DawnSqlПьЫйШыУХ
дДДDawnSqlПьЫйШыУХ
дДД
1ЁЂЩшжУХфжУЮФМў
1.1ЁЂХфжУЮФМўЕФЮЛжУ
АВзАЮФМўНтбЙКѓЃЌНјШы config ФПТМЃЌХфжУЮФМўЃКdefault-config.xml
1.2ЁЂЩшжУГЌМЖЙмРэдБЕФ root token
<!-- ГЌМЖЙмРэдБЕФ root token, гУЛЇПЩвджБНгРДЩшжУвЛИі root token -->
<!-- БОР§жа root token ЮЊ dafu -->
<property name="root_token" value="dafu"/>DawnSql жагУЛЇЪЧЭЈЙ§ user_token РДЧјЗжгУЛЇжЎМфЕФЗУЮЪШЈЯоЕФЁЃ
Р§ШчЃК
дкЭЈЙ§ jdbc ЗУЮЪЕФЪБКђЃЌuser_token ЪЧБиаывЊЩшжУЕФЁЃ
Class.forName("org.apache.ignite.IgniteJdbcDriver");
String user_token = "my_token";
String url = "jdbc:ignite:thin://127.0.0.1:10800/public?lazy=true&userToken=" + user_token;
Connection conn = DriverManager.getConnection(url);1.3ЁЂгУЛЇЪЧЗёЪЕЯжСЫ log ЪТЮёНгПкЁЃФЌШЯЪЧУЛгаЪЕЯжЃЌетИіашвЊгУЛЇИљОнздМКЕФЪЕМЪашЧѓРДЪЕЯжЁЃ
<!-- ЩшжУЪЕЯж log ЪТЮёНгПкЕФРр -->
<!--
<property name="myLogCls" value="org.gridgain.smart.logClient.MyLogTransactionClient"/>
-->1.4ЁЂЪЧЗёЪЕЯжСЫГѕЪМЛЏКѓОЭжДааЕФЗНЗЈ
МШЪ§ОнПтЯЕЭГЃЌГѕЪМЛЏЭъГЩКѓЃЌТэЩЯжДааЕФЗНЗЈ
<!-- ЩшжУЦєЖЏЕФЪБКђЃЌГѕЪМЛЏ rpc ЗўЮёЦї -->
<!-- org.dawn.rpc.MyRpcStartImpl ЪЧЪЕЯжСЫ IDawnSqlStart НгПкЕФРр -->
<!-- ВЛЩшжУдђВЛЦєЖЏетИіЗўЮёЃЌОпЬхДњТыПЩвдВЮПДПЊдДЕФР§зг -->
<property name="startAppCls" value="org.dawn.rpc.MyRpcStartImpl"/>ФЌШЯЕФЪЧПЊЦє DBeaverWeb ЗУЮЪ DawnSql МЏШК(ЭЦМіЪЙгУ) ЕФЗНЗЈ
ОпЬхЪЙгУЗНЗЈЃК
- ЩшжУЭъГЩКѓЃЌНјШыАВзАЮФМўФПТМЯТЃЌЦєЖЏ DawnSql Ъ§ОнПтЃК АВзАВЂМЄЛю DawnSql
- ЯТди DBeaverWeb ЕФ war Аќ ЯТди DBeaverWeb ЕФ war Аќ
- ЦєЖЏ DBeaverWeb ЦєЖЏ DBeaverWeb
- DBeaverWeb ЕФдДТы DBeaverWeb ЕФдДТы
1.5ЁЂДДНЈБэЕФФЃАх (етИіЪЧБиаывЊЩшжУЕФ)
Р§згжаЩшжУСЫСНИіФЃАхЃК
base ФЃАхЃКИДжЦФЃЪНЃЌжЇГжЪТЮё
manage ФЃАхЃКЗжЧјФЃЪНЃЌЭЌвЛЗнЪ§ОнЃЌдкМЏШКжаБИЗн 3 ДЮЃЌжЇГжЪТЮё
<!-- ДДНЈБэЕФФЃАх -->
<property name="templateConfiguration">
<map key-type="java.lang.String" value-type="org.apache.ignite.configuration.TableTemplateConfiguration">
