Innodb Buffer Pool详解

导读
数据库为了高效读取和存储物理数据,通常都会采用缓存的方式来弥补磁盘IO与CPU运算速度差。InnoDB 作为一个具有高可靠性和高性能的通用存储引擎也不例外,Buffer Pool就是其用来在内存中缓存数据页面的结构。本文将基于MySQL-8.0.22源码,从buffer pool结构、buffer pool初始化、buffer pool管理、页面读取过程、页面淘汰过程、buffer pool加速等方面介绍buffer pool的实现原理。
第一部分、Buffer pool结构
Buffer pool不仅仅缓存了磁盘的数据页,也存储了锁信息、change buffer信息、adaptive hash index、double write buffer等信息。本章节将从物理与逻辑两方面介绍buffer pool的结构。
1.1? Buffer pool的物理结构
Buffer pool的物理结构自上而下分instance、chunk和page三层,如下图所示:

- Buffer pool instance
Buffer pool instance对应的结构体是buf_pool_t。整个buffer pool由多个instance组成,个数等于innodb_buffer_pool_size/innodb_buffer_pool_instances。instances是为并发读取与写入而设计,各instance之间没有锁竞争关系。当 innodb_buffer_pool_size小于1GB时为防止instances太小而出现性能问题,innodb_buffer_pool_instances会被重置为1。instance之内包含完整锁、信号量、chunks、为方便数据页管理而设计的逻辑链表(lru list、free list、flush list)以及一个用于快速找到指定space_id和page_no的数据页的的page hash链表。
- Buffer pool chunk
Buffer pool chunk对应的结构体是buf_chunk_t。每个buffer pool instance被均匀划分为多个chunk,buffer pool resize以chunk为粒度。chunk分为数据页和数据页对应的控制体,控制体中有指针指向数据页。遍历所有instance的chunk可以几乎访问innodb所有缓存的数据,只有部分诸如尚未解压的压缩页等除外。
- Buffer pool page
Buffer pool page对应的结构体包括块描述符buf_block_t和页面描述符buf_page_t。Buffer pool page大小为16KB,默认与磁盘上数据页的大小相同(innodb的文件结构的介绍,请参考浅析InnoDB文件结构),其缓存的不仅仅是数据页,缓存的对象还包括:undo log页面、change buffer(插入缓存信息)、AHI(自适应哈希)、SDI(结构化字典信息)、行锁等。所有缓存对象在buffer pool中都是以页面为单位存储。
Innodb支持数据页压缩,压缩页的大小在建表的时候指定,目前支持的范围包括16K,8K,4K,2K,1K等(由于压缩页的管理方式与普通页面不同,即使指定16K的压缩页,也能对数据量大的类型有一定益处)。压缩页面在buffer pool中使用伙伴系统管理,不论压缩页面在磁盘上的大小是多少,解压后都为16K。当buffer pool空闲页面不足时,innodb会优先淘汰压缩页面的解压页(buf_LRU_free_from_unzip_LRU_list),当前者操作后仍不能为innodb提供足够的空闲页面时,会接着淘汰LRU list上的正常页面和压缩页面(buf_LRU_free_from_common_LRU_list)。
1.1.1 Buffer pool page结构
buf_block_t主要包含以下信息:
- 描述页所属space ID、文件内偏移的page no、页面大小、IO状态、最新修改的LSN、最老修改的LSN、zip压缩页面原始数据、用于链接到page hash节点等信息的结构buf_page_t。buf_page_t处于buf_block_t的第一项,方便二者之间灵活转化。
- 指向存储页面数据的内存地址frame。
- 页面mutex,用于保护buf_fix_count、io_fix等页面状态等。
- 是否处于unzip LRU list、withdraw list、unzip CLOCK_list等信息,这些链表的含义将在1.2节中介绍。
- 其他信息。
每个buffer pool page的buf_block_t和frame等信息于buf_chunk_init函数中被初始化。在使用allocate_chunk分配到chunk的空间后,chunk内所有页面的buf_block_t连在一起从内存前向后初始化,chunk内所有frame连在一起,从内存后向前初始化,最左侧的buf_block_t控制最左侧的frame,如下图所示:
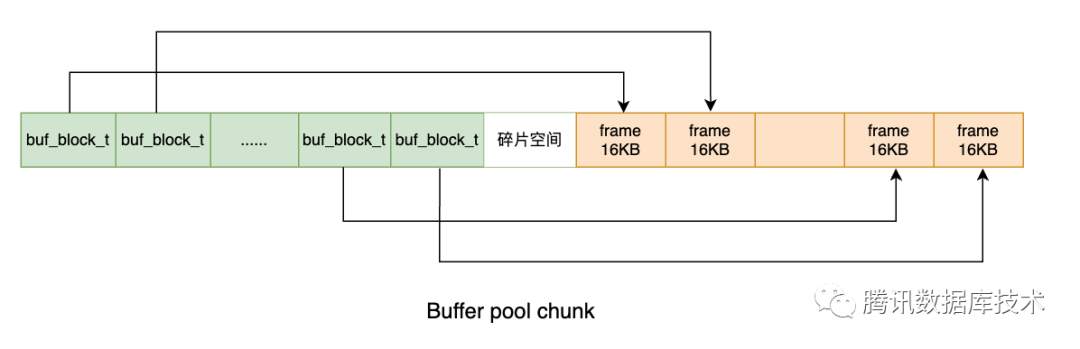
1.1.2 Buffer pool page分类
所有buffer pool page分为以下类别:
- BUF_BLOCK_POOL_WATCH:用于purge操作异步读取磁盘页面的一种类型。每个buf_pool_t结构体中都有一个名为watch的数组,元素类型为buf_page_t,大小为purge线程数+1。当purge操作需要读取一个不在buffer pool中的页面时,会将watch数组中一个BUF_BLOCK_POOL_WATCH状态的页面设置为BUF_BLOCK_ZIP_PAGE,设置对应space id,page id,设置buf_fix_count设置为1防止其被淘汰出buffer pool,并将其加入page hash中(buf_pool_watch_set)。当磁盘数据被读取进入buffer pool时,会将watch数组对应的页面状态恢复为BUF_BLOCK_POOL_WATCH,将watch页面从page hash中删除(buf_pool_watch_remove),后续会将新页面加入page hash中。通过较为tricky地判断存在于page hash的page地址是否在watch数组范围内,可以巧妙地判断目标页面是否成功读入buffer pool。
- BUF_BLOCK_ZIP_PAGE:压缩页未解压的对应状态。从磁盘读取压缩页时,用buf_page_alloc_descriptor分配一个临时页面描述符buf_page_t,再调用buf_buddy_alloc从伙伴系统中分配一个空间存放压缩页原始数据,临时的bpage会被加入LRU list和page hash(buf_page_init_for_read)。这个临时buf_page_t等到页面被解压时,innodb会使用从free_list中申请到的状态为BUF_BLOCK_FILE_PAGE的buf_page_t替换掉临时buf_page_t,放在LRU list相同的位置,并把解压页面的块描述符buf_block_t放入unzip LRU list中;删除page hash中的临时buf_page_t,在其中加入新的buf_page_t;最后通过buf_zip_decompress解压页面(zip_page_handler)。如果解压页被淘汰,而压缩页本身未被淘汰,并且页面未被修改,则此页面会再次被标记为BUF_BLOCK_ZIP_PAGE。关于BUF_BLOCK_ZIP_PAGE的另一个用法如前所述,为在watch操作中被用来标记尚未读入的页面,不再复述。
- BUF_BLOCK_ZIP_DIRTY:压缩页的解压页被释放时,如果页面被修改过(oldest_modification非0),则页面从BUF_BLOCK_FILE_PAGE状态变为BUF_BLOCK_ZIP_DIRTY状态,未被修改过则为BUF_BLOCK_ZIP_PAGE(buf_LRU_free_page/buf_CLOCK_free_page)。解压页被释放后,BUF_BLOCK_ZIP_PAGE/BUF_BLOCK_ZIP_DIRTY压缩页的页面描述符也会在buf_LRU_free_page/buf_CLOCK_free_page临时分配。BUF_BLOCK_ZIP_DIRTY状态的页面无法从LRU/CLOCK list中淘汰,只能在flush_list中等待刷盘。在flush_list中,也只存在BUF_BLOCK_FILE_PAGE和BUF_BLOCK_ZIP_DIRTY这两种页面。
- BUF_BLOCK_NOT_USED:页面在free_list中时的状态,此类页面较为常见。
- BUF_BLOCK_READY_FOR_USE:当页面从free list取下,准备放入LRU/CLOCK list(buf_LRU_get_free_block/buf_CLOCK_get_free_block)时处于的临时状态。
- BUF_BLOCK_FILE_PAGE:非压缩页面的页面状态,压缩页解压页的页面状态。最常见的页面状态。
- BUF_BLOCK_MEMORY:用于存储内存对象,包括innodb行锁、AHI(自适应哈希)、压缩页伙伴系统等。此类页面不存在任何逻辑链表中。
- BUF_BLOCK_REMOVE_HASH:页面从page hash删除后,被放入free_list前处于的临时状态。
1.1.3 页面读取方法
页面读取方法包括:NORMAL、SCAN、IF_IN_POOL、PEEK_IF_IN_POOL、NO_LATCH、IF_IN_POOL_OR_WATCH、POSSIBLY_FREED。在详细介绍页面读取方法之前,先介绍随机预读、make young、线性预读等概念:
