一篇文章回答你关于NVIDIA DLA的所有疑问
一篇文章回答你关于NVIDIA DLA的所有疑问

哪些 NVIDIA Jetson 或 DRIVE 模块具有 DLA?
所有 Jetson AGX Orin 和 Orin NX 板以及所有上一代 Jetson AGX Xavier 和 Xavier NX 模块都具有 DLA 内核。对于至少具有一个 DLA 实例及其相应时钟设置的所有平台。DRIVE Xavier 和 DRIVE Orin 也有 DLA 核心。
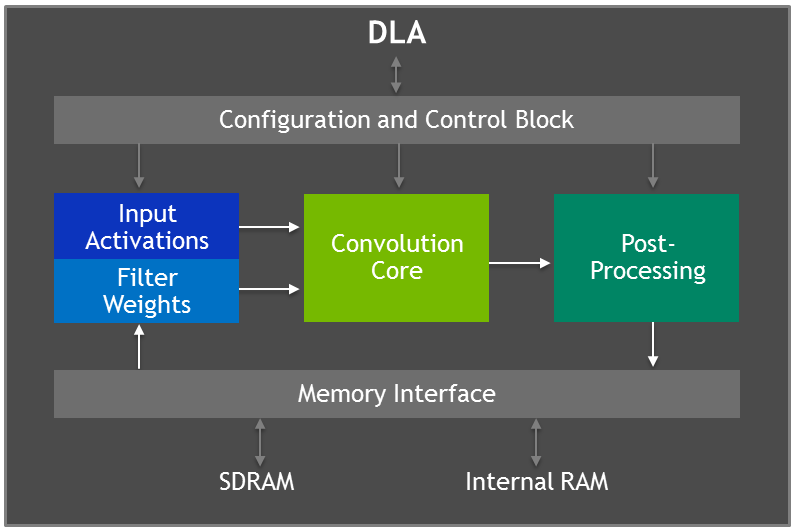
什么是 DLA Core,什么是 DLA Falcon?
DLA Core 负责执行所有数学运算,而 Falcon 是在 DLA Core 上编排/调度工作负载的微控制器。
是否有特定网络或推荐用于 DLA 的网络列表?
您可以在 DLA 上运行任何网络,其中支持的层在 DLA 上运行,不支持的层回退到 GPU. 如果您想要在 DLA 上运行整个模型,DLA 支持骨干网,例如 EfficientNet-Lite、EfficientNet-EdgeTPU、多个 MobileNet 版本(例如 MobileNet-EdgeTPU)、Inception 系列的模型(例如 GoogLeNet 或 InceptionV3)、ResNets、YOLO 模型。例如,您可以将分段头(例如 FCN)、对象检测头(例如 SSD)或分类头(例如 AveragePool + FC/1x1 卷积)附加到上述主干之一以用于您的特定用例。如果您对高利用率感兴趣,那么具有高算术强度(这意味着:每个内存操作有很多数学运算)的模型最适合 DLA。这方面的示例是 ResNet-18、ResNet-34 或 ResNet-50。但也有较低算术强度的模型,如 MobileNet,在 DLA 上具有低延迟。
DLA 是否支持 Point-Pillar Networks?
DLA 支持卷积和转置卷积。通过对参数进行一些调整(例如,通过 stride==kernel size 使用Transposed Convolution 或切换到 Nearest-Neighbor Resize),应该可以支持 Point Pillar Networks。您可以通过修改 ONNX 图或原始模型定义来完成此操作。
DLA 目前不支持Re-expressing operations。
当您部署一个在 GPU 和 DLA 之间交替层的网络时,存在什么样的开销?
由于几个常见原因,可能会产生开销:从今天开始,在 GPU 和 DLA 内存格式之间重新格式化张量。kCHW16 (FP16) 和 kCHW32 (INT8) 格式在 DLA 和 GPU 上很常见;但是,默认格式并不相同。因此,请确保您使用普遍支持的张量格式以避免重新格式化开销。由于工作量小而产生的开销。确保您有一个子图(网络图的连续部分)映射到 DLA 的网络,而不是在 GPU 和 DLA 之间来回移动的各个层。
为什么在两个 DLA 内核和 GPU 上运行工作负载时延迟更高?