<entry key="base">
<bean class="org.apache.ignite.configuration.TableTemplateConfiguration">
<property name="templateValue" value="template=REPLICATED,ATOMICITY=TRANSACTIONAL"></property>
<property name="description" value="ИДжЦФЃЪНЃЌРДБЃДцЪ§ОнЃЁ"></property>
</bean>
</entry>
<entry key="manage">
<bean class="org.apache.ignite.configuration.TableTemplateConfiguration">
<property name="templateValue" value="template=partitioned,backups=3,ATOMICITY=TRANSACTIONAL"></property>
<property name="description" value="ЗжЦЌФЃЪНЃЌРДБЃДцЪ§ОнЃЁ"></property>
</bean>
</entry>
</map>
</property>1.6ЁЂЩшжУЖргУЛЇзщ(ФЌШЯЪЧжЇГжЖргУЛЇзщЕФ)
<!-- ЪЧЗёЦєгУЖргУЛЇзщ -->
<property name="multiUserGroup" value="true"/>1.7ЁЂЬэМгЦфЫћНкЕу
<property name="discoverySpi">
<bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi">
<property name="ipFinder">
<bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.multicast.TcpDiscoveryMulticastIpFinder">
<property name="addresses">
<list>
<!-- ЗжВМЪНЛЗОГЬцЛЛЪЕМЪЕФ ip КЭ ЖЫПк -->
<!-- Р§ШчЃКХфжУЖрИіЬЈЛњЦїЛњЦї -->
<!-- 47500..47509 БэЪОЖЫПкЗЖЮЇ -->
<!-- <value>ipЕижЗвЛ:47500..47509</value> -->
<!-- <value>ipЕижЗЖў:47500..47509</value> -->
<!-- <value>ipЕижЗШ§:47500..47509</value> -->
<value>127.0.0.1:47500..47509</value>
</list>
</property>
</bean>
</property>
</bean>
</property>2ЁЂДДНЈ schema
жЛга root гУЛЇЃЌВХФмДДНЈКЭаоИФ schema
ДДНЈ schema гаСНжжаДЗЈЃК
ОпЬхгУЗЈЃК
-- ДДНЈ schema wudafu
create schema wudafu;
-- Лђеп
-- ДДНЈ schema wudafu
create schema if not exists wudafu;3ЁЂЮЊ schema ЬэМггУЛЇзщ
жЛга root гУЛЇЃЌВХФмЩшжУгУЛЇзщ
ОпЬхгУЗЈЃК<a href=''></a>
-- ЬэМггУЛЇзщ
add_user_group('wudafu_group', 'wudafu_token', 'all', 'wudafu');
-- ЭЈЙ§ user_token ЛёШЁгУЛЇзщ