- 随机预读(buf_read_ahead_random):发生在磁盘页面读取函数buf_read_page_low之后,所有非SCAN的页面读取模式都会尝试随机预读。随机预读的作用是当一个extent(通常为1M,64个连续的物理页面)内处于LRU list前1/4的热点页面(buf_page_peek_if_young返回为true)个数超过13时(BUF_READ_AHEAD_RANDOM_THRESHOLD)时,会采用异步IO和IO合并的方式将该extent内所有页面都读入buffer pool。随机预读是可选的,可以使用innodb_random_read_ahead参数关闭。
- make young(buf_page_make_young_if_needed):用于修改页面的位置,除SCAN和PEEK_IF_IN_POOL之外的所有模式都会尝试make young。对于LRU list中的页面,如果页面处于LRU末尾,并且距离上一次读取超过一定时长(buf_LRU_old_threshold_ms),则将页面放入LRU list的头部。对于CLOCK list页面,如果页面被没有independent标记的正常流量访问,则需按innodb_independent_buffer_pool_list_move_action的配置决定是否移动到LRU list中。
- 线性预读(buf_read_ahead_linear):发生在buf_page_make_young_if_needed之后,除SCAN和PEEK_IF_IN_POOL之外的模式中,第一次读取页面(access_time为0)时才会尝试线性预读。线性预读条件比较苛刻,只有extent的数据边界页面,即extent的第一个页面或者最后一个页面读取结束后才可能触发,并且要求在extent范围内超过innodb_read_ahead_threshold(默认值为56)个页面被顺序访问(判定方法是检查页面的访问时间access_time),满足条件后会采用异步IO和IO合并的方式将下一个extent的数据都读入buffer pool。
下面来了解各种页面读取方法的具体作用:
- NORMAL:默认获取数据页的方式,如果数据页不在 buffer pool中,则从磁盘读取,如果已经在buffer pool中,则直接返回。会尝试进行随机预读、make young和线性预读。正常加读写锁。
- SCAN:用于扫描类的页面读取。扫描类的特点为大批量读取页面,但短时间不再需要此类页面,因此页面读取应尽可能不影响buffer pool的状态。所以SCAN不会进行随机预读、make young和线性预读。正常加读写锁。
- IF_IN_POOL:只在buffer pool查找目标数据页,如果不在则直接返回为空。随机预读发生在磁盘页面读取之后,因此不会尝试随机预读。会尝试make young和线性预读。正常加读写锁。
- PEEK_IF_IN_POOL:与IF_IN_POOL模式相似,但只是窥探页面是否在buffer pool中,不会修改页面的位置和干扰buffer pool状态,因此不会随机预读、make young和线性预读。正常加读写锁。
- NO_LATCH:除了不加读写锁之外,其他与NORMAL模式相似,从磁盘或者buffer pool读取页面。会尝试进行随机预读、make young和线性预读。
- IF_IN_POOL_OR_WATCH:用于purge操作,与IF_IN_POOL模式相似,页面在buffer pool则直接返回,但如果页面不在buffer pool,则会设置page watch,等待目标页面被其他线程异步读入buffer pool。会尝试make young和线性预读。正常加读写锁。
- POSSIBLY_FREED:用于数据统计操作,与NORMAL模式相似,但不在乎页面是否被freed。从磁盘或者buffer pool读取页面。会尝试进行随机预读、make young和线性预读。正常加读写锁。????????????????
1.1.4 Page hash
innodb为加速buffer pool中页面的查找,在每个buffer pool instance(buf_pool_t)中提供了page hash。page hash对应的结构体为hash_table_t。page hash中只存储对应到物理文件的页面(buf_page_in_file() == TRUE),类型包括BUF_BLOCK_ZIP_PAGE、BUF_BLOCK_ZIP_DIRTY、BUF_BLOCK_FILE_PAGE三类。page hash的key为(m_space << 20) + m_space + m_page_no,value为页面描述符buf_page_t*。page hash为了提高性能,提供了锁分区的功能,即采用一系列锁来保护page hash的单元(hash_cell_t),不同锁保护不同分区。分区个数为默认16个,只有在debug模式下才能通过innodb_page_hash_locks参数更改。
1.1.5 Zip hash
innodb的压缩页存储空间由伙伴系统管理。为加速伙伴系统所有页面的查找,其页面都会存入zip hash中。
1.2 Buffer Pool的逻辑结构
为方便管理buffer pool page,innodb用多个逻辑链表将相同属性的buffer pool页面描述符(通常都是buf_page_t)串联在一起。
1.2.1 Free list
free list对应暂时没有被使用的节点,对应结构为buf_pool_t中的UT_LIST_BASE_NODE_T(buf_page_t) free,如前所述,其页面的类型为BUF_BLOCK_NOT_USED。LRU list、CLOCK list等链表需要新页面时就会向free list申请,当后者空闲页面不足时(buf_get_free_only返回为空),则需要通过扫描CLOCK list(buf_CLOCK_scan_and_free_block)或者LRU list(buf_LRU_scan_and_free_block),淘汰合适的节点以腾出空间页面。
1.2.2 LRU list
LRU list是buffer pool最重要的链表,对应的结构为buf_pool_t中的UT_LIST_BASE_NODE_T(buf_page_t) LRU,除被independent标记的页面外,所有读进来的页面都放在LRU list上。LRU list页面被用改良后的LRU算法管理,除LRU算法的基本特点之外,还包括以下特点:
- 所有新页面被插入距离队尾3/8 LRU list长度的位置,此位置称为midpoint,前5/8称为young list,濒临淘汰的3/8称为old list。
- 处于midpoint的页面在超过一定时间间隔(buf_LRU_old_threshold_ms)后再次被读取时才会被移入LRU list的头部。
- 处于LRU list前1/4的的页面属于热点页面,不会被移动到LRU list的头部(buf_page_peek_if_young)。
如上方式管理LRU list的主要原因是担心buffer pool中经常被使用的页面被预读的页面以及全表扫描类操作淘汰,影响数据库的性能。
1.2.3 Unzip LRU list
unzip LRU list是用于存储LRU list中压缩页的解压页的链表,对应结构为buf_pool_t中的UT_LIST_BASE_NODE_T(buf_block_t) unzip_LRU,存储单元是块描述符buf_block_t。读取磁盘中的压缩页时,会调用buf_page_alloc_descriptor临时分配一个页面描述符buf_page_t,再调用buf_buddy_alloc从伙伴系统中分配一个空间存放压缩页原始数据,临时的buf_page_t会被加入LRU list和page hash(buf_page_init_for_read),如果是debug模式,还会将未解压的压缩页放入zip clean list。
压缩页在被用户请求的过程中,在压缩页面获取之后,innodb会在zip_page_handler函数内,先通过buf_relocate从free list申请新的空闲页面替换掉临时的buf_page_t,放在LRU list相同的位置,并把解压页面的块描述符buf_block_t放入unzip LRU list中(unzip LRU list中页面的前后顺序与LRU list相同),并且删除page hash中的临时buf_page_t,在其中加入新的buf_page_t;后通过buf_zip_decompress对压缩数据进行解压。由于解压页既以buf_page_t存在于LRU list,又以buf_block_t存在于unzip LRU list,buf_page_t和buf_block_t又能互相转化,因此unzip LRU list实际上是LRU list的子集。
当free list空间不足时,innodb会优先淘汰unzip LRU list,并且只淘汰解压页而不淘汰压缩页。如果从unzip LRU list中没能淘汰出页面,则会尝试从LRU list中淘汰,此时如果遇到解压页,则会连同压缩页本身一起淘汰(buf_LRU_scan_and_free_block)。当解压页被淘汰,而压缩页未被淘汰时,innodb会重新为压缩页分配临时页面描述符buf_page_t,将其插入LRU list中与解压页相同的位置,并且从page hash中删除解压页,将临时buf_page_t加入page hash(buf_LRU_free_page)。
1.2.4 CLOCK list
虽然innodb小心翼翼地设计了midpoint的buffer pool page读取方案,8.0还引入了SCAN读取模式尽可能减少全表扫描与正常query的数据页面间的冲突,但并未根除。假设buffer pool有限,正常query需要的页面可以恰好完整缓存到buffer pool或者还无法缓存到buffer pool,若此时发起类似全表扫描的操作,全表扫描需要的页面不论需要多少,都会导致以下问题:
- LRU list队尾中正常query的旧页面会快速被全表扫描淘汰。
- 全表扫描页面和正确query竞争free buffer pool page,正常query读取新页面速度受影响。