这可能有多种原因,让我们关注三个最常见的原因:
- DLA 和 GPU 都消耗相同的资源:系统 DRAM。工作负载的带宽限制越大,DLA 和 GPU 在并行运行时成为内存访问瓶颈的可能性就越大。
- 如果您不通过 TensorRT 运行具有原生 DLA 格式的 DLA,则会在每个 DLA 推理周围插入 GPU 重新格式化内核。这意味着您增加了额外的 GPU 工作负载(因为 GPU 正忙于重新格式化)。要减少这种情况,您可以使用DLA的无重新格式化 I/O 选项。
- 低效调度造成的干扰也是一个原因:特别是在小批次大小和输入帧以固定速率一个接一个到达的情况下,DLA 任务没有得到快速调度或没有将完成信号注册回GPU不够快。对于单上下文情况和多上下文情况都会发生这种情况。减少此类干扰的已知选项:使用cuDLA 进行 DLA 推理。从 TensorRT 8.5 开始,通过 TensorRT 接口的 DLA 推理默认使用 cuDLA。增加计算和复制引擎并发连接的首选数量(工作队列):可以通过设置Linux环境变量来实现
CUDA_DEVICE_MAX_CONNECTIONS=32。
DLA 支持哪些精度格式?
Orin 和 Xavier 上的 DLA 支持最佳推理精度格式 - FP16 和 INT8。Orin 上的 DLA 特别针对 INT8 进行了优化,因为与 Xavier 上的 DLA 相比,通过权衡 FP16 性能来优化 AI 推理的这种精度。同一模型中的 FP16 和 INT8 混合精度选项使您可以在精度和低资源消耗之间找到最佳平衡点。
FP16 性能与 int8 相比如何?
NVIDIA 设计了其深度学习加速器,重点是用于 AI 推理的 INT8,因为推理是 Jetson 或 DRIVE 模块的关键价值主张。训练在更大的 NVIDIA GPU 和系统上进行。与上一代 Xavier 架构相比,Orin DLA 旨在将 INT8 计算提高 9 倍,并以更高的功率效率换取更低的 FP16 卷积计算。DLA 专为易于理解的 AI 推理模型而设计,并以较低的功耗和较小的面积开销运行。因此,它提供了高度优化的 INT8 DL 推理引擎。
如何将网络量化为 INT8 以进行 DLA?
要为 DLA 量化网络,您需要知道中间张量的动态范围,以帮助将 FP32/FP16(宽表示)映射到 INT8(wide representation)。对于 DLA,这可以通过 TensorRT 的训练后量化 (PTQ) 工具链来实现。TensorRT PTQ 工作流程在模型训练后使用具有代表性的校准数据集。这为要在 int8 中运行的层的输出和输入张量提供了比例因子。如果您没有比例因子,这些层将以 fp16 运行。这是您可以参考以开始使用的示例:https ://github.com/NVIDIA/TensorRT/tree/main/samples/sampleINT8 ,请注意--useDLACore=N选项的存在。
将模型转换为 int8 是否总是需要校准文件?
您可以使用 TensorRT 校准文件或使用ITensor TensorRT API来设置网络张量的缩放因子。如果您没有单个张量的比例因子,您还可以以 fp16 精度运行受影响的层。
如果没有 TensorRT,我将如何使用 DLA?TensorRT Builder 是调用 DLA 编译器的唯一用户界面,它提供一致的界面来解析您的网络并为 GPU 和 DLA(DLA 可加载)构建推理引擎。TensorRT 运行时提供运行时 API 来调用 DLA 运行时堆栈,几乎不需要用户干预,但对于高级用户,您还可以使用 cuDLA 运行时 API 来运行可加载到 DLA 硬件上的 DLA。
ONNX 是从 PyTorch 到 TensorRT 的推荐方式吗?
在 DLA 编译器将其编译为可加载文件之前,DLA 依赖于 TensorRT 解析网络。截至目前,ONNX 是从各种框架(包括 Pytorch)到 TRT 的首选 TensorRT 路径。但是,您也可以将Torch-TensorRT与 DLA 结合使用,例如使用 TensorRT 的 API 构建您自己的翻译器。
密集 TOP 和稀疏 TOPS 之间有什么区别?
