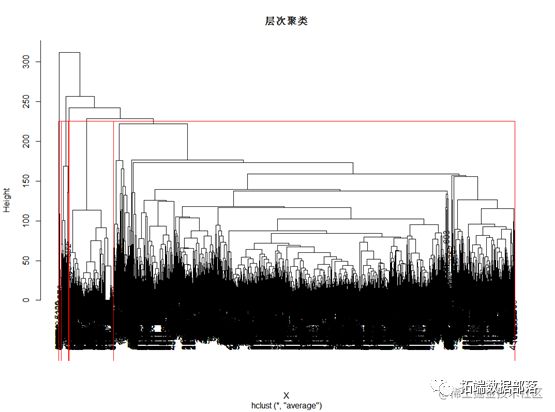
对数据进行层次聚类后,根据谱系图可以发现,所有样本大概可以分成5个类别。因此,后续对数据进行kmean聚类。
点击标题查阅往期内容
R语言空气污染数据的地理空间可视化和分析:颗粒物2.5(PM2.5)和空气质量指数(AQI)
左右滑动查看更多
01
02
03
04
剔除缺失值
plot(pydat[,8:12],
???? col =km$cluster,
???? main="聚类结果1")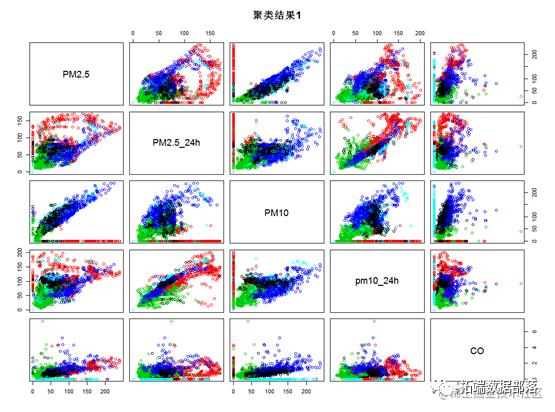
???? main="聚类结果2")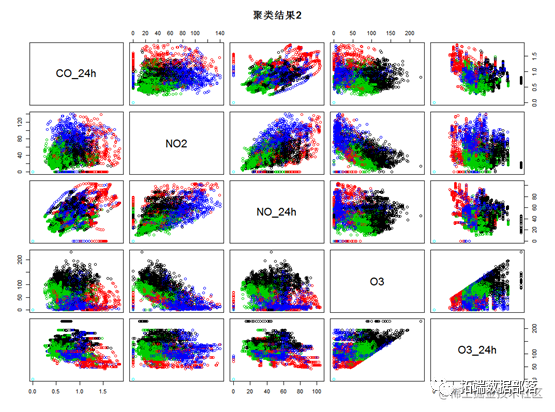
???? main="聚类结果3")
通过kmeans的可视化结果来看,kmeans方法比较好的将所有样本点区分开来,其中绿色的样本点各项指标值较低,红色样本点各项指标值较高,蓝色和黑色样本点主要在O3,NO2 等指标上有较明显的区别。为了具体比较每个类的指标,下面对每个类的数据特征进行描述。
#每个类中的空气质量情况
par(mfrow=c(3,4))
?
boxplot(pydat[,8]~pydat[,23])#聚类结果和pm2.5的关系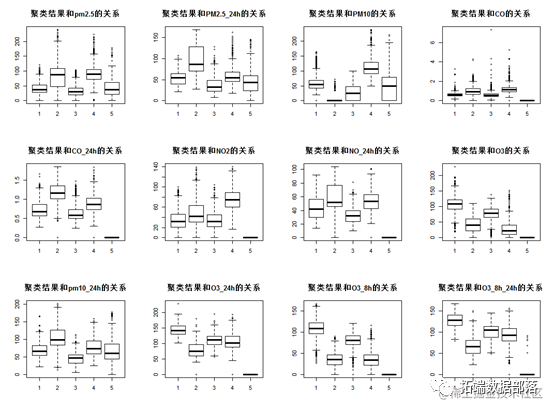
从上面的箱线图,可以看到每个类别的特征,第一类O3值较高,第二个类PM2.5的值较高,第三个类pm2.5,NO值较低,第4类O3水平较低,PM10值较高,第五类的各个指标值都相对较低。因此第5个类别空气质量比较好。其他各个类别的地区在不同指标上有不同特征。
par(mfrow=c(2,3))
hist(as.numeric(pydat[km$cluster==1,6]))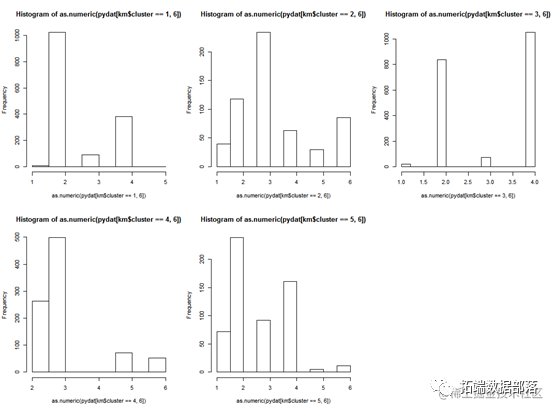
再看每个类中空气质量水平的频率,可以看到第一个类的地区空气质量水平大多在良好水平,第二个类地区水平层次不齐,第3个类空气质量水平在4居多,因此空气质量较差,第4个类别2,3居多,因此良好,第5个类大多地区集中在1-3,因此空气质量最好。
unique(pydat[pydat[,23]==5,4])
? unique(pydat[pydat[,23]==1,4])
?[1]??????????????? 十五厂???????? 虹口?????????? 徐汇上师大???? 杨浦四漂?????? 青浦淀山湖???