- 正常query读入的新页面放在midpoint处,全表扫描读入的页面也是如此,如果正常query没及时读取新页面,新页面会被全表扫描流量快速推向队尾并淘汰。
上述问题的根本原因在于全表扫描页面与正常query页面存在耦合,能够互相影响。CLOCK list是CDB为接触全表扫描页面与正常query页面耦合而引入的新链表结构,对应结构为buf_pool_t中的UT_LIST_BASE_NODE_T(buf_page_t) CLOCK。所有用independent hint标记过的页面都会存入CLOCK list,而非LRU list。CLOCK list采用类似优化过的CLOCK算法进行管理:
- buf_page_t新增use_times参数,记录页面被访问的次数,每次被读取时use_times加1。
- CLOCK list上限用innodb_txsql_independent_buffer_pool_size_pct配置,其表示CLOCK list能使用的BP最大比例。
- CLOCK list未达到上限时,需要新数据页时直接从free list申请。CLOCK list达到上限时,扫描CLOCK list,被扫描的页面use_times减1,直至找到use_times为0的能顺利淘汰的页面为止(buf_CLOCK_scan_and_free_block)。
- 新增后台线程buf_independent_buffer_pool_evict_thread,每隔innodb_txsql_independent_buffer_pool_evict_interval时长,对CLOCK list进行扫描,将每个页面的use_times减1,主动淘汰CLOCK list页面
- 淘汰的CLOCK list页面归还给free list,没有全表扫描时,可以给正常query使用。
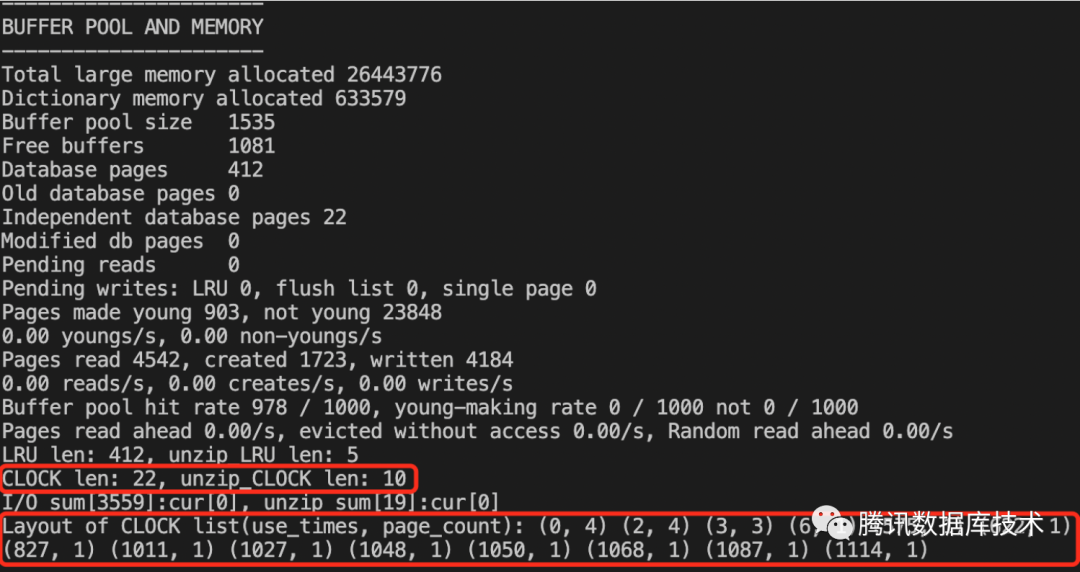
使用CLOCK list的方法很简单,只需要在INSERT、DELETE、UPDATE等DML关键词后添加名为independent的hint即可,例如select /*+ independent */ id from t。CLOCK list的长度、页面被使用次数分布等信息可以使用show engine innodb status命令观察。如下图所示:
1.2.5 Unzip CLOCK list
unzip CLOCK list与unzip LRU list类似,都是用于存储解压的压缩页,对应的结构为buf_pool_t中的UT_LIST_BASE_NODE_T(buf_block_t) unzip_CLOCK。CLOCK list对压缩页的读取,解压过程都与LRU list相似,都是先用临时buf_page_t读取原始压缩数据,将临时buf_page_t加入CLOCK list和page hash,如果是debug模式,还会将未解压的压缩页放入zip clean list。之后在zip_page_handler函数内,再用从free list申请的新页面替换临时buf_page_t,存放到CLOCK list和unzip CLOCK list对应的位置中,最后用buf_zip_decompress进行数据解压。与unzip LRU list相似,unzip CLOCK list也是CLOCK list的子集。
unzip CLOCK list的淘汰分两种,一种与unzip LRU list相似:当independent hint访问需要的页面不足时,先扫描unzip CLOCK list,后扫CLOCK list,直至找到use_times为0的页面并淘汰复用(buf_CLOCK_scan_and_free_block)。淘汰页面时如果只有解压页被淘汰而压缩页未被淘汰,处理细节与unzip LRU list相同。另一种是后台线程buf_independent_buffer_pool_evict_thread主动扫描unzip CLOCK list和CLOCK list,将每个页面的use_times减1,遇到解压页会连同压缩页一起释放,需要的话还会进行刷脏,从而避免全表扫描页面长时间驻留在unzip CLOCK list和CLOCK list中。
1.2.6 Flush list
flush list用来存储buffer pool中所有修改过的页面,对应结构是buf_pool_t中的UT_LIST_BASE_NODE_T(buf_page_t) flush_list。如前所述,flush list中只有BUF_BLOCK_FILE_PAGE和BUF_BLOCK_ZIP_DIRTY这两种页面。flush list是LRU list + CLOCK list的子集。flush list中的页面按照最老修改的LSN(即第一次修改页面的LSN)排序,链表尾是LSN最小的页面,优先被刷入磁盘。多次修改不影响页面在flush list中的位置,如果刷盘的时候,页面存在多个LSN,那么这些修改将合并刷入磁盘。
1.2.7 Zip clean list
zip clean list仅存在于debug模式下,用于调试buffer pool的页压缩功能,对应结构是buf_pool_t中的UT_LIST_BASE_NODE_T(buf_page_t) zip_clean。zip clean list用于存储还没解压的,类型为BUF_BLOCK_ZIP_PAGE的干净压缩页。从源码中观察,zip clean list中的页面来源以下三类:
- 从磁盘读取压缩页时(buf_page_init_for_read)
- 解压页淘汰时,压缩页没有一起淘汰并且压缩页未被修改时(buf_LRU_free_page和buf_CLOCK_free_page)
- flush list中类型的页面完成刷盘,压缩页重新处于干净状态时(buf_flush_remove)
压缩页完成解压后,就会从zip clean链表中删除,然后根据请求是否带有independent hint来判断,解压页是加入unzip LRU list还是unzip CLOCK list。
1.2.8 Zip free list
zip free list是用来管理压缩页伙伴系统的链表,对应结构为buf_pool_t中的UT_LIST_BASE_NODE_T(buf_buddy_free_t) zip_free[BUF_BUDDY_SIZES_MAX]。buf_buddy_free_t由三部分组成分别记录了状态、页面描述符和下一节点指针,链表的第一个buf_buddy_free_t会记录链表中节点页面大小。从zip free list对应结构可以看出,其由多个对应page size不同大小(16K、8K、4K、2K、1K)的链表组成。构成zip free list的所有page的类似为BUF_BLOCK_MEMORY,所有页面存入zip hash中。
压缩页读取时,需要从zip free list中申请空间到block→page.zip.data,用于存储压缩页原始数据(buf_buddy_alloc),下面举例说明其申请过程,假设申请2K的空间:
- 如果没有在size为2K的链表上找到空闲空间,则去4K链表上寻找;找到则会进行伙伴分裂,高地址2K空间插入到2K链表中,低地址的2K空间返回。
- 如果没有在size为4K的链表上找到空闲空间,则去8K链表上寻找;找到则对8K空间进行2次伙伴分裂,将高地址空间的4K和2K分别插入对应链表,将最低地址的2K返回。
- 如果没有在size为8K的链表上找到空闲空间,则去16K链表上寻找;找到则对16K空间进行3次伙伴分裂,将高地址空间的8K、4K和2K分别插入对应链表,将最低地址的2K返回。
- 如果没有size为16K的链表,则通过buf_LRU_get_free_block从free list上申请新的页面,通过buf_buddy_block_register函数将页面设置为BUF_BLOCK_MEMORY,插入zip hash。之后进行4次伙伴分裂,将高地址空间的8K、4K和2K分别插入对应链表,将最低地址的2K返回。
伙伴系统调用buf_buddy_alloc释放空间。对于size为16K的空间回收,则直接清空后挂回到16K链表即可。对于size低于16K的空间回收,会先递归寻找其伙伴空间,如果伙伴空间也处于空闲状态,则合并至更大的size;如果合并失败,则将释放的空间挂至zip free对应链表中。通过这样的方式,尽可能减少伙伴系统中的内存碎片。
1.2.9 Withdraw list
withdraw list仅仅用于buffer pool缩小过程(bp resize),对应的结构为buf_pool_t中的UT_LIST_BASE_NODE_T(buf_page_t) withdraw。下面介绍buffer pool resize的过程:
- 用户设置innodb_buffer_pool_size参数会触发buffer pool size的更新函数innodb_buffer_pool_size_update,该函数设置srv_buf_resize_event,借此方式通知buffer pool更新事件。
- 专门用于处理buffer pool resize的后台线程buf_resize_thread接到srv_buf_resize_event事件,调用buf_pool_resize开启resize实际过程。
- 如果开启adaptive hash index(AHI),则暂时关闭并清空。
- 如果目标空间小于当前空间,则计算withdraw_target。当前buffer pool instance的最后部分多余的chunks将被回收。接下来借用withdraw list汇总收缩空间的页面(buf_pool_withdraw_blocks),buf_pool_withdraw_blocks详细逻辑如下:
- 合并伙伴系统(zip free list)中空闲的页面(buf_buddy_condense_free)。