get_user_group('wudafu_token');add_user_group ЮЊФкжУКЏЪ§ЫќгаЫФИіВЮЪ§ЃКЕквЛИіЃКгУЛЇзщЕФУћзжЃЌЕкЖўИіЃКгУЛЇЕФ user_token гУЛЇЗУЮЪЪ§ОнПтЃЌЕкШ§ИіЃКжЛФмбЁдё allЃЌ dmlЃЌ ddlЃЌЕкЫФИіЃКschema ЕФУћзжЁЃ
add_user_group ЕФвтЫМЪЧЮЊ schema ЬэМгвЛИігУЛЇзщЁЃАќКЌЃКгУЛЇзщУћГЦЁЂuser_token КЭЫќЕФВйзїШЈЯоЁЃ
4ЁЂЬэМгБэВЂВхШыЪ§Он
Р§ШчЃКгУ root ЕФ token ЛђепЪЧЩЯУцР§згЕФ myy_token
ШчЙћгУ DBeaverWeb РДВйзїЃЌжЛашвЊЪфШы root ЕФ token Лђеп myy_token</br>
ШчЙћгУ JDBC СЌНгзжЗћДЎЮЊЃКjdbc:ignite:thin://127.0.0.1:10800/public?lazy=true&userToken=dafu
dafu ЮЊЩЯУц root ЕФ userToken
вВПЩвдгУ myy_token ЃЌвђЮЊЫќЕФгаЬэМгБэЕФШЈЯоЁЃ
DROP TABLE IF EXISTS public.Categories;
-- ВњЦЗРраЭБэ
CREATE TABLE IF NOT EXISTS public.Categories (
-- ВњЦЗРраЭID
CategoryID INTEGER NOT NULL auto,
-- ВњЦЗРраЭУћ
CategoryName VARCHAR(15) NOT NULL,
-- РраЭЫЕУї
Description VARCHAR,
-- ВњЦЗбљБО
Picture VARCHAR,
PRIMARY KEY (CategoryID)
) WITH "template=manage";
CREATE INDEX IF NOT EXISTS Categories_CategoryName_idx ON public.Categories (CategoryName);
INSERT INTO public.Categories (CategoryName, Description, Picture) VALUES('Beverages','Soft drinks, coffees, teas, beers, and ales', '');
INSERT INTO public.Categories (CategoryName, Description, Picture) VALUES('Condiments','Sweet and savory sauces, relishes, spreads, and seasonings', '');
INSERT INTO public.Categories (CategoryName, Description, Picture) VALUES('Confections','Desserts, candies, and sweet breads', '');
INSERT INTO public.Categories (CategoryName, Description, Picture) VALUES('Dairy Products','Cheeses', '');
INSERT INTO public.Categories (CategoryName, Description, Picture) VALUES('Grains/Cereals','Breads, crackers, pasta, and cereal', '');
INSERT INTO public.Categories (CategoryName, Description, Picture) VALUES('Meat/Poultry','Prepared meats', '');