?[7] 静安监测站???? 浦东川沙?????? 浦东新区监测站 浦东张江?????
12 Levels:? 虹口 静安监测站 美国领事馆 普陀 浦东川沙 浦东新区监测站 浦东张江 ... 杨浦四漂
> unique(pydat[pydat[,23]==2,4])
?[1] 杨浦四漂?????? 浦东新区监测站 徐汇上师大???? 静安监测站???? 青浦淀山湖???? 虹口?????????
?[7] 十五厂???????? 浦东川沙?????? 浦东张江?????? 普陀??????????????? ?????????
12 Levels:? 虹口 静安监测站 美国领事馆 普陀 浦东川沙 浦东新区监测站 浦东张江 ... 杨浦四漂
> unique(pydat[pydat[,23]==3,4])
?[1]??????????????? 十五厂???????? 虹口?????????? 徐汇上师大???? 杨浦四漂?????? 青浦淀山湖???
?[7] 静安监测站???? 浦东川沙?????? 浦东新区监测站 浦东张江?????
12 Levels:? 虹口 静安监测站 美国领事馆 普陀 浦东川沙 浦东新区监测站 浦东张江 ... 杨浦四漂
> unique(pydat[pydat[,23]==4,4])
?[1] 虹口?????????? 静安监测站???? 十五厂??????????????????????? 浦东新区监测站 浦东张江?????
?[7] 徐汇上师大???? 青浦淀山湖???? 杨浦四漂?????? 浦东川沙?????? 普陀?????????
12 Levels:? 虹口 静安监测站 美国领事馆 普陀 浦东川沙 浦东新区监测站 浦东张江 ... 杨浦四漂
> unique(pydat[pydat[,23]==5,4])
[1] 普陀?????? 静安监测站
12 Levels:? 虹口 静安监测站 美国领事馆 普陀 浦东川沙 浦东新区监测站 浦东张江 ... 杨浦四漂时间序列分析
###对AQi值进行时间序列分析
?
plot.ts(mynx1)指数平滑法