由于零权重,结构化稀疏度是一种优化,可以在网络内的稀疏计算中利用特定模式。结构化稀疏性是 Ampere GPU 和 Orin 中的 DLA 的新特性。它允许您通过提供具有 2:4 “稀疏”权重模式的卷积权重来提高计算吞吐量。这意味着对于 KCRS 卷积权重 blob,对于沿 C 维度的每 4 个权重,至少有 2 个为零。对于 DLA,您需要 C > 64 才能启用结构化稀疏性。
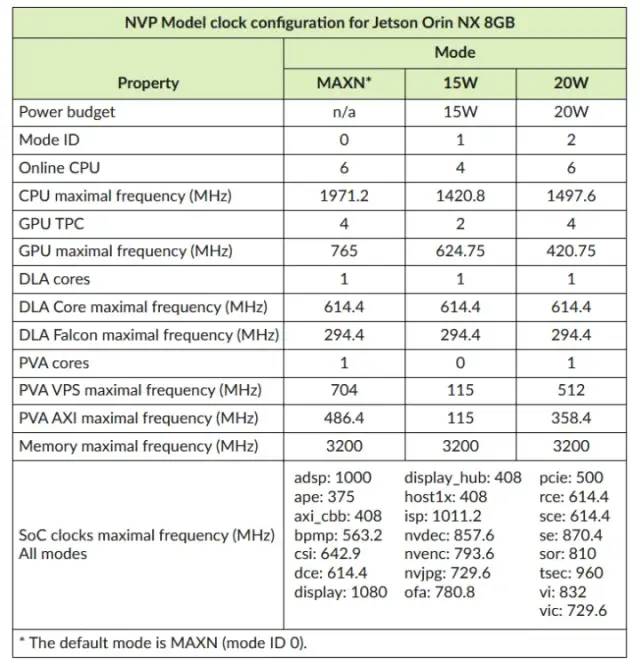
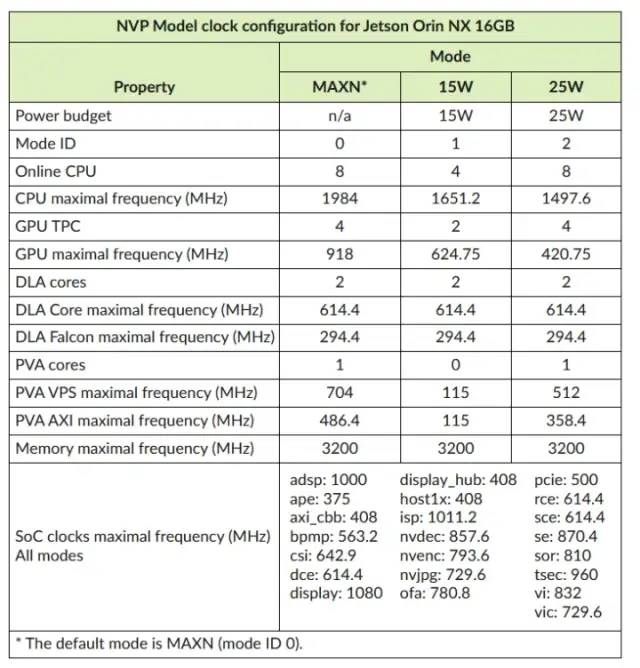
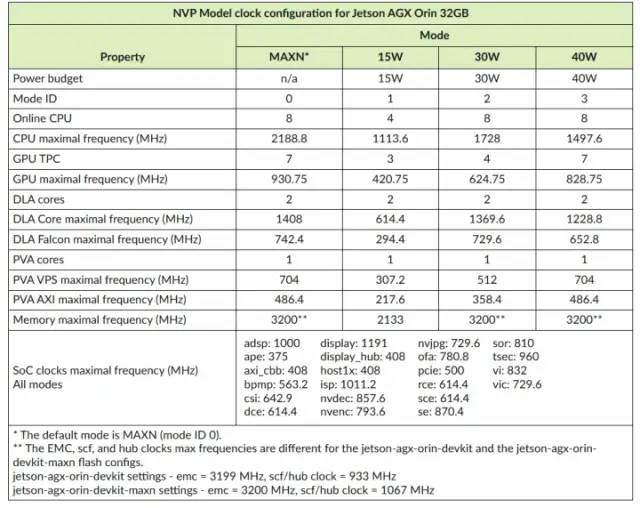
我们可以调整 DLA 上的时钟频率吗?