INSERT INTO public.Categories (CategoryName, Description, Picture) VALUES('Produce','Dried fruit and bean curd', '');
INSERT INTO public.Categories (CategoryName, Description, Picture) VALUES('Seafood','Seaweed and fish', '');ЬэМгБэвЊзЂвтЃЌШчЙћЪЧСЊКЯжїМќЃЌПЩвдАДеевЕЮёЕФЬиЕуЃЌНЋвЛИіжїМќЩшжУЮЊ affinity_key
Р§ШчЃК
-- ЖЉЕЅЯъЧщБэ
CREATE TABLE wudagui.OrderDetails (
-- ЖЉЕЅБрКХ
OrderID INTEGER NOT NULL,
-- ВњЦЗБрКХ
ProductID INTEGER NOT NULL,
-- ЕЅМл
UnitPrice DECIMAL(10,4) DEFAULT 0,
-- ЖЉЙКЪ§СП
Quantity SMALLINT(2) DEFAULT 1,
-- елПл
Discount REAL(8,0) NOT NULL,
PRIMARY KEY (OrderID, ProductID)
) WITH "template=manage,affinity_key=ProductID";affinity_key ЧзКЭМќЃЌвтЫМЪЧНЋЯрЭЌМќжЕЕФЪ§ОнЃЌЗжХфЕНЭЌвЛНкЕуЁЃетбљжДаа SQL ЕФЪБКђЃЌЭЌвЛНкЕуЕФЪ§ОнЃЌОЭВЛашвЊвЦЖЏСЫЃЁ
5ЁЂИјгУЛЇзщЗжХфЗУЮЪШЈЯо
ОпЬхгУЗЈЃК
-- ЮЊгУЛЇзщЃКwudafu_groupЃЌЬэМгВщбЏ public.Categories БэЕФШЈЯоЁЃ
-- ШУЦфжЛФмВщбЏ CategoryName <> 'Seafood' ЧвжЛФмВщбЏСа CategoryName, Description ЕФЪ§Он
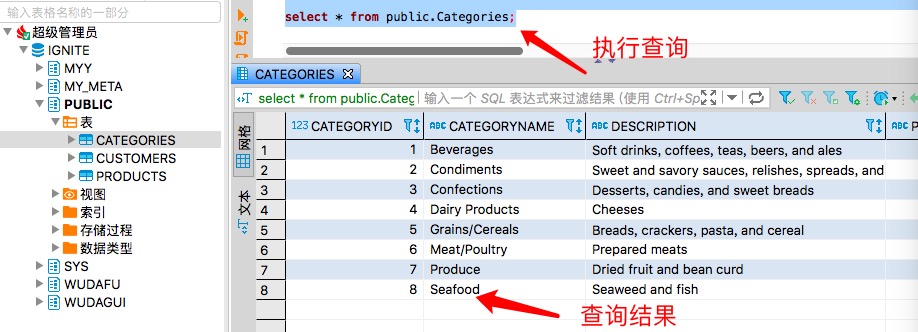
my_view('wudafu_group', "SELECT CategoryName, Description from public.Categories where CategoryName <> 'Seafood'");гУ wudafu_group ЕФ user_token: wudafu_token ЕЧТМ DBeaverWeb ВщбЏ public.Categories ЕУЕННсЙћ
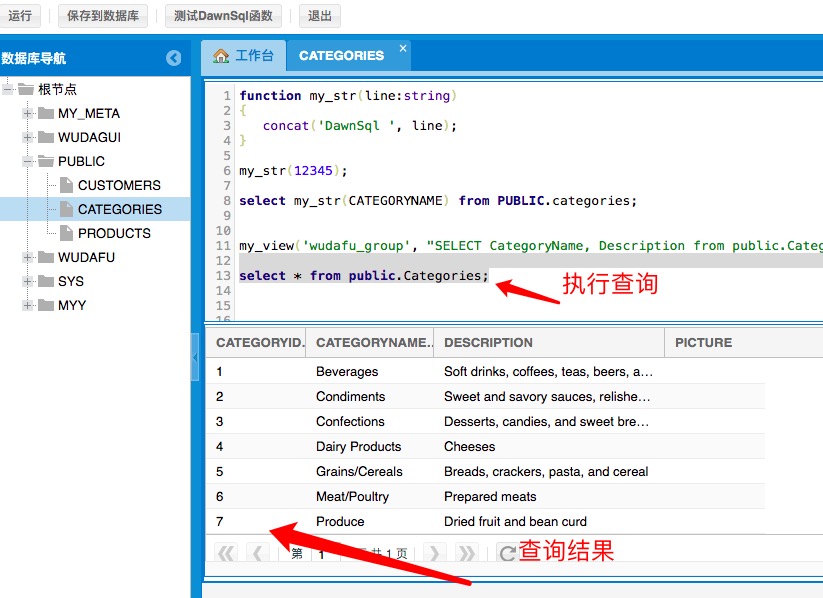
ЪЕМЪНсЙћЪЧ 8 Ьѕ
ШЈЯоЪгЭМЪЕЯжЕФдРэЃКЭЈЙ§ЗНЗЈНЋБэКЭБэЕФЖСаДШЈЯоАѓЖЈЕНгУЛЇзщЃЌетбљгУЛЇзщжДаа sql гяОфЕФЪБКђЃЌОЭЛсШЅЖСШЁШЈЯоЪгЭМЕФ ast ЃЌзюКѓдкзщКЯГЩаТ ast жДааЁЃ
6ЁЂNoSql ЕФжЇГж
ОпЬхгУЗЈЃК
trans(SqlЛђепNoSql ЕФађСа) ЪТЮёКЏЪ§
-- ДДНЈвЛИіЗжЧјЕФЛКДц
noSqlCreate({"table_name": "my_cache", "mode": "partitioned"});
-- дкЛКДцжаЃЌВхШыЪ§Он
noSqlInsert({"table_name": "my_cache", "key": "000A", "value": {"name": "ЮтДѓИЛ", "age": 100}});
-- ЖСШЁЛКДцжаЕФЪ§Он
noSqlGet({"table_name": "my_cache", "key": "000A"});7ЁЂЪТЮёЕФжЇГж
ОпЬхгУЗЈЃК