plot.ts(train)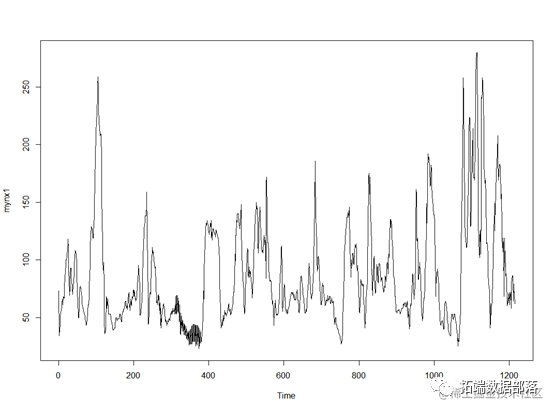
plot.ts(mynxSMA3)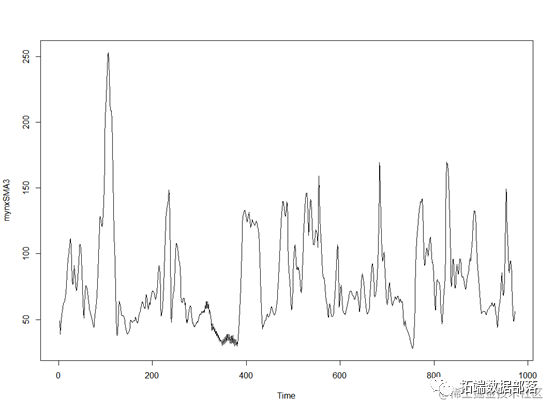
plot.ts(mynxSMA10)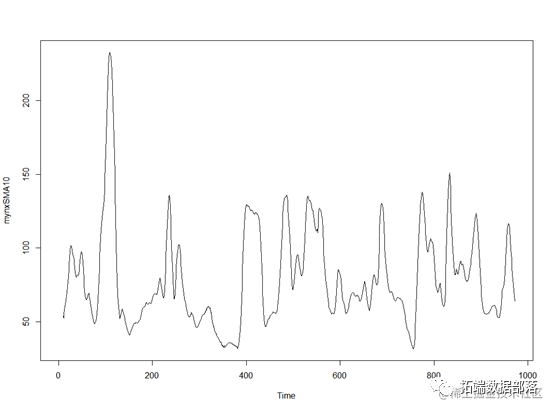
对时间序列进行平滑后,可以看到数据有较稳定的波动趋势。
#画出原始时间序列和预测的
plot(mynxforecasts)
mynxforecasts$SSE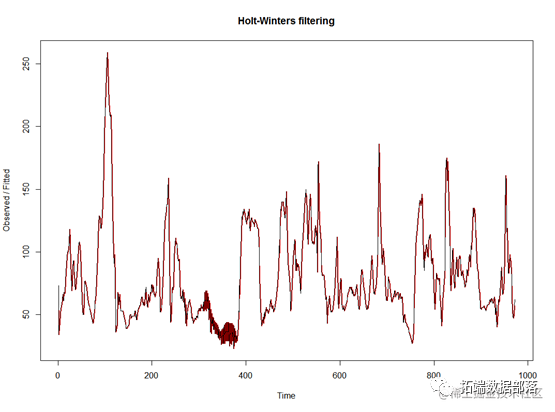
得到红色的拟合数据和黑色的原始数据,可以看到模型拟合较好。
预测
mynxforecasts2
plot.forecast(mynxforecasts2)
lines(mynx1)#原始数据预测对比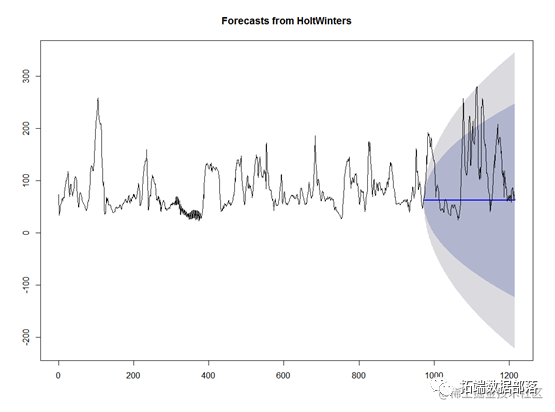
使用该模型对数据进行拟合,可以看到测试集的数据基本上再预测的置信区间之内。
向后预测90天
mynxforecasts2
plot.forecast(mynxforecasts2)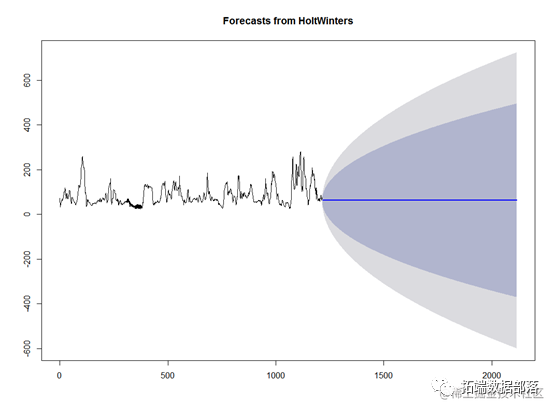
然后对未来的数据进行预测额,可以得到预测的区间。
由于后续预测的数值区间较大,因此我们使用arima模型进行拟合,测试效果。
arima模型
plot(pre)#绘制预测数据
prev=train-residuals(fit3)#原始数据
pre$mean#每天的预测均值
lines(prev,col="red")#拟合原始数据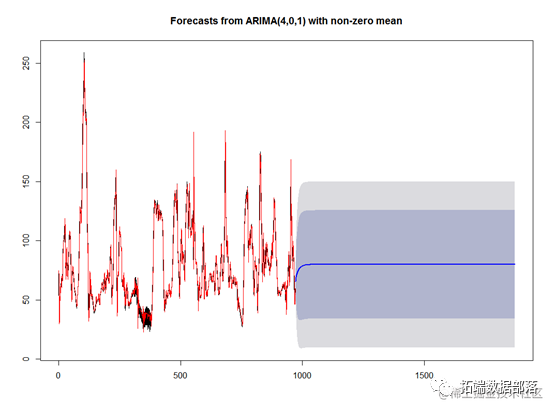
同样得到拟合和预测的值,红色代表拟合的样本点,黑色代表原始的样本点,后面的代表预测的数据和置信区间,可以看到样本拟合的状况较好,预测的区间比指数平滑法要精确。
本文选自《R语言分析上海空气质量指数数据:kmean聚类、层次聚类、时间序列分析:arima模型、指数平滑法》。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。