- 扫描free list,将待收缩空间的页面从free list摘下,存入withdraw list。先处理free list的原因是避免后续LRU/CLOCK list重新分配页面的时候使用收缩空间的页面。
- 将LRU list进行一次刷盘,flush LRU长度受innodb_lru_scan_depth,innodb_buffer_pool_size变化量,当前LRU list长度、当前CLOCK list长度等因素影响。
- 扫描LRU list,将处于收缩空间的压缩页在伙伴系统中重新分配空间(buf_buddy_realloc),处于收缩空间的普通页在free list重新申请页面(buf_page_realloc)。
- 扫描CLOCK list,将处于收缩空间的压缩页在伙伴系统中重新分配空间(buf_buddy_realloc),处于收缩空间的普通页在free list重新申请页面(buf_page_realloc)。
- 如果withdraw list的长度未达到withdraw_target,则循环扫描buffer pool,单次循环10次没有达成目标,返回true表示本次回收不成功。
- withdraw list的长度达到withdraw_targe后,逐一校验所有收缩空间的页面是否都在withdraw list中(检查block→in_withdraw_list状态)。
- 停止正在进行的buffer pool load(页面预热的一种方式,后续将详细介绍)。
- 如果上一次buf_pool_withdraw_blocks回收失败,则打印所有非尚未启动状态的事务(trx_sys→mysql_trx_list)到错误日志告警,然后休眠一段时间后再次进入buf_pool_withdraw_blocks扫描buffer pool。休息时间规则为:重试次数5次及以内,休眠时间为重试次数*2s,重试次数大于5次,则只休眠10s。
- 上述所有过程允许并发负载,接下来将获取buffer pool所有mutex,锁定整个buffer pool,不再允许任何并发。
- 删除或者新增chunks:如果是收缩buffer pool,使用deallocate_chunk将多余的chunk,释放withdraw list;如果是扩展buffer pool,使用ut_zalloc_nokey_nofatal分配新内存,使用buf_pool_register_chunk初始化新chunk。
- 根据调整的结果,将buf_pool→curr_size调整到chunks的倍数,再重新设置innodb_buffer_pool_size。
- 如果新的buffer pool size是旧size的2倍或者不到1/2,将重新设置page hash和zip hash(buf_pool_resize_hash)。
- 释放buffer pool所有锁,允许并发负载。
- 如果新的buffer pool size是旧size的2倍或者不到1/2,进行lock_sys_resize和dict_resize,重新设置lock_sys->rec_hash、lock_sys->prdt_hash、lock_sys->prdt_page_hash、dict_sys->table_hash和dict_sys→table_id_hash等结构的大小。
- 重新开启AHI。
1.2.10 Hazard point
hazard point是用来避免逆向扫描链表过程的迭代器。hazard point与普通迭代器不同,当扫描过程的下一节点被其他操作移除或替换了时,hazard point能调整位置并指向被移除或替换的节点的下一有效节点,避免逆向扫描过程失败。使用hazard point逆向扫描链表的时间复杂度为O(N),可以避免逆向扫描失败时从头开始扫描而导致的最高 O(N*N)的时间复杂度。因此hazard point广泛应用于flush list、LRU list、CLOCK list等链表的批量操作中的链表扫描中。
hazard point的实现也不复杂,对应的基类为HazardPointer,包括get、set、is_hp、adjust、move等方法。使用于不同的链表时,基于基类派生出不同的子类,并添加定制化的方法。当逆向扫描链表时,每次循环通过get函数获取下一个节点,并将节点的下一节点设置为hazard point。并发的负载如果修改了链表,并且节点是hazard point(is_hp返回为true),则使用adjust函数将被修改的节点的下一节点设置为hazard point。
1.2.11 总结
上述介绍的链表都是用于管理需要持久化的页面的缓存。从内存来源来看,除未解压的压缩页的buf_page_t存储于临时分配空间,其他所有页面都存储于buf_pool→chunks中。从页面分布来看,通常而言,LRU list和CLOCK list描述了所有在buffer pool中的页面,unzip LRU list、unzip CLOCK list、flush list都是LRU list + CLOCK list的子集。从用途来看,LRU/unzip LRU list、CLOCK/unzip CLOCK list、free list、zip free list、flush list属于常规链表,服务于数据库正常服务,zip clean list和withdraw list属于特殊用途的list,zip clean list用于debug模式下压缩页面的调试,withdraw list仅仅服务于buffer pool resize。
第二部分、Buffer pool快速读写优化
2.1 Buffer pool初始化
Buffer pool初始化入口是buf_pool_init。在buf_pool_init中先通过ut_zalloc_nokey分配管理所有buffer pool instance的结构体(buf_pool_t)的buf_pool_ptr,接着为每个instance创建buf_pool_create线程来初始化instance中的链表、chunks、mutex、page_hash、zip_hash、hazard_point、用于purge异步读取页面的watch结构体等。chunks初始化结束后,逐一对每个block调用buf_block_init,对block的io、是否在逻辑链表、是否在page hash、zip hash等信息进行初始化,并添加到buf_pool->free链表中。
Buffer pool初始化过程中,内存申请比较常见的是使用减少了用户空间与内核空间地址拷贝(零拷贝)的mmap。在chunks初始化时,也会调用os_mem_alloc_large分配内存,尝试在Linux支持的情况下采用HUGETLB的方式分配内存。
2.2 单机buffer pool预热
MySQL官方为了让实例能够在重启后快速恢复到重启前的状态,在5.6版本开始支持了buffer pool单机预热的功能。单机预热功能分为dump和load两个步骤。
dump将实例重启前的所有buffer pool instance的LRU list中每个页面的space_id和page_no记录到本地innodb_buffer_pool_filename文件中。(space_id是数据文件的编号,page_no数据文件内的偏移。space_id与page_no可以唯一确定一个页面,详见浅析InnoDB文件结构)。为了尽可能避免扫描过程对buffer pool正常工作的影响,dump先将LRU list扫描过程中的页面信息记录在临时的数组中,扫描LRU list后立刻释放LRU_list_mutex锁,再在无锁的情况下将LRU list的信息写入innodb_buffer_pool_filename文件中。
load在实例重启后将本地innodb_buffer_pool_filename文件中记录的所有页面加载到buffer pool中,从而完成数据预热,将实例快速恢复成重启前的状态。load操作会遍历innodb_buffer_pool_filename文件两次(由于每个页面的信息只包括space_id和page_no,一共只占8个字节,正常情况下文件只有几百K到几G的级别,两次扫描带来的IO量尚可接受)。第一次遍历整个文件以确定其中总共包含的page记录数,如果page记录数超过当前buffer pool size,调整待读入的page总数。第二遍扫描文件时,先按照第一遍得到的page数量,创建好page数组,再依次读入innodb_buffer_pool_filename文件中所有的page记录。为提高IO效率,对page数组进行按照space_id和page_no排序。最后才使用buf_read_page_background函数在后台将所有页面加载到LRU list中的midpoint中。
官方数据预热的特点如下:
- 能够精准高效地恢复实例重启前的状态。
- 应用场景比较有限,只能用于单机预热,无法解决主从切换、跨机迁移场景的预热需求。
2.3 主从buffer pool同步
MySQL官方提供的dump和load操作只能用于单机预热的根本原因是:MySQL的主从复制是逻辑复制,非物理复制。数据虽然是一致的,但是主从数据的分布是不一样的。InnoDB的所有数据都存储于B+树中,也可简单理解为主从所对应数据的B+树的结构是不一样的,在从库按部就班加载B+树相同位置的页面无法解决主从切换、跨机迁移等多场景的预热问题。
主从缓存同步是CDB针对主从多场景下快速buffer pool预热的解决方案,其从逻辑复制的思路出发,通过主从逻辑数据一致的角度解决了多场景的预热问题。主从缓存同步分为snapshot、transmit、recover三个步骤:
snapshot将主库buffer pool状态逻辑导出到主库本地的ib_bp_info文件中,具体过程如下(buf_snapshot):
- 逐一扫描每个所有buffer pool instance的LRU list和CLOCK list中的每个页面,将页面的space_id和page_no汇总到以space_id为key,unordered_set为value的lru_maps中。扫描结束后,所有页面按照space_id进行了初步归类。