是的,您可以在 DLA 上设置时钟频率。参考官方文档将引导您完成在 Jetson 开发板上设置电源和时钟配置文件的步骤。
DLA可以直接访问DRAM系统内存中的数据吗?
是的,它连接到系统 DRAM,就像 GPU 或 CPU 一样。
DLA 有多少内部 SRAM?
在 Xavier 上,2 个 DLA 和 2 个可编程视觉加速器 (PVA) 共享总共 4 兆字节的 SRAM。在 Orin 上,每个 DLA 都可以独占访问 1 兆字节的内部 SRAM。
DLA 的推理延迟与 GPU 相比如何?
与 GPU 相比,一个 DLA 上单个工作负载的延迟会更高,因为每个 DLA 实例的理论数学吞吐量 (TOP) 都低于 GPU。Xavier 和 Orin 上有 2 个 DLA,在默认时钟下,每个 DLA 实例的理论数学吞吐量 (TOP) 低于 GPU。
但是,当您从应用程序的角度来看时,您可以通过在 DLA 和 GPU 上分配深度学习和非深度学习工作负载来减少总延迟或整体延迟。对于某些对工作负载延迟一致性有要求的应用程序,DLA 特别适合。
如果您想评估特定工作负载的设备性能,我们建议从计算 GPU 和 DLA 的数学利用率开始。数学利用率的计算方法是将实现的吞吐量(每秒图像数乘以每幅图像的 FLOPs)除以加速器在使用精度下的理论峰值吞吐量(每秒操作数,通常以每秒 Tera 操作数或 TOPs 表示) .
是否可以在两个 DLA 核心上同时运行多个网络?
是的,可以在两个 DLA 上同时运行多个网络(因此模型 A 在第一个实例上运行,模型 B 在第二个实例上运行)。您可以对同一网络的两个实例执行相同的操作。事实上,您可以在 GPU 和 DLA 核心上同时运行多个网络。快速入门的一种方法是运行两个并发的 trtexec 进程,其中第一个进程使用 运行--useDLACore=0,第二个进程使用 运行--useDLACore=1。如果您想在同一进程中使用 2 个 DLA 核心,请使用 TensorRT API。
多个模型可以在单个 DLA 上运行吗?
是的,您可以按顺序在单个 DLA 核心上运行多个模型。
哪些工具和实用程序可用于分析和调试 DLA 工作负载?
衡量 DLA 性能的最简单方法是使用trtexec。例如,您可以使用以下命令在 INT8 模式下使用 trtexec 在 DLA 上运行 ResNet-50 网络:
./trtexec --onnx=rn50.onnx --int8 --useDLACore=0 --dumpProfile --memPoolSize=dlaSRAM:1 --inputIOFormats=int8:dla_hwc4 --outputIOFormats=int8:chw32如果模型不能在 DLA 上完全运行则添加--allowGPUFallback 如果模型不能在 DLA 上完全运行则添加
Nsight System 是分析您的应用程序的最佳工具,不仅适用于 DLA,也适用于整个 SoC。您可以获得每个子图的 DLA 运行时的详细配置文件以及在运行时使用的核心,NVIDIA将继续向 Nsight 系统添加更多配置文件功能。
DLA 是否有助于降低功耗?
是的,DLA 针对每瓦特的高性能进行了优化。如果您想降低 Jetson 或 DRIVE 模块的功耗,最好的方法是将尽可能多的深度学习工作负载映射到 DLA。
我们在哪里可以了解有关如何在 ISAAC 参考应用程序中利用 DLA 的更多信息?
ISAAC SDK 有一个使用立体数据进行邻近分割的参考应用程序。该应用程序要求有两条独立的路径,团队设计了独立的管道以最佳地利用 GPU 和 DLA。您可以在此处的链接中找到代码及其网络架构:https ://github.com/NVIDIA-ISAAC-ROS/isaac_ros_proximity_segmentation