function update_table(CategoryID:int, CategoryName:string)
{
let lst = [['update public.Categories set CategoryName = ? where UserID = ?', [CategoryName, CategoryID]]];
lst.add(noSqlDeleteTran({"table_name": "my_cache", "key": CategoryID}));
trans(lst);
}жДааЪТЮёашвЊЕїгУ DawnSql ЕФ trans ЗНЗЈЁЃИУЗНЗЈЛсНЋађСажаЕФ sql Лђ no sql ЖМЛсзЊЛЛГЩ key -value аЮЪНЃЌШЛКѓжДааЖўНзЖЮЬсНЛ
8ЁЂDawnSql гяЗЈЕФМђНщ
ОпЬхгУЗЈЃК
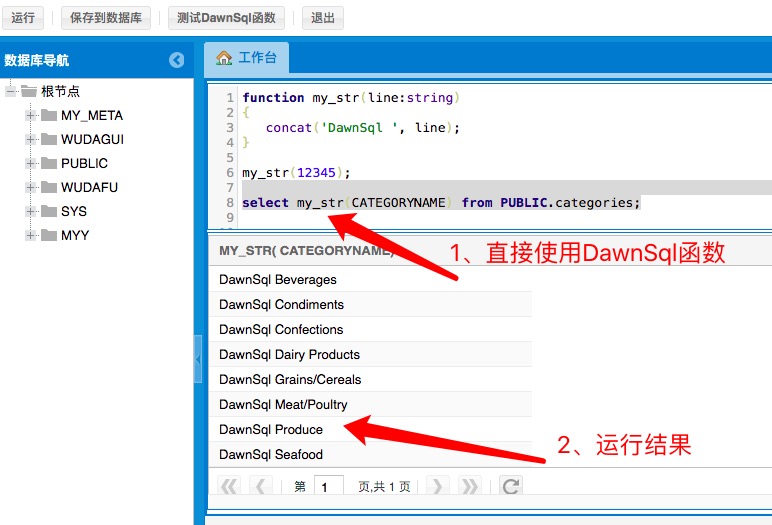
-- 1ЁЂЪфШывЛИізжЗћДЎЃЌЪфГівЛИіЧАзК DawnSql ЕФзжЗћДЎ
function my_str(line:string)
{
concat('DawnSql ', line);
}
-- 2ЁЂЕБАб DawnSqlКЏЪ§жаЬсНЛЕНЪ§ОнКѓЃЌОЭПЩвддк sql КЭ DawnSql жаЪЙгУетИіКЏЪ§
select my_str(CATEGORYNAME) from PUBLIC.categories;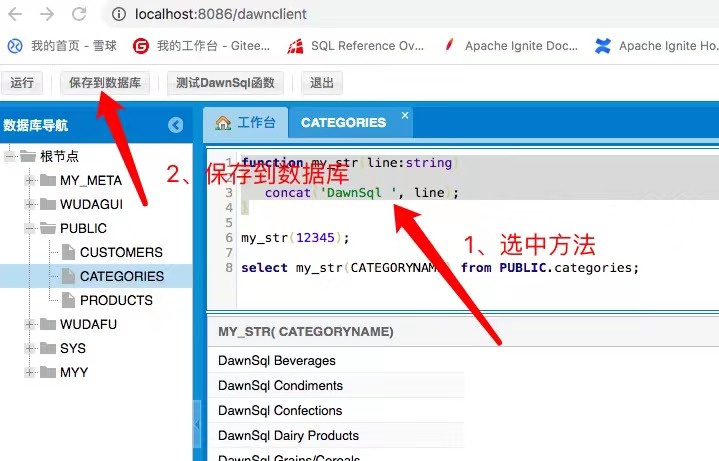
9ЁЂDawnSql ЕФРЉеЙ
ОпЬхгУЗЈЃК
9.1ЁЂJava ДњТы
package org.dawnsql.lib;
import java.sql.Timestamp;
import java.text.SimpleDateFormat;
import java.util.Date;
public class MyUtil {
public String getNow()
{
Timestamp timestamp = new Timestamp(System.currentTimeMillis());
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
System.out.println(simpleDateFormat.format(new Date(timestamp.getTime())));
return simpleDateFormat.format(new Date(timestamp.getTime()));
}
}9.2ЁЂзЂВсГЩ DawnSql жаЕФЗНЗЈ
add_func({"method_name":"getNow","java_method_name":"getNow","cls_name":"org.dawnsql.lib.MyUtil","return_type":"String","descrip":"","lst":[]});10ЁЂЗжВМЪНЖЈЪБШЮЮё
ОпЬхгУЗЈЃК
-- УПИєСНЗжжгЃЌжиИДжДаа 30 ДЮ getNow ЗНЗЈ
add_job('getNow', [], '{2,30} * * * * *');ЖЈЪБШЮЮёжаЕФШЮЮёЃЌдкМЏШКжаЪЧИКдиОљКтЕФЃЌЕБНкЕуЙЪеЯЪБЃЌЖЈЪБШЮЮёЛсНјааЙЪеЯзЊвЦ
дДДЩљУїЃКБОЮФЯЕзїепЪкШЈЬкбЖдЦПЊЗЂепЩчЧјЗЂБэЃЌЮДОаэПЩЃЌВЛЕУзЊдиЁЃ
ШчгаЧжШЈЃЌЧыСЊЯЕ cloudcommunity@tencent.com ЩОГ§ЁЃ
дДДЩљУїЃКБОЮФЯЕзїепЪкШЈЬкбЖдЦПЊЗЂепЩчЧјЗЂБэЃЌЮДОаэПЩЃЌВЛЕУзЊдиЁЃ
ШчгаЧжШЈЃЌЧыСЊЯЕ cloudcommunity@tencent.com ЩОГ§ЁЃ