- 逐一处理每个space_id下的页面。通过页面的前后节点指针,将相邻的页面串联成页面链表,并用最左页面、最左页面的第一条用户记录、最右页面、最右页面最后一条用户记录代表该页面链表,存入multi_ranges中(link_page)。
- 将multi_ranges中所有record range按照一定格式落盘到本地ib_bp_info文件中。
针对如何传输ib_bp_info文件,有很多备选方案:采用scp来传输文件误操作的可能性比较高,并且经常修改传输脚本;采用binlog传输会加重binlog的负担,加大主从延迟的风险,方案复杂,风险大;采用内建表的方式同步文件又担心引入兼容性的问题。主从缓存通过最终选择了transmit方案,即在slave新创建一种与IO线程相似,需要与master建立tcp连接的transmit线程(handle_slave_transmit),该线程负责向master发送ib_bp_info文件传输申请,并负责接收ib_bp_info文件。transmit方案不侵入主从复制的原有逻辑,对于不支持transmit的主库,也仅仅是无法从主库获取ib_bp_info文件,不存在兼容问题。
recover将ib_bp_info文件中代表的数据加载到从库buffer pool中。recover可以在跨机迁移前、版本升级前、主从切换前或切换过程中进行,也可以定期将主库的buffer pool同步到从库,随时做好切换准备。recover具体过程如下(buf_recover):
- 按固定格式识别ib_bp_info中的record_range信息。
- 在从库通过B+树搜索record_range最左页面的第一条用户记录和最右页面的最后一条用户记录对应的两个页面。
- 将上述两个页面之间的所有页面加载到buffer pool中。为了避免新加载的页面互相淘汰,recover操作还支持将新页面直接加载到LRU list的头部而不是midpoint。
- 重复1-3步骤,直至ib_bp_info中所有recored_range被处理完成。
2.4 Change buffer优化
2.4.1 原理
innodb的二级索引与cluster index相同,也存储在B+树中。cluster index与二级索引的B+树节点散落在数据文件中。在此架构下,一条普通的DML都可能因为需要修改多个二级索引,而带来大量随机IO,对innodb的性能带来巨大挑战。
change buffer就是为了解决二级索引随机IO问题而引入的缓存。当待插入、删除、修改的记录所在的二级索引页面不在buffer pool中时,修改内容会以记录的形式缓存到change buffer中。当二级索引页面最终被读入buffer pool中时,需要检查change buffer中是否有该页面的修改记录,如果存在需要将修改记录合并到新读入的二级索引页面上,再返回。change buffer适用于buffer pool大小有限,无法将所有数据缓存到buffer pool,并且有大量二级索引需要更新的场景。但如果buffer pool足够大到能缓存所有索引页面,或者随机IO的速度和顺序IO的速度所差无几,也可以考虑关闭change buffer。
2.4.2 实现
innodb在Mysql-5.5版本之前的版本中只支持了二级索引的insert buffer,后续才支持了update和delete,名称改为了change buffer。而在代码层面上,很多以ibuf为前缀的参数、函数、文件沿袭了下来,没有做修改。
change buffer本身也是一颗B+树,它位于系统表空间(space_id为0),根结点的page_no固定为4(FSP_IBUF_TREE_ROOT_PAGE_NO),所有innodb用户表的二级索引变更都缓存在同一颗B+树上。一条change buffer record中的信息包括:
- IBUF_REC_FIELD_SPACE:二级索引的space_id。
- IBUF_REC_FIELD_MARKER:用于以4.1.x版本为界区分新旧版本,新版本该值为0。
- IBUF_REC_FIELD_PAGE:二级索引的 page_no。
- IBUF_REC_FIELD_METADATA分为以下三项信息:
- IBUF_REC_OFFSET_COUNTER:相同space_id和page_no页面内的操作序号,单调递增。
- IBUF_REC_OFFSET_TYPE:缓存的操作的类型,IBUF_OP_INSERT(插入);IBUF_OP_DELETE_MARK (用户删除,二级索引的删除都是delete_mark + insert);IBUF_OP_DELETE(purge操作)。
- IBUF_REC_OFFSET_FLAGS:待操作的用户记录格式,REDUNDANT / COMPACT。
- IBUF_REC_FIELD_USER:用户列数据。
change buffer的B+树以(space_id、page_no、counter)为主键,来确保记录的唯一性以及apply时的顺序。change buffer在正常运行过程中必须保证缓存合并到二级索引后,二级索引不能发生分裂或合并操作,否则缓存到主键将对应到未知的页面而失效。为此需要实时获取目标二级索引页面的剩余空间,innodb的方案是在数据文件中(ibdata或ibd)。page_size是默认大小16KB的情况下,page_no为1、1+16384*N的页面都是FIL_PAGE_IBUF_BITMAP类型,用于记录其后16384个页面change buffer的信息。FIL_PAGE_IBUF_BITMAP页面用4个bit来描述一个页面:
- IBUF_BITMAP_FREE占2个bit,表示页面空闲的空间范围。其值是页面当前剩余空间max_ins_size/512字节的结果。0表示max_ins_size处于[0,512)字节中间,1表示max_ins_size处于[512,1024)字节中间,2表示max_ins_size处于[1024,2048)字节中间,3表示max_ins_size大于2048字节(ibuf_index_page_calc_free_bits)。
- IBUF_BITMAP_BUFFERED占1个bit:表示页面是否有操作缓存,准备向change buffer B+tree插入前会将对应二级索引页面的IBUF_BITMAP_BUFFERED设置为true(ibuf_insert_low)。二级索引页面物理页面被读入buffer pool时会根据该标记判断是否需要进行change buffer 合并操作(buf_page_io_complete)。
- IBUF_BITMAP_IBUF占1个bit:表示页面是否为change buffer B+tree 的节点。
DML运行过程中会实时将二级索引信息变化更新到FIL_PAGE_IBUF_BITMAP页面中。在change buffer插入过程中,如果发现准备插入的change buffer record可能会导致二级索引页面分裂,则插入失败并调用ibuf_get_merge_page_nos触发一次从当前cursor位置附近开始的异步的change buffer 合并操作,目的是尽量将当前页面的缓存操作做一次合并(ibuf_insert_low)。此外为避免出现空页面,需要在purge线程真正删除记录时使用ibuf_get_volume_buffered预估合并完页面所有change buffer record之后的记录数,如果二级索引页面上记录等于1(加上purge线程这次缓存的删除操作将变为空页面),则索引插入失败,改走正常读入物理页面逻辑。
二级索引记录没有trx_id这一系统列,这为缓存purge线程删除记录操作带来了困难,难以区分真正要删除掉的记录。为避免purge线程删除操作误删用户reinsert的二级索引记录,如果purge操作先进入ibuf_insert,则用户后续的insert操作将放弃缓存插入,转而读取物理页面;如果insert操作先进入ibuf_insert,则purge操作也放弃缓存删除。
change buffer页面的与普通索引页面相同,其修改也是先记录redo日志后刷盘,在crash recover时,同样需要redo来保证一致性。change buffer可以理解为记录在index page上的二级索引更改日志。
2.4.3 缓存条件
只有满足一定条件时,二级索引变更才会被change buffer缓存,判断条件如下(ibuf_should_try):
- 用户设置了innodb_change_buffering,innodb_change_buffer_max_size非0。
- 非数据字典表空间,非聚簇索引,非空间索引。
- 对IBUF_OP_INSERT操作要求二级索引为非unique类型,对于其他操作不限制二级索引是否为unique类型。
- 只缓存二级索引叶子结点(不包括B+树只有一层时的根节点)。
- 表上没有flush 操作,例如执行flush table for export时,不允许对表进行缓存 (通过dict_table_t::quiesce进行标识)。
- 二级索引不能只包含降序列。
2.4.4 合并时机
有以下几种场景会触发change buffer合并操作:
- 用户线程触发二级索引页面的读取时,例如用户通过二级索引查询数据(buf_page_io_complete)。
- 尝试将缓存插入change buffer,但预估二级索引页面空间不足,可能导致页面分裂时,会调用ibuf_get_merge_page_nos从当前cursor位置附近开始的异步的change buffer merge(ibuf_insert_low)。
- change buffer B+tree size空间变化(ibuf_contract_after_insert):
- size小于innodb_change_buffer_max_size配置大小时,不做处理。
- size介于innodb_change_buffer_max_size配置大小与innodb_change_buffer_max_size配置大小 + 5之间,执行一次异步change buffer merge,位置随机。
- size大于innodb_change_buffer_max_size配置大小 + 5 (IBUF_CONTRACT_ON_INSERT_SYNC)时,执行一次同步change buffer merge(ibuf_contract),位置随机。
- size大于innodb_change_buffer_max_size配置大小 + 10(IBUF_CONTRACT_DO_NOT_INSERT)时,执行一次同步change buffer merge(ibuf_contract),不再允许change buffer插入。
- innodb master线程调用ibuf_merge_in_background 合并change buffer。master线程较为空闲时,会以100%的io capacity合并change buffer(srv_master_do_idle_tasks),系统活跃时则根据change buffer size来控制io capacity,size越大io capacity比例越高(srv_master_do_active_tasks)。
- slow shutdown时,会调用ibuf_merge_in_background全量合并change buffer(srv_master_do_shutdown_tasks)。
- 对某个表执行flush table for export操作时,会调用ibuf_merge_space强制合并change buffer(row_quiesce_table_start)。合并change buffer是为flush for export准备的,避免准备拷贝的ibd文件对change buffer有依赖。
2.5 Adaptive hash index优化
2.5.1 原理
innodb的数据存储于B+树中,B+树通常不会太高,通常只有3到5层。从根节点到叶节点的寻路涉及到多层页面内记录的比较,即使所有路径上的页面都在内存中,也是比较消耗CPU的操作。
对寻路到CPU开销优化分两部分,第一部分为尽可能避免寻路次数,innodb为此设计了多个优化,例如一次寻路多缓存几条记录到fetch_cache中;寻路结束将cursor缓存到row_prebuilt_t::pcur,方便下次查询复用。第二部分为尽可能避免单词寻路的开销。Adaptive hash index(AHI)便是为此而设计。AHI可以理解为建立在B+树上的索引,它采用自适应的方式管理,为B+树寻路建立以查询条件为key,B+树record地址为value的hash index。
AHI的大小为buffer pool size的1/64,在buf_pool_init中调用btr_search_sys_create初始化。为了避免AHI的锁竞争压力,innodb支持AHI分区,可以使用innodb_adaptive_hash_index_parts参数配置分区个数,默认为8。当buffer pool size动态调整大小为原大小的2倍以上或者1/2以下时,AHI也随之调用btr_search_sys_resize调整大小(buf_pool_resize)。
2.5.2 创建过程
当innodb_adaptive_hash_index参数打开,非临时表、非空间类型的索引会累加索引被使用的次数,当使用次数小于17(BTR_SEARCH_HASH_ANALYSIS),当前索引被认为不够热,被自动忽略(btr_search_info_update)。索引次数达标后,进入下一步骤。
AHI的key与用户的查询条件相关,每个索引(dict_index_t)都包含用于存储查询条件的search_info(btr_search_t)。search_info主要用三项信息描述查询条件:完整匹配的匹配列数n_fields,不完整匹配的列的前缀字节数n_bytes,是否为左侧匹配left_side。如果查询条件与上一次缓存的相同,则将search_info->n_hash_potential加1。否则清空search_info,重新设定index的查询条件(btr_search_info_update_hash)。
即使索引通过了筛选,查询条件通过了考核,AHI也不会对索引的每个页面都建立hash index。对于需要创建AHI的页面还需要经过一轮筛选:某页如果能通过当前search_info命中,则对页面的n_hash_helps加1(当前search_info首次命中到页面,还会将search_info信息记录在页面buf_block_t中)。如果页面的n_hash_helps大于记录数/16(BTR_SEARCH_PAGE_BUILD_LIMIT)并且search_info->n_hash_potential大于100(BTR_SEARCH_BUILD_LIMIT),则对该页面创建AHI。对于已经创建过AHI的页面,只有页面的n_hash_helps大于记录数的两倍,或者search_info发生改变了才会重新创建AHI(btr_search_update_block_hash_info)。
创建AHI之前,会先检查AHI锁的状态,如果其他线程正在持有AHI的X锁,则先跳过本次AHI的创建。原因是当前处于B+树搜索的关键路径,在此处等锁会拖累其他B+树的搜索效率,而本次search_info→n_hash_potential和页面的n_hash_helps状态并未清空,下一次该页面被读取时会再次触发AHI创建流程。AHI的创建过程分为5步(btr_search_build_page_hash_index):
- 再次判断innodb_adaptive_hash_index参数打开,并且当前索引非临时表索引。
- 加AHI的S锁,如果当前页面已经创建AHI并且与当前search_info不同,则解锁后调用btr_search_drop_page_hash_index删除旧AHI索引,否则直接解开S锁。
- 根据当前search_info挑选出具有代表性的记录,计算hash fold值,并记录在folds和recs两个数组中。举例,假设page上记录为 (2,1), (2,2), (5, 3), (5, 4), (7, 5), (8, 6),n_fields=1
- 若left_most为true,则hash存储的记录为(2,1) , (5, 3), (7, 5), (8,6)
- 若left_most为false,则hash存储的记录为(2, 2), (5, 4), (7,5), (8, 6)
- 重新加上AHI的X锁,检查block上的search_info,如果发生变化则放弃本次AHI构建,否则插入上一步准备好的folds和recs两个数组,插入AHI中。
- 解开AHI的X锁,释放folds和recs两个数组的内存。
2.5.3 使用条件
AHI的使用在B+树搜索的关键路径上,使用AHI的几个条件如下(btr_cur_search_to_nth_level):
- AHI处于非X锁状态。AHI查询过程中要加AHI的S锁,等锁会导致AHI得不偿失。
- 加锁模式为BTR_SEARCH_LEAF或BTR_MODIFY_LEAF,即本次查询不变更B+树结构,只在叶子节点查询或者修改页面内的单条记录。
- 索引上的search_info显示上一次AHI使用成功。
- 当前索引非空间索引。
满足上述条件后,在正式搜索AHI之前,会再次对比索引的最新search_info是否已经被重置了,即search_info→n_hash_potential是否等于0,以及当前查询条件的列数相比search_info是否完整。前者等于0意味着当前旧AHI记录已经被删除;后者查询条件不足意味着当前查询条件不足以构建AHI的key值进行查询,两种情况都只能放弃AHI查询,转而使用正常的B+树搜索(btr_search_guess_on_hash)。接下来,将查询条件转化为AHI的key值,加AHI的S锁从AHI中读取数据(ha_search_and_get_data)。如果查询失败了,并且页面上的search_info信息仍然与索引上的search_info相同,则会将新的记录插入AHI中(btr_search_update_hash_ref)。
从上述AHI创建过程中可以看到,只有较为查询模式较为固定的业务才能经过层层筛选,创建出AHI,从该功能中受益。
2.5.4 自适应维护- 自动插入与更新:叶节点的新记录如果未产生页面重组,则新记录插入或更新到AHI中(btr_search_update_hash_on_insert、btr_search_update_hash_node_on_insert)。
- 自动记录删除:记录删除时,如果记录的fold存在于AHI中,则将其删除(btr_search_update_hash_on_delete)。
- 自动全页面记录删除:AHI作用是加速内存中B+数的搜索。当页面从内存淘汰(buf_LRU_free_page或buf_CLOCK_free_page)时,AHI会自动删除。此外,页面发生合并、分裂时记录地址发生变更,调整后的页面相当于新读入内存的页面,旧AHI信息会删除(btr_search_drop_page_hash_index)。删除方法为找到页面所有具有代表性的folds,调用ha_remove_all_nodes_to_page删除。
- 自动全索引AHI删除:当索引被删除时则需要所有此索引相关AHI删除。删除方法为遍历LRU list和CLOCK list上的所有页面,将该索引的页面存入数组中。最后注意删除每个页面的AHI记录(btr_drop_ahi_for_index)。
- 自动全表记录AHI删除:当表被删除时,触发全表记录的AHI删除。删除方法为逐一删除每个索引的AHI记录(btr_drop_ahi_for_table)。不过当表非常大时,全表记录的AHI删除非常缓慢,删表过程持有dict_sys->mutex,将长时间阻塞此实例其他DDL操作,其他DDL操作也会长期持有更多资源,进而阻塞整个系统。一种tradeoff的做法是当改表的AHI记录数量足够多或者比例足够大时将整个AHI都清空。AHI的清空不影响数据查询的正确性,而AHI最终还能再次创建。上述方法可以用此暂时的效率降低换来系统的稳定。
第三部分、页面读取过程解读
3.1 页面读取堆栈
buf_page_get_gen Buf_fetch<T>::single_page Buf_fetch_normal::get lookup read_page buf_read_page_low buf_page_init_for_read buf_LRU_get_free_block buf_LRU_get_free_only buf_LRU_scan_and_free_block buf_LRU_free_from_unzip_LRU_list???????????????? buf_LRU_free_page buf_LRU_block_remove_hashed buf_LRU_free_from_common_LRU_list buf_flush_single_page_from_LRU buf_LRU_add_block buf_LRU_add_block_low fil_io buf_page_io_complete3.2 核心函数概述
buf_page_get_gen- 检查页面获取mode是否是7类获取模式之一,不是则报错。
- 如果页面获取类型是NORMAL并且页面不是系统临时系统表,则使用Buf_fetch_normal的single_page函数获取页面;否则页面采用Buf_fetch_other的single_page函数获取页面。
Buf_fetch<T>::single_page- 调用Buf_fetch子类的的get函数(例如Buf_fetch_normal::get、Buf_fetch_other::get)获取页面,如果get函数结果为DB_NOT_FOUND,则向上返回nullptr,否则继续往下。
- 检查页面获取类型是否为乐观类型(IF_IN_POOL或PEEK_IF_IN_POOL),持锁获取block的io_fix(表示IO操作状态)的状态,如果是BUF_IO_READ状态,说明页面正在读到BP的过程中,不继续等待其完成,将block的buf_fix_count(表示当前对该页面操作的次数)减1,返回nullptr。
- 用check_state和debug_check检查block的状态,如果状态是DB_NOT_FOUND,则返回nullptr;如果状态是DB_FAIL则从1重新开始。
- 调用buf_page_is_accessed获取block的第一次读取时间access_time,如果access_time=0,表示这是block第一次被读取。
- 如果页面获取模式非scan类型,则为access_time为0的页面设置access_time,假设页面获取模式非scan且非PEEK_IF_IN_POOL,则调用buf_page_make_young_if_needed在需要的时候make young,即将页面移入lru的young list头部,避免其快速被淘汰。
- 使用buf_wait_for_read函数等待页面完成读入。
- 如果读取模式不是PEEK_IF_IN_POOL或者SCAN,并且是第一次读入的话调用buf_read_ahead_linear进行线性预读。结束后向上一层函数返回block。
Buf_fetch_normal::get- 使用normal模式读取页面。先调用look_up函数page_hash中查找,找到则用buf_block_fix对page的buf_fix_count++,表示增加了一个线程在读取这个页面,解锁page_hash分区锁。
- lookup失败则使用read_page函数在磁盘中读取该页面。失败则再次回到1尝试(异步IO的缘故),读取成功后返回block。
Buf_fetch_other::get- 使用非normal模式读取页面。先调用look_up函数page_hash中查找。调用buf_block_fix对buf_fix_count++,表示增加了一个线程在读取这个页面,解锁page_hash分区锁。(临时表空间使用block->mutex在用户线程和刷盘线程之间同步,需要额外加block->mutex)
- 如果读取模式是IF_IN_POOL_OR_WATCH,调用is_on_watch等待block被读取并得到block。
- 如果block此时非空,从循环中退出并返回找到block。
- 如果页面获取类型是乐观类型(IF_IN_POOL或PEEK_IF_IN_POOL)或者为IF_IN_POOL_OR_WATCH,返回nullptr。
- 使用read_page函数在磁盘中读取该页面。失败则再次回到1尝试(异步IO的缘故),读取成功后返回block。
Buf_fetch<T>::lookup- 在hash_scan中查找页面。先获取分区锁。
- 加锁后,担心page_hash情况有变,用buf_page_hash_lock_s_confirm再次确认,如果确认锁变化了,则在循环中释放旧锁加上新锁,再次检测,直到变化结束。
- 如果guess block不在bp中,或者不属于BUF_BLOCK_FILE_PAGE类型说明猜测失败。尝试用buf_page_hash_get_low从page_hash中读取页面,如果还是读取失败则解锁page_hash的分区锁然后返回nullptr,如果从buf_page_hash_get_low读到页面,从buf_pool->watch检查这个页面是否是被watch的页面,是的话解锁page_hash的分区锁然后返回nullptr,否的话返回页面。
Buf_fetch<T>::read_page- scan模式异步调用buf_read_page_low异步读取页面。其他模式调用buf_read_page同步读取页面,buf_read_page底层也是调用buf_read_page_low,但是输入的是同步读取参数。读取失败则最多重试BUF_PAGE_READ_MAX_RETRIES次,直至成功。
- 同步读取的话还会尝试随机预读,随机预读为:一个extent中超过一定数量的页面被读取则将整个extent全部读取到内存。
buf_read_page_low
此函数的第四参数mode并非Page_fetch,而是BUF_READ_IBUF_PAGES_ONLY和BUF_READ_ANY_PAGE二选一,前者是指读取ibuf页面。
- 支?持同步和异步读取,如果是ibuf_bitmap或者系统表空间事务头页面(0,5)则直接不论传入的参数是同步读取还是异步读取,都改为同步读取。
- 使用buf_page_init_for_read准备一个空block,函数逻辑后续有详细介绍。
- 如果是同步模式,调用thd_wait_begin,准备同步等待io完成。
- 如果是压缩页面的话,读入的内存位置是bpage->zip.data,否则是((buf_block_t *)bpage)->frame。调用fil_io读取页面。
- 如果是同步模式,调用thd_wait_end,表示同步io结束。
- 如果出现表空间不存在等情况导致io不成功,调用buf_read_page_handle_error报错。
- 如果是同步模式,调用buf_page_io_complete。buf_page_io_complete简单分两类BUF_IO_READ、BUF_IO_WRITE。对于BUF_IO_READ,通过页面前后的checksum检查页面是否损坏,损坏的话,得看srv_force_recovery的级别,如果低于SRV_FORCE_IGNORE_CORRUPT,则使用报错。没有报错则修改页面状态为BUF_IO_NONE,更新统计信息;对于BUF_IO_WRITE则是加锁后调用buf_flush_write_complete将页面移除flush_list,更新相应统计信息。
- 返回。
buf_page_init_for_read- BUF_READ_IBUF_PAGES_ONLY是ibuf的预读路径。该类型下,recv_no_ibuf_operations为false(没有进行crash recovery),并且目标页面不是ibuf的层次结构中的2层或者3层页面(ibuf_page函数范围false),则返回nullptr。
- 如果page_size是压缩页面,而请求的是非压缩页面,并且没有进行crash recovery时,将block设置为nullptr。否则使用buf_LRU_get_free_block获取一个free_block。buf_LRU_get_free_block逻辑后续有详细介绍,大概内容为从LRU list中找到合适的block,如果没有从LRU list获取到则尝试刷盘。
- 如果block为nullptr,说明准备读取的是一个压缩页,用buf_page_alloc_descriptor分配一个临时页面描述符bpage,再调用buf_buddy_alloc从伙伴系统中分配一个空间存放压缩页原始数据。这个临时bpage会等到页面被解压成功,使用buf_relocate函数从free_list中申请到的bpage替换掉临时bpage,放在LRU list相同的位置。
- 调用buf_page_hash_get_low尝试从page_hash中读取该block。如果读到页面,并且该block不是被watch的页面,说明这个页面已经在buffer pool中了。释放临时资源:释放临时分配的描述符(如果分配了)、释放伙伴系统中分配的空间(如果申请了)、将空闲block插入free_list(如果block不为空),跳到函数结束处准备返回。
- block不为空,则调用buf_page_init:初始化该block,并调用HASH_INSERT该页面插入page_hash。调用buf_LRU_add_block将block插入LRU。参数is_old为true的话,插入old_list头部,参数is_old为false的话,插入young list头部。如果LRU_list很短,LRU_list将不再划分young、old,新block将直接被插入LRU_list头部。如果页面是压缩页面的解压页,还会先设置block->page.zip.data,然后将该页面加入unzip_LRU_list中。如果页面是临时表页面并且开启了srv_temp_tablespace_fast_cleanup,还会调用temp_tablespace_pages_map_add,将页面插入buf_pool->temp_tablespace_pages。
- 如果block为空,说明是压缩页。将从伙伴系统申请到的空间设置到bpage->zip.data中。调用buf_page_init_low初始化临时页面描述符bpage。调用buf_LRU_add_block将block插入LRU。参数is_old为true的话,插入old_list头部,参数is_old为false的话,插入young list头部。如果LRU_list很短,LRU_list将不再划分young、old,新block将直接被插入LRU_list头部。DEBUG模式下,将临时描述符bpage加入通过buf_LRU_insert_zip_clean函数加入zip_clean链表中。将bpage状态设置为BUF_IO_READ。
- 如果是BUF_READ_IBUF_PAGES_ONLY类型,调用ibuf_mtr_commit提交mtr。否则返回页面。
buf_LRU_get_free_block- ?调用buf_LRU_get_free_only:如果free_list有空闲的block则将block->page.zip设置为空后返回。
- 如果没有从free_list得到空闲的block,则判断多次从lru_list中淘汰block并获取。如果设置了try_LRU_scan,则调用buf_LRU_scan_and_free_block开始第一轮扫描LRU list,最多从LRU list尾部扫描srv_LRU_scan_depth个block,如果还没成功的话调用buf_flush_single_page_from_LRU将flush list中最尾部的页面刷入磁盘。如果还是没有获取到空闲block则跳转到步骤2重新开始第二轮扫描。
- 第二轮扫描,即使没有设置try_LRU_scan,也会扫描整个lru list。没有获取到空闲block则再调用buf_flush_single_page_from_LRU将flush list中最尾部的页面刷入磁盘。还是没获取空闲页面则进入第三轮。
- 第三轮扫描开始,每轮中间间隔10ms,其他和第二轮扫描相同。如果超过20轮都没找到合适的block,则向用户告警:调大BP或升级操作系统版本。
?buf_LRU_get_free_only- 负责从buffer_pool的free_list中获取一个空闲的block。获取的方法是用封装好的list操作接口:UT_LIST_GET_FIRST。
- 获取不到空闲block直接返回nullptr。如果顺利获取的空闲的block,需要判断此block是否准备被resize buffer pool操作回收:使用buf_block_will_withdrawn判断当前页面是否准备回收的页面(最后一个chunk的block),使用buf_get_withdraw_depth判断withdraw list的页面是否达到释放目标大小。如果经上述判断页面不需要被resize回收则返回block,否则将block插入withdraw list中,循环使用UT_LIST_GET_FIRST从free_list尝试再获取一个block,循环判断是否有空闲block,以及block是否恰好需要被回收。
buf_LRU_scan_and_free_block- 如果是用了压缩页(use_unzip_list为true),则调用buf_LRU_free_from_unzip_LRU_list从unzip_LRU_list中淘汰空闲block。这一步只释放压缩页的解压页,压缩页本身并不需要释放。
- 如果上一步没有成功释放空闲block,则再调用buf_LRU_free_from_common_LRU_list从lru_list中淘汰空闲block。
- 如果前两步骤没有成功释放空闲block,则释放LRU_list_mutex锁,否则退出时不释放buf_pool->LRU_list_mutex锁。
buf_LRU_free_from_unzip_LRU_list- 调用buf_LRU_evict_from_unzip_LRU判断是需要从unzip_LRU_list中淘汰页面。如果unzip_LRU_list是空或者unzip_LRU_list的空间小于LRU_list空间的10%,则拒绝从unzip_LRU_list淘汰。此外,通过公式判断当前业务类型,如果是IO bound类型,则只淘汰解压页,不淘汰压缩页;CPU bound类型则连压缩页也淘汰。
- 使用for循环从尾到头扫描(或者最多扫描srv_LRU_scan_depth个页面)unzip_LRU_list,逐一调用buf_LRU_free_page尝试释放页面,释放解压的压缩页不会释放压缩页原数据,最后返回释放状态freed。成功释放为true。
buf_LRU_free_from_common_LRU_list
从buf_pool->lru_scan_itr.start()开始扫描LRU_list,如果扫描个数没达到BUF_LRU_SEARCH_SCAN_THRESHOLD或者是全表扫描则一直向下扫描。使用buf_flush_ready_for_replace判断页面是否能立即替换:先使用buf_page_in_file判断页面是否为文件页面类型之一:BUF_BLOCK_FILE_PAGE、BUF_BLOCK_ZIP_DIRTY、BUF_BLOCK_ZIP_PAGE;再调用buf_LRU_free_page判断页面是否能淘汰成功。此轮淘汰将淘汰压缩页原数据。
buf_LRU_free_page
尝试从LRU list中释放一个页面,中间有临时释放锁再加锁的逻辑,实现比较复杂。
- 先调用buf_page_can_relocate判断页面是否正在被读取,判断方法是查看页面是否正在被其他页面读取,如果在被读取则直接返回释放失败。
- 查看当前页面是否为被修改过的压缩页面,是的话页返回失败。
- 调用buf_LRU_block_remove_hashed将页面从page_hash表中删除。
- 如果是压缩页面的解压页,则再将压缩页面插入LRU_list(如果前一个页面不为空,则调用UT_LIST_INSERT_AFTER插入,如果前一个页面为空,则调用buf_LRU_add_block_low插入midpoint或者young_list头部),page_hash(使用HASH_INSERT),如果有必要的话还需要插入flush_list。
- 如果不是BUF_BLOCK_ZIP_PAGE类型,说明是脏页(BUF_BLOCK_ZIP_DIRTY),使用buf_flush_relocate_on_flush_list插入放入flush_list合适的位置。
- 检查页面是否有自适应hash(adaptive hash index),有的话则删除,对应函数为btr_search_drop_page_hash_index。
- 调用buf_LRU_block_free_hashed_page将释放成功的,不再被page_hash索引的页面,放回free_list上。
buf_LRU_free_page有一个参数配置是否释放解压页的原压缩数据。buf_LRU_free_from_unzip_LRU_list中这个参数是false,即默认不删除压缩页的原数据。buf_LRU_free_from_common_LRU_list中这个参数是true,即将压缩页原数据删除。
buf_LRU_add_block_low- 如果old参数为false,或者LRU_list的总长度小于BUF_LRU_OLD_MIN_LEN,将页面插入young_list的开头。否则插入old_list的头部之后。
- 调整 LRU_list长度,old_list头部位置等。如果LRU_list现在长于BUF_LRU_OLD_MIN_LEN,则将其初始化为young_list和old_list两部分。
- 用buf_page_belongs_to_unzip_LRU判断:如果当前页面是一个解压缩页面,则也同时将此页面插入unzip_LRU_list(buf_unzip_LRU_add_block)。
buf_flush_single_page_from_LRU
用来淘汰一个页面,将其刷盘。并将页面从page_hash和LRU_list中删除,放入free_list。
- 加LRU_list锁进入for循环
- 从尾巴逐一先用buf_flush_ready_for_replace判断页面当前页面是否可以直接释放(检查oldest_modification==0,buf_fix_count==0,处于BUF_IO_NONE状态),是则调用buf_LRU_free_page将页面释放。
- 上一步骤没有成功,则调用buf_flush_ready_for_flush来将一个可以被刷盘的页面刷入磁盘(检查oldest_modification是否不等于0,页面是否在被读取,刷盘模式是否正确等)。是则调用buf_flush_page将页面单独同步刷盘。
- 上述两个步骤成功一个即可退出循环,释放锁,返回刷盘是否成功。
buf_relocate
将压缩页的bpage从LRU中删除,重新分配block,把bpage中的内容拷贝到block->page中,把dpage (block->page)插入bpage的